译者 | 李睿
审校 | 孙淑娟
表格数据是网络上最好的数据来源之一。它们可以存储大量有用的信息,同时又不丢失易于阅读的格式,使其成为数据相关项目的金矿。
无论是抓取足球赛事数据还是提取股票市场数据,都可以使用Python从HTML表中快速访问、解析和提取数据,而这需要感谢Requests和Beautiful Soup。
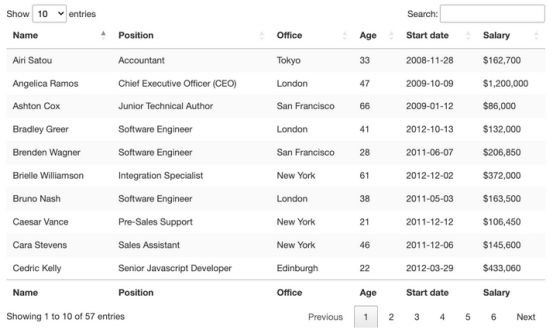
从视觉上看,HTML表是一组以表格格式显示信息的行和列。本文主要介绍如何抓取表格数据:
为了能够抓取该表中包含的数据,需要更深入地研究它的编码。
一般来说,HTML表实际上是使用以下HTML标记构建的:
然而,正如人们在实际场景中看到的,并不是所有开发人员在构建表时都遵循这些约定,这使得一些项目比其他项目更难。不过,了解它们的工作原理对于找到正确的方法至关重要。
在浏览器中输入表的URL,并检查页面,看看在底层发生了什么。
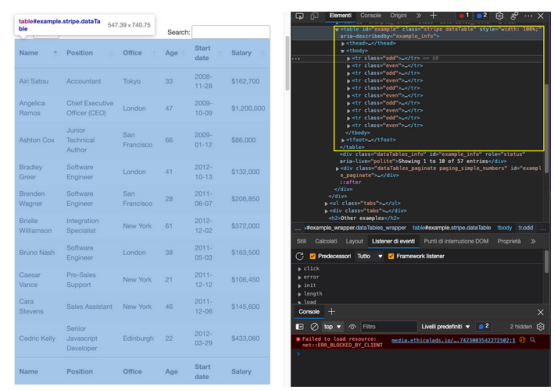
这就是这个页面非常适合练习用Python抓取表格数据的原因。有一个明确的<table>标签对打开和关闭表,所有相关数据都在<tbody>标签中。它只显示与前端所选条目数量匹配的10行。
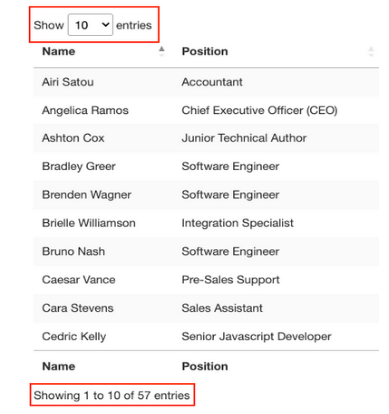
关于这个表还有一些需要了解的事情,即想要抓取的条目共有57个,并且似乎有两种访问数据的解决方案。第一种是点击下拉菜单,选择“100”,显示所有条目:
或者单击“下一步”按钮以浏览分页。

那么哪一种方案会更好?这两种解决方案都会给脚本增加额外的复杂性,因此,先检查从哪里提取数据。
当然,因为这是一个HTML表,因此所有数据都应该在HTML文件本身上,而不需要AJAX注入。要验证这一点,需要右击>查看页面来源。接下来,复制一些单元格并在源代码中搜索它们。
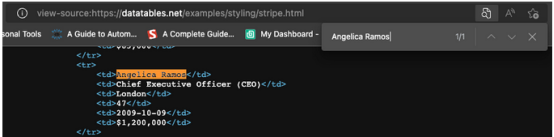
对来自不同分页单元格的多个条目执行了相同的操作,尽管前端没有显示,但似乎所有目标数据都在其中。
有了这些信息,就可以开始编写代码了。
因为要获取的所有员工数据都在HTML文件中,所以可以使用Requests库发送HTTP请求,并使用Beautiful Soup解析响应。
注:对于网页抓取的新手,本文作者在Python教程中为初学者创建了一个网络抓取教程。尽管新手没有经验也可以学习,但从基础开始总是一个好主意。
在这个项目中创建一个名为python-html-table的新目录,然后创建一个名为bs4-table-scraper的新文件夹,最后创建一个新的python_table_scraper.py文件。
从终端pip3安装请求beautifulsoup4,并将它们导入到项目中,如下所示:
import requests
from bs4 import BeautifulSoup要用requests发送HTTP请求,所需要做的就是设置一个URL并通过request.get()传递它,将返回的HTML存储在响应变量中并输出response.status_code。
注:如果完全不熟悉Python,可以使用命令python3python_table_scraper.py从终端运行代码。
url = 'https://datatables.net/examples/styling/stripe.html'
response = requests.get(url)
print(response.status_code)如果它有效,将会返回一个200状态码。任何其他情况都意味着IP正在被网站设置的反抓取系统拒绝。一个潜在的解决方案是在脚本中添加自定义标题,使脚本看起来更加人性化,但这可能还不够。另一个解决方案是使用Web抓取API处理所有这些复杂的问题。
在提取数据之前,需要将原始HTML转换为格式化或解析的数据。将这个解析后的HTML存储到一个soup对象中,如下所示:
soup = BeautifulSoup(response.text, 'html.parser')从这里开始,可以使用HTML标记及其属性遍历解析树。
如果返回到页面上的表,已经看到该表用类stripe dataTable封装在<table>标记之间,可以使用它来选择该表。
table = soup.find('table', class_ = 'stripe')
print(table)注:在测试之后,添加第二个类(dataTable)并没有返回元素。实际上,在return元素中,表的类只是stripe。还可以使用id='example'。
以下是它返回的结果:
Table Return既然已经获取了表,就可以遍历行并获取所需的数据。
回想一下HTML表的结构,每一行都由<tr>元素表示,其中有包含数据的<td>元素,所有这些都包装在<tbody>标签对之间。
为了提取数据,将创建两个for looks,一个用于抓取表的<tbody>部分(所有行所在的位置),另一个用于将所有行存储到可以使用的变量中:
