

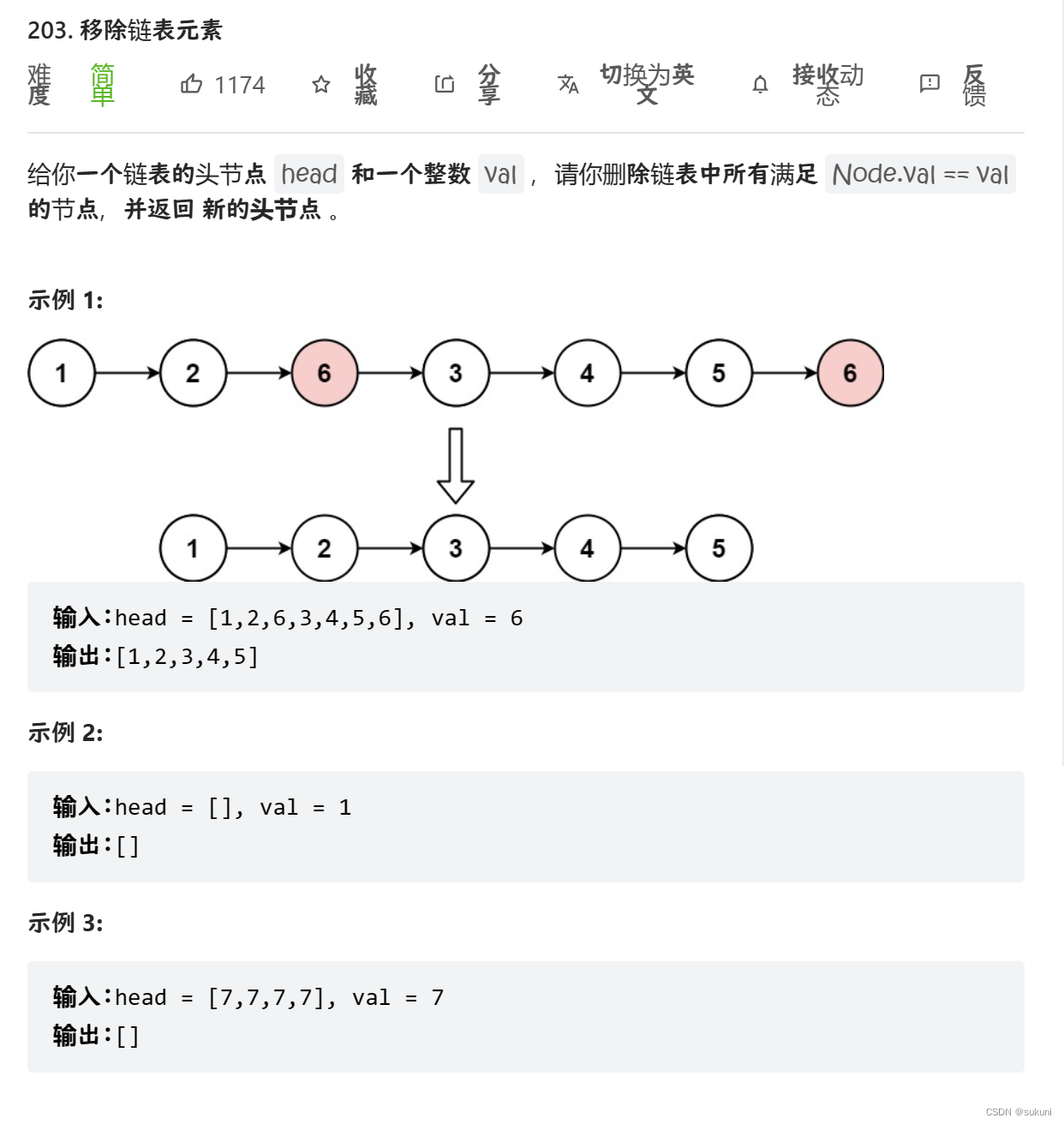
目录
1.创建一个指针 cur=head 和一个指针 pre=NULL;
2.用cur->val 与 val 比较,如果不相等则把 cur 赋给 pre 使cur 指向下一个节点,即
cur=cur->next;
3.如果相等则使 pre 的 next 指向 cur 的 next ,即:
pre->next=cur->next ,然后再 free 掉 cur ,最后再使 cur 等于 pre 的 next,注意在进行这些步骤之前要判断 pre 是否为空 ,若为空即为头删;
演示:
双指针
代码:
struct ListNode* removeElements(struct ListNode* head, int val)
{
struct ListNode*pre=NULL;
struct ListNode*cur=head;
while(cur)
{
if(cur->val!=val)
{
pre=cur;
cur=cur->next;
}
else
{
if(pre==NULL)
{
head=cur->next;
free(cur);
cur=head;
}
else
{
pre->next=cur->next;
cur=pre->next;
}
}
}
return head;
}1.创建一个新的指针newhead ,同时为了省去找尾的麻烦,我们可以定义一个尾指针 tail 来保存尾节点;
2.再创建一个指针 cur =head ,用来遍历链表;
3.如果 cur->val != val ,则尾插 ,注意要判断 tail 是否为空 ,类似于单链表的尾插那部分,如果不理解的话,可查看文章 :单链表的增删查改;
4.如果 cur->val ==val,则 cur=cur->next ;
5.最后要将尾节点置空。
演示:
类尾插
代码:
struct ListNode* removeElements(struct ListNode* head, int val)
{
struct ListNode *newhead=NULL;
struct ListNode*tail=NULL;
struct ListNode*cur=head;
while(cur)
{
if(cur->val!=val)
{
if(tail==NULL)
{
newhead=tail=cur;
}
else
{
tail->next=cur;
tail=tail->next;
}
cur=cur->next;
}
else
{
cur=cur->next;
}
}
if(tail)
{
tail->next=NULL;
}
return newhead;
}1.malloc 一个哨兵位节点 dummyhead,使其 next 指向 head ;
2.再定义一个节点 tmp = dummyhead ,用这个遍历链表;
3.注意因为 tmp ->next 才是 head ,所以 while 里要写 tmp->next !=NULL
演示:
移除链表元素 哨兵位法动态演示
代码:
struct ListNode* removeElements(struct ListNode* head, int val)
{
struct ListNode*dummyhead=(struct ListNode*)malloc(sizeof(struct ListNode));
dummyhead->next=head;
struct ListNode*tmp=dummyhead;
while(tmp->next!=NULL)
{
if(tmp->next->val==val)
{
tmp->next=tmp->next->next;
}
else
{
tmp=tmp->next;
}
}
return dummyhead->next;
}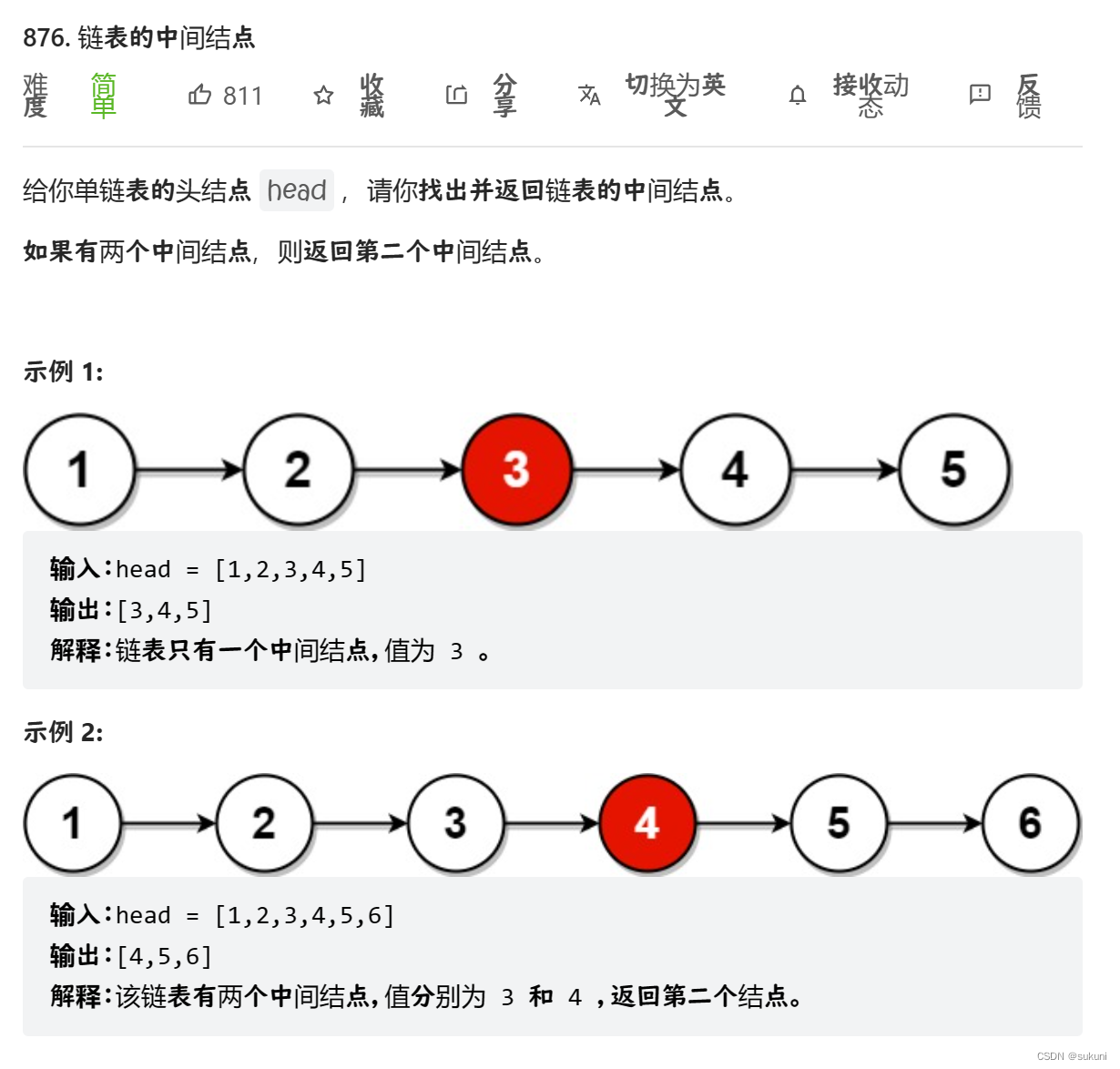
1.定义一个快指针 fast 和一个慢指针 slow 都初始化为 head;
2.遍历链表,快指针一次走2步,慢指针一次走1步 ;
3.注意:因为链表的长度可能是单数也可能是双数,所以当我们已 fast 是否为NULL 作为循环控制条件的话,要在 fast 走2步前判断 fast->next 是否为空;
4.最后慢指针就是中间节点。
演示:
链表中间节点 快慢指针动态演示
代码:
struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode*slow=head;
struct ListNode*fast=head;
while(fast)
{
if(fast->next==NULL) //注意判断
{
break;
}
else
{
fast=fast->next->next; //fast 走2步
}
slow=slow->next; //slow 走1步
}
return slow; //返回慢指针
}
1.定义一个快指针 fast 和一个慢指针 slow 都初始化为 head;
2.因为倒数第k个节点和尾节点的差为 k-1 ,所以我们先让快指针先走 k-1 步;
或者因为尾节点所指向的NULL 和倒数第k个节点相差k,也可以先让快指针走k步;
这个时候慢指针不动;
3.快指针走完后,快指针和慢指针依次走,每次只走1步;
注意,如果是k-1,那么遍历结束的条件是fast->next 是否为空 ,如果是k,那么遍历结束的条件是fast 是否为空;
4.返回慢指针。
演示:
链表倒数第K个节点 快慢指针动态演示
代码:
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k )
{
if(pListHead==NULL)
{
return NULL;
}
struct ListNode*slow=pListHead;
struct ListNode*fast=pListHead;
while(k--) //这里以先走k步为例
{
if(fast==NULL)
{
return NULL;
}
fast=fast->next;
}
while(fast)
{
slow=slow->next;
fast=fast->next;
}
return slow;
}😽本篇文章到此就结束了,若有错误或是建议,欢迎小伙伴们指出;😻
😍请多多支持博主哦~🥰
🤩谢谢你的阅读~😃

查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
ValidPalindromeGivenastring,determineifitisapalindrome,consideringonlyalphanumericcharactersandignoringcases. [#125]Example:"Aman,aplan,acanal:Panama"isapalindrome."raceacar"isnotapalindrome.Haveyouconsiderthatthestringmightbeempty?Thisisagoodquestiontoaskduringaninterview.Forthepurposeofthisproblem
我是HanamiWorld的新人。我已经写了这段代码:moduleWeb::Views::HomeclassIndexincludeWeb::ViewincludeHanami::Helpers::HtmlHelperdeftitlehtml.headerdoh1'Testsearchengine',id:'title'hrdiv(id:'test')dolink_to('Home',"/",class:'mnu_orizontal')link_to('About',"/",class:'mnu_orizontal')endendendendend我在模板上调用了title方法。htm
在Ruby中,是否有一种简单的方法可以将n维数组中的每个元素乘以一个数字?这样:[1,2,3,4,5].multiplied_by2==[2,4,6,8,10]和[[1,2,3],[1,2,3]].multiplied_by2==[[2,4,6],[2,4,6]]?(很明显,我编写了multiplied_by函数以区别于*,它似乎连接了数组的多个副本,不幸的是这不是我需要的)。谢谢! 最佳答案 它的长格式等价物是:[1,2,3,4,5].collect{|n|n*2}其实并没有那么复杂。你总是可以使你的multiply_by方法:c
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
我在尝试使用Nokogiri构建XML文档时遇到了一个小问题。我想将我的元素之一称为“文本”(请参阅下面粘贴代码的最底部)。通常,要创建一个新元素,我会执行类似以下的操作xml.text--但它似乎是.text是Nokogiri已经用来做其他事情的方法。因此,当我写这行时xml.textNokogiri没有创建名为的新元素但只是写了意味着成为元素内容的文本。我怎样才能让Nokogiri实际制作一个名为的元素??builder=Nokogiri::XML::Builder.newdo|xml|xml.TEI("xmlns"=>"http://www.tei-c.org/ns/1.0"
如果我想使用“create”构建策略创建和实例,然后想使用“attributes_for”构建策略进行验证,是否可以这样做?如果我在工厂中使用序列?在Machinistgem中有可能吗? 最佳答案 不太确定我是否完全理解。而且我不是机械师的用户。但听起来您只是想做这样的事情。@attributes=FactoryGirl.attributes_for(:my_object)my_object=MyObject.create(@attributes)my_object.some_property.should==@attributes
我想通过内部数组中的第一个元素从数组数组中找到唯一元素。例如a=[[1,2],[2,3],[1,5]我想要类似的东西[[1,2],[2,3]] 最佳答案 uniq方法需要一个block:uniq_a=a.uniq(&:first)或者如果您想就地进行:a.uniq!(&:first)例如:>>a=[[1,2],[2,3],[1,5]]=>[[1,2],[2,3],[1,5]]>>a.uniq(&:first)=>[[1,2],[2,3]]>>a=>[[1,2],[2,3],[1,5]]或者>>a=[[1,2],[2,3],[1,5]
我的任务是从数组中选择最高和最低的数字。我想我很清楚我想做什么,但只是努力以正确的格式访问信息以满足通过标准。defhigh_and_low(numbers)array=numbers.split("").map!{|x|x.to_i}array.sort!{|a,b|ba}putsarray[0,-1]end数字可能看起来像"80917234100",要通过,我需要输出"9234"。我正在尝试putsarray.first.last,但一直无法弄明白。 最佳答案 有Array#minmax完全满足您需要的方法:array=[80,