redis 的集群方案大致有三种:
sentinel(哨兵)是用于监控 redis 集群中 master 状态的工具,是 Redis 的高可用性解决方案,sentinel 哨兵模式已经被集成在 redis2.4 之后的版本中。
sentinel 本身是一个独立运行的进程,它能监控 master-slave 集群,发现 master 宕机后能进行自动切换。sentinel 可以让 redis 实现主从复制,当一个集群中的 master 失效之后,sentinel 可以选举出一个新的 master 用于自动接替 master 的工作,集群中的其他 redis 服务器自动指向新的 master 同步数据。一般建议 sentinel 采取奇数台,防止某一台 sentinel 无法连接到 master 导致误切换。
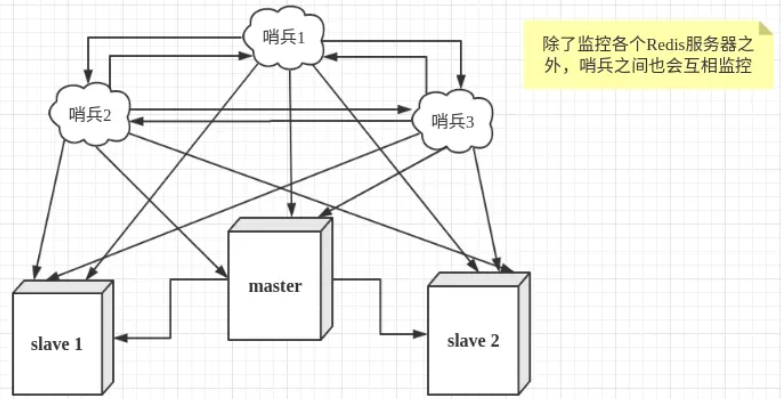
sentinel 的主要作用:
sentinel 工作方式:
sentinel 在内部有 3 个定时任务:
每 10 秒每个 sentinel 会对 master 和 slave 执行 info 命令,这个任务达到两个目的:
每 2 秒每个 sentinel 通过 master 节点的 channel 交换信息(pub/sub)。master 节点上有一个发布订阅的频道(sentinel:hello)。sentinel 节点通过 sentinel:hello 频道进行信息交换(对节点的"看法"和自身的信息),达成共识。
每 1 秒每个 sentinel 对其他 sentinel 和 redis 节点执行 ping 操作(相互监控),这个其实是一个心跳检测,是失败判定的依据。
所谓主观下线(subjectively down, 简称 sdown)指的是单个 sentinel 实例对服务器做出的下线判断,即单个 sentinel 认为某个服务下线(有可能是接收不到订阅,之间的网络不通等等原因)。主观下线就是说如果服务器在 down-after-milliseconds 给定的毫秒数之内, 没有返回 sentinel 发送的 ping 命令的回复, 或者返回一个错误, 那么 sentinel 将这个服务器标记为主观下线。
客观下线(objectively down, 简称 odown)指的是多个 sentinel 实例在对同一个服务器做出 sdown 判断, 并且通过 sentinel is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断,然后开启 failover。客观下线就是说只有在足够数量的 sentinel 都将一个服务器标记为主观下线之后, 服务器才会被标记为客观下线(odown)。只有当 master 被认定为客观下线时,才会发生故障迁移。
主节点:10.124.5.207
从节点:10.124.5.198
redis:redis-6.2.7
# 去官网检查最新版本,yum 安装的版本较低,不推荐
root@controller1:~# wget http://download.redis.io/releases/redis-6.2.7.tar.gz
root@controller1:~# tar -xzf redis-6.2.7.tar.gz
root@controller1:~# cd redis-6.2.7/
root@controller1:~/redis-6.2.7# make && make install
root@controller1:~/redis-6.2.7# mkdir -p /usr/local/redis/data
root@controller1:~/redis-6.2.7# mkdir -p /usr/local/redis/sentinel_data
root@controller1:~/redis-6.2.7# cp redis.conf /usr/local/redis/
root@controller1:~/redis-6.2.7# cp sentinel.conf /usr/local/redis/
主节点 redis.conf:
bind 0.0.0.0
port 6379
daemonize yes
pidfile /usr/local/redis/redis.pid
logfile "/usr/local/redis/redis.log"
dir /usr/local/redis/data
从节点 redis.conf:
bind 0.0.0.0
port 6379
daemonize yes
pidfile /usr/local/redis/redis.pid
logfile "/usr/local/redis/redis.log"
dir /usr/local/redis/data
slaveof 10.124.5.207 6379
主、从节点的 sentinel.conf 都为:
bind 0.0.0.0
port 26379
daemonize yes
pidfile /usr/local/redis/sentinel.pid
logfile "/usr/local/redis/sentinel.log"
