性能测试主要是通过压力机不断向服务器施压,找出服务器的性能瓶颈,从而提高系统的健壮性。很多项目都有性能测试的要求,这里主要基于个人性能测试的经验,整理了性能测试基本流程,仅供参考。
在性能测试前,需要提前跟客户确认性能测试的要求,可以从以下几个方面考虑:
| 类型 | 具体内容 | 确认对象 |
| 测试环境 | 提前与客户确认在哪个环境进行性能测试,建议在生产环境或预发布环境上进行。 | 项目经理、研发 |
| 测试时间 | 性能测试期间尽量不要与其他测试项并行,以免影响测试结果。所以需要提前与客户确认性能测试的具体时间范围。 | 项目经理 |
| 压测范围 | 需要与客户、研发沟通压测的接口范围 | 项目经理、研发 |
| 性能指标 | 需要客户、研发提前给出性能测试的性能指标 | 项目经理、研发 |
| 压力机 | 压力机需要提前向客户申请,要求:内网环境压力机,配置不低于4核8G | 项目经理 |
| 监控平台 | 需要提前确认服务器性能监控方式,找运维搭建监控平台或者手动部署监控工具 | 项目经理、运维 |
| 监控服务器列表 | 需要提前确认待监控的服务器列表有哪些 | 项目经理、研发 |
| 接口地址 | 如果是内网环境测试,需要提前提供内网环境,已做好负载均衡的内存地址 | 研发、运维 |
| 数据清理方式 | 压测期间会产生大量的压测数据,需要提前确认所测试环境,是否允许清理数据,以及数据清理的方式 | 项目经理、运维 |
基于前期沟通的压测范围、性能指标等信息,编写压测方案,可以包含以下几个方面:
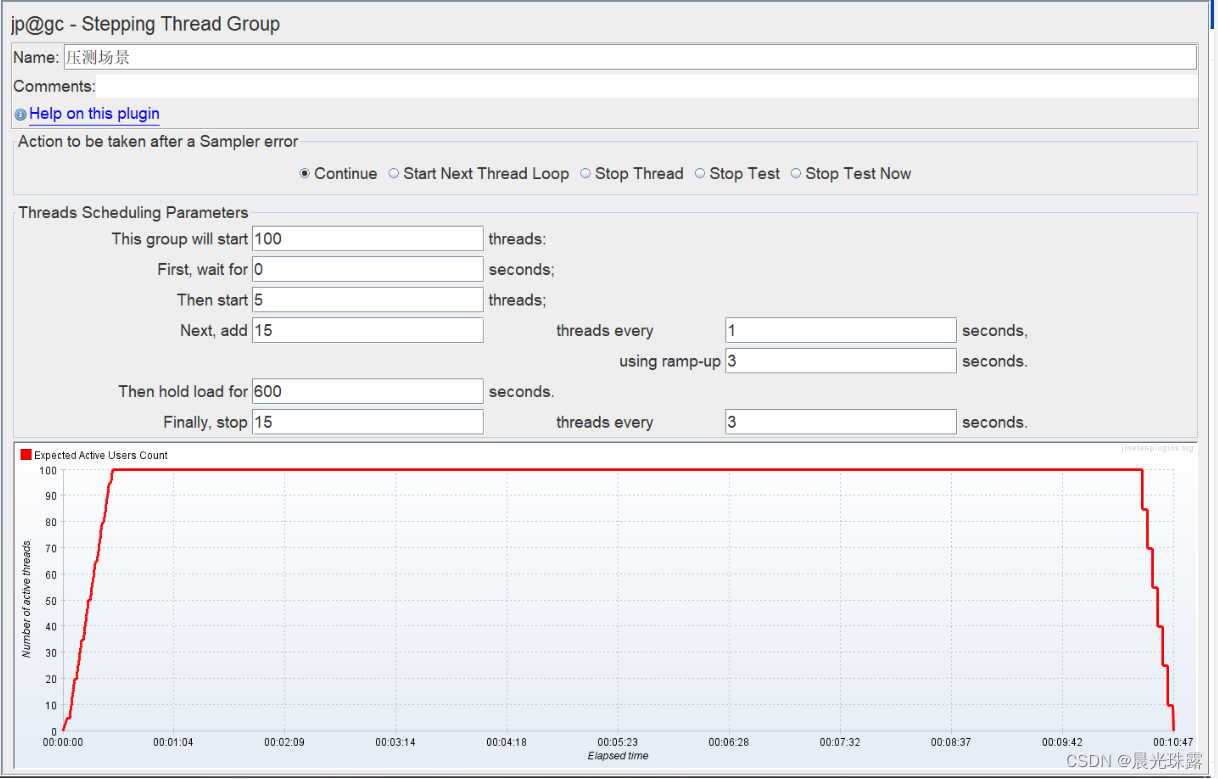
1、线程组
性能测试脚本的线程组建议使用Stepping Thread Group,逐步增加、释放线程,避免线程同时启动。
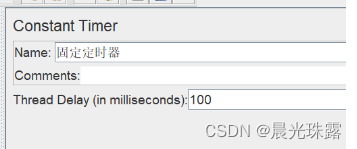
2、增加思考时间
可以根据具体的业务需求,适当的增加思考时间,例如:1s-5s,增加固定定时器。
3、接口比例设置
如果需要不同的接口需要设置不同的比例,可以增加吞吐量控制器来把控不同接口的执行比例。

4、其他注意项
- 接口地址设置内网ip地址,需要运维提前配置好负载均衡
- 非界面模式运行时,可以禁用所有监听器,降低压力机的CPU使用率
- 注释正向流程的日志打印,只保留运行错误时的日志打印
- 各个接口之间尽量独立运行,不要产生参数依赖,以免干扰测试结果
1、压力机权限
需要运维同事帮忙开通压力机的读写权限,或某个文件夹的读写权限,方便执行性能测试。
2、检查压力机配置是否满足要求
cat /proc/cpuinfo 查看CPU信息命令
cat /proc/meminfo 查看内存信息命令3、jdk配置
检查压力机jdb是否配置,如果没有可以参考以下教程配置::Linux系统下安装jdk及环境配置(两种方法)_凉凉的西瓜的博客-CSDN博客_linux配置jdk。
4、jmeter配置
1) 将jmeter工具包拷贝到压力机指定目录中。命令:rz
2)将jmeter工具包解压缩,命令:unzip apache-jmeter-5.2.1.zip
3)执行命令:vim /etc/profile,配置环境变量
在文件末尾追加jmeter配置信息:
export JMETER_HOME=/home/ota/test/tools/jmeter/apache-jmeter-5.2.1
export CLASSPATH=$JMETER_HOME/lib/ext/ApacheJMeter_core.jar:$JMETER_HOME/lib/jorphan.jar:$CLASSPATH
export PATH=$JMETER_HOME/bin:$PATH4)执行命令:source /etc/profile,使环境变量立即生效
5)进入jmeter工具的bin文件夹中,给jmeter文件增加执行的权限,命令:chmod a+x jmeter
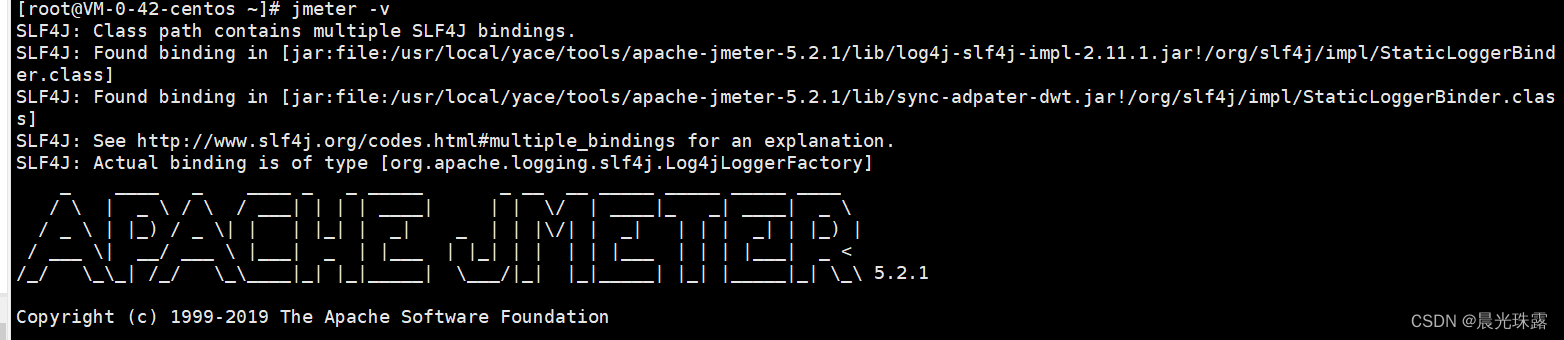
6)检查jmeter是否配置成功,命令:jmeter -v
5、Jmeter运行内存设置
linux环境下,一般运行jmeter工具bin目录中的jmeter,可以提前将jmeter的运行内存设置为压力机整体内存的一半,以免出现jmeter内存不足的现象
1)进入jmeter工具的bin目录中,编辑jmeter文件
命令:vim jmeter
2)搜索关键字:${HEAP,定位到内存所在位置,如果前面存在#,去除#
命令:/${HEAP
3)可以将运行内存的最大值,最小值都设置为压力机内存的一半,比如压力机内存16G,jmeter的运行内存可以设置为8G
: "${HEAP:="-Xms8g -Xmx8g -XX:MaxMetaspaceSize=256m"}"4)保存并退出,重新启动jmeter即可
6、压力机端口数量调整
性能测试前,建议先修改配置文件中配置的端口数量,将支持的端口数量修改为最大,以免端口不足,影响测试结果
修改/etc/sysctl.conf文件:
net.ipv4.tcp_fin_timeout = 30
net.ipv4.ip_local_port_range = 1100 65535
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_max_tw_buckets = 100007、测试资源准备
在压力机上创建对应文件夹,并将测试脚本、依赖jar、基础数据等资源上传到压力机中。
1、小批量压测
先进行小批量的测试,检查脚本在压力机上是否可以正常运行。
2、Jmeter非GUI模式执行
命令行中输入命令:jmeter -n -t xxxx.jmx -l xxx.jtl -e -o /xx/xx/
# 参数说明?
-n 非窗口模式
-t 指定要运行的 Jmeter 测试脚本文件
-l 记录结果文件,每次运行之前,要确保 jtl文件没有同名文件
-r Jmeter.properties文件中指定的所有远程服务器
-e 在脚本运行结束后生成HTML报告
-o 用于存放html报告的目录,每次运行前,要确保所设置的目录为空
3、稳定性测试
稳定性测试时间比较长,jmeter命令需要在后台运行,以免进程被kill。测试时间不超过12小时,不需要后台运行。
1)后台运行命令:nohup jmeter -n -t xxxx.jmx -l xxx.jtl -e -o /xx/xx/
2)查看jmeter进程:ps -ef|grep jmeter
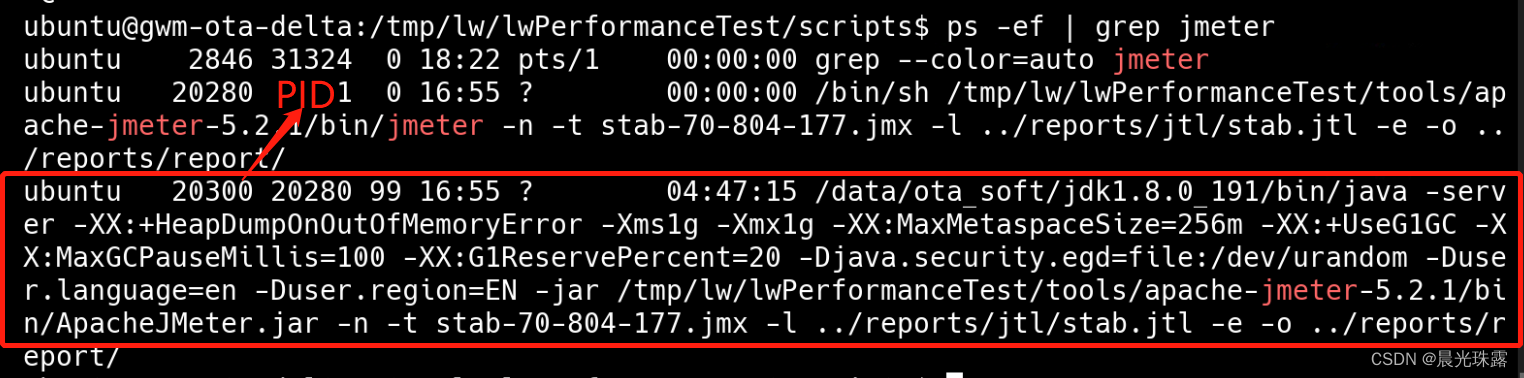
3)如果测试失败,可以手动杀进程:kill -9 pid(jmeter的pid)
测试过程中,建议实时监控压力机、服务器的性能指标,观察性能测试是否正常
1、jmetr结果查看
方式一:直接查看命令执行窗口中生产的聚合报告,观察性能指标是否满足要求
方式二:进入jmeter的执行路径,查看jmeter日志,命令:tail -f -n 100 jmter.log

2、压力机资源监督
可以通过top命令实时观察压力机的资源消耗情况。
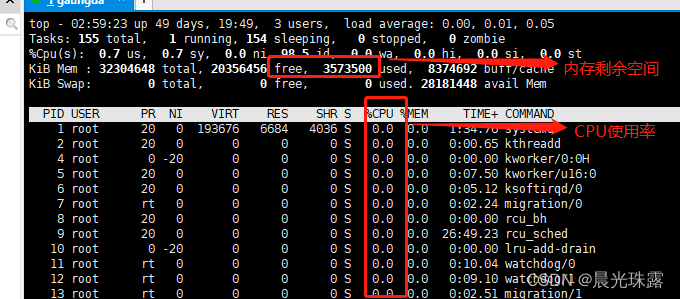
3、服务器资源监控
如果公司已于监控平台,可以打开监控平台,实时监控服务器的资源消耗
1)登录性能监控平台,选择需要监控的服务器
2)筛选测试时间段的性能指标,截图保存
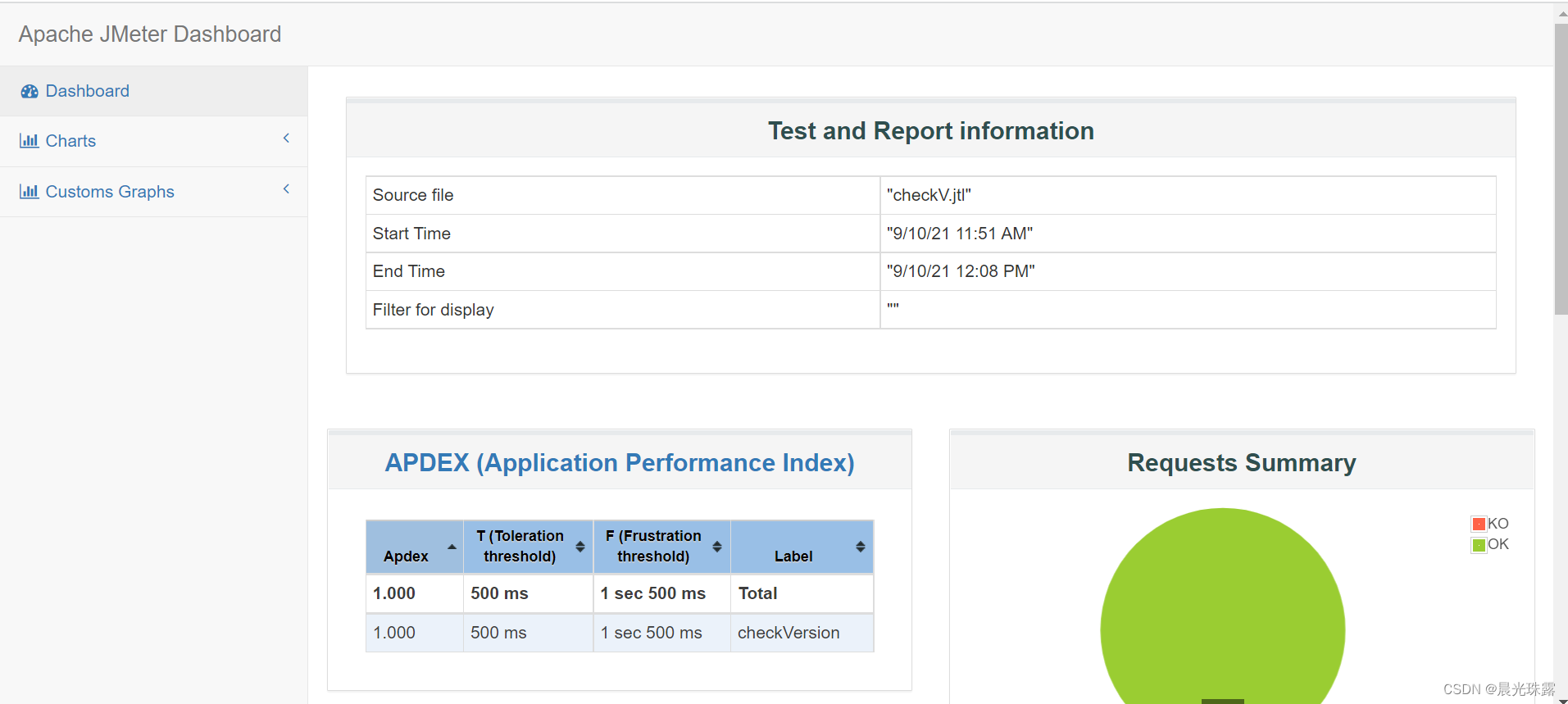
4、jmeter聚合报告
1)将非GUI模式下-o指定目录中的所有数据打包
命令:zip -r xxx.zip /xx/xx/*
2)将打包的zip拉取到本地保存
命令:sz xxx.zip
3)将jmeter聚合报告解压缩,打开index.html文件,查看聚合报告
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
我有:When/^(?:|I)follow"([^"]*)"(?:within"([^"]*)")?$/do|link,selector|with_scope(selector)doclick_link(link)endend我打电话的地方:Background:GivenIamanexistingadminuserWhenIfollow"CLIENTS"我的HTML是这样的:CLIENTS我一直收到这个错误:.F-.F--U-----U(::)failedsteps(::)nolinkwithtitle,idortext'CLIENTS'found(Capybara::Element