目录:导读
为了彻底进行API接口测试,我们将讨论在接口测试期间经常发生的几个常见错误。还提供简单的解决方案,以帮助改进API测试方法、运行状况和测试结果。
错误的条目
通常可以观察到,当使用一组必需的输入参数对API进行单独测试时,它工作得很好,但是当与合作伙伴集成时,它开始出现行为错误和故障。这是因为伙伴可能正在为某些必需字段发送’NULL’值,这些值在集成模式下可能难以弄清楚。
它有一个简单的解决方案,即在测试期间,当API接收到“NULL”或错误条目作为输入参数时,我们应该有测试用例来覆盖它的行为。API应向合作伙伴发送响应,并返回适当的错误消息,其中可以声明来自合作伙伴应用程序的输入数据不正确且API正常运行。
无效响应
API响应可能像HTTP 200一样成功,或者像404(即找不到资源)那样失败。有时,从API返回的格式不能被合作伙伴应用程序消化(处理),因为它可能会在字段数量上存在差异。
测试的解决方案非常简单,响应中的字段数量应该明确定义成功和失败响应消息,并应在所有类型的API响应中一致地测试。
缓存API响应
API充当一个黑盒,接受输入参数并针对所触发的所需业务功能提供响应。合作伙伴应用程序可以选择缓存来自API的相同重复输入参数集的输出响应。现在,如果对于相同的输入参数,API的输出经常发生更改,那么伙伴应用程序的缓存输出结果将过时,并传递不正确的信息。
它有一个简单的解决方案,尽管API按预期工作,但是合作伙伴应用程序必须决定它们需要缓存什么结果,不需要缓存什么结果。如果结果像实时数据一样经常从API更改,则不应执行缓存;但如果有产品图像、描述等不希望经常更改的结果,则可以在合作伙伴应用程序中缓存。
处理False Negative(错误否定)回应
通过HTTP将响应返回为200时的API被视为成功,但此类响应也可能具有空值,这是False Negative(错误否定)的情况。虽然合作伙伴应用程序会将这样的响应读取为成功,但是响应中的那些NULL值对它们有意义吗?这是针对False Negative需要实际测试覆盖的地方。
团队沟通失败
随着API基于用户体验和业务变化而增长,API维护变得非常重要。这是需要最佳团队沟通的地方。不应该发生API更改,并且已经开始影响所有合作伙伴应用程序的情况。
任何对API或合作伙伴应用程序的更改都应该得到良好的沟通、实现、集成和测试。此外,标准接口API文档的版本应动态更新,以避免开发人员的任何不良开发实践。
非标准编码方法
API开发团队应在输入参数和输出响应参数方面就特定的标准方法达成一致,任何与该标准的偏差都将直接导致API拒绝输入(或合作伙伴应用程序响应)。有时开发人员接受空白null作为输入或输出,这可能会导致长期问题。应明确定义数据类型(强制或非强制)、范围、阈值等,测试应根据此类标准对API进行测试,任何与此类标准的偏差都不应以任何方式被接受。
确保字符集
API应为输入和输出参数指定接受的字符集,如ASCII,Unicode等。这是为了确保合作伙伴应用程序正在与约定字符集的API交互,并且在约定范围之外接收到的任何字符都会导致直接拒绝。
此外,如英语、法语、西班牙语等作为回应的语言应事先达成一致。我们的测试用例应该对商定的字符集和语言的所有这些要求覆盖完全。
API与合作伙伴应用的兼容性
建立API时要牢记合作伙伴应用程序的兼容性。除了添加到API或合作伙伴应用程序中的新功能之外,任何来自API端或合作伙伴应用程序端的发布都应针对所有现有测试用例进行回归测试。
换句话说,API或合作伙伴应用程序的所有版本都应始终满足兼容性标准。
运用你的测试技巧
API可能有许多隐藏的问题,通过一个经验丰富的测试团队所拥有的测试技能,这些问题实际上可以被发现。建议测试人员执行异常场景测试,以捕获传统测试实践无法捕获的缺陷。
测试人员可以通过Monkey测试来破坏API,这将为开发人员编写一个非常健壮和智能的高效API提供很大的空间。
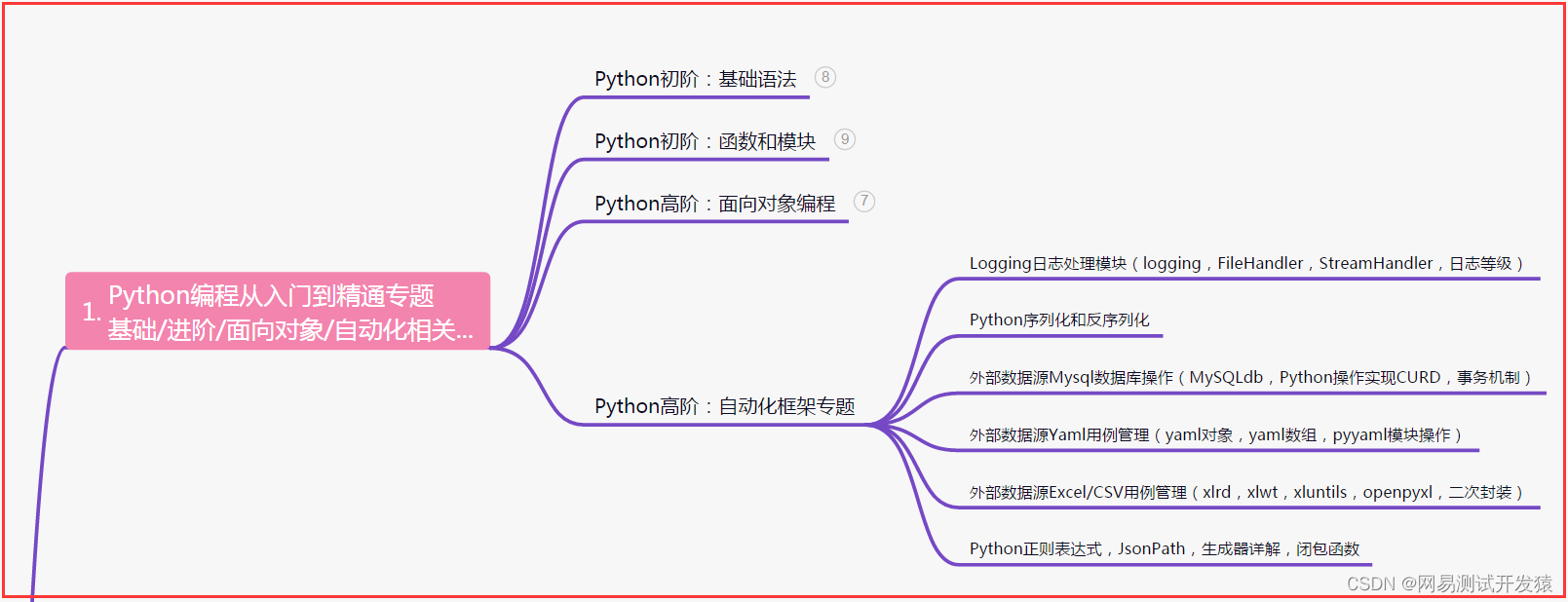
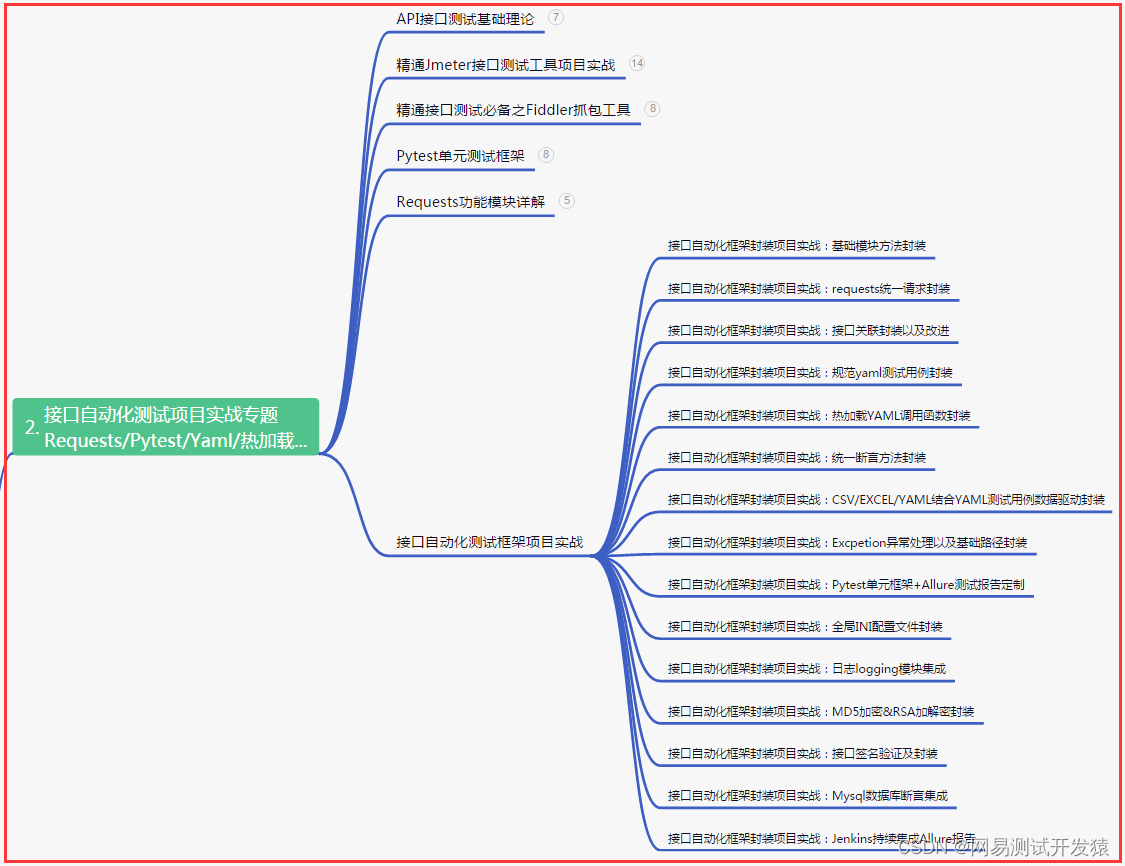
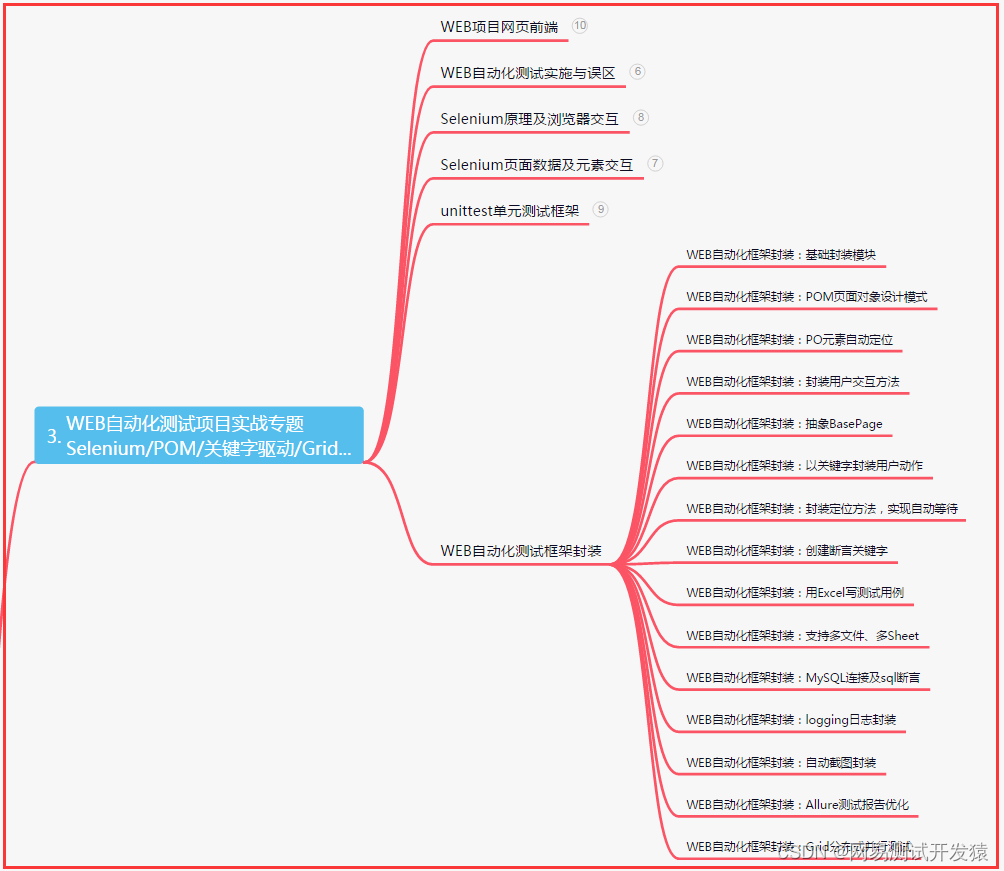
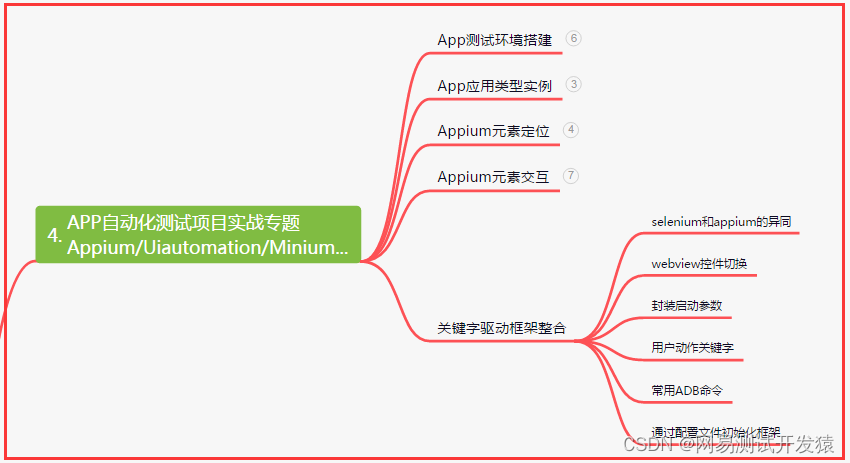
| 下面是我整理的2022年最全的软件测试工程师学习知识架构体系图 |


时间真的是这个世界上最好的跨度,让惨痛变得苍白,让执着的人选择离开,然后历经沧桑人来人往,你会明白,万般皆是命,半点不由人。
人生的秘诀,就是寻找一种最适合自己的速度,莫因疾进而不堪重荷,莫要因迟缓而去空耗生命。
生活坏到一定程度就会好起来,因为它无法更坏,努力过后,才知道许多事情,坚持坚持,就过来了。
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere