一.pytest-html基本语法
1.安装:pip install pytest-html
2.查看版本:pip show pytest-html
3.生成测试报告基本语法:
语法一:pytest --html=生成报告的url 运行用例的.py文件
语法二:pytest --html=生成报告的url --self-contained-html 运行用例的.py文件
二.实例
1.创建一个test_pytestHtml.py文件,编写几条用例(忽略警告)
2.在Terminal运行命令:pytest --html=生成报告的url 运行用例的.py文件,运行成功后,这个时候我们去

生成报告的url下可以看见生成两个文件,一个是我们生成的html报告,另一个是assets文件,里面存放的是
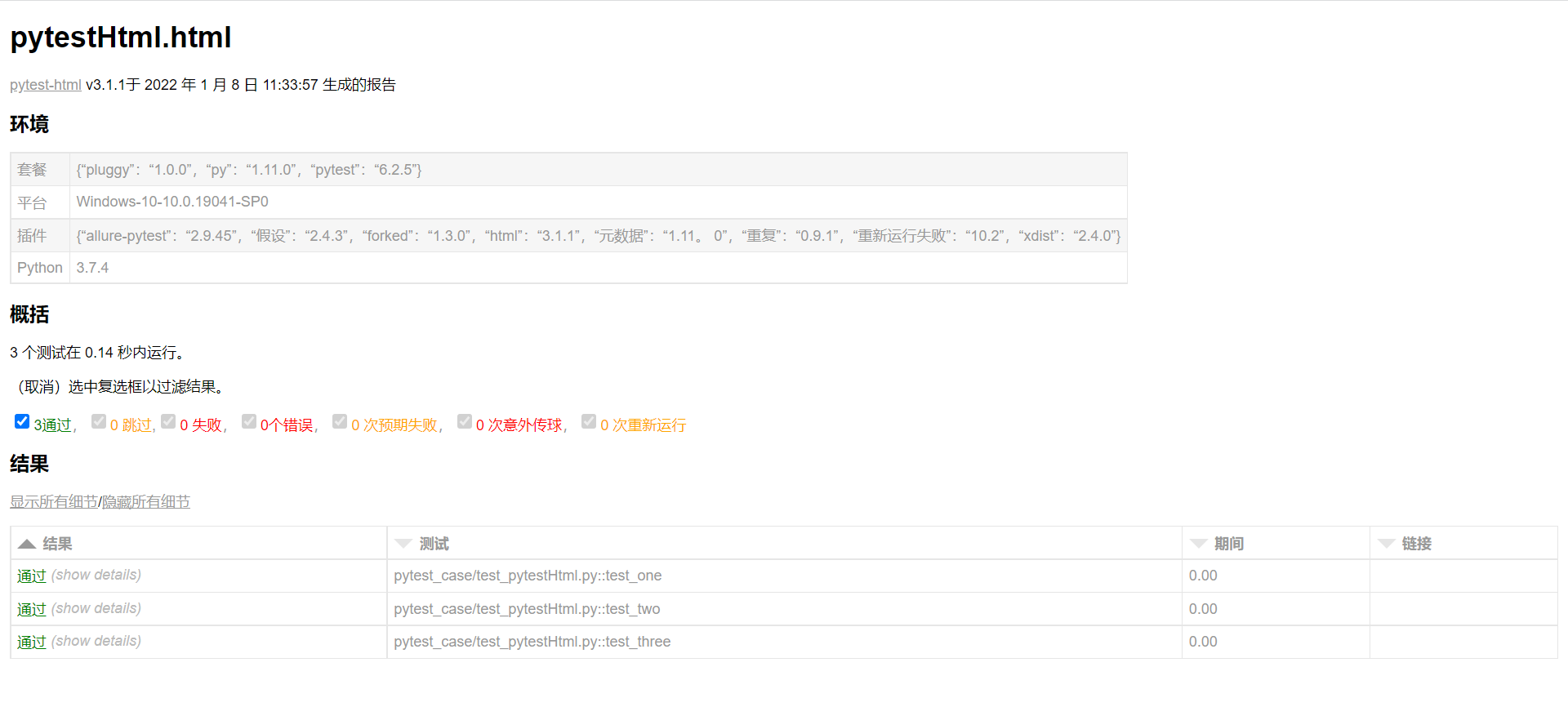
css文件,打开素材的html报告后可以看见用例的执行情况
3.我们再在Terminal运行命令:pytest --html=生成报告的url --self-contained-html 运行用例的.py文件,
同样运行成功后,我们去看下生成的文件,发现只有html生成,并没有assets文件,这是因为css语法
写在了html文件中,没有单独放出来。所以方便以后报告的发送,建议使用第二中语法。
三.修改生成的测试报告(挂钩用法见pytest官方:https://docs.pytest.org/en/latest/reference/reference.html#hooks)
1.环境的修改
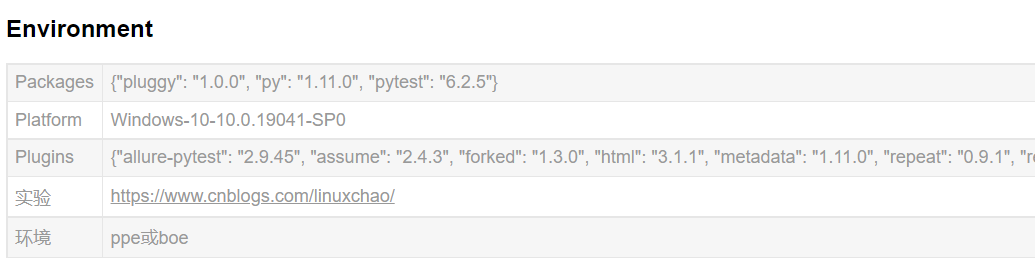
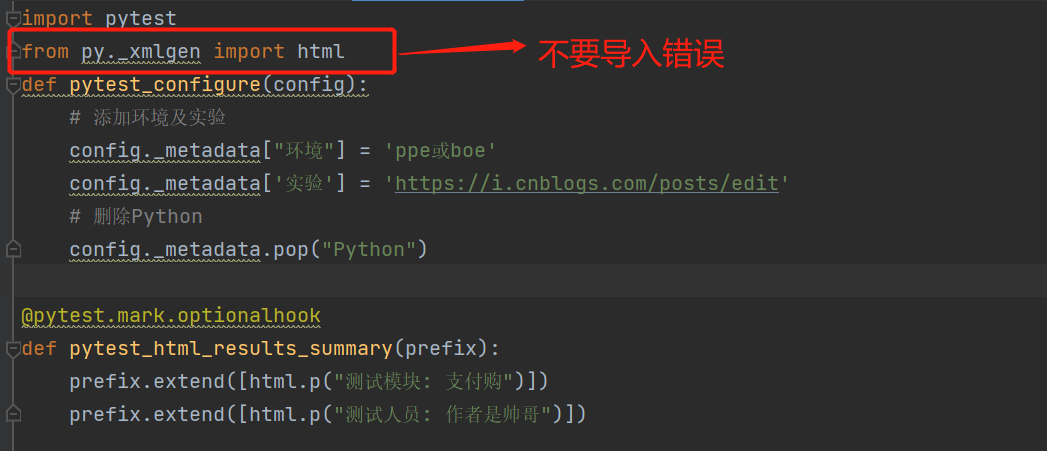
我们可以看到在html中248行,环境是以表格的形式呈现出来的,如果我们想删除某些默认环境或者添加自

己想要的环境,可在根目录下创建conftest.py文件,如下图,pytest_configure(config): 许插件和conftest文

件执行初始配置。我在再来重新生成html报告可以看见我们在Environment下修改的内容
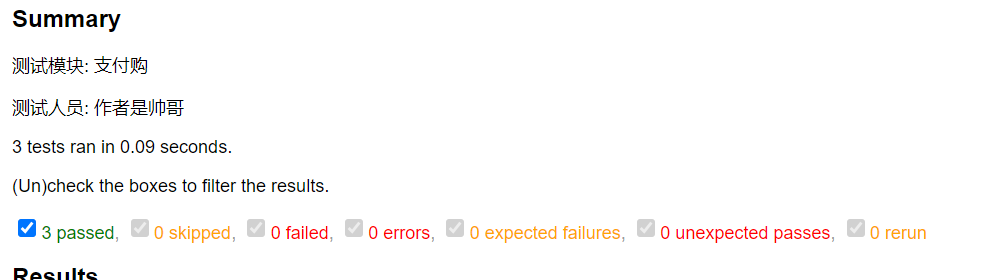
2.概括的修改
可以看到源代码中264行表示的是概括,但默认的内容只有用例总数和运行时间,如果我们想要增加自己想要的

信息模块,可在conftest.py下编写函数,再次运行生成html文件就可看见需要的内容了
