上一篇分享了如何在windows下搭建了一个分布式ES集群,这一篇来入门下DSL开发。
ES支持JSON格式的查询,叫做DSL(domain specific language)。
常用数据类型:text、keyword、number、array、range、boolean、date、geo_point、ip、nested、object
| 类型 | 注释 |
|---|---|
| text | 默认会进行分词,支持模糊查询(5.x之后版本string类型已废弃,请大家使用text) |
| keyword | 不进行分词;keyword类型默认开启doc_values来加速聚合排序操作,占用了大量磁盘io 如非必须可以禁用doc_values。 |
| number | 如果只有过滤场景 用不到range查询的话,使用keyword性能更佳,另外数字类型的doc_values比字符串更容易压缩。 |
| array | ES不需要显示定义数组类型,只需要在插入数据时用’[]'表示即可,元素类型需保持一致。 |
| range | 对数据的范围进行索引;目前支持 number range、date range 、ip range |
| object | 嵌套类型,不支持数组。 |
| boolean | 只接受true、false 也可以是字符串类型的“true”、“false” |
| date | 支持毫秒、根据指定的format解析对应的日期格式,内部以long类型存储。 |
开发工具
利用本地部署的kibana上自带的Dev Tools。启动Kibana,浏览器进入 http://localhost:5601/app/dev_tools#/console
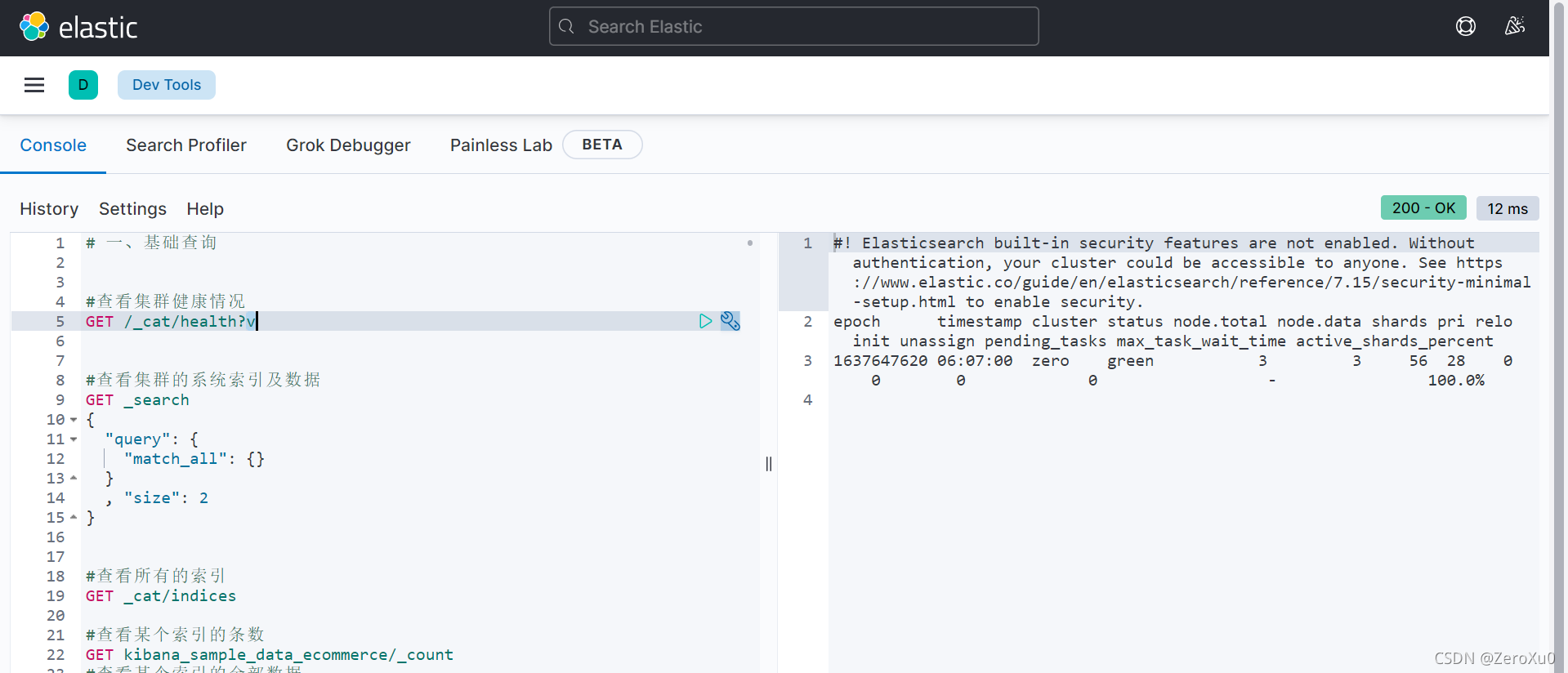
#############基础查询#################
#查看集群健康情况
GET /_cat/health?v
#查看集群的系统索引及数据
GET _search
{
"query": {
"match_all": {}
}
, "size": 2 #指定返回结果的条数
}
#查看所有的索引
GET _cat/indices
#查看某个索引的条数
GET kibana_sample_data_ecommerce/_count
#查看某个索引的全部数据
GET kibana_sample_data_ecommerce/_search
#插入(创建)users索引,并创建id为1的文档,如果存在则报错
POST users/_doc/1
{ "firstname": "will", "lastname": "smith"}
#创建id为2的文档
POST users/_create/2
{
"firstname": "zero",
"lastname": "xu",
"age": "25",
"hobby": "sneakers movies"
}
#创建id为3的文档
PUT users/_create/3
{
"firstname": "russ",
"lastname": "westbrook",
"hobby": "fashion"
}
#创建id为4的文档
POST users/_doc/4
{
"firstname": "wet",
"lastname": "keep"
}
#更新id为1的文档,并新增两个属性
POST users/_update/1
{
"doc": {
"hobby": "sneakers",
"age": "25"
}
}
POST users/_update/1
{
"doc": {
"age": "54",
"type":"keyword"
}
}
#删除索引下的某个id文档
DELETE users/_doc/4
#删除索引
DELETE users
#查询users索引的某个id文档
GET users/_doc/3
GET users/_doc/2
GET users/_doc/1
#批量查询多个指定的id的数据,也可以批量查询
GET /_mget
{
"docs": [
{
"_index": "users",
"_id": 1
},
{
"_index": "users",
"_id": 2
}
]
}
#match_all
#查询所有数据,[按照id进行排序]
GET users/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_id": {
"order": "desc"
}
}
]
}
#泛查询,查询所有的文档,只要属性值包含zero的文档
GET users/_search?q=zero
#查询fisrtname属性包含russ的文档
GET users/_search?q=russ&df=firstname
GET users/_search?q=firstname:russ
#查询lastname中包含xu,从第0条开始,查询1条(es的计数是从0开始)
GET users/_search?q=lastname:xu&from=0&size=1
