在 CentOS 7.9 主机上部署了 k8s 1.21 集群。
因为改配置,需要重启 kubelet 。几个主机都能一秒重启完 kubelet ,不影响容器运行。
但是在某个主机重启 kubelet 时,却一直阻塞无反应,然后报错超时。
于是看 kubelet 日志,发现报错:
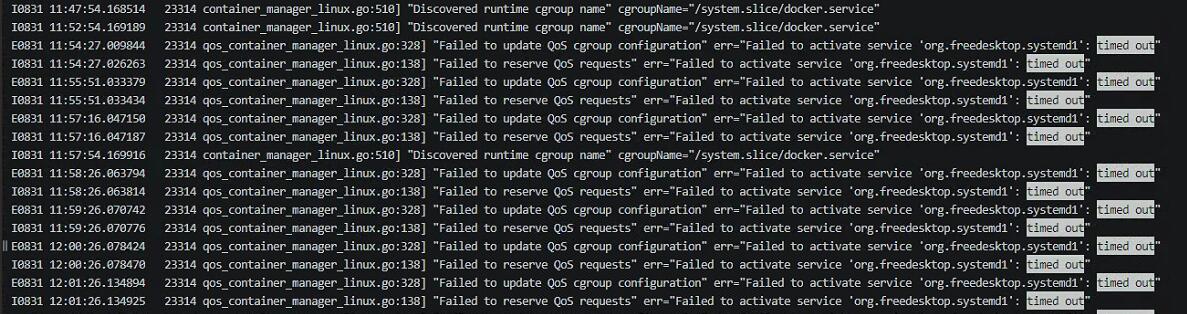
google 搜了下这个报错 org.freedesktop.systemd1 ,发现可能是 systemd 出问题了。
于是看内核日志,发现几天前就有报错了:

报错表示 kubelet 收到了 QUIT 信号,因此不能正常工作。虽然容器还能继续运行,但重启 kubelet 就会失败。
而 Started Session 日志可能是有用户登录,也可能是 cron 等系统进程引发的。
但是看了监控,没人在这个主机上执行 kill 命令或什么奇怪命令。所以怀疑是 CentOS 或 k8s 的 bug 引发的。比如本来要发送 kill 信号给容器内 1 号进程,却发送给宿主机的 1 号进程。
既然 systemd 不能正常工作,那就尝试重启主机,于是恢复了。
如果它没自己恢复,那就重装主机,反正是 k8s 节点,能自动迁移。
选一台测试主机,尝试手动发送 SIGTERM 信号给 systemd 进程,没有反应。
然后发送 QUIT 信号,果然能复现该问题。一堆 systemd 模块不能正常工作,连 reboot、shutdown 也不行。

我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我正在尝试在我的SnowLeopard10.6.8上安装RVM,方法是:\curl-Lhttps://get.rvm.io|bash-sstable--ruby我得到这个错误:InstallingRubyfromsourceto:/Users/Villa/.rvm/rubies/ruby-2.0.0-p0,thismaytakeawhiledependingonyourcpu(s)...ruby-2.0.0-p0-#downloadingruby-2.0.0-p0,thismaytakeawhiledependingonyourconnection...ruby-2.0.0-p0-#e
亲测可用。Anerroroccurredwhileresolvingpackages:Projecthasinvaliddependencies: com.unity.xxx:No'git'executablewasfound.PleaseinstallGitonyour systemthenrestartUnityandUnityHub在我们使用PackageManager时,Unity允许我们使用Git上的package(点击加号,选择addpackagefromgitURL,或者是直接在Asset/Packages/manifest.json中添加包名)。但是这种操作需要我们事先装好g
更新:eventmachinegem已安装并在我的gemfile中:eventmachine(1.0.0,0.12.10)请帮忙!尝试使用以下内容创建数据库:Fitzs-MacBook-Pro:twilio_insanityFitz$rakedb:create'返回以下错误:UnabletoloadtheEventMachineCextension;Tousethepure-rubyreactor,require'em/pure_ruby'rakeaborted!cannotloadsuchfile--rubyeventmachine/Users/Fitz/.rvm/gems/ruby
一、前言最近,在测试环境的nginx里增加了一个https配置:location/api-meeting-qq/{proxy_passhttps://api.meeting.qq.com/;}然后,执行命令://这个是nginx启动文件的路径,根据实际情况自行更改sudo/home/useradmin/nginx/sbin/nginx-sreload结果,nginx就报错了:nginx:[emerg]httpsprotocolrequiresSSLsupportin/home/useradmin/nginx/conf.d/trainNginx.conf:9二、解决方法百度发现,是之前安装ngi
我们开始在日志中看到一些奇怪的错误,这些错误通常在ruby未使用OpenSSL正确编译时出现。但它不一致...我们收到如下错误:RuntimeError:不支持的摘要算法(SHA256)。(还有其他摘要,如sha1)。exampleerrortraceFaraday::SSLError(SSL_CTX_new:(null))exampleerrortrace我们在使用serviceunicornstart或systemctlstartunicorn启动unicorn时成功重现了它。但只有一些请求...不是全部。某些在后台使用OpenSSL的请求确实有效。其他人没有。但是,当我们使用
文章目录一.搭建集群时出现错误错误日志elasticsearch.logorg.elasticsearch.cluster.block.clusterblockexception:blockedby:[service_unavailable/1/statenotrecovered/initialized];原因:解决方案:一.搭建集群时出现错误错误日志elasticsearch.logorg.elasticsearch.cluster.block.clusterblockexception:blockedby:[service_unavailable/1/statenotrecovered/i
我正在关注RubyonRailsTutorial并且在测试部分变得有些困惑,特别是-3.6.2-AutomatedtestswithGuard按照部署到Heroku的教程说明,我已切换到Postgresql并从我的gemfile中删除了sqlite3,并进行了捆绑安装以进行更新。但是,一旦我运行bundleexecguard我收到消息:/Users/username/.rvm/gems/ruby-1.9.3-p125@global/gems/bundler-1.1.3/lib/bundler/rubygems_integration.rb:147:inblockinreplace_ge
当我打字时geminstallsass我收到以下错误消息C:>geminstallcompassERROR:Couldnotfindavalidgem'compass'(>=0),hereiswhy:Unabletodownloaddatafromhttps://rubygems.org/-SSL_connectreturned=1errno=0state=SSLv3readservercertificateB:certificateverifyfailed(https://rubygems.org/latest_specs.4.8.gz) 最佳答案