目录

链表的类型多种多样,具体可以分为:
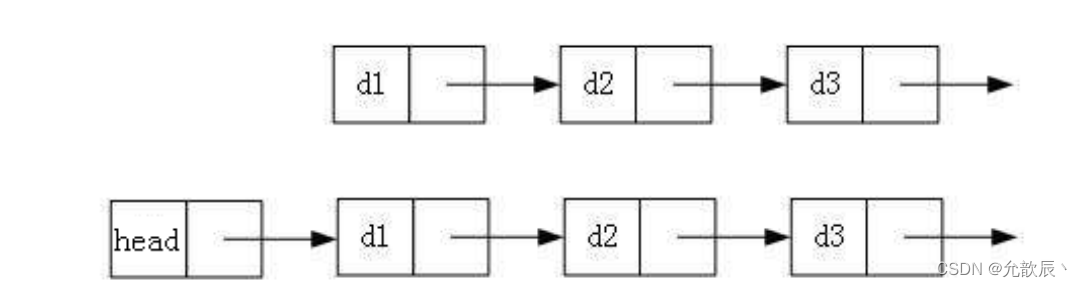
1.带头结点的链表和不带头结点的链表
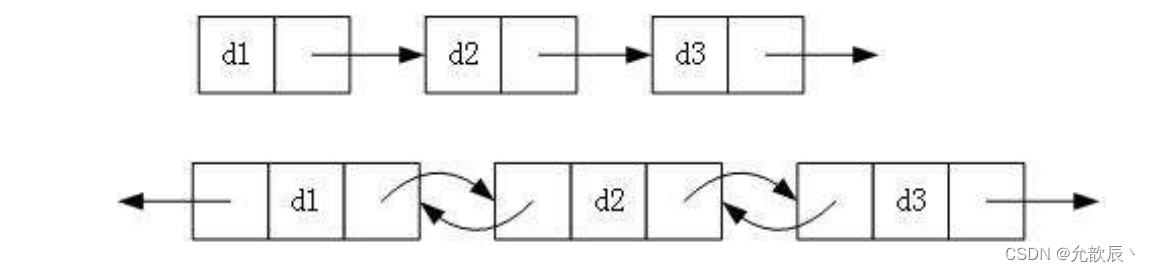
2.单向链表和双向链表
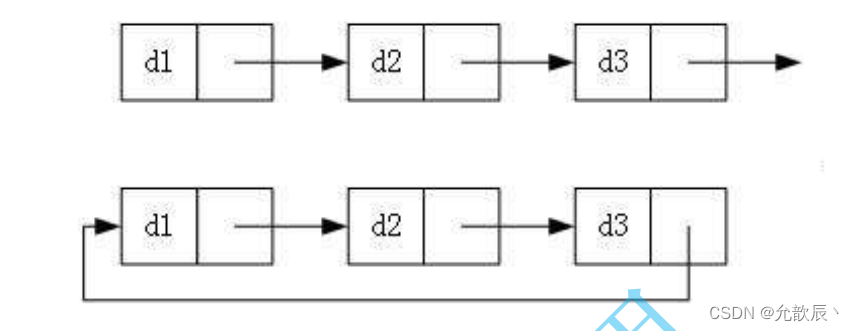
 3.循环的和非循环的
3.循环的和非循环的
在实现具体的方法之前,我们先定义一个接口,之后的这些链表都将实现这些接口,实现这些接口内的方法,主要包含了一些常用的CRUD方法.这个接口我们使用了泛型,之后的链表类也将继承这个接口的泛型,元素的类型就是泛型的类型
public interface SeqList<E> {
// 在线性表中的最后插入值为element的新元素
void addLast(E element);
// 在线性表的前边插入新元素,插入后的元素下标为index
void addFirst(E element);
//在索引为index处插入值为element的结点
void add(int index, E element);
// 删除当前线性表中索引为index的元素,返回删除的元素值
E removeByIndex(int index);
// 删除当前线性表中第一个值为element的元素
void removeByValue(E element);
// 删除当前线性表中所有值为element的元素
void removeAllValue(E element);
// 将当前线性表中index位置的元素替换为element,返回替换前的元素值
E set(int index, E element);
// 得到下标为index结点的值
E get(int index);
// 查询链表内是否包含element的结点
boolean contains(E element);
// 查询当前线性表中第一个值为element的下标
int indexOf(E element);
}我们这里定义了一个内部类Node,为单向链表的结点类,同时单向链表的属性包含了头结点的引用信息和链表结点个数的定义
public class SingleLinkedList<E> implements SeqList<E> {
private Node head; //第一个结点的位置
private int size; //链表结点的个数
private class Node {
E val;
Node next;
public Node(E val) {
this.val = val;
}
}
@Override
public void addLast(E element) {
}
@Override
public void addFirst(E element) {
}
@Override
public void add(int index, E element) {
}
@Override
public E removeByIndex(int index) {
return null;
}
@Override
public void removeByValue(E element) {
}
@Override
public void removeAllValue(E element) {
}
@Override
public E set(int index, E element) {
return null;
}
@Override
public E get(int index) {
return null;
}
@Override
public boolean contains(E element) {
return false;
}
@Override
public int indexOf(E element) {
return 0;
}
} @Override
public void addFirst(E element) {
//产生一个值为element的结点
Node newNode = new Node(element);
//当前结点的指向头结点
newNode.next = head;
//更新head的引用,将其指向新节点
head = newNode;
size++;
} @Override
public void addLast(E element) {
Node temp = head;
if (head == null) {
head = new Node(element);
size++;
return;
}
while (temp.next != null) {
temp = temp.next;
}
temp.next = new Node(element);
size++;
}记住:插入和删除的关键是找到插入和删除位置的前驱节点
@Override
public void add(int index, E element) {
//边界的判断
if (!rangeCheck(index)) {
throw new IllegalArgumentException("get index illegal!");
}
//头插
if (index == 0) {
addFirst(element);
return;
}
//尾插
if (index == size) {
addLast(element);
return;
}
Node temp = head;
//找到插入位置的前驱节点
for (int i = 0; i < index - 1; ++i) {
temp = temp.next;
}
Node newNode = new Node(element);
newNode.next = temp.next;
temp.next = newNode;
size++;
}
//index的检查
private boolean rangeCheck(int index) {
//如果插入的位置索引不合理,返回false
if (index < 0 || index > size) {
return false;
}
return true;
}
@Override
public E removeByIndex(int index) {
//边界的判断
if (!rangeCheck(index)) {
throw new IllegalArgumentException("get index illegal!");
}
//判断头结点的删除
if (index == 0) {
Node node = head;
head = head.next;
node.next = null;
size--;
return node.val;
}
//除头结点的输出,找到要删除位置的前驱节点
Node temp = head;
for (int i = 0; i < index - 1; ++i) {
temp = temp.next;
}
Node node = temp.next;
temp.next = temp.next.next;
node.next = null;
size--;
return node.val;
} @Override
public void removeByValue(E element) {
if (head == null)
return;
//删除的恰好是头结点
if (head.val.equals(element)) {
head = head.next;
size--;
return;
}
//删除的是其他节点
Node temp = head;
while (temp.next != null) {
if (temp.next.val.equals(element)) {
temp.next = temp.next.next;
size--;
return;
}
temp = temp.next;
}
//没有要删除值的结点
System.out.println("当前链表中不存在值为:" + element + "的结点");
} @Override
public void removeAllValue(E element) {
if (head == null) {
return;
}
//删除的恰好是头结点
while (head != null && head.val.equals(element)) {
head = head.next;
size--;
}
//链表全部删完了
if (head == null) {
return;
}
//删除的是其他节点
Node temp = head;
while (temp.next != null) {
if (temp.next.val.equals(element)) {
temp.next = temp.next.next;
size--;
} else {
//只有后继节点不是element的时候才能移动
temp = temp.next;
}
}
}
@Override
public E set(int index, E element) {
//边界的判断
if (!rangeCheck(index)) {
throw new IllegalArgumentException("get index illegal!");
}
Node temp = head;
//找到索引为index的结点
for (int i = 0; i < index; ++i) {
temp = temp.next;
}
//保存结点的旧值
E oldValue = temp.val;
//将索引为index结点的值更换为element
temp.val = element;
return oldValue;
} @Override
public E get(int index) {
//边界的判断
if (!rangeCheck(index)) {
throw new IllegalArgumentException("get index illegal!");
}
Node temp = head;
//找到索引为index的结点
for (int i = 0; i < index; ++i) {
temp = temp.next;
}
return temp.val;
} @Override
public boolean contains(E element) {
Node temp = head;
while (temp != null) {
if (temp.val.equals(element)) {
return true;
}
temp = temp.next;
}
return false;
} @Override
public int indexOf(E element) {
//头结点为空
if (head == null)
return -1;
Node temp = head;
for (int i = 0; i < size; ++i) {
if (temp.val.equals(element)) {
return i;
}
temp = temp.next;
}
//表示没有找到值为element的结点的索引
return -1;
} @Override
public String toString() {
Node temp = head;
StringBuffer sb = new StringBuffer();
while (temp != null) {
sb.append(temp.val + "->");
temp = temp.next;
}
sb.append("NULL");
return sb.toString();
}
带头结点的单链表有一个虚拟头结点,头结点里面存储的值并不是链表中真实的值,没有实际意义,只是作为一个头结点的存在,同时size的值不会因为虚拟头结点的存在加一.