#查询hobby中包含fashion或者sneakers的文档
GET users/_search?q=hobby:fashion sneakers
GET users/_search?q=hobby:(fashion sneakers)
#查询hobby中包含"sneaker movies"串的文档(有前后顺序之分)
GET users/_search?q=hobby:"sneakers movies"
#查询hobby中既包含"sneaker"又包含"movies"的文档(无前后顺序之分,AND要大写)
GET users/_search?q=hobby:(sneakers AND movies)
#查询hobby中包含sneakers但是不包含movies的文档(NOT要大写)
GET users/_search?q=hobby:(sneakers NOT movies)
#查询年纪大于30岁的数据
GET users/_search?q=age:>=30
# 返回user索引下的所有数据
GET users/_search
######### 高级查询 ##############
# 分词器
GET _analyze
{
"analyzer": "standard",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
#request body深入搜索:term是最小搜索单位,包含:term查询的种类有:Term Query、Range Query等。
GET users/_search
{
"query": {
"term": {
"hobby": {
"value": "sneakers"
}
}
}
}
GET users/_search
{
"query": {
"terms": {
"hobby": [
"movies",
"fashion"
]
}
}
}
#要将age转成keyword类型,否则使用默认的fileddata类型无法进行排序
GET users/_search
{
"query": {
"range": {
"age.keyword": {
"gte": 25,
"lte": 33
}
}
},
"sort": [
{
"age.keyword": {
"order": "desc"
}
}
]
}
#constant_score不进行相关性算分,查询的数据进行缓存,提高效率
GET users/_search
{
"query": {
"constant_score": {
"filter": {
"terms": {
"hobby": [
"movies",
"fashion"
]
}
}
}
}
}
GET users/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"hobby": "movies"
}
}
}
}
}
#match
#查询hobby包含sneakers或者fashion的firstname和lastname
GET users/_search
{
"_source": ["firstname","lastname"],
"query": {
"match": {
"hobby": "sneakers fashion"
}
}
}
#match_pgrase
#查询hobby中包含有 "sneakers movies" 这个短语的所有的数据
GET users/_search
{
"query": {
"match_phrase": {
"hobby": "sneakers movies"
}
}
}
#muti_match
#组合查询:age或者hobby中包含33或者movies的数据
GET /users/_search
{
"query": {
"multi_match": {
"query": "33 movies",
"fields": ["age","hobby"]
}
}
}
#match_all
#查询所有数据
GET users/_search
{
"query": {
"match_all": {}
}
}
#query_string和simple_query_string
GET users/_search
{
"query": {
"query_string": {
"default_field": "hobby",
"query": "sneakers OR movies"
}
}
}
GET users/_search
{
"query": {
"simple_query_string": {
"query": "movies",
"fields": ["hobby"]
}
}
}
#查询hobby中包含snearkers movies短语的数据
GET users/_search
{
"query": {
"simple_query_string": {
"query": "\"sneakers movies\"",
