apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: my-app
updatePolicy:
updateMode: "Auto"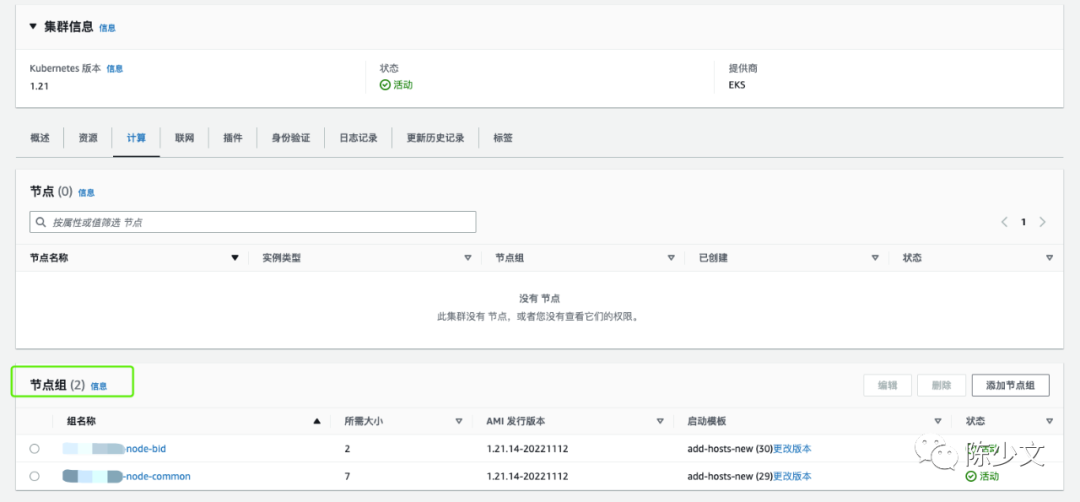 EKS 集群,具有若干节点组,每个节点组构成一个弹性伸缩的单元。如下图,节点组最少有 1 个节点,最多有 7 个节点:
EKS 集群,具有若干节点组,每个节点组构成一个弹性伸缩的单元。如下图,节点组最少有 1 个节点,最多有 7 个节点: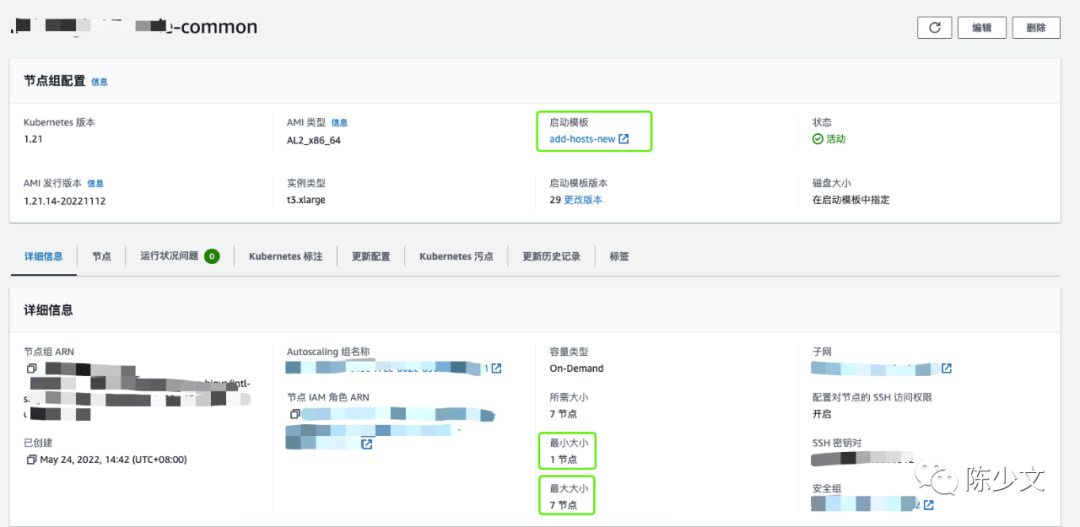 EKS 的节点弹性是针对节点组的,同一个节点组下的节点具有相同的机器配置、污点、标签、主机启动模板。当 EKS 判断需要进行节点扩容时,会结合节点组允许的最大节点数,进行扩容。这样也保障扩容出来的节点已经打上正确的污点和标签,能够直接被 Kubernetes 调度器使用。另外,节点组的概念,在产品和使用层面还可以包装成超级节点。只要节点数量的上限足够大,一个节点组就能提供超大的计算和内存资源池。
EKS 的节点弹性是针对节点组的,同一个节点组下的节点具有相同的机器配置、污点、标签、主机启动模板。当 EKS 判断需要进行节点扩容时,会结合节点组允许的最大节点数,进行扩容。这样也保障扩容出来的节点已经打上正确的污点和标签,能够直接被 Kubernetes 调度器使用。另外,节点组的概念,在产品和使用层面还可以包装成超级节点。只要节点数量的上限足够大,一个节点组就能提供超大的计算和内存资源池。文章目录1.任务背景2.任务目标3.相关知识点4.任务实操4.1安装配置JDK4.2启动FISCOBCOS4.3下载解压WeBASE-Front4.4拷贝sdk证书文件4.5启动节点4.6访问节点4.7检查运行状态5.任务总结1.任务背景FISCOBCOS其实是有控制台管理工具,用来对区块链系统进行各种管理操作。但是对于初学者来说,还是可视化界面更友好,本节就来介绍WeBASE管理平台,这是一款微众银行开源的自研区块链中间件平台,可以降低区块链使用的门槛,大幅提高区块链应用的开发效率。微众银行是腾讯牵头设立的民营银行,在国内民营银行里还是比较出名的。微众银行参与FISCOBCOS生态建设,一定
基本上我想选择一个节点(div),其中它的子节点(h1,b,h3)包含指定的文本。Childtext1Childtext2...Childtext3我期待的是/html/div/而不是/html/div/h1我在下面有这个,但不幸的是返回了child,而不是div的xpath。expression="//div[contains(text(),'Childtext1')]"doc.xpath(expression)我期待的是/html/div/而不是/html/div/h1那么有没有一种方法可以简单地使用xpath语法来做到这一点? 最佳答案
这个问题在这里已经有了答案:Nokogiri:SelectcontentbetweenelementAandB(3个答案)关闭2年前。我正在从url中抓取文本的div,并想删除具有backtotop类的段落下方的所有内容。我在stackoverflow上看到了一段遍历代码片段,看起来很有希望,但我不知道如何将它合并,所以@el只包含第一个p.backtotop之前的所有内容分区我的代码:@doc=Nokogiri::HTML(open(url))@el=@doc.css("div")[0]end遍历片段:doc=Nokogiri::HTML(code)stop_node=doc.css
我正在尝试为ChefRecipe编写一个库,以简化一些常见的搜索。例如,我希望能够在cookbook/libraries/library.rb中执行类似的操作,然后从同一Recipe中的Recipe中使用它:moduleExampledefself.search_attribute(attribute_name)returnsearch(:nodes,node[attribute_name])endend问题是,在Chef库文件中,node对象或search函数都不可用。似乎可以使用Chef::Search::Query.new().search(...)进行搜索,但我找不到任何可以访
我正在尝试使用Nokogiri来解析带有一些相当古怪的标记的HTML文件。具体来说,我正在尝试获取同时定义了id、多个类和样式的div。标记看起来像这样:titleListofstuff我正在尝试获取里面的问题.我可以毫无问题地获得具有单个id属性的div,但我想不出一种方法让Nokogiri获取具有和两个id类的div。所以这些工作正常:content=@doc.xpath("//div[id='foo']")content=@doc.css('div#foo')但是这些不返回任何东西:content=@doc.xpath("//div[id='bar']")content=@doc
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录查看ES信息查看节点信息查看分片信息实际场景下ES分片及副本数量应该怎么分关于ES的灵活使用查看ES信息查看版本kibana:GET/查看节点信息GET/_cat/nodes?v解释:ip:集群中节点的ip地址;heap.percent:堆内存的占用百分比;ram.percent:总内存的占用百分比,其实这个不是很准确,因为buff/cache和available也被当作使用内存;cpu:cpu占用百分比;load_1m:1分钟内cpu负载;load_5m:5分钟内cpu负载;load_15m:15分钟内cpu负载;node.role:上图的dilmrt代表全部权限master:*代表
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172
Kubernetes(K8s)是一个用于管理容器化应用程序的开源平台,可以帮助开发人员更轻松地部署、管理和扩展应用程序。在Kubernetes中,集群划分是一种重要的概念,可以帮助我们更好地组织和管理集群中的节点和资源。本文将介绍如何使用Kubernetes对集群进行划分,并提供详细的操作示例,希望能够帮助读者更好地了解和使用Kubernetes平台。Node划分Node划分是将集群中的节点按照一定的规则进行划分。在Kubernetes中,可以使用NodeSelector和Affinity机制来实现Node划分。NodeSelectorNodeSelector是一种将Pod调度到符合特定节点标
我有这样的代码:@doc=Nokogiri::HTML(open(url)@doc.xpath(query).eachdo|html|putshtml#howgetcontentofanodeend我如何获取节点的内容而不是像这样: 最佳答案 这是READMEfile中的概要示例为Nokogiri展示了一种使用CSS、XPath或混合的方法:require'nokogiri'require'open-uri'#GetaNokogiri::HTML:Documentforthepagewe’reinterestedin...doc=N