for employee_data in table.find_all('tbody'):
rows = employee_data.find_all('tr')
print(rows)在行中,将存储表正文部分中找到的所有<tr>元素。如果遵循这个逻辑,下一步就是将每一行存储到单个对象中,并循环遍历它们以查找所需的数据。
首先,尝试使用.querySelectorAll()方法在浏览器控制台上选择第一个员工的名字。这个方法的一个真正有用的特性是,可以越来越深入地实现大于(>)符号的层次结构,以定义父元素(在左侧)和要获取的子元素(在右侧)。
document.querySelectorAll('table.stripe &amp;amp;gt; tbody &amp;amp;gt; tr &amp;amp;gt; td')[0]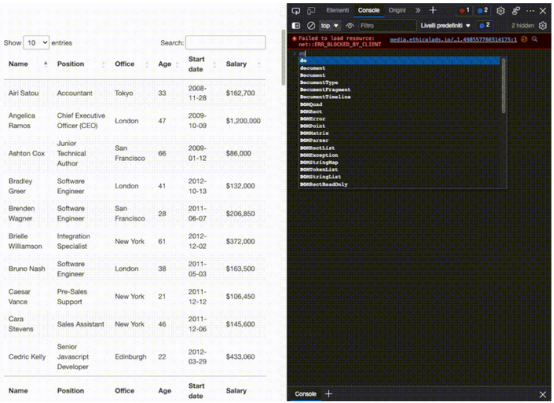
如上所见,一旦抓取所有<td>元素,这些元素就会成为节点列表。因为不能依赖类来获取每个单元格,所以只需要知道它们在索引中的位置,而第一个name是0。
从那里,可以像这样编写代码:
for row in rows:
name = row.find_all('td')[0].text
print(name)简单地说,逐个获取每一行,并找到其中的所有单元格,一旦有了列表,只获取索引中的第一个单元格(position 0),然后使用.text方法只获取元素的文本,忽略不需要的HTML数据。
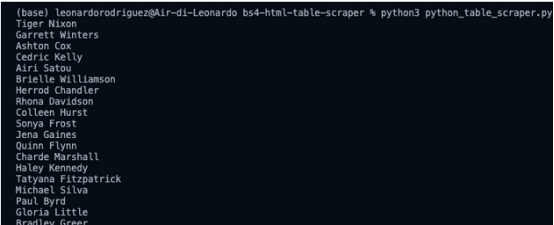
这是一个包含所有员工姓名的列表! 对于其余部分,只需要遵循同样的逻辑:
position = row.find_all('td')[1].text
office = row.find_all('td')[2].text
age = row.find_all('td')[3].text
start_date = row.find_all('td')[4].text
salary = row.find_all('td')[5].text然而,将所有这些数据输出在控制台上并没有太大帮助。与其相反,可以将这些数据存储为一种、更有用的新格式。
虽然可以轻松地创建一个CSV文件并将数据发送到那里,但如果可以使用抓取的数据创建一些新内容,那么这将不是最容易管理的格式。
尽管如此,以前做的一个项目解释了如何创建一个CSV文件来存储抓取的数据。
好消息是,Python有自己的JSON模块来处理JSON对象,所以不需要安装任何程序,只需要导入它。
import json但是,在继续并创建JSON文件之前,需要将所有这些抓取的数据转换为一个列表。为此,将在循环外部创建一个空数组。
employee_list = []然后向它追加数据,每个循环向数组追加一个新对象。
employee_list.append({ 'Name': name, 'Position': position, 'Office': office, 'Age': age, 'Start date': start_date, 'salary': salary })如果print(employee_list),其结果如下:
Employee_List还是有点混乱,但已经有了一组准备转换为JSON的对象。
注:作为测试,输出employee_list的长度,它返回57,这是抓取的正确行数(行现在是数组中的对象)。
将列表导入到JSON只需要两行代码:
with open('json_data', 'w') as json_file:
json.dump(employee_list, json_file, indent=2)如果一直按照下面的方法做,那么代码库应该是这样的:
#dependencies
import requests
from bs4 import BeautifulSoup
import json
url = 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afbxxxxxxxxxxx&url=https://datatables.net/examples/styling/stripe.html'
#empty array
employee_list = []
#requesting and parsing the HTML file
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
#selecting the table
table = soup.find('table', class_ = 'stripe')
#storing all rows into one variable
for employee_data in table.find_all('tbody'):
rows = employee_data.find_all('tr')
