摘要: HetuEngine作为MRS服务中交互式分析&多源统一SQL引擎,亲自全程体验其如何实现多数据源的跨源跨域分析能力。
本文分享自华为云社区《MRS HetuEngine体验跨源跨域分析【玩转华为云】》,作者:龙哥手记。
HetuEngine作为MRS服务中交互式分析&多源统一SQL引擎,亲自全程体验其如何实现多数据源的跨源跨域分析能力。
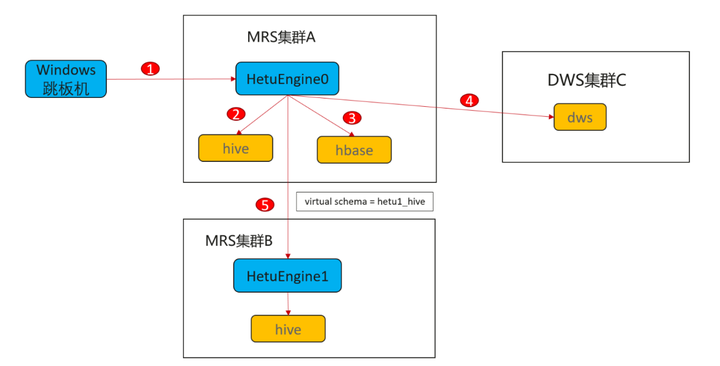
1)用户通过登录Windows跳板机,使用SQL开发工具DBeaver连接MRS集群A的HetuEngine进行分析体验
2)跨源分析体验,通过HetuEngine0连接集群内部数据源hive
3)跨源分析体验,通过HetuEngine0连接集群内部数据源hbase
4)跨仓分析体验,通过HetuEngine0连接关系型数据库DWS
5)跨湖分析体验,通过HetuEngine0连接到MRS集群B的HetuEngine1再连接到集群B的数据源hive
登录:http://121.13.226.78:18080/ssh/#/
① 用户名:hdc01,
② 密码:请联系现场引导员获取
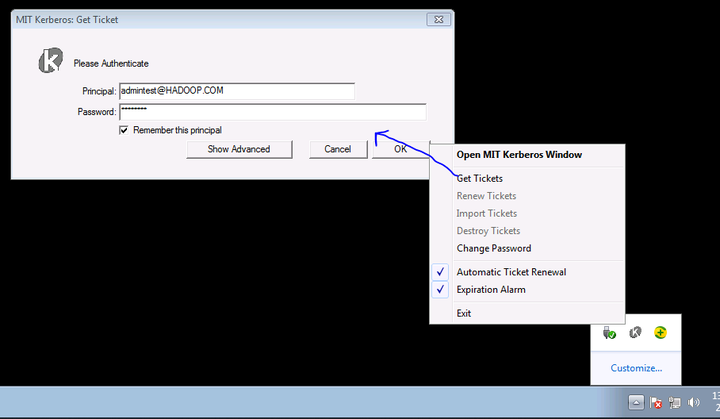
点击右下角的MIT Kerberos,选择Get Tickets输入用户名密码获取Kerberos认证票据
① Principal:admintest@HADOOP.COM,
② Password: Admin12!
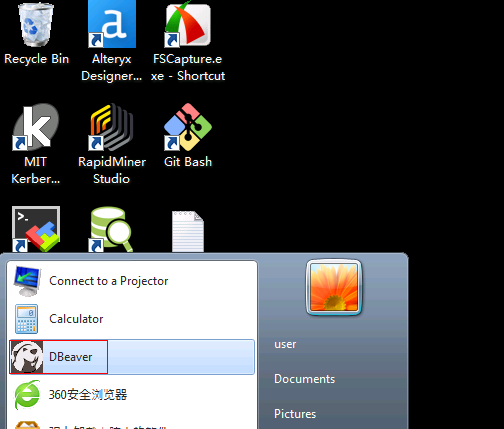
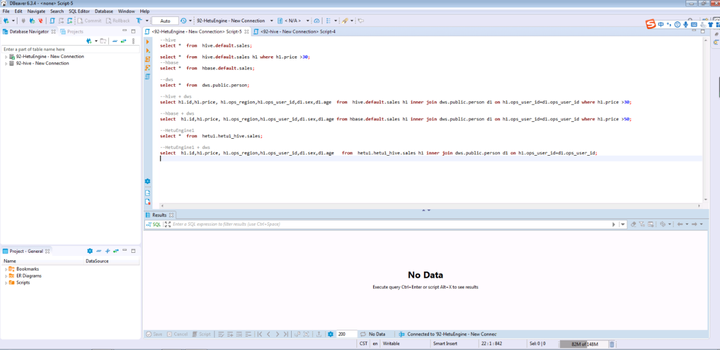
点击三角符号打开已配置好的HetuEngine连接
说明:
① dws: 外部dws数据库
② hbase: MRS集群A中的hbase数据源
③ hetu1: 远端MRS集群B的HetuEngine
④ hive: MRS集群A中的hive数据源
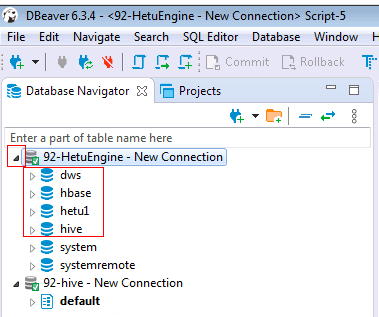
选择配置好的hive数据源92-hive - New Connection,右键选择SQL Editor
输入以下SQL语句并查看结果与时间
SELECT * FROM sales h1 WHERE h1.price >30;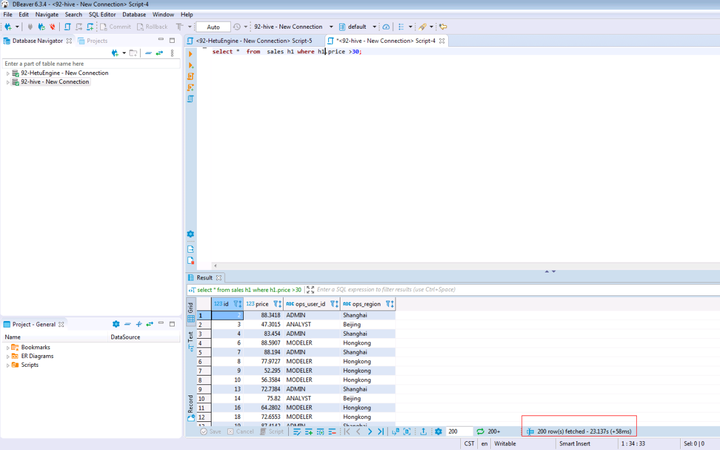
选择配置好的hive数据源92-HetuEngine - New Connection,右键选择SQL Editor
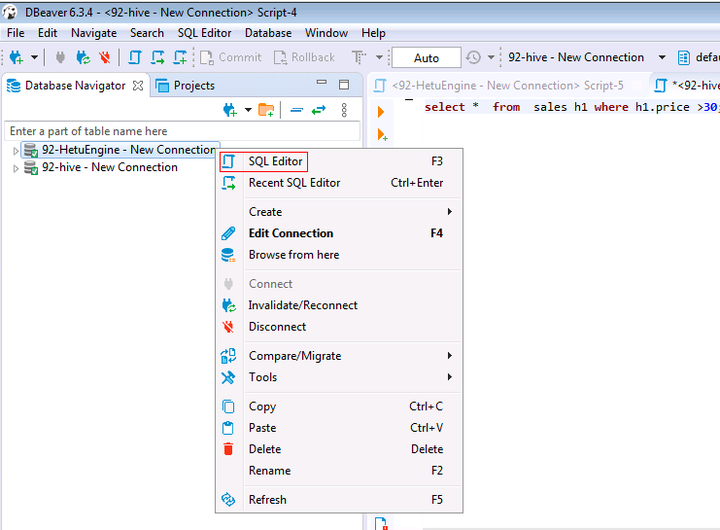
输入以下的SQL语句并查看结果和时间
SELECT * FROM hive.default.sales h1 WHERE h1.price >30;
通过比较两次查询时间,可以看到HetuEngine会加速查询性能,比普通的hive查询更加快速;
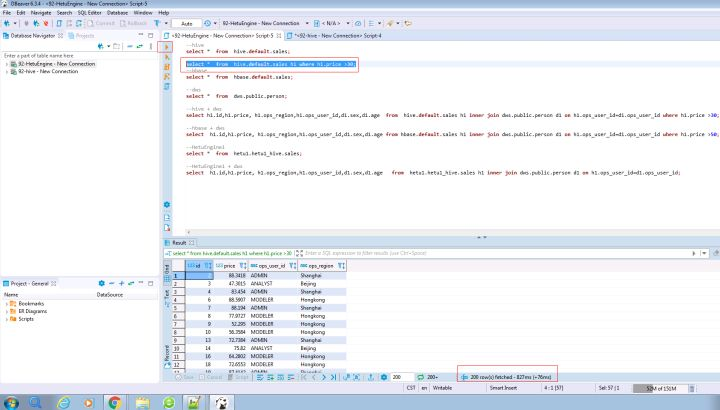
在打开的SQL Editor中输入如下SQL语句查询MRS集群A的HBase数据
SELECT * FROM hbase.default.sales;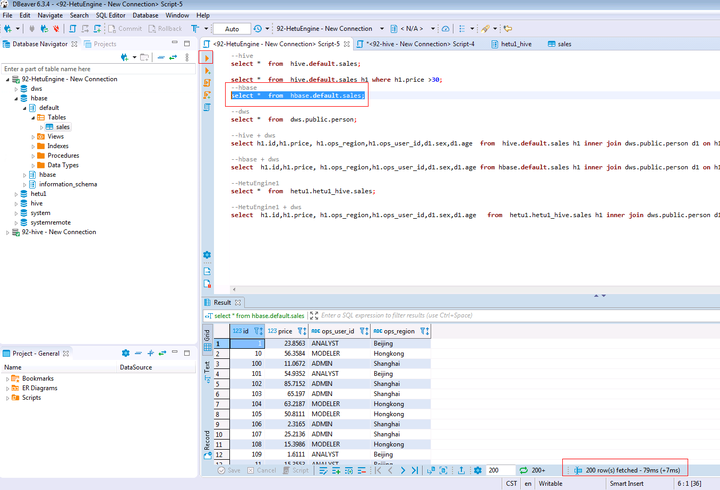
在打开的SQL Editor中输入如下SQL语句查询DWS集群C中的维表数据
SELECT * FROM dws.public.person;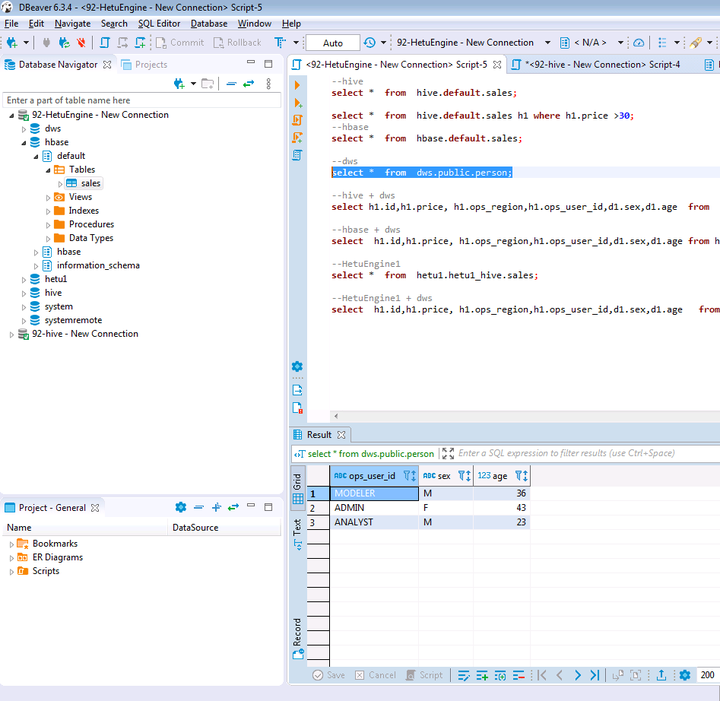
在打开的SQL Editor中输入如下SQL语句可做MRS集群A的hive与DWS集群C的跨仓数据分析
SELECT h1.id,h1.price, h1.ops_region,h1.ops_user_id,d1.sex,d1.age FROM hive.default.sales h1 INNER JOIN dws.public.person d1 ON h1.ops_user_id=d1.ops_user_id WHERE h1.price >30;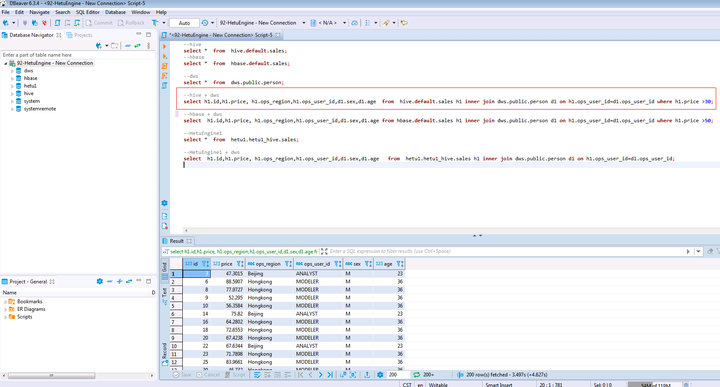
在打开的SQL Editor中输入如下SQL语句可做MRS集群A的hbase与DWS集群C的跨仓数据分析
SELECT h1.id,h1.price, h1.ops_region,h1.ops_user_id,d1.sex,d1.age FROM hbase.default.sales h1 INNER JOIN dws.public.person d1 ON h1.ops_user_id=d1.ops_user_id WHERE h1.price >50;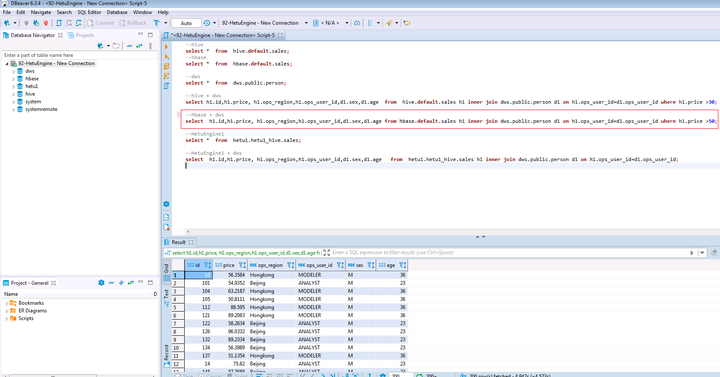
出于管理和信息收集的需要,企业内部会存储海量数据,包括数目众多的各种数据库、数据仓库等,此时会面临数据源种类繁多、数据集结构化混合、相关数据存放分散等困境,导致跨源查询开发成本高,跨源复杂查询耗时长。HetuEngine提供了统一标准SQL实现跨源协同分析,简化跨源分析操作;
在打开的SQL Editor中输入如下SQL语句可做MRS集群B中HetuEngine的hive跨湖查询
SELECT * FROM hetu1.hetu1_hive.sales;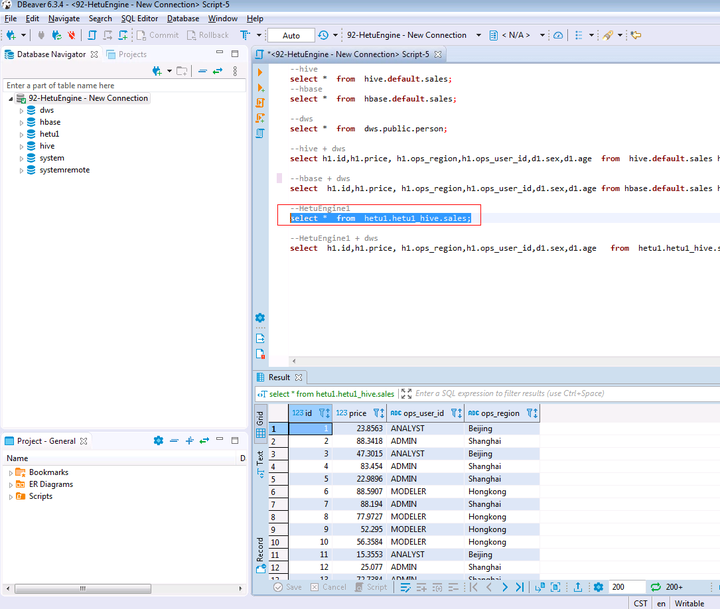
打开SQL Editor输入如下SQL语句可做MRS集群B中HetuEngine的hive同DWS集群C的跨湖查询
SELECT h1.id,h1.price, h1.ops_region,h1.ops_user_id,d1.sex,d1.age FROM hetu1.hetu1_hive.sales h1 INNER JOIN dws.public.person d1 ON h1.ops_user_id=d1.ops_user_id;HetuEngine提供统一标准SQL对分布于多个地域(或数据中心)的多种数据源实现高效访问,屏蔽数据在结构、存储及地域上的差异,实现数据与应用的解耦。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
我有一大串格式化数据(例如JSON),我想使用Psychinruby同时保留格式转储到YAML。基本上,我希望JSON使用literalstyle出现在YAML中:---json:|{"page":1,"results":["item","another"],"total_pages":0}但是,当我使用YAML.dump时,它不使用文字样式。我得到这样的东西:---json:!"{\n\"page\":1,\n\"results\":[\n\"item\",\"another\"\n],\n\"total_pages\":0\n}\n"我如何告诉Psych以想要的样式转储标量?解