服务器大多都采用 Linux 系统,这里我们以 Linux 为例来讲解:
ubuntu 和 Centos 都是 Linux 的发行版,发行版可以看成对 linux 包了一层壳,任何 Linux 发行版,其系统内核都是 Linux 。我们的应用都需要通过 Linux 内核与硬件交互

用户的应用,比如 redis ,mysql 等其实是没有办法去执行访问我们操作系统的硬件的,所以我们可以通过发行版的这个壳子去访问内核,再通过内核去访问计算机硬件

计算机硬件包括,如 cpu,内存,网卡等等,内核(通过寻址空间)可以操作硬件的,但是内核需要不同设备的驱动,有了这些驱动之后,内核就可以去对计算机硬件去进行 内存管理,文件系统的管理,进程的管理等等
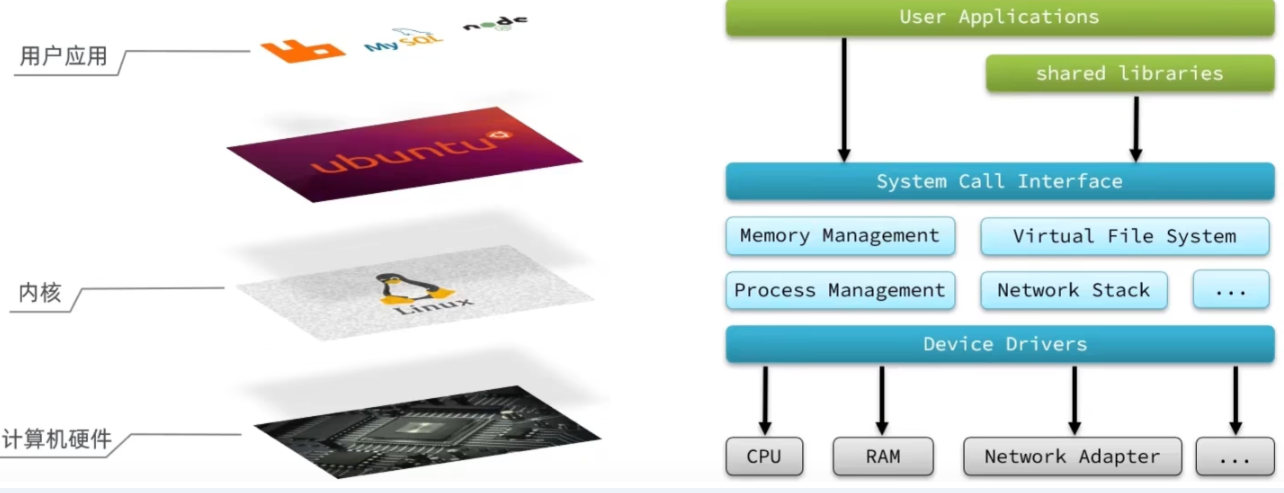
我们想要用户的应用来访问,计算机就必须要通过对外暴露的一些接口,才能访问到,从而简介的实现对内核的操控,但是内核本身上来说也是一个应用,所以他本身也需要一些内存,cpu 等设备资源,用户应用本身也在消耗这些资源,如果不加任何限制,用户去操作随意的去操作我们的资源,就有可能导致一些冲突,甚至有可能导致我们的系统出现无法运行的问题,因此我们需要把用户和内核隔离开
进程的寻址空间划分成两部分:内核空间、用户空间
什么是寻址空间呢?我们的应用程序也好,还是内核空间也好,都是没有办法直接去物理内存的,而是通过分配一些虚拟内存映射到物理内存中,我们的内核和应用程序去访问虚拟内存的时候,就需要一个虚拟地址,这个地址是一个无符号的整数。
比如一个 32 位的操作系统,他的带宽就是 32,他的虚拟地址就是 2 的 32 次方,也就是说他寻址的范围就是 0~2 的 32 次方, 这片寻址空间对应的就是 2 的 32 个字节,就是 4GB,这个 4GB,会有 3 个 GB 分给用户空间,会有 1GB 给内核系统

在 linux 中,他们权限分成两个等级,0 和 3,用户空间只能执行受限的命令(Ring3),而且不能直接调用系统资源,必须通过内核提供的接口来访问内核空间可以执行特权命令(Ring0),调用一切系统资源,所以一般情况下,用户的操作是运行在用户空间,而内核运行的数据是在内核空间的,而有的情况下,一个应用程序需要去调用一些特权资源,去调用一些内核空间的操作,所以此时他俩需要在用户态和内核态之间进行切换。
比如:
Linux 系统为了提高 IO 效率,会在用户空间和内核空间都加入缓冲区:
针对这个操作:我们的用户在写读数据时,会去向内核态申请,想要读取内核的数据,而内核数据要去等待驱动程序从硬件上读取数据,当从磁盘上加载到数据之后,内核会将数据写入到内核的缓冲区中,然后再将数据拷贝到用户态的 buffer 中,然后再返回给应用程序,整体而言,速度慢,就是这个原因,为了加速,我们希望 read 也好,还是 wait for data 也最好都不要等待,或者时间尽量的短。
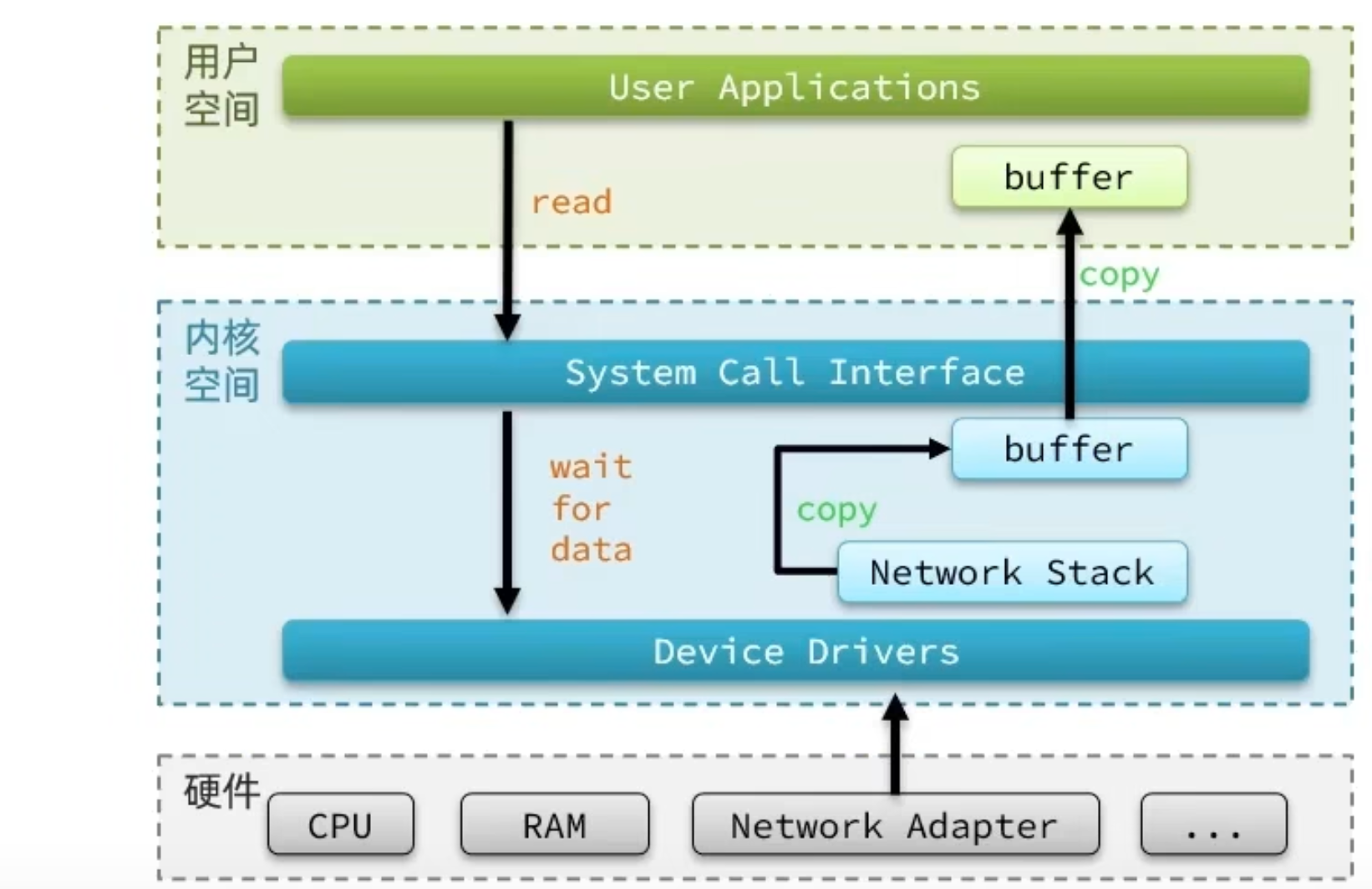
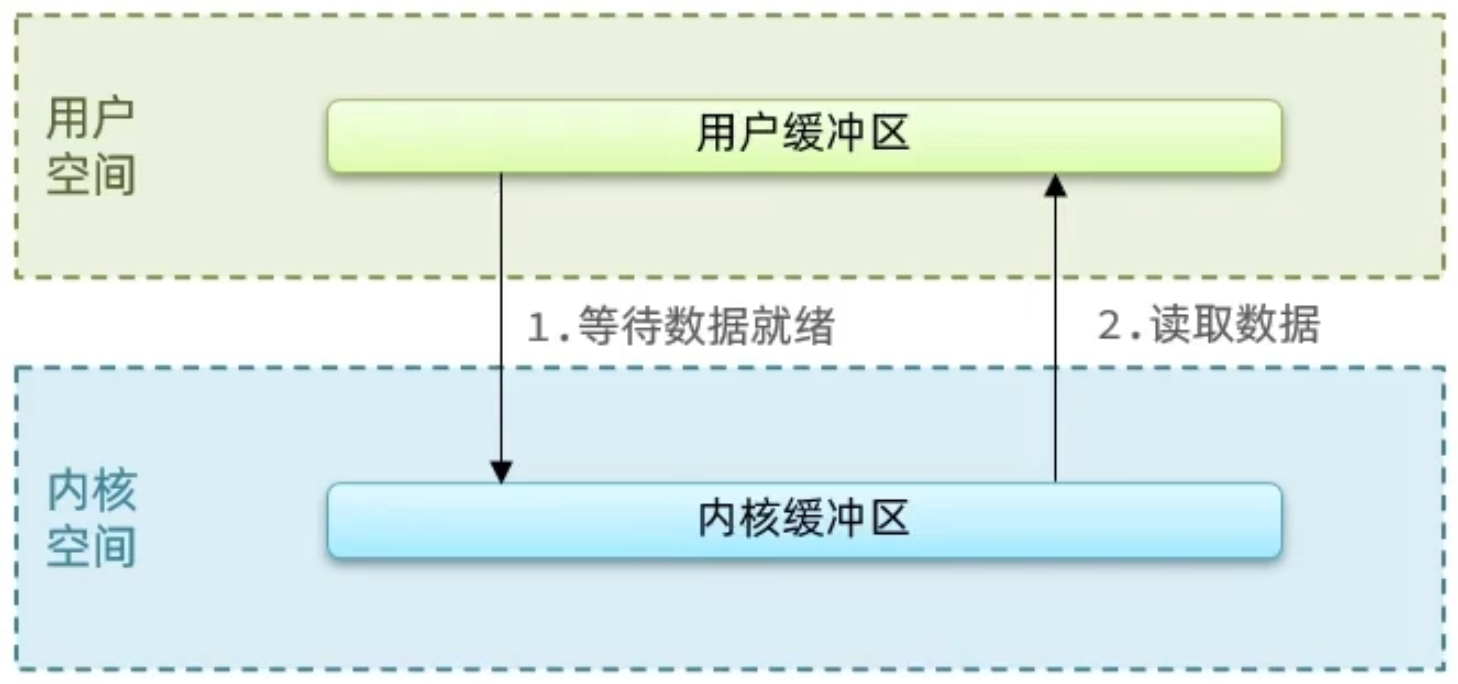
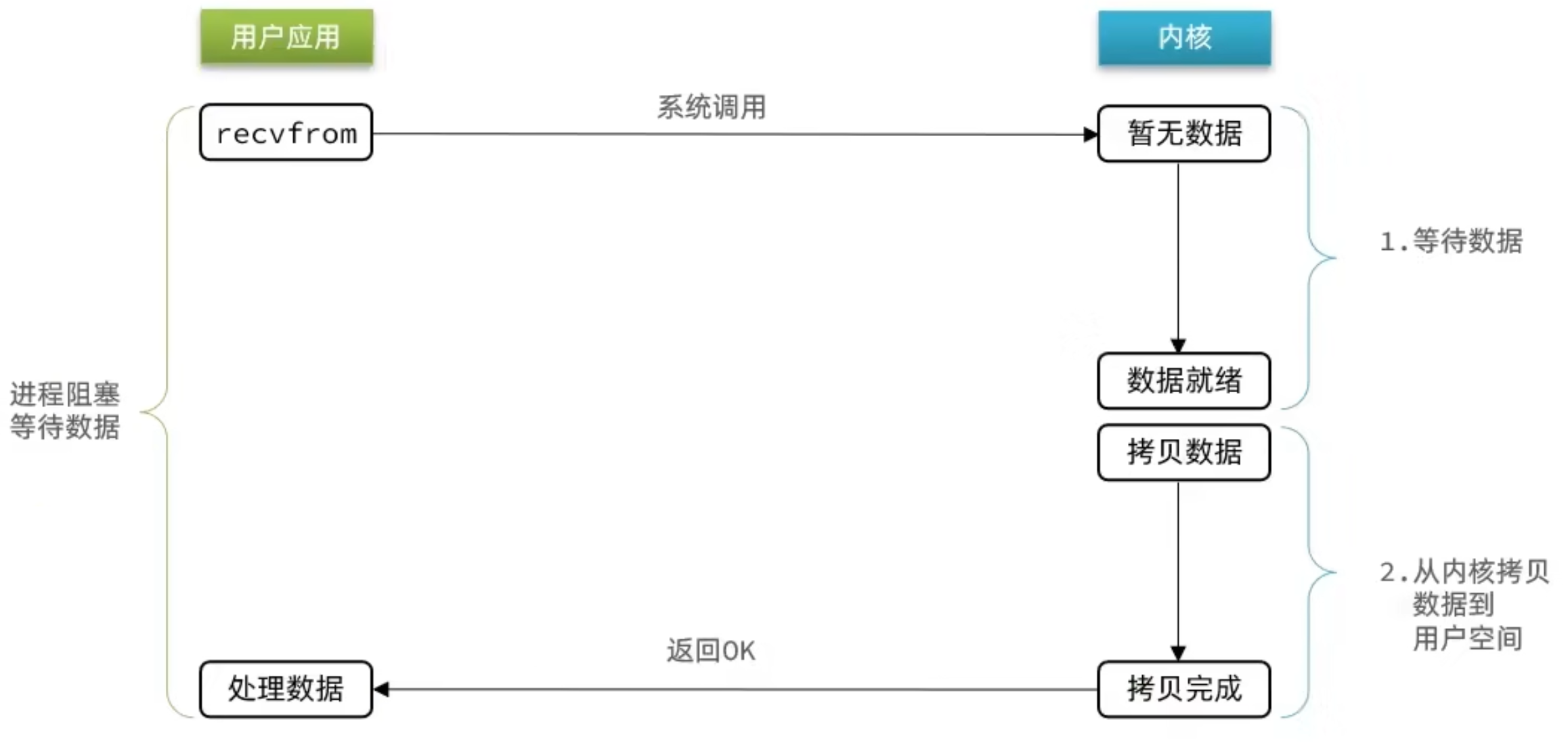
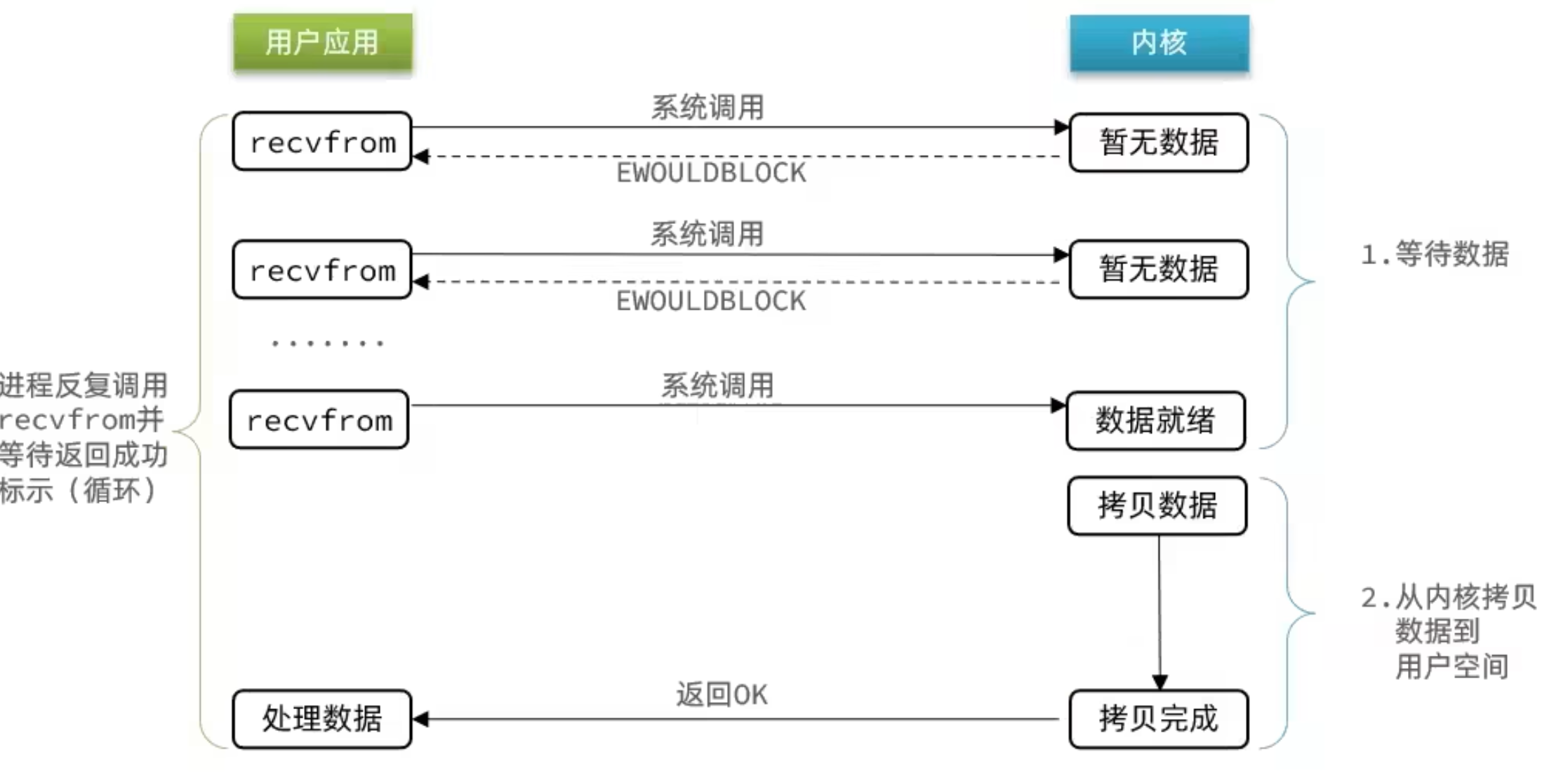
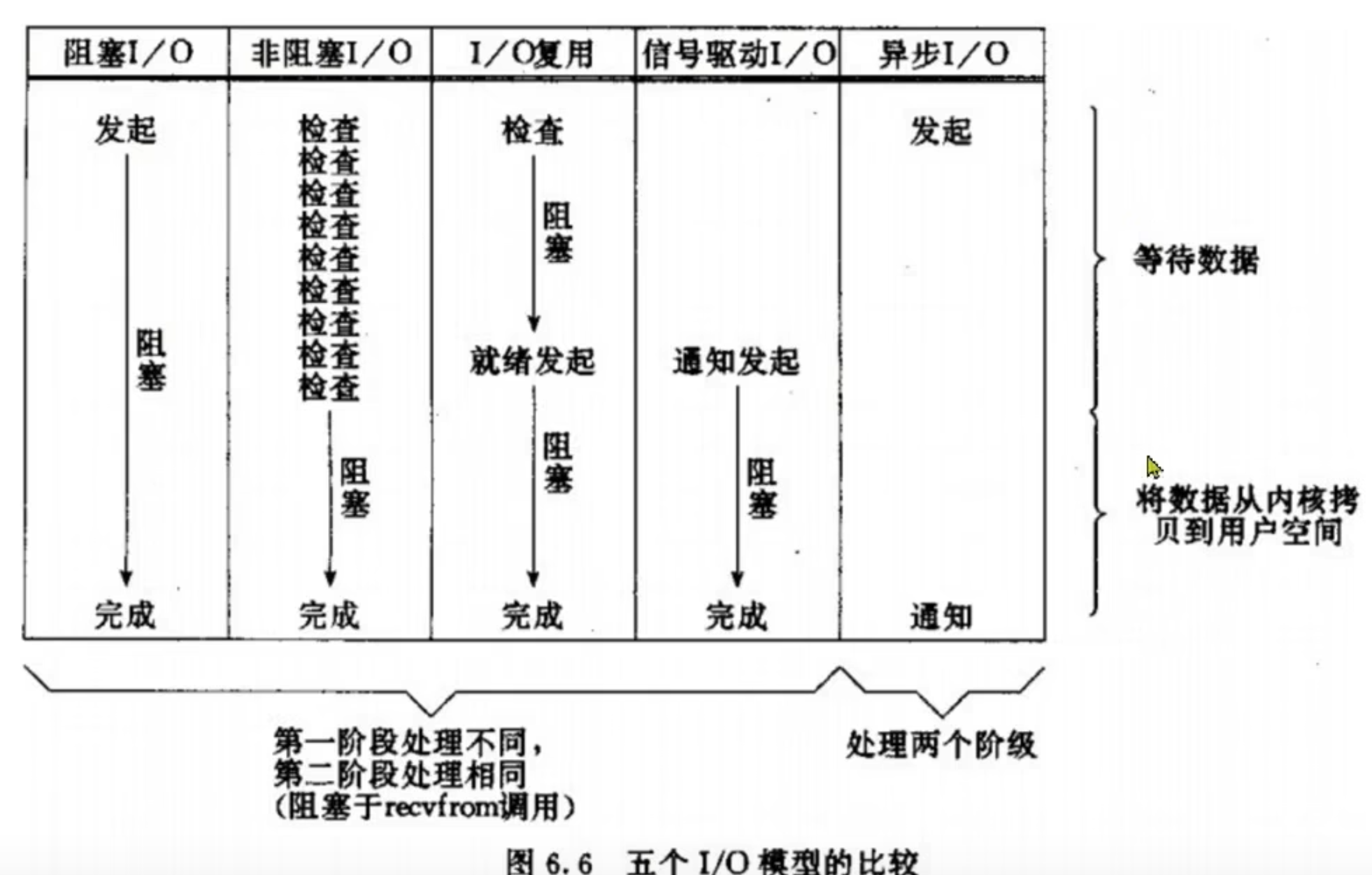
用户去读取数据时,会去先发起 recvform 一个命令,去尝试从内核上加载数据,如果内核没有数据,那么用户就会等待,此时内核会去从硬件上读取数据,内核读取数据之后,会把数据拷贝到用户态,并且返回 ok,整个过程,都是阻塞等待的,这就是阻塞 IO
总结如下:
顾名思义,阻塞 IO 就是两个阶段都必须阻塞等待:
阶段一:
阶段二:
可以看到,阻塞 IO 模型中,用户进程在两个阶段都是阻塞状态。
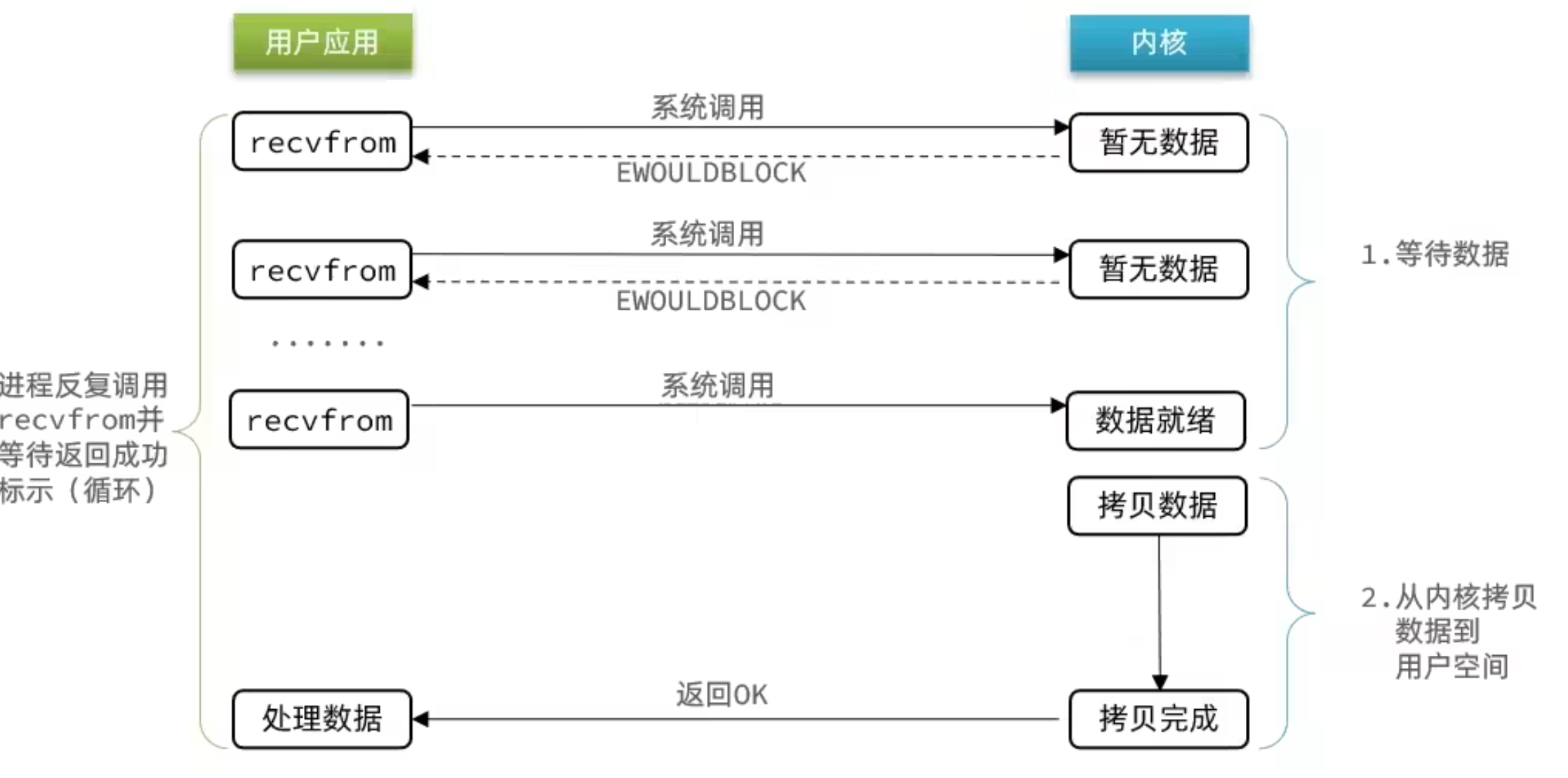
顾名思义,非阻塞 IO 的 recvfrom 操作会立即返回结果而不是阻塞用户进程
阶段一:
阶段二:
信号驱动 IO 是与内核建立 SIGIO 的信号关联并设置回调,当内核有 FD 就绪时,会发出 SIGIO 信号通知用户,期间用户应用可以执行其它业务,无需阻塞等待。
阶段一:
阶段二:
当有大量 IO 操作时,信号较多,SIGIO 处理函数不能及时处理可能导致信号队列溢出,而且内核空间与用户空间的频繁信号交互性能也较低。
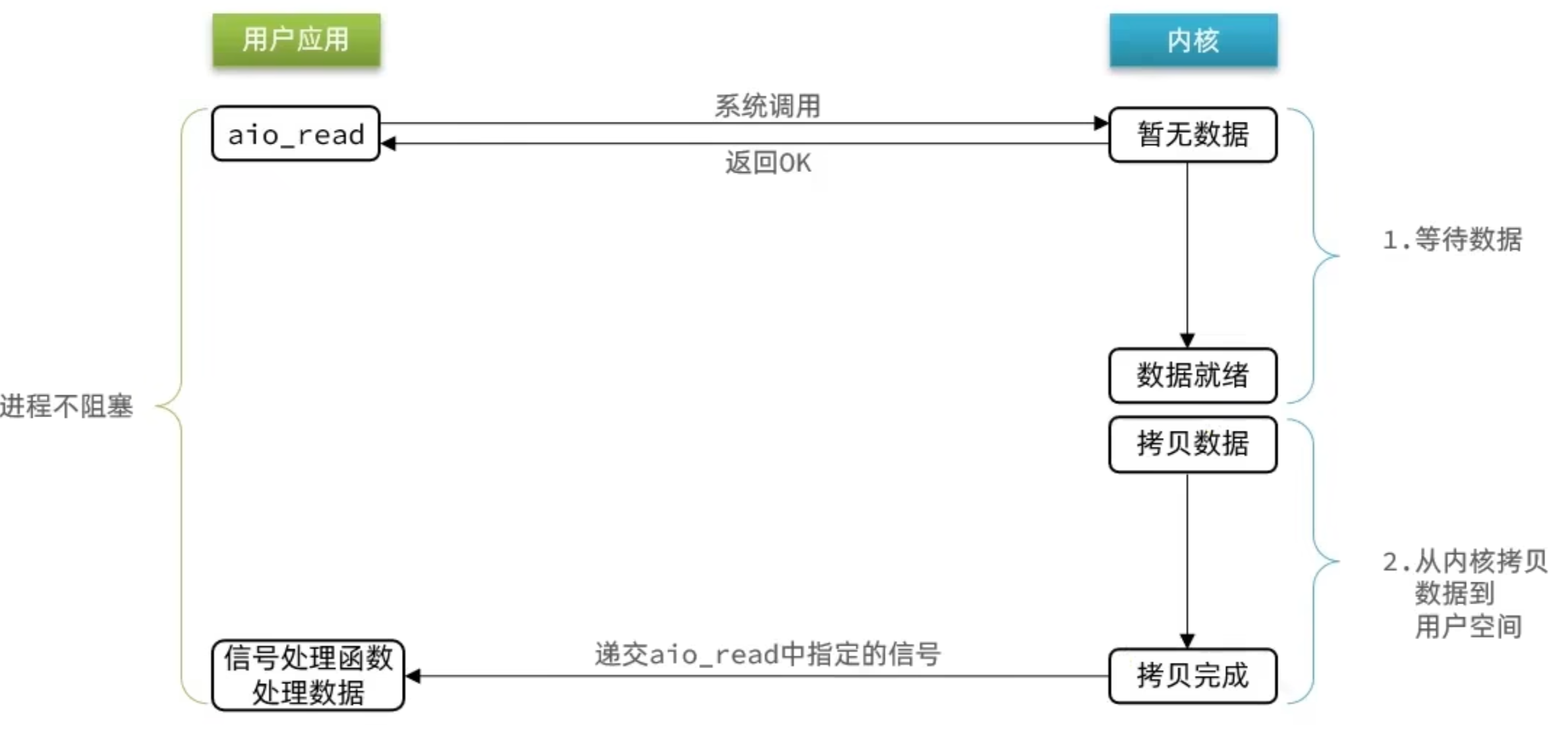
这种方式,不仅仅是用户态在试图读取数据后,不阻塞,而且当内核的数据准备完成后,也不会阻塞
他会由内核将所有数据处理完成后,由内核将数据写入到用户态中,然后才算完成,所以性能极高,不会有任何阻塞,全部都由内核完成,可以看到,异步 IO 模型中,用户进程在两个阶段都是非阻塞状态。
为了更好的理解 IO ,现在假设这样一种场景:一家餐厅

每排到一位客户要吃到饭,都要经过两个步骤:
思考要吃什么
顾客开始点餐,厨师开始炒菜
由于餐厅只有一位服务员,因此一次只能服务一位客户,并且还需要等待当前客户思考出结果,这浪费了后续排队的人非常多的时间,效率极低。这就是阻塞 IO。
当然,为了缓解这种情况,老板完全可以多雇几个人,但这也会增加成本,而在极大客流量的情况下,仍然不会有很高的效率提升
每排到一位客户要吃到饭,都要经过两个步骤:
与 A 情况不同的是,此时服务员会不断询问顾客:“你想吃番茄鸡蛋盖浇饭吗?那滑蛋牛肉呢?那肉末茄子呢?……”
虽然服务员在不停的问,但是在网络中,这并不会增加数据的就绪速度,主要还是等顾客自己确定。所以,这并不会提高餐厅的效率,说不定还会招来更多差评。这就是非阻塞 IO。
每排到一位客户要吃到饭,还是都要经过两个步骤:
与 A B 不同的是,这种情况服务员不必再等待顾客思考吃什么,只需要在收到顾客通知后,去接收菜单就好。这样相当于餐厅在只有一个服务员的情况下,同时服务了多个人,而不像 A B,同一时刻只能服务一个人。此时餐厅的效率自然就提高了很多。
映射到我们的网络服务中,就是这样:
目前流程的多路复用 IO 实现主要包括四种: select、poll、epoll、kqueue。下表是他们的一些重要特性的比较:
| IO 模型 | 相对性能 | 关键思路 | 操作系统 | JAVA 支持情况 |
|---|---|---|---|---|
| select | 较高 | Reactor | windows/Linux | 支持,Reactor 模式 (反应器设计模式)。Linux 操作系统的 kernels 2.4 内核版本之前,默认使用 select;而目前 windows 下对同步 IO 的支持,都是 select 模型 |
| poll | 较高 | Reactor | Linux | Linux 下的 JAVA NIO 框架,Linux kernels 2.6 内核版本之前使用 poll 进行支持。也是使用的 Reactor 模式 |
| epoll | 高 | Reactor/Proactor | Linux | Linux kernels 2.6 内核版本及以后使用 epoll 进行支持;Linux kernels 2.6 内核版本之前使用 poll 进行支持;另外一定注意,由于 Linux 下没有 Windows 下的 IOCP 技术提供真正的 异步 IO 支持,所以 Linux 下使用 epoll 模拟异步 IO |
| kqueue | 高 | Proactor | Linux | 目前 JAVA 的版本不支持 |
多路复用 IO 技术最适用的是 “高并发” 场景,所谓高并发是指 1 毫秒内至少同时有上千个连接请求准备好。其他情况下多路复用 IO 技术发挥不出来它的优势。另一方面,使用 JAVA NIO 进行功能实现,相对于传统的 Socket 套接字实现要复杂一些,所以实际应用中,需要根据自己的业务需求进行技术选择。
select 是 Linux 最早是由的 I/O 多路复用技术:
linux 中,一切皆文件,socket 也不例外,我们把需要处理的数据封装成 FD,然后在用户态时创建一个 fd_set 的集合(这个集合的大小是要监听的那个 FD 的最大值 + 1,但是大小整体是有限制的 ),这个集合的长度大小是有限制的,同时在这个集合中,标明出来我们要控制哪些数据。
其内部流程:
用户态下:
内核态:

不足之处:
poll 模式对 select 模式做了简单改进,但性能提升不明显。
IO 流程:
与 select 对比:

epoll 模式是对 select 和 poll 的改进,它提供了三个函数:eventpoll 、epoll_ctl 、epoll_wait
select 模式存在的三个问题:
poll 模式的问题:
epoll 模式中如何解决这些问题的?
一张图搞定:

我们来梳理一下这张图
红黑树(为空):rb_root 用来去记录需要被监听的 FD
链表(为空):list_head,用来存放已经就绪的 FD
创建好了之后,会去调用 epoll_ctl 函数,此函数会会将需要监听的 fd 添加到 rb_root 中去,并且对当前这些存在于红黑树的节点设置回调函数。
当这些被监听的 fd 一旦准备就绪,与之相关联的回调函数就会被调用,而调用的结果就是将红黑树的 fd 添加到 list_head 中去 (但是此时并没有完成)
fd 添加完成后,就会调用 epoll_wait 函数,这个函数会去校验是否有 fd 准备就绪(因为 fd 一旦准备就绪,就会被回调函数添加到 list_head 中),在等待了一段时间 (可以进行配置)。
如果等够了超时时间,则返回没有数据,如果有,则进一步判断当前是什么事件,如果是建立连接事件,则调用 accept () 接受客户端 socket ,拿到建立连接的 socket ,然后建立起来连接,如果是其他事件,则把数据进行写出。
最后用一幅图,来说明他们之间的区别
Redis 是一个 CS 架构的软件,通信一般分两步(不包括 pipeline 和 PubSub):
而在 Redis 中采用的是 RESP(Redis Serialization Protocol)协议:
但目前,默认使用的依然是 RESP2 协议。在 RESP 中,通过首字节的字符来区分不同数据类型,常用的数据类型包括 5 种:

本文由
传智教育博学谷教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我对最新版本的Rails有疑问。我创建了一个新应用程序(railsnewMyProject),但我没有脚本/生成,只有脚本/rails,当我输入ruby./script/railsgeneratepluginmy_plugin"Couldnotfindgeneratorplugin.".你知道如何生成插件模板吗?没有这个命令可以创建插件吗?PS:我正在使用Rails3.2.1和ruby1.8.7[universal-darwin11.0] 最佳答案 随着Rails3.2.0的发布,插件生成器已经被移除。查看变更日志here.现在
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