public class SingleLinkedListWithHead<E> implements SeqList<E> {
private class Node {
E val;
Node next;
public Node(E val) {
this.val = val;
}
}
private Node dummyHead = new Node(null);
int size = 0;
@Override
public void addFirst(E element) {
}
@Override
public void addLast(E element) {
}
@Override
public void add(int index, E element) {
}
@Override
public E removeByIndex(int index) {
return null;
}
@Override
public void removeByValue(E element) {
}
@Override
public void removeAllValue(E element) {
}
@Override
public E set(int index, E element) {
return null;
}
@Override
public E get(int index) {
return null;
}
@Override
public boolean contains(E element) {
return false;
}
@Override
public int indexOf(E element) {
return 0;
}
}
@Override
public void addFirst(E element) {
Node node = new Node(element);
node.next = dummyHead.next;
dummyHead.next = node;
size++;
} @Override
public void addLast(E element) {
Node temp = dummyHead;
for (int i = 0; i < size; ++i) {
temp = temp.next;
}
Node node = new Node(element);
temp.next = node;
size++;
} @Override
public void add(int index, E element) {
//边界的判断
if (!rangeCheck(index)) {
throw new IllegalArgumentException("get index illegal!");
}
if (index == 0) {
addFirst(element);
return;
}
if (index == size) {
addLast(element);
return;
}
Node temp = dummyHead;
Node node = new Node(element);
for (int i = 0; i < index; ++i) {
temp = temp.next;
}
node.next = temp.next;
temp.next = node;
size++;
} @Override
public E removeByIndex(int index) {
//边界的判断
if (!rangeCheck(index)) {
throw new IllegalArgumentException("get index illegal!");
}
Node temp = dummyHead;
for (int i = 0; i < index; ++i) {
temp = temp.next;
}
Node node = temp.next;
temp.next = temp.next.next;
return node.val;
} @Override
public void removeByValue(E element) {
Node temp = dummyHead;
while (temp.next != null) {
if (temp.next.val.equals(element)) {
temp.next = temp.next.next;
size--;
return;
}
temp = temp.next;
}
System.out.println("当前链表中不存在值为:" + element + "的结点");
} @Override
public void removeAllValue(E element) {
Node temp = dummyHead;
while (temp.next != null) {
if (temp.next.val.equals(element)) {
temp.next = temp.next.next;
size--;
} else {
temp = temp.next;
}
}
}这里不对其他操作进行描述,因为大致方法和不带头结点的单链表的操作一致
递归方式主要实现的是插入操作和删除操作,它的结构和不带头结点的单链表的结构一样
//在索引值为index处插入val的结点
public void add(int index, int val) {
head = addInternal(head, index, val);
}
private Node addInternal(Node head, int index, int val) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("不合法");
}
//头插
if (index == 0) {
Node node = new Node(val);
node.next = head;
head = node;
size++;
return head;
}
//index不在头结点插入
head.next = addInternal(head.next, index - 1, val);
return head;
} //正序打印
public void print(Node head) {
if (head == null) {
System.out.print("NULL");
return;
}
System.out.print(head.val + "->");
print(head.next);
} //逆序打印
public void printReverse(Node head) {
if (head == null) {
return;
}
printReverse(head.next);
if (head == this.head) {
System.out.print(head.val + "->NULL");
} else {
System.out.print(head.val + "->");
}
}力扣:力扣
public ListNode removeElements(ListNode head, int val) {
if (head == null)
return null;
head.next = removeElements(head.next, val);
return head.val == val ? head.next : head;
}力扣:力扣
public ListNode deleteDuplicates(ListNode head) {
if (head == null || head.next == null) {
return head;
}
head.next = deleteDuplicates(head.next);
return head.val == head.next.val ? head.next : head;
}力扣:力扣
解法一:
public ListNode deleteDuplicates(ListNode head) {
if (head == null || head.next == null) {
return head;
}
if (head.val != head.next.val) {
head.next = deleteDuplicates(head.next);
return head;
} else {
//头结点就是重复的结点
while (head.next != null && head.val == head.next.val) {
head = head.next;
}
head = deleteDuplicates(head.next);
return head;
}
}解法二:
public ListNode deleteDuplicates(ListNode head) {
if(head==null||head.next==null){
return head;
}
if(head.val!=head.next.val){
head.next=deleteDuplicates(head.next);
return head;
}else{
//头结点就是重复的结点
ListNode cur=head.next;
while(cur!=null&&cur.val==head.val){
cur=cur.next;
}
return deleteDuplicates(cur);
}
}在这里不做细致的介绍
public class DoubleLinkedList<E> implements SeqList<E> {
private class DoubleNode {
E val;
DoubleNode pre;
DoubleNode next;
public DoubleNode(E val) {
this.val = val;
}
public DoubleNode(E val, DoubleNode pre, DoubleNode next) {
this.val = val;
this.pre = pre;
this.next = next;
}
}
private DoubleNode head;
private DoubleNode tail;
private int size = 0;
//尾插法
@Override
public void addLast(E element) {
}
@Override
public void addFirst(E element) {
}
//找到索引为index的位置的结点
private DoubleNode node(int index) {
return null;
}
@Override
public void add(int index, E element) {
}
@Override
public E removeByIndex(int index) {
return null;
}
@Override
public void removeByValue(E element) {
}
@Override
public void removeAllValue(E element) {
}
@Override
public E set(int index, E element) {
return null;
}
@Override
public E get(int index) {
return null;
}
@Override
public boolean contains(E element) {
return false;
}
@Override
public int indexOf(E element) {
return 0;
}
}
@Override
public void addFirst(E element) {
DoubleNode node = new DoubleNode(element);
if (tail == null) {
tail = node;
} else {
head.pre = node;
node.next = head;
}
head = node;
size++;
} //尾插法
@Override
public void addLast(E element) {
DoubleNode node = new DoubleNode(element);
if (head == null) {
head = node;
} else {
tail.next = node;
node.pre = tail;
}
tail = node;
size++;
} //找到索引为index的位置的结点
private DoubleNode node(int index) {
DoubleNode result = null;
if (index < (size >> 1)) {
result = head;
for (int i = 0; i < index; ++i) {
result = result.next;
}
} else {
result = tail;
for (int i = size - 1; i > index; --i) {
result = result.pre;
}
}
return result;
}
private boolean rangeCheck(int index) {
if (index < 0 || index > size) {
return false;
}
return true;
}
@Override
public void add(int index, E element) {
if (!rangeCheck(index)) {
throw new IllegalArgumentException("illegal index!!!");
}
if (index == 0) {
addFirst(element);
}
if (index == size) {
addLast(element);
}
DoubleNode pre = node(index - 1);
DoubleNode next = pre.next;
DoubleNode node = new DoubleNode(element, pre, next);
pre.next = node;
next.pre = node;
size++;
} //在当前链表中删除node结点
private DoubleNode unlink(DoubleNode node) {
DoubleNode pre = node.pre;
DoubleNode next = node.next;
// 先处理左半区域
if (pre == null) {
this.head = next;
} else {
node.pre = null;
pre.next = next;
}
// 在处理右半区域
if (next == null) {
this.tail = pre;
} else {
node.next = null;
next.pre = pre;
}
size--;
return node;
}
@Override
public E removeByIndex(int index) {
if (!rangeCheck(index)) {
throw new IllegalArgumentException("illegal index!!");
}
DoubleNode node = node(index);
return unlink(node).val;
} @Override
public void removeByValue(E element) {
DoubleNode node = head;
for (int i = 0; i < size; i++) {
if (node.val.equals(element)) {
unlink(node);
return;
}
node = node.next;
}
} @Override
public void removeAllValue(E element) {
DoubleNode node = head;
// 因为每次unlink之后都会修改size的值,但是删除所有元素,
// 要把所有链表节点全部遍历一遍
int length = this.size;
for (int i = 0; i < length; i++) {
DoubleNode next = node.next;
if (node.val.equals(element)) {
unlink(node);
}
node = next;
}
}我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我在用Ruby执行简单任务时遇到了一件奇怪的事情。我只想用每个方法迭代字母表,但迭代在执行中先进行:alfawit=("a".."z")puts"That'sanalphabet:\n\n#{alfawit.each{|litera|putslitera}}"这段代码的结果是:(缩写)abc⋮xyzThat'sanalphabet:a..z知道为什么它会这样工作或者我做错了什么吗?提前致谢。 最佳答案 因为您的each调用被插入到在固定字符串之前执行的字符串文字中。此外,each返回一个Enumerable,实际上您甚至打印它。试试
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.