3.标题的修改
同样在conftest文件下编写pytest_html_report_title函数,如下

一.环境配置
1.下载jdk配置java运行环境,下载地址:https://www.oracle.com/java/technologies/downloads/#jdk18-windows
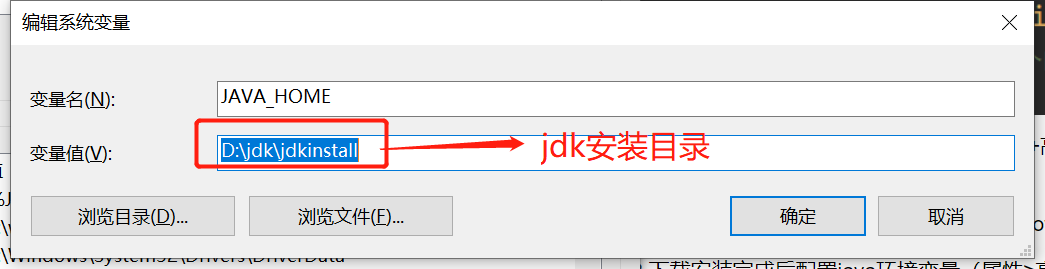
2.下载安装完成后配置java环境变量(属性>高级设置>环境变量>新建),添加JAVA_HOME。
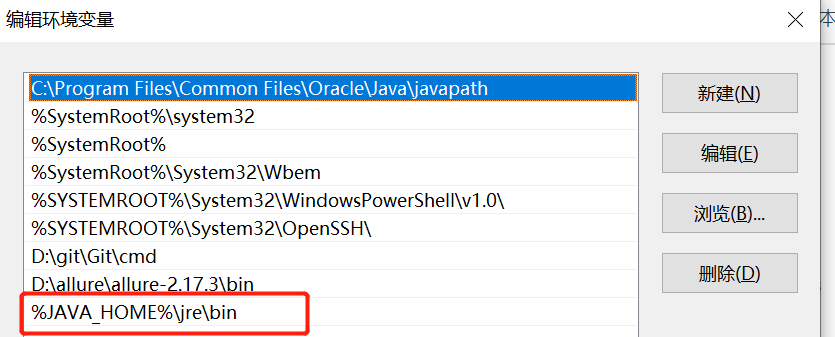
在path下里添加:%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin
3.配置完成后可在dos窗口输入javac,java -version,能输出版本号及相关指令即安装配置成功
4.下载allure工具:https://repo.maven.apache.org/maven2/io/qameta/allure/allure-commandline/,下载成功
后配置环境变量,path下添加allure的bin文件所在目录
5.配置完成在dos创建输入allure有相关内容时即安装成功
6.安装allure-pytest工具,打开你使用的编程工具,这里以pycharm为例,在Terminal输入pip install allure-pytest
二.allure报告的生成指令
1.生成json文件:pytest -q --alluredir=生成json文件的路径 需要运行的case路径(说明:-q简要输出)
2.将生成的json文件转出html格式
(1)指定路径生成html报告:allure generate -o 生成html报告的路径 json文件路径
(2)默认路径生成html报告:allure generate -clear json文件路径(说明:默认路径
为allure-report,clear清空该路径原有的报告)
(3)open及serve用法
serve:allure serve -o 生成html报告的路径 json文件路径(说明:与generater
不同的是,serve生成html后会自动在浏览器打开该报告)
open:allure open -h ip地址 html路径(说明:打开生成的html报告)
