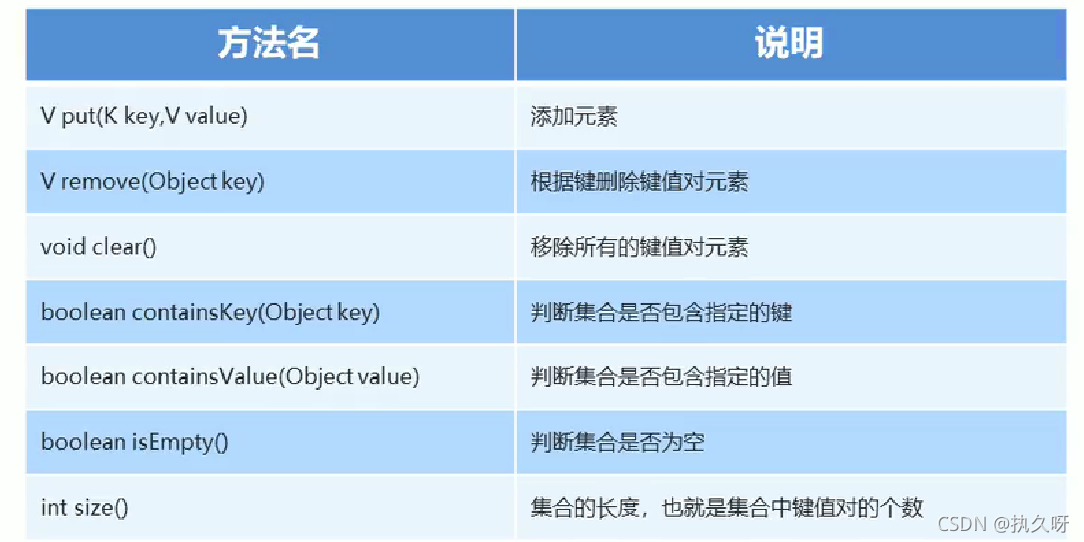
目录
map集合是我们常使用的集合,了解和使用map集合是必要的
基本形式: public interface Map<K,V>
Map是一个接口,我们不能直接创建对象,可以通过多态的形式创建对象,Map中有两个
参数,一个是K表示键,一个是V表示值,且一个键有且对应一个值,Map中不能包含重复的
键,若是有重复的键添加,则会以最后一次的键为准,而其他的键会被覆盖。集合都在
java.util包下,所以需要导包。
具体实现常用的一般有两种,一是HashMap,另一个是TreeMap
import java.util.HashMap;
import java.util.Map;
public class MapTest {
public static void main(String[] args) {
Map<String,String> map=new HashMap<>();
map.put("2001", "张三");
map.put("2002", "张三");
map.put("2003", "李四");
map.put("2003", "王五");//键重复,会覆盖上一个,留下最新的
System.out.println(map);//{2003=王五, 2002=张三, 2001=张三}
}
}
由上可知,map中的键是不能重复的,而值是可以重复的可以直接通过输出对象来得到
集合的内容,说明此集合内重写了toString方法。
这些功能是常见的,掌握这些即可
import java.util.HashMap;
import java.util.Map;
public class MapTest {
public static void main(String[] args) {
//创建Map集合对象
Map<String,String> map=new HashMap<>();
//增加元素
map.put("2001", "张三");
map.put("2002", "李四");
map.put("2003", "王五");
System.out.println(map);//{2003=王五, 2002=李四, 2001=张三}
//根据键删除元素
// map.remove("2001");
//System.out.println(map);//{2003=王五, 2002=李四}
//判断集合中是否包含指定的键返回boolean类型
System.out.println(map.containsKey("2001"));//true
System.out.println(map.containsKey("2004"));//false
//判断集合中是否包含指定的值返回boolean类型
System.out.println(map.containsValue("张三"));//true
System.out.println(map.containsValue("赵六"));//false
//判断集合是否为空返回boolean类型
System.out.println(map.isEmpty());//false
//得到集合的长度
System.out.println(map.size());//3
//清除所有键值对
map.clear();
System.out.println(map.isEmpty());//true,为空了
}
}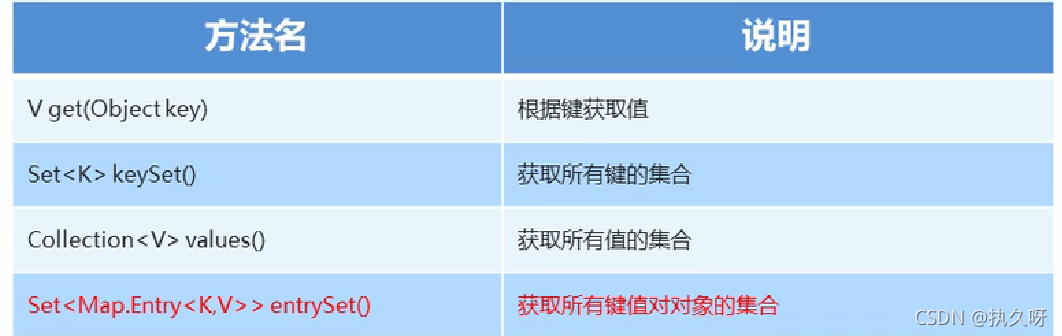
此方法多是用在遍历集合时,前三种比较常用也比较好记。
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Maptest2 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("2001", "张三");
map.put("2002", "李四");
map.put("2003", "王五");
//遍历集合
//方式1:
// 由键找值,创建键的集合
Set<String> keySet=map.keySet();
//遍历键的集合,得到每一个键
for (String key:keySet){
//由键找值
String value=map.get(key);
//输出键和值
System.out.print(key+" "+value+", ");
}
System.out.println("\n------------");
//方式2:
//获取所有键值对的集合
Set<Map.Entry<String,String>> entrySet =map.entrySet();
//遍历键值对集合
for (Map.Entry<String,String> me:entrySet){
//分别得到键和值
String key=me.getKey();
String value=me.getValue();
System.out.print(key+" "+value+", ");
}
}
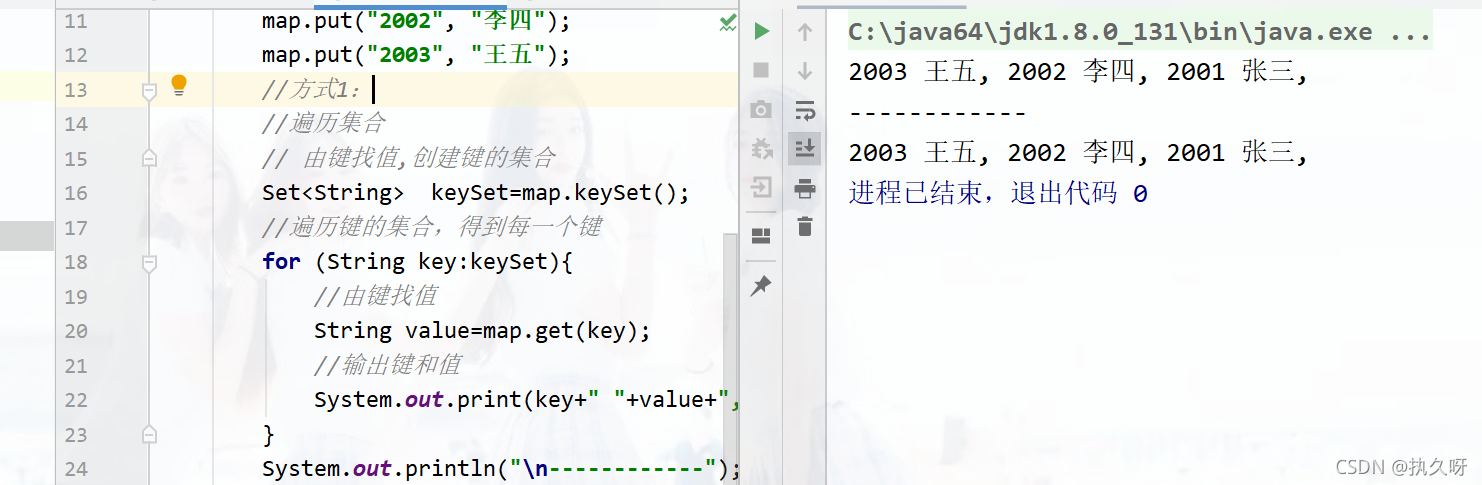
}如图:
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
我基本上来自Java背景并且努力理解Ruby中的模运算。(5%3)(-5%3)(5%-3)(-5%-3)Java中的上述操作产生,2个-22个-2但在Ruby中,相同的表达式会产生21个-1-2.Ruby在逻辑上有多擅长这个?模块操作在Ruby中是如何实现的?如果将同一个操作定义为一个web服务,两个服务如何匹配逻辑。 最佳答案 在Java中,模运算的结果与被除数的符号相同。在Ruby中,它与除数的符号相同。remainder()在Ruby中与被除数的符号相同。您可能还想引用modulooperation.