#looping through the HTML table to scrape the data
for row in rows:
name = row.find_all('td')[0].text
position = row.find_all('td')[1].text
office = row.find_all('td')[2].text
age = row.find_all('td')[3].text
start_date = row.find_all('td')[4].text
salary = row.find_all('td')[5].text
#sending scraped data to the empty array
employee_list.append({
'Name': name,
'Position': position,
'Office': office,
'Age': age,
'Start date': start_date,
'salary': salary
})
#importing the array to a JSON file
with open('employee_data', 'w') as json_file:
json.dump(employee_list, json_file, indent=2)注:在这里为场景添加了一些注释。
以下是JSON文件中的前三个对象:
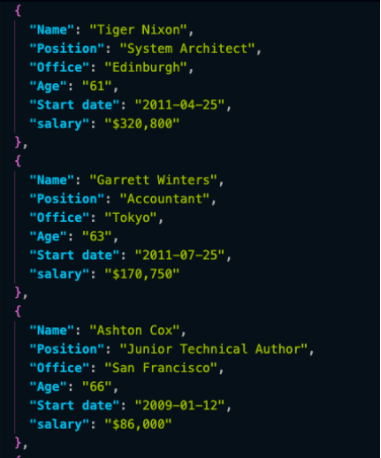
以JSON格式存储抓取数据允将信息用于新的应用程序
在离开页面之前,希望探索第二种抓取HTML表的方法。只需几行代码,就可以从HTML文档中抓取所有表格数据,并使用Pandas将其存储到数据框架中。
在项目的目录中创建一个新文件夹(将其命名为panda-html-table-scraper),并创建一个新文件名pandas_table_scraper.py。
打开一个新的终端,导航到刚刚创建的文件夹(cdpanda-html-table-scraper),并从那里安装pandas:
pip install pandas在文件的顶部导入它。
import pandas as pdPandas有一个名为read_html()的函数,它主要抓取目标URL,并返回所有HTML表作为DataFrame对象的列表。
要实现这一点,HTML表至少需要结构化,因为该函数将查找<table>之类的元素来标识文件中的表。
为了使用这个函数,需要创建一个新变量,并将之前使用的URL传递给它:
employee_datapd.read_html('http://api.scraperapi.com?api_key=51e43be283e4db2a5afbxxxxxxxxxxxx&url=https://datatables.net/examples/styling/stripe.html')当输出它时,它将返回页面内的HTML表列表。
HTMLTables如果比较DataFrame中的前三行,它们与采用BeautifulSoup抓取的结果完全匹配。
为了处理JSON,Pandas可以有一个内置的.to_json()函数。它将把DataFrame对象列表转换为JSON字符串。
而所需要做的就是调用DataFrame上的方法,并传入路径、格式(split,data,records,index等),并添加缩进以使其更具可读性:
employee_data[0].to_json('./employee_list.json', orient='index', indent=2)如果现在运行代码,其结果文件如下:
Resulting File注意,需要从索引([0])中选择表,因为.read_html()返回一个列表,而不是单个对象。
以下是完整的代码以供参考
import pandas as pd
employee_data = pd.read_html('http://api.scraperapi.com?api_key=51e43be283e4db2a5afbxxxxxxxxxxxx&url=https://datatables.net/examples/styling/stripe.html')
employee_data[0].to_json('./employee_list.json', orient='index', indent=2)有了这些新知识,就可以开始抓取网络上几乎所有的HTML表了。只要记住,如果理解了网站的结构和背后的逻辑,就没有什么是不能抓取的。
也就是说,只要数据在HTML文件中,这些方法就有效。如果遇到动态生成的表,则需要找到一种新的方法。
原文标题:How to Use Python to Loop Through HTML Tables and Scrape Tabular Data,作者:Zoltan Bettenbuk
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t