来源:blog.csdn.net/qq_29879799/article/details/105146415
java的stream编程给调试带来了极大的不便,idea 推出了streamtrace功能,可以详细看到每一步操作的关系、结果,非常方便进行调试。
初遇StreamTrace
这里简单将字符串转成它的字符数,并设置断点开启debug模式。
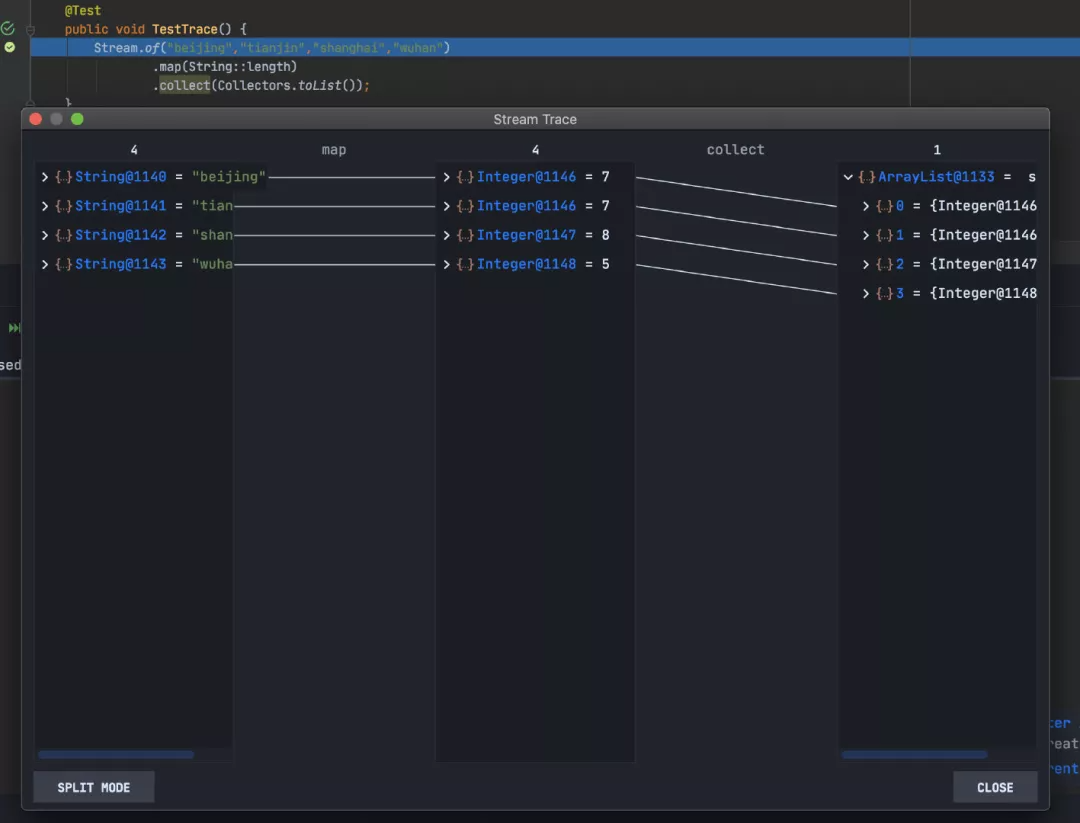
如上图所示,可以看到每一步操作的元素个数、操作的结果、元素转换前后的对应关,非常清晰明了;还可以查看具体的对象内容。
使用StreamTrace
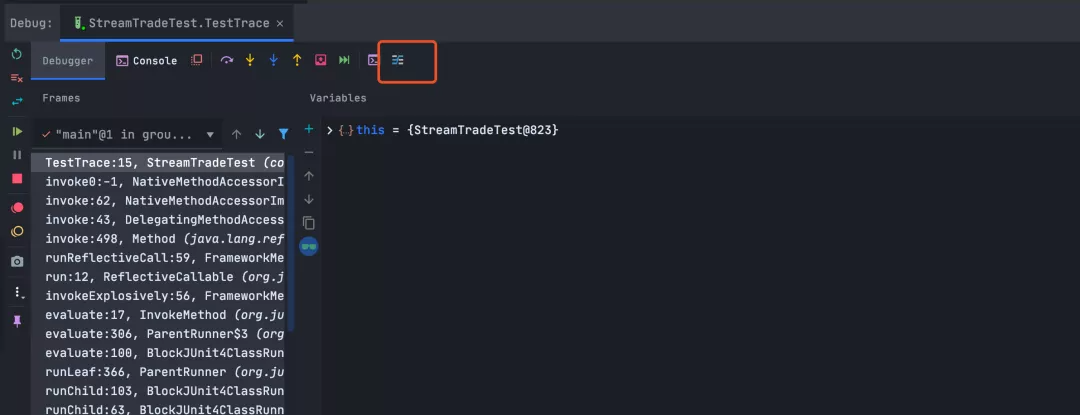
StreamTrace只有在debug模式下才能使用,当在Stream代码上设置断点后,启动debug,点击流按钮,如图所示。
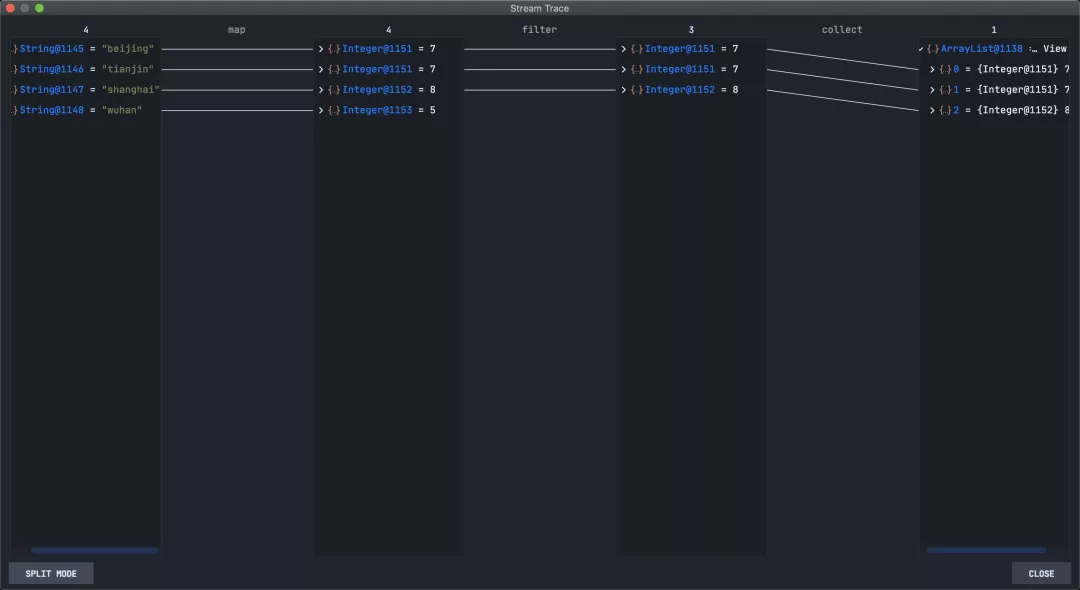
点击后,默认Split 模式显示。
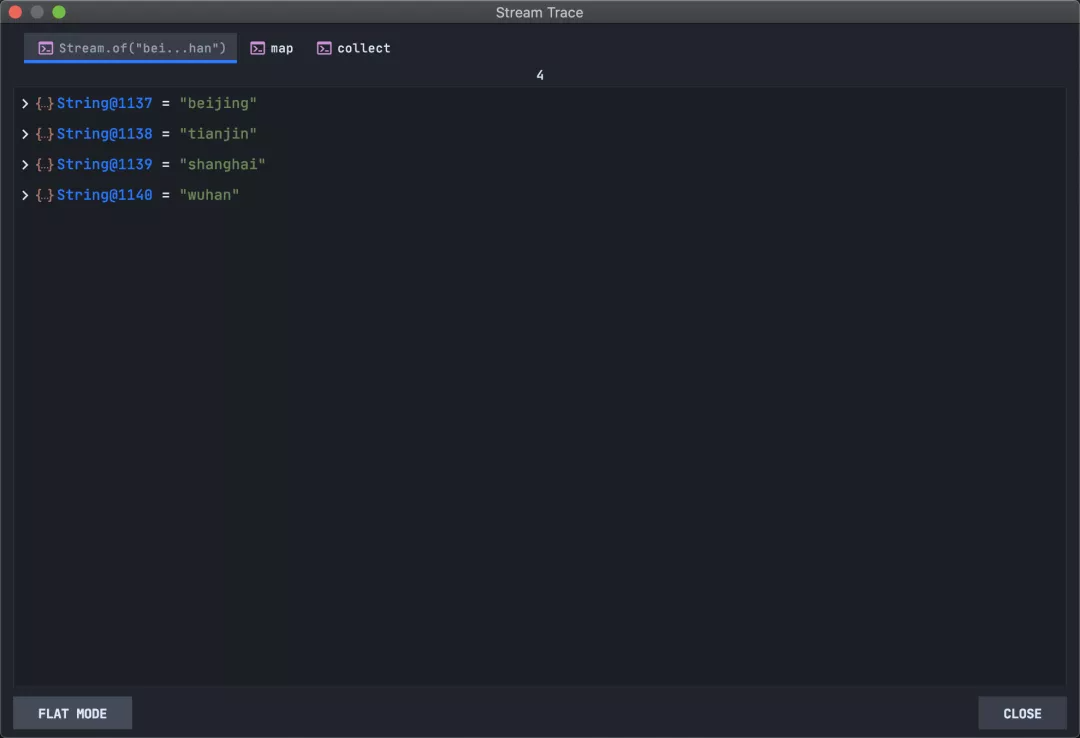
可以点击左下方按钮切换到FlatMode模式,当然也可以再切换回去。
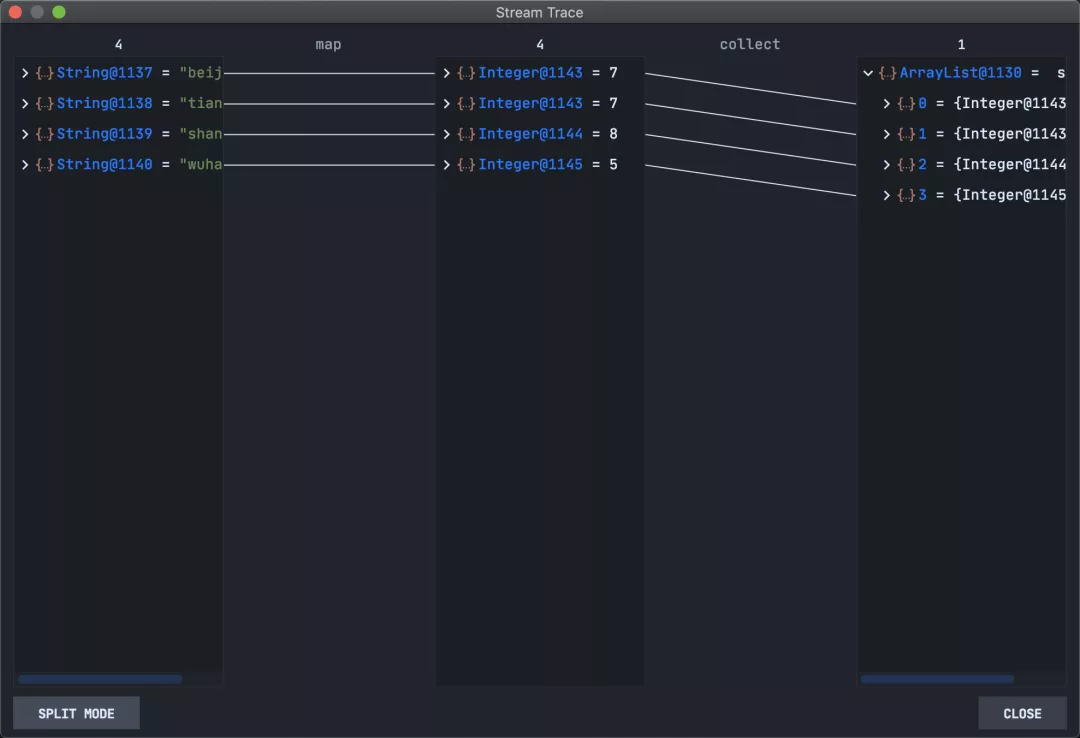
实战演示
这里演示一段字符转长度并过滤长度小于5的stream操作
@Test
public void TestTrace() {
Stream.of("beijing","tianjin","shanghai","wuhan")
.map(String::length)
.filter(e->e>5)
.collect(Collectors.toList());
}
近期热文推荐:
1.1,000+ 道 Java面试题及答案整理(2022最新版)
4.别再写满屏的爆爆爆炸类了,试试装饰器模式,这才是优雅的方式!!
觉得不错,别忘了随手点赞+转发哦!
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下
GivenIamadumbprogrammerandIamusingrspecandIamusingsporkandIwanttodebug...mmm...let'ssaaay,aspecforPhone.那么,我应该把“require'ruby-debug'”行放在哪里,以便在phone_spec.rb的特定点停止处理?(我所要求的只是一个大而粗的箭头,即使是一个有挑战性的程序员也能看到:-3)我已经尝试了很多位置,除非我没有正确测试它们,否则会发生一些奇怪的事情:在spec_helper.rb中的以下位置:require'rubygems'require'spork'
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
使用Ruby1.9.2运行IDE提示说需要gemruby-debug-base19x并提供安装它。但是,在尝试安装它时会显示消息Failedtoinstallgems.Followinggemswerenotinstalled:C:/ProgramFiles(x86)/JetBrains/RubyMine3.2.4/rb/gems/ruby-debug-base19x-0.11.30.pre2.gem:Errorinstallingruby-debug-base19x-0.11.30.pre2.gem:The'linecache19'nativegemrequiresinstall
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
我有:When/^(?:|I)follow"([^"]*)"(?:within"([^"]*)")?$/do|link,selector|with_scope(selector)doclick_link(link)endend我打电话的地方:Background:GivenIamanexistingadminuserWhenIfollow"CLIENTS"我的HTML是这样的:CLIENTS我一直收到这个错误:.F-.F--U-----U(::)failedsteps(::)nolinkwithtitle,idortext'CLIENTS'found(Capybara::Element
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候