注:serve和open运行时会自动打开一个java进程,且只能手动关闭,因此多次使用
serve和open会增加内存消耗

三.allure报告的用法(本次介绍下面几种常用的allure方法)
| 方法 | 说明 |
| @allure.epic() | 一级类目 |
| @allure.feature() | 二级类目 |
| @allure.story() | 三级类目 |
| @allure.title() | 用例标题 |
| @allure.testcase() | case地址 |
| @allure.issue() | bug地址 |
| @allure.description() | case描述 |
| @allure.step() | case步骤 |
| @allure.severity() | case等级 |
| @allure.link() | 链接 |
1.@allure.epic(),allure.feature(),allure.story()的使用
(1)创建一个test.two.py文件,写法如下
import allure
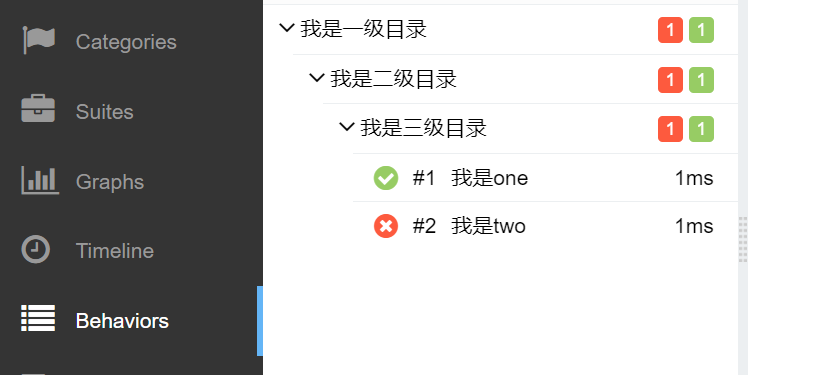
@allure.epic("我是一级目录") @allure.feature("我是二级目录") @allure.story("我是三级目录") class TestDome: def test_one(self): print("我是test_one") assert True def test_two(self): print("我是test_two") assert False
(2)生成json文件:pytest --alluredir=./report/2022-5-22 testcase/test_two.py
(3)将生成的json文件转出html:allure generate -o ./allure-report/2022-5-22 ./report/2022-5-22
此时我们可以看见allrue-report目录下有个2022-5-22/index.html,打开后在Behaviors下可看见运行case

2.@allure.title()的使用
(1)从上面可以看出每条case的标题都是函数名字(如:test_one,test_two),我们可以用title修改默认标题
class TestDome:
@allure.title("我是one")
def test_one(self):
print("我是test_one")
assert True
@allure.title("我是two")
def test_two(self):
print("我是test_two")
assert False
(2)运行后的结果
3.@allure.testcase(),@allure.issue(),@allure.link()用法
(1)allure作用与class上,那么该class下所有的函数都会被定义到,如果allure作用于
每个函数上,那么只对该函数生效
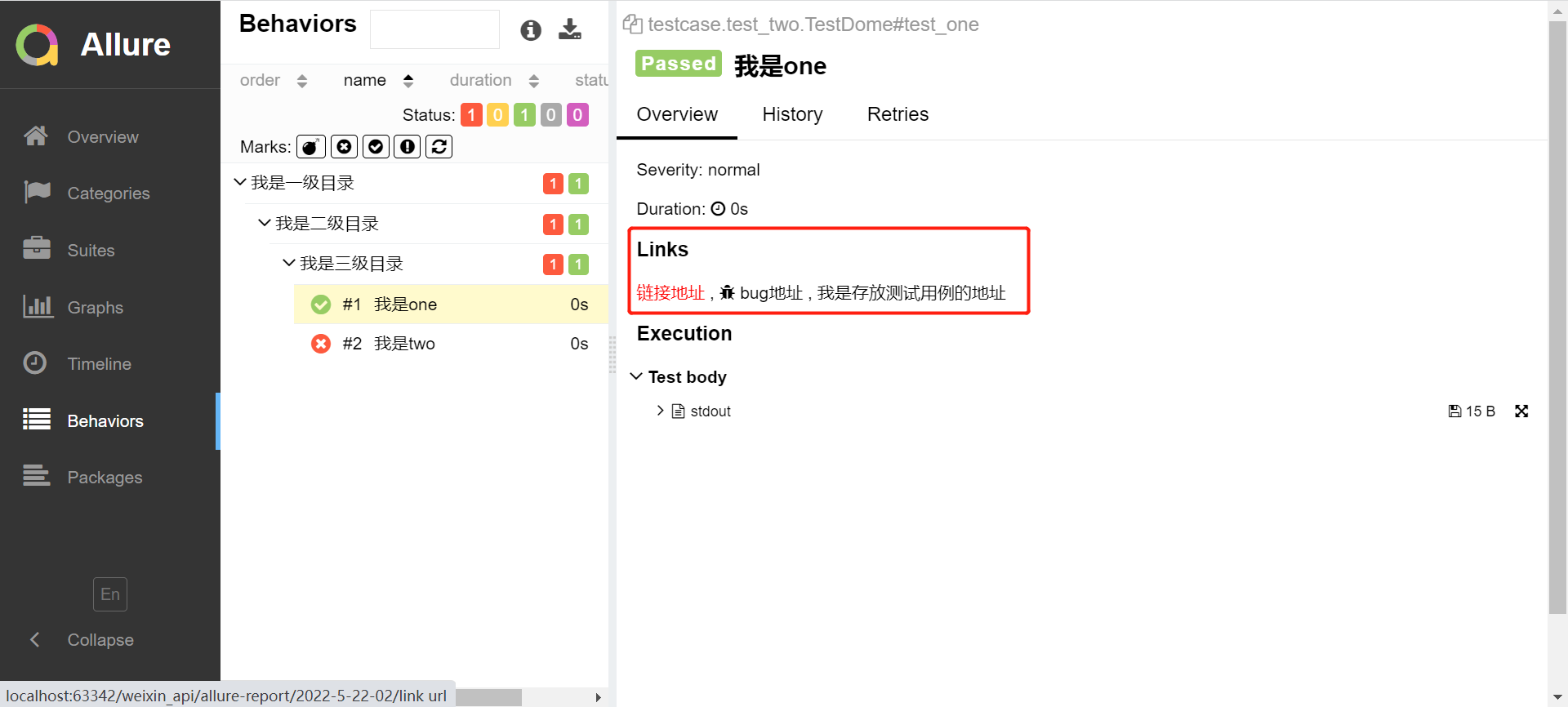
@allure.testcase("path url", name="我是存放测试用例的地址")
@allure.issue("bug url", name="bug地址")
@allure.link("link url", name="链接地址")
class TestDome:
@allure.title("我是one")
def test_one(self):
print("我是test_one")
assert True
@allure.title("我是two")
def test_two(self):
print("我是test_two")
assert False
(2)运行后的结果,可以看出case右侧多出links模块
4.@allure.description()用法
(1)用法一:使用description编写case描述
import pytest
import allure
@allure.epic("我是一级目录")
@allure.feature("我是二级目录")
@allure.story("我是三级目录")
@allure.testcase("path url", name="我是存放测试用例的地址")
@allure.issue("bug url", name="bug地址")
@allure.link("link url", name="链接地址")
class TestDome:
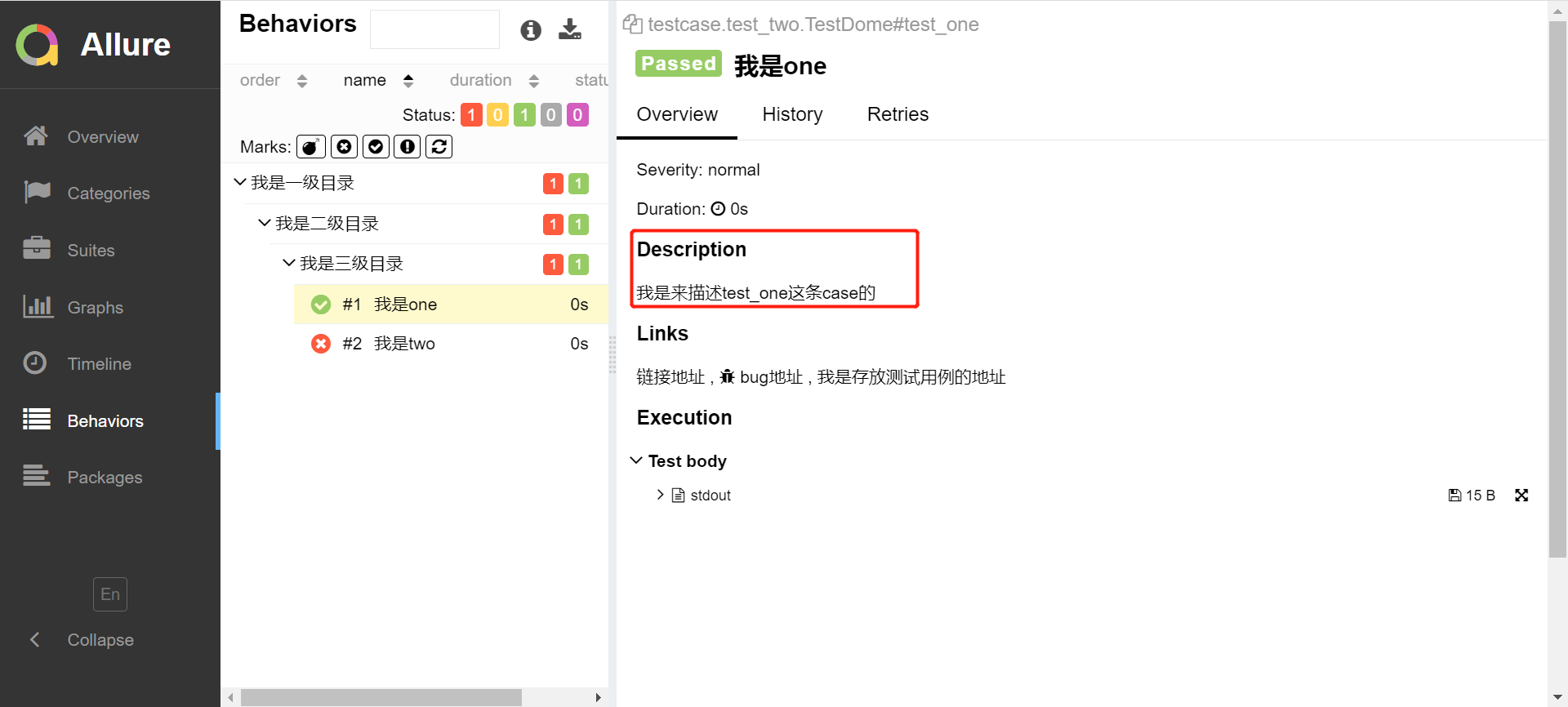
@allure.description("我是来描述test_one这条case的")
@allure.title("我是one")
def test_one(self):
print("我是test_one")
assert True
@allure.title("我是two")
def test_two(self):
print("我是test_two")
assert False
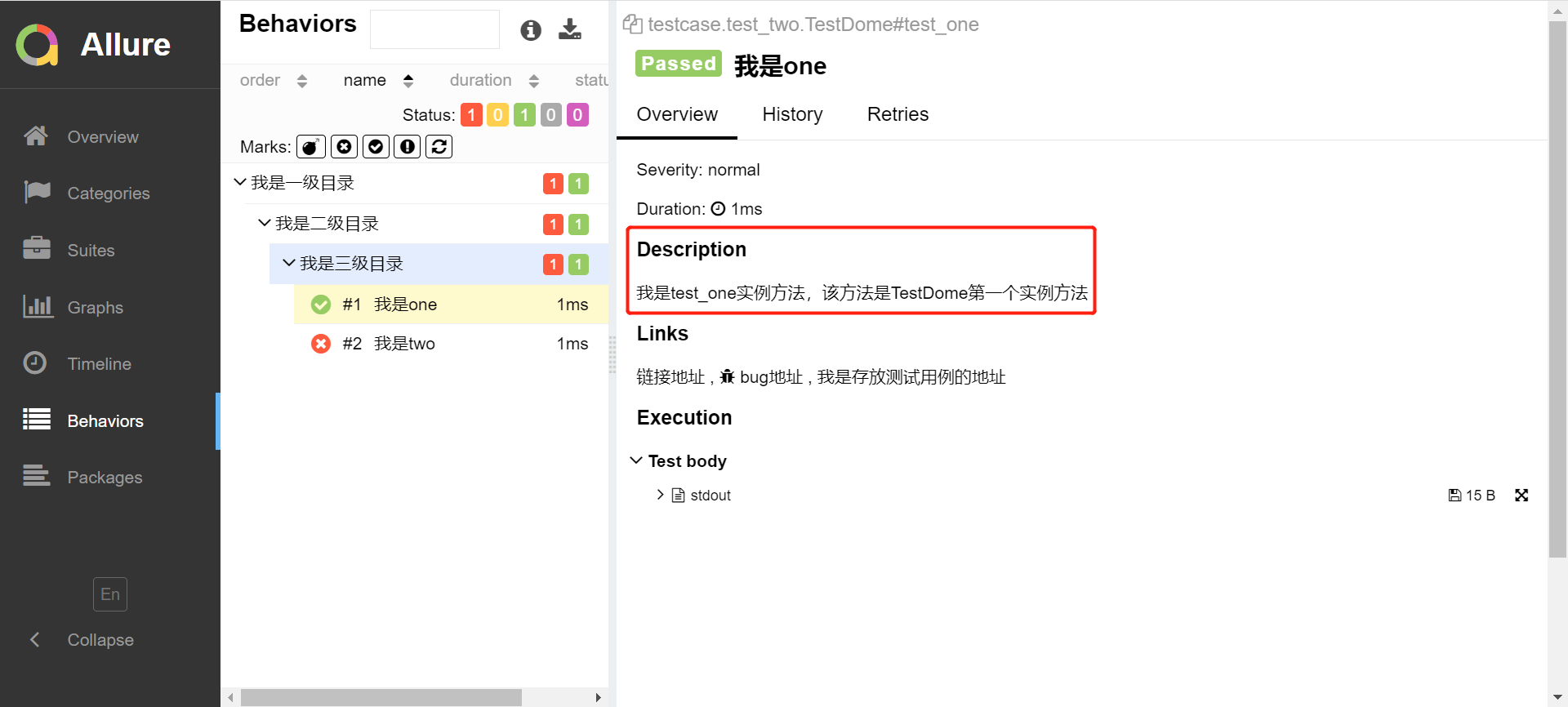
运行后该条case右侧overview多出了description模块
(2)用法二:无需使用@allure.description(),可在函数中使用(""""""),生成测试报告会自动获取
import pytest
import allure
@allure.epic("我是一级目录")
@allure.feature("我是二级目录")
@allure.story("我是三级目录")
@allure.testcase("path url", name="我是存放测试用例的地址")
@allure.issue("bug url", name="bug地址")
@allure.link("link url", name="链接地址")
class TestDome:
@allure.title("我是one")
def test_one(self):
"""我是test_one实例方法,该方法是TestDome第一个实例方法"""
print("我是test_one")
assert True
@allure.title("我是two")
def test_two(self):
print("我是test_two")
assert False
# pytest --alluredir=./report/2022-5-22-02 testcase/test_two.py
# allure generate -o ./allure-report/2022-5-22-02 ./report/2022-5-22-02
运行后的结果
5.@allure.step()用法
(1)该方法在函数外使用时直接@allure.step()即可。要是在函数中使用,需要with allure.step():
import pytest
import allure
class TestDome:
@allure.step("步骤一")
@allure.step("步骤二")
@allure.step("步骤三")
def test_one(self):
print("我是test_one")
assert True
def test_two(self):
print("我是test_two")
assert False
import pytest
import allure
class TestDome:
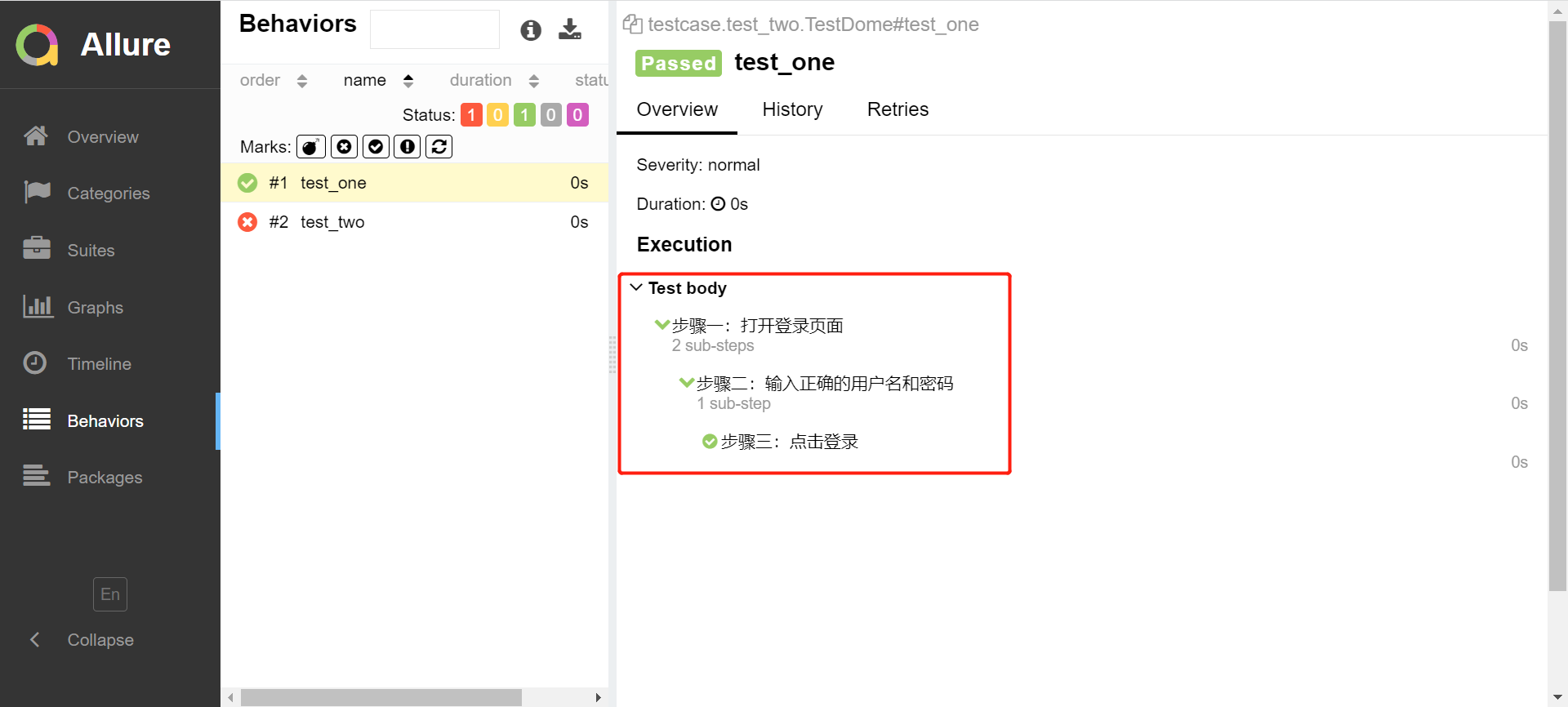
def test_one(self):
with allure.step("步骤一:打开登录页面"):
with allure.step("步骤二:输入正确的用户名和密码"):
with allure.step("步骤三:点击登录"):
assert True
def test_two(self):
print("我是test_two")
assert False
运行后结果,可以看到test body下的运行步骤
6.@allure.severity()用法
(1)severity有四种等级
| blocker | 阻塞缺陷 |
| critical | 严重缺陷 |
| normal | 一般缺陷 |
| trivial | 轻微缺陷 |
| minor | 次要缺陷 |
(2)具体用法:@allure.severity("等级")
import pytest
import allure
class TestDome:
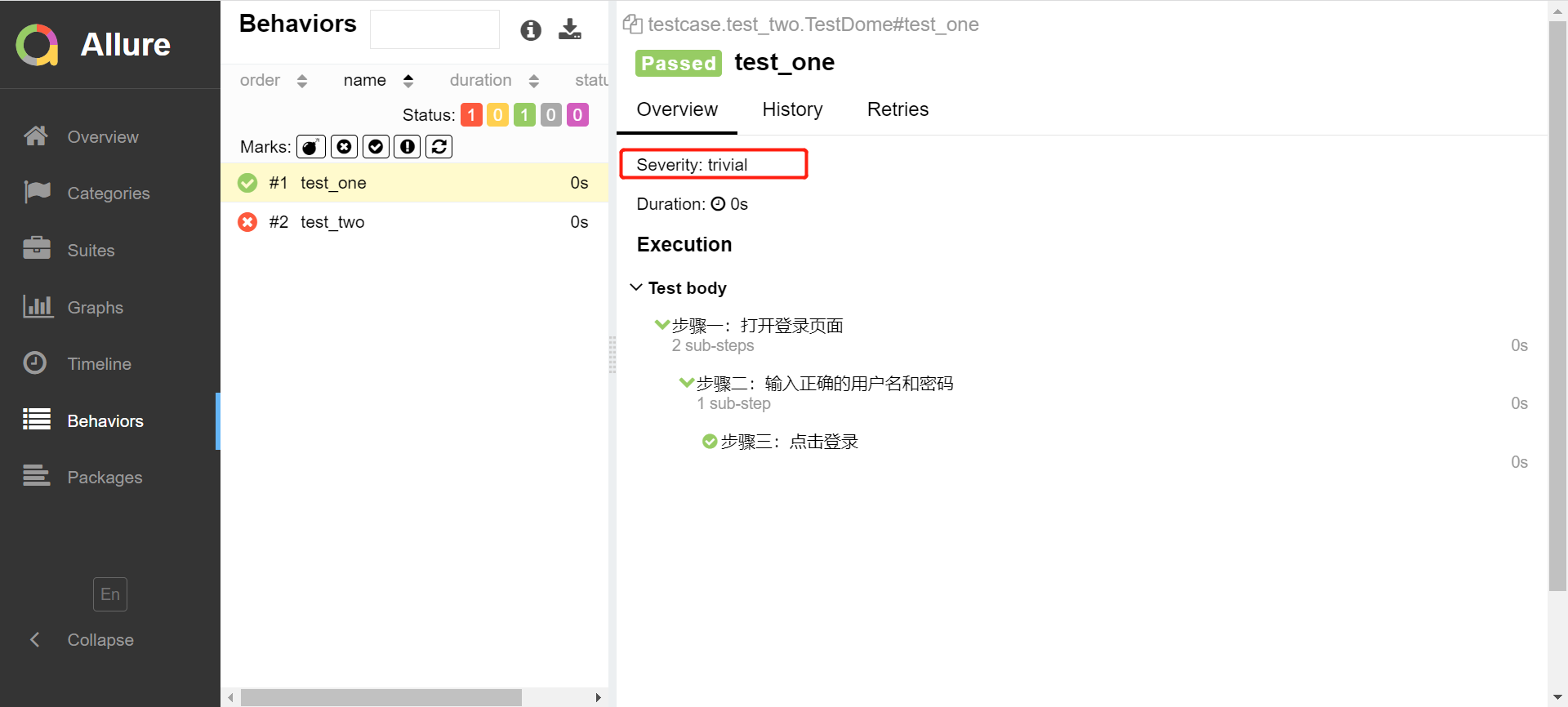
@allure.severity("trivial")
def test_one(self):
with allure.step("步骤一:打开登录页面"):
with allure.step("步骤二:输入正确的用户名和密码"):
with allure.step("步骤三:点击登录"):
assert True
def test_two(self):
print("我是test_two")
assert False
(3)运行结果,如果不手动定义的话,默认为normal bug
四.allure和pytest参数连用
1.@pyteat.mark.parametrize参数化
import pytest
import allure
class TestDome:
@pytest.mark.parametrize("param", [{"name": "李明", "age": 18}, {"name": "李华", "age": 17}])
def test_one(self,param):
with allure.step("步骤一:打开登录页面"):
with allure.step("步骤二:输入正确的用户名和密码"):
with allure.step("步骤三:点击登录"):
assert True
def test_two(self):
print("我是test_two")
assert False
运行后结果,可以看出这里test_one运行了两次,成功测试报告后参数值会自己填充在parameters中

2.skip和xfail
(1)我们先来了解下这两种方法的定义
@pytest.mark.skip()来跳过该条case不执行,可以看出以下代码运行后并不会执行test_one case
import pytest
import allure
class TestDome:
@pytest.mark.skip(reason="跳过该条case")
def test_one(self):
print("我是test_one")
assert True
def test_two(self):
print("我是test_two")
assert True

@pytest.mark.xfail()标记预期结果值,
import pytest
import allure
class TestDome:
@pytest.mark.xfail(reason="预期返回True")
def test_one(self):
print("我是test_one")
assert True
def test_two1(self):
print("我是test_two")
assert True

(2)接下来进入正题,skip and xfail与alure一起使用这里直接贴图吧,具体写法和上面一致
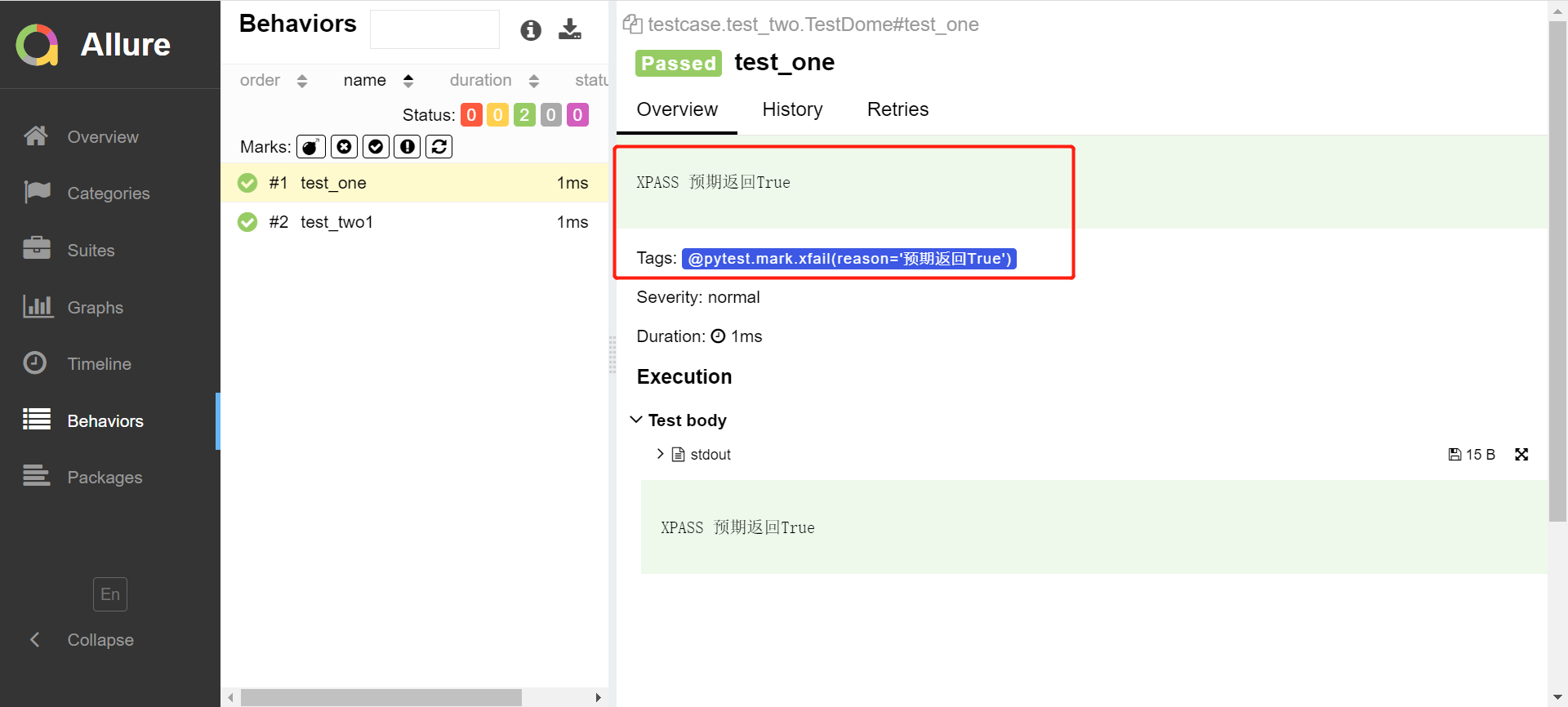
这里可以看出test_one case跳过后并没有运行,置灰显示

五.在allure报告中打印日志和print内容
1.首先我们需要先封装下logging日志,具体写法如下(这里你定义一个函数,编写在函数中)
import logging
import os
logger = logging.getLogger("weixin_api_log") # 设置日志名称
logger.setLevel(logging.DEBUG) # 设置日志等级
formats = logging.Formatter("[%(asctime)s] [%(levelname)s] %(message)s") # 设置打印格式
file_url = logging.FileHandler("C:/Users/XXX/PycharmProjects/weixin_api/log/weixin.log", mode="a+",
encoding="utf8") # log文件路径
# file_url1 = logging.StreamHandler() # 操作台打印
file_url.setFormatter(formats) # 赋予打印格式
# file_url1.setFormatter(formats)
logger.addHandler(file_url)
# logger.addHandler(file_url1)
2.创建test_one.py调用logging
import pytest
import allure
from commom.log import logger
import datetime
class TestDome:
def test_one(self):
logger.debug(f"日志时间:{datetime.datetime.now()}")
print("我是test_one")
assert True
def test_two1(self):
print("我是test_two")
assert True
3.运行结果(这里需要注意的是,运行是不用加-s参数,如果加的话,print打印内容不会再报告中显示)
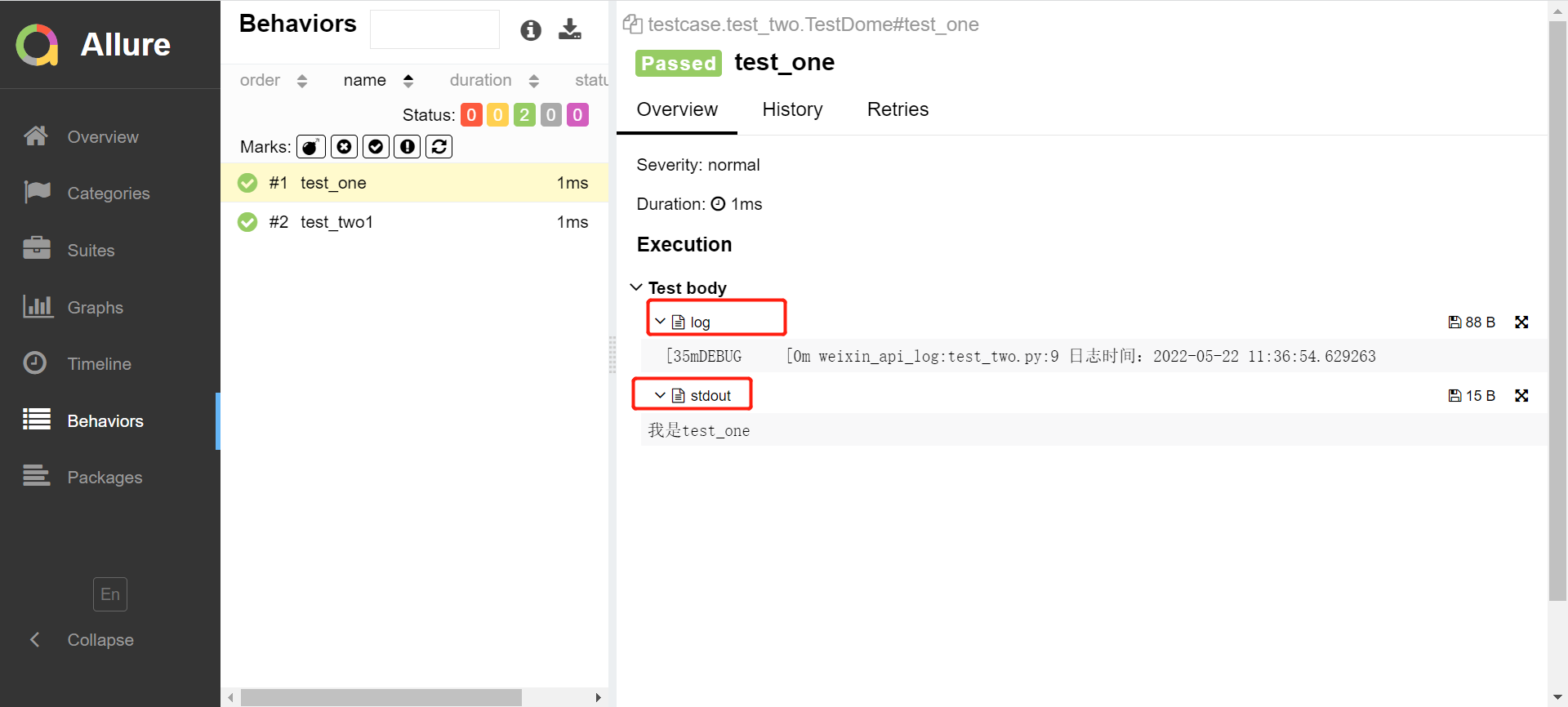
在test body下log里会展示打印的日志,stdout里展示的是print打印的内容
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
在我的Controller中,我通过以下方式在我的index方法中支持HTML和JSON:respond_todo|format|format.htmlformat.json{renderjson:@user}end在浏览器中拉起它时,它会自然地以HTML呈现。但是,当我对/user资源进行内容类型为application/json的curl调用时(因为它是索引方法),我仍然将HTML作为响应。如何获取JSON作为响应?我还需要说明什么? 最佳答案 您应该将.json附加到请求的url,提供的格式在routes.rb的路径中定义。这
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("