dir /usr/local/redis/sentinel_data
sentinel monitor mymaster 10.124.5.207 6379 1
sentinel down-after-milliseconds mymaster 3000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
sentinel monitor mastername ip port quorum
该配置定义了判断 master 客观下线的方式:
mastername 这个是对某个 master+slave 组合的一个区分标识,一套 sentinel 是可以监听多套 master+slave 这样的组合的;
ip 和 port 就是 master 节点的 ip 和 端口号;
quorum 这个参数是进行客观下线的一个依据,至少有 quorum 个 sentinel 主观的认为这个 master 有故障,才会对这个 master 进行下线以及故障转移。
sentinel down-after-milliseconds mastername timeout
该配置是判断主观下线的一个依据,mastername 区分标识,timeout 是一个毫秒值,表示如果这台 sentinel 超过 timeout 这个时间都无法连通 master 包括 slave(slave 不需要客观下线,因为不需要故障转移)的话,就会主观认为该 master 已经下线(实际下线需要客观下线的判断通过才会下线)。
向主节点发送数据,在从节点中查询:
alex@WXIE-M-393D ~ % redis-cli -h 10.124.5.207
10.124.5.207:6379> set test 123
OK
alex@WXIE-M-393D ~ % redis-cli -h 10.124.5.198
10.124.5.198:6379> get test
"123"
主节点 shutdown,查看是否发生切换:
# 10.124.5.207 shutdown 主节点
root@controller1:/usr/local/redis# ps -ef|grep redis
root 79739 1 0 11:45 ? 00:00:00 redis-server 0.0.0.0:6379
root 79760 1 0 11:46 ? 00:00:00 redis-sentinel 0.0.0.0:6380 [sentinel]
root 79778 75169 0 11:49 pts/0 00:00:00 grep --color=auto redis
root@controller1:/usr/local/redis# kill -9 79739
root@controller1:/usr/local/redis# ps -ef|grep redis
root 79760 1 0 11:46 ? 00:00:13 redis-sentinel 0.0.0.0:6380 [sentinel]
root 79807 75169 0 12:40 pts/0 00:00:00 grep --color=auto redis
# 10.124.5.198 查看从节点信息
root@controller2:/usr/local/redis# cat redis.log
22740:S 07 Nov 2022 11:52:26.432 * MASTER <-> REPLICA sync: Finished with success
22740:S 07 Nov 2022 12:40:37.674 # Connection with master lost.
22740:S 07 Nov 2022 12:40:37.674 * Caching the disconnected master state.
22740:S 07 Nov 2022 12:40:37.674 * Reconnecting to MASTER 10.124.5.207:6379
22740:S 07 Nov 2022 12:40:37.674 * MASTER <-> REPLICA sync started
22740:S 07 Nov 2022 12:40:37.674 # Error condition on socket for SYNC: Connection refused
22740:S 07 Nov 2022 12:40:38.217 * Connecting to MASTER 10.124.5.207:6379
22740:S 07 Nov 2022 12:40:38.217 * MASTER <-> REPLICA sync started
22740:S 07 Nov 2022 12:40:38.218 # Error condition on socket for SYNC: Connection refused
22740:M 07 Nov 2022 12:40:38.932 * Discarding previously cached master state.
22740:M 07 Nov 2022 12:40:38.932 # Setting secondary replication ID to 287cfb56ef8b4aeaf8cd24e03e15233d11a34d9f, valid up to offset: 394628. New replication ID is 47753363b21dd61a75aa40893ede060ffd718fde
22740:M 07 Nov 2022 12:40:38.932 * MASTER MODE enabled (user request from 'id=6 addr=10.124.5.198:34285 laddr=10.124.5.198:6379 fd=10 name=sentinel-bda84617-cmd age=2882 idle=0 flags=x db=0 sub=0 psub=0 multi=4 qbuf=188 qbuf-free=40766 argv-mem=4 obl=45 oll=0 omem=0 tot-mem=61468 events=r cmd=exec user=default redir=-1')
22740:M 07 Nov 2022 12:40:38.942 # CONFIG REWRITE executed with success.
# 也可以登录查看,但是通常需要等待大于 sentinel failover-timeout mymaster 180000 的时间
alex@WXIE-M-393D ~ % redis-cli -h 10.124.5.198
10.124.5.198:6379> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:7147ad909c787dc42a6ebe5825119d19a721c0d2
master_replid2:62813525645534dec7ed1a4a87ecd0837d823fad
master_repl_offset:15434
second_repl_offset:9991
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:15434
发现日志中 MASTER MODE enabled ,说明 10.124.5.198 已经从 slave 切换为 master。
此时,再恢复 10.124.5.207 的 redis 服务,查看其日志情况:
root@controller1:/usr/local/redis# redis-server redis.conf
root@controller1:/usr/local/redis# ps -ef|grep redis
root 80018 1 0 13:01 ? 00:00:03 redis-sentinel 0.0.0.0:26379 [sentinel]
root 80062 1 0 13:13 ? 00:00:00 redis-server 0.0.0.0:6379
root 80068 75169 0 13:13 pts/0 00:00:00 grep --color=auto redis
alex@WXIE-M-393D ~ % redis-cli -h 10.124.5.207
10.124.5.207:6379> info replication
# Replication
role:slave
master_host:10.124.5.198
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_read_repl_offset:484515
slave_repl_offset:484515
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:47753363b21dd61a75aa40893ede060ffd718fde
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:484515
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:457441
repl_backlog_histlen:27075
似乎 10.124.5.207 没有恢复为主节点,需要后续继续研究。
…后续:
参考了一些文章,似乎原来的主节点宕机重启后,不会恢复成为主节点,而是成为现在主节点的从节点。参考内容如下:
故障转移分为三个步骤:
- 从下线的主服务的所有从服务里面挑选一个从服务,将其转成主服务。sentinel 状态数据结构中保存了主服务的所有从服务信息,领头 sentinel 按照如下的规则从从服务列表中挑选出新的主服务;
- 删除列表中处于下线状态的从服务;
- 删除最近 5 秒没有回复过领头 sentinel info 信息的从服务;
- 删除与已下线的主服务断开连接时间超过 down-after-milliseconds*10 毫秒的从服务,这样就能保留从的数据比较新(没有过早的与主断开连接);
领头 sentinel 从剩下的从列表中选择优先级高的,如果优先级一样,选择偏移量最大的(偏移量大说明复制的数据比较新),如果偏移量一样,选择运行 id 最小的从服务。
已下线主服务的所有从服务改为复制新的主服务。挑选出新的主服务之后,领头 sentinel 向原主服务的从服务发送 slaveof 新主服务 的命令,复制新 master。
将已下线的主服务设置成新的主服务的从服务,当其回复正常时,复制新的主服务,变成新的主服务的从服务。同理,当已下线的服务重新上线时,sentinel 会向其发送 slaveof 命令,让其成为新主的从。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
注意:本文主要掌握DCN自研无线产品的基本配置方法和注意事项,能够进行一般的项目实施、调试与运维AP基本配置命令AP登录用户名和密码均为:adminAP默认IP地址为:192.168.1.10AP默认情况下DHCP开启AP静态地址配置:setmanagementstatic-ip192.168.10.1AP开启/关闭DHCP功能:setmanagementdhcp-statusup/downAP设置默认网关:setstatic-ip-routegeteway192.168.10.254查看AP基本信息:getsystemgetmanagementgetmanaged-apgetrouteAP配
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl