 这篇文章,我们来聊一下对于一个支撑日活百万用户的高并系统,他的数据库架构应该如何设计?看到这个题目,很多人第一反应就是:分库分表啊!但是实际上,数据库层面的分库分表到底是用来干什么的,他的不同的作用如何应对不同的场景,我觉得很多同学可能都没搞清楚。
这篇文章,我们来聊一下对于一个支撑日活百万用户的高并系统,他的数据库架构应该如何设计?看到这个题目,很多人第一反应就是:分库分表啊!但是实际上,数据库层面的分库分表到底是用来干什么的,他的不同的作用如何应对不同的场景,我觉得很多同学可能都没搞清楚。 结果呢,没想到我们运气这么好,碰上个优秀的CEO带着我们走上了康庄大道!公司业务发展迅猛,过了几个月,注册用户数达到了2000万!每天活跃用户数100万!每天单表新增数据量达到50万条!高峰期每秒请求量达到1万!同时公司还顺带着融资了两轮,估值达到了惊人的几亿美金!一只朝气蓬勃的幼年独角兽的节奏!好吧,现在大家感觉压力已经有点大了,为啥呢?因为每天单表新增50万条数据,一个月就多1500万条数据,一年下来单表会达到上亿条数据。经过一段时间的运行,现在咱们单表已经两三千万条数据了,勉强还能支撑着。但是,眼见着系统访问数据库的性能怎么越来越差呢,单表数据量越来越大,拖垮了一些复杂查询SQL的性能啊!然后高峰期请求现在是每秒1万,咱们的系统在线上部署了20台机器,平均每台机器每秒支撑500请求,这个还能抗住,没啥大问题。但是数据库层面呢?如果说此时你还是一台数据库服务器在支撑每秒上万的请求,负责任的告诉你,每次高峰期会出现下述问题:
结果呢,没想到我们运气这么好,碰上个优秀的CEO带着我们走上了康庄大道!公司业务发展迅猛,过了几个月,注册用户数达到了2000万!每天活跃用户数100万!每天单表新增数据量达到50万条!高峰期每秒请求量达到1万!同时公司还顺带着融资了两轮,估值达到了惊人的几亿美金!一只朝气蓬勃的幼年独角兽的节奏!好吧,现在大家感觉压力已经有点大了,为啥呢?因为每天单表新增50万条数据,一个月就多1500万条数据,一年下来单表会达到上亿条数据。经过一段时间的运行,现在咱们单表已经两三千万条数据了,勉强还能支撑着。但是,眼见着系统访问数据库的性能怎么越来越差呢,单表数据量越来越大,拖垮了一些复杂查询SQL的性能啊!然后高峰期请求现在是每秒1万,咱们的系统在线上部署了20台机器,平均每台机器每秒支撑500请求,这个还能抗住,没啥大问题。但是数据库层面呢?如果说此时你还是一台数据库服务器在支撑每秒上万的请求,负责任的告诉你,每次高峰期会出现下述问题: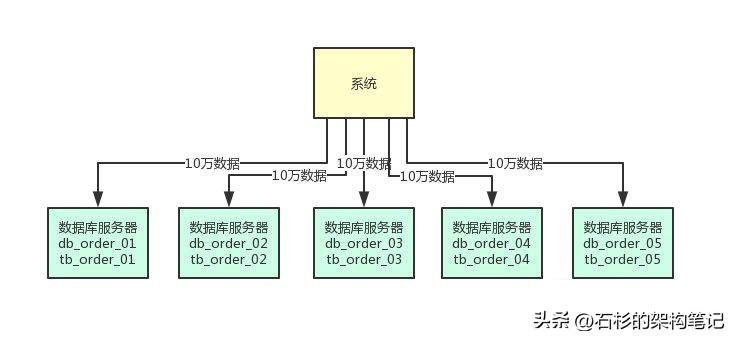 做这一步有什么好处呢?第一个好处,原来比如订单表就一张表,这个时候不就成了5张表了么,那么每个表的数据就变成1/5了。假设订单表一年有1亿条数据,此时5张表里每张表一年就2000万数据了。那么假设当前订单表里已经有2000万数据了,此时做了上述拆分,每个表里就只有400万数据了。而且每天新增50万数据的话,那么每个表才新增10万数据,这样是不是初步缓解了单表数据量过大影响系统性能的问题?另外就是每秒1万请求到5台数据库上,每台数据库就承载每秒2000的请求,是不是一下子把每台数据库服务器的并发请求降低到了安全范围内?这样,降低了数据库的高峰期负载,同时还保证了高峰期的性能。
做这一步有什么好处呢?第一个好处,原来比如订单表就一张表,这个时候不就成了5张表了么,那么每个表的数据就变成1/5了。假设订单表一年有1亿条数据,此时5张表里每张表一年就2000万数据了。那么假设当前订单表里已经有2000万数据了,此时做了上述拆分,每个表里就只有400万数据了。而且每天新增50万数据的话,那么每个表才新增10万数据,这样是不是初步缓解了单表数据量过大影响系统性能的问题?另外就是每秒1万请求到5台数据库上,每台数据库就承载每秒2000的请求,是不是一下子把每台数据库服务器的并发请求降低到了安全范围内?这样,降低了数据库的高峰期负载,同时还保证了高峰期的性能。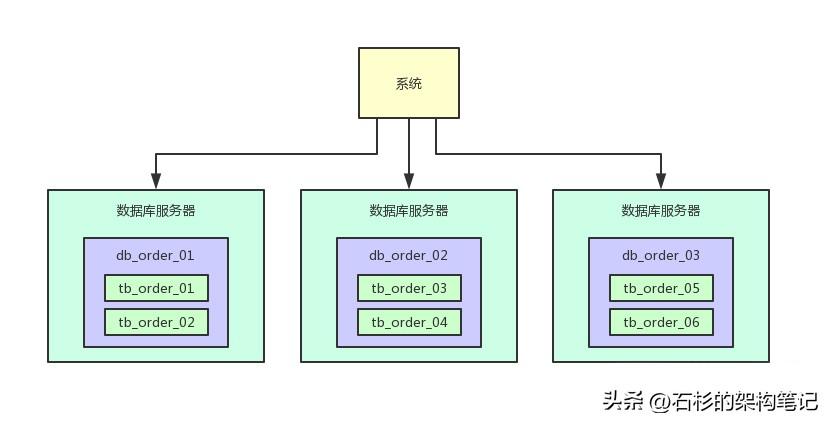
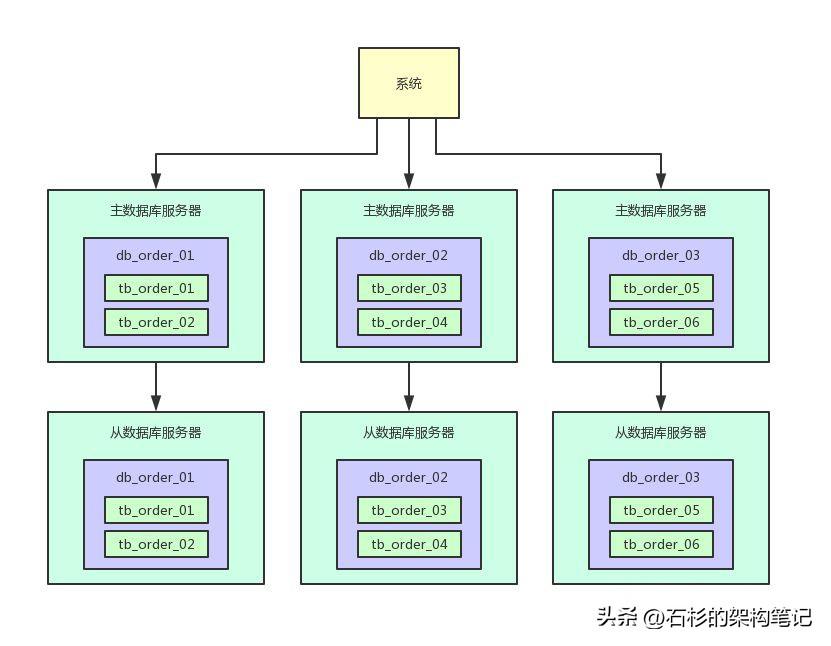 写入主库的时候,会自动同步数据到从库上去,保证主库和从库数据一致。然后查询的时候都是走从库去查询的,这就通过数据库的主从架构实现了读写分离的效果了。现在的好处就是,假如说现在主库写请求增加到800,这个无所谓,不需要扩容。然后从库的读请求增加到了3200,需要扩容了。这时,你直接给主库再挂载一个新的从库就可以了,两个从库,每个从库支撑1600的读请求,不需要因为读请求增长来扩容主库。实际上线上生产你会发现,读请求的增长速度远远高于写请求,所以读写分离之后,大部分时候就是扩容从库支撑更高的读请求就可以了。而且另外一点,对同一个表,如果你既写入数据(涉及加锁),还从该表查询数据,可能会牵扯到锁冲突等问题,无论是写性能还是读性能,都会有影响。所以一旦读写分离之后,对主库的表就仅仅是写入,没任何查询会影响他,对从库的表就仅仅是查询。
写入主库的时候,会自动同步数据到从库上去,保证主库和从库数据一致。然后查询的时候都是走从库去查询的,这就通过数据库的主从架构实现了读写分离的效果了。现在的好处就是,假如说现在主库写请求增加到800,这个无所谓,不需要扩容。然后从库的读请求增加到了3200,需要扩容了。这时,你直接给主库再挂载一个新的从库就可以了,两个从库,每个从库支撑1600的读请求,不需要因为读请求增长来扩容主库。实际上线上生产你会发现,读请求的增长速度远远高于写请求,所以读写分离之后,大部分时候就是扩容从库支撑更高的读请求就可以了。而且另外一点,对同一个表,如果你既写入数据(涉及加锁),还从该表查询数据,可能会牵扯到锁冲突等问题,无论是写性能还是读性能,都会有影响。所以一旦读写分离之后,对主库的表就仅仅是写入,没任何查询会影响他,对从库的表就仅仅是查询。我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为