"fields": ["hobby"]
}
},
"_source": ["firstname","lastname"]
}
#组合查询,组合must、should、must_not,实现多条件查询
GET users/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"hobby": "movies"
}
},
{
"match": {
"age.keyword": "25"
}
}
]
}
}
}
#filter不会进行相关性的算分,并且将计算出来的结果进行缓存,效率比query高
GET users/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"hobby": "sneakers"
}
},
{
"range": {
"age.keyword": {
"gte": 25,
"lte": 55
}
}
}
]
}
}
}
# 二、通过mapping创建索引
PUT employee
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "keyword"
},
"job": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"gender": {
"type": "keyword"
}
}
}
}
#批量导入数据
PUT employee/_bulk
{"index": {"_id": 1}}
{"id": 1, "name": "Bob", "job": "java", "age": 21, "sal": 8000, "gender": "female"}
{"index": {"_id": 2}}
{"id": 2, "name": "Rod", "job": "html", "age": 31, "sal": 18000, "gender": "female"}
{"index": {"_id": 3}}
{"id": 3, "name": "Gaving", "job": "java", "age": 24, "sal": 12000, "gender": "male"}
{"index": {"_id": 4}}
{"id": 4, "name": "King", "job": "dba", "age": 26, "sal": 15000, "gender": "female"}
{"index": {"_id": 5}}
{"id": 5, "name": "Jonhson", "job": "dba", "age": 29, "sal": 16000, "gender": "male"}
{"index": {"_id": 6}}
{"id": 6, "name": "Douge", "job": "java", "age": 41, "sal": 20000, "gender": "female"}
{"index": {"_id": 7}}
{"id": 7, "name": "cutting", "job": "dba", "age": 27, "sal": 7000, "gender": "male"}
{"index": {"_id": 8}}
{"id": 8, "name": "Bona", "job": "html", "age": 22, "sal": 14000, "gender": "female"}
{"index": {"_id": 9}}
{"id": 9, "name": "Shyon", "job": "dba", "age": 20, "sal": 19000, "gender": "female"}
{"index": {"_id": 10}}
{"id": 10, "name": "James", "job": "html", "age": 18, "sal": 22000, "gender": "male"}
{"index": {"_id": 11}}
{"id": 11, "name": "Golsling", "job": "java", "age": 32, "sal": 23000, "gender": "female"}
{"index": {"_id": 12}}
{"id": 12, "name": "Lily", "job": "java", "age": 24, "sal": 2000, "gender": "male"}
{"index": {"_id": 13}}
{"id": 13, "name": "Jack", "job": "html", "age": 23, "sal": 3000, "gender": "female"}
{"index": {"_id": 14}}
{"id": 14, "name": "Rose", "job": "java", "age": 36, "sal": 6000, "gender": "female"}
{"index": {"_id": 15}}
{"id": 15, "name": "Will", "job": "dba", "age": 38, "sal": 4500, "gender": "male"}
{"index": {"_id": 16}}
{"id": 16, "name": "smith", "job": "java", "age": 32, "sal": 23000, "gender": "male"}
GET employee/_search/
GET employee/_doc/1
GET employee/_count
#查询工资总和
GET employee/_search
{
"size": 0,
"aggs": {
"total_sal": {
"sum": {
"field": "sal"
}
}
}
}
#查询不同工作的薪资统计情况:sum、avg、min、max
GET employee/_search
{
"size": 0,
"aggs": {
"job_inf": {
"terms": {
"field": "job"
},
"aggs": {
"sal_info": {
"stats": {
"field": "sal"
}
}
}
}
}
}
#查询不同工作,男女员工的数量。以及薪资统计情况:sum、avg、min、max
GET employee/_search
{
"size": 0,
"aggs": {
"job_info": {
"terms": {
"field": "job"
},
"aggs": {
"gender_info": {
"terms": {
"field": "gender"
},
"aggs": {
"sal_info": {
"stats": {
"field": "sal"
}
}
}
}
}
}
}
}
GET employee/_search
{
"size": 0,
"aggs": {
"sal_info": {
"histogram": {
"field": "sal",
"interval": 5000,
"extended_bounds": {
"min": 0,
"max": 30000
}
}
}
}
}
#查询不同区间的员工工资统计
GET employee/_search
{
"size": 0,
"aggs": {
"sal_info": {
"range": {
"field": "sal",
"ranges": [
{
"key": "0 <= sal <= 5000",
"from": 0,
"to": 5000
},
{
"key": "5001 <= sal <= 10000",
"from": 5001,
"to": 10000
},
{
"key": "10001 <= sal <= 15000",
"from": 10001,
"to": 15000
}
]
}
}
}
}
#查询在不同工资区间的员工姓名
GET employee/_search
{
"_source": ["name","job"],
"query": {
"range": {
"sal": {
"gte": 0,
"lte": 5000
}
}
}
}
GET employee/_search
{
"size": 0,
"aggs": {
"sal_info": {
"range": {
"field": "sal",
"ranges": [
{
"key": "0 <= sal <= 5000",
"from": 0,
"to": 5000
},
{
"key": "5001 <= sal <= 10000",
"from": 5001,
"to": 10000
},
{
"key": "10001 <= sal <= 15000",
"from": 10001,
"to": 15000
}
]
}
}
},
"_source": ["name","job"],
"query": {
"match_all": {}
}
}
GET mytest_index_2/_search
{
"query": {
"match_all": {}
}
}
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我正在尝试找出如何为我的Ruby项目创建一种“无类DSL”,类似于在Cucumber步骤定义文件中定义步骤定义或在Sinatra应用程序中定义路由。例如,我想要一个文件,其中调用了我的所有DSL函数:#sample.rbwhen_string_matches/hello(.+)/do|name|call_another_method(name)end我认为用我的项目特有的一堆方法污染全局(内核)命名空间是一种不好的做法。因此方法when_string_matches和call_another_method将在我的库中定义,并且sample.rb文件将以某种方式在我的DSL方法的上下文中
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD