Apache Superset 是一款现代化的开源大数据工具,也是企业级商业智能 Web 应用,用于数据探索分析和数据可视化。
Apache Superset 是一个适合企业日常生产环境中使用的商业智能可视化工具。它具有快速、轻量、直观的特点,任何用户都可以轻松地上手探索他们的数据。从非常简单的饼图到复杂的地理空间图,Superset都给到了非常好的支持。

Superset 提供以下功能:
Superset 是云原生的,旨在提供高可用性。它旨在扩展到大型分布式环境,并且在容器中运行良好。既可以仅在本地环境上轻松测试 Superset,又可以横向扩展到生产环境中使用。
Superset 是云原生的,因此它很灵活,可以让你切换各种中间件,如:
Superset 还可以很好地与 NewRelic、StatsD 和 DataDog 等服务配合使用,用于监控 Superset服务的健壮性,并且能够针对最流行的数据库技术运行分析工作负载
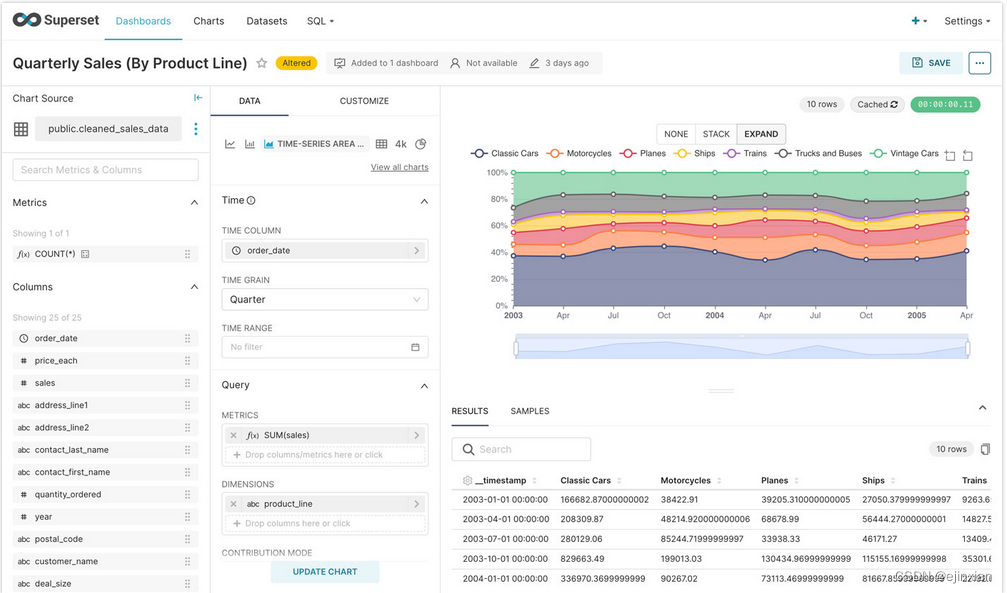
Apache Superset拥有非常丰富的图表,来实现不同的可视化需求
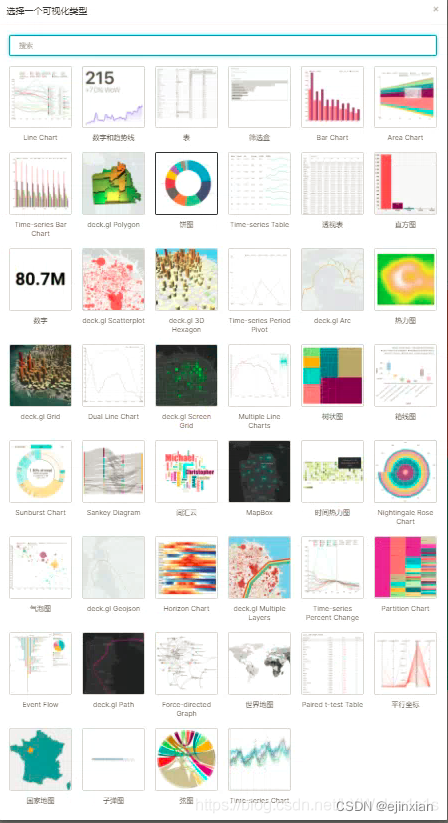
大数据数据可视化的目标架构
可是架构分为三个梯队;
第一梯队:ClickHouse、DorisDB、Kylin等优秀OLAP技术做存储,利用自带的连接引擎,快速响应,同时支持实时数据和离线数据的接入,外接可视化平台,通过权限管控后呈现给用户;
第二梯队:数据存在数据仓库Hive内或者NoSQL的Hbase,再通过较为优秀且高效的引擎Presto、Flink、Spark等接入可视化平台,通过权限管控后呈现给用户;
剩下就是一个特殊的,如MySQL,临时文件等文件的接入;
常用的也还有其它技术架构,如ELK架构,ELK由ElasticSearch、Logstash和Kiabana三个开源工具组成。Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。 Logstash是一个完全开源的工具,他可以对你的日志进行收集、分析,并将其存储供以后使用(如,搜索)。 kibana 也是一个开源和免费的工具,他Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。这个后续再讲,这里书归正传,先讲讲Apache Superser
参考:
我即将开始一个将录制和编辑音频文件的项目,我正在寻找一个好的库(最好是Ruby,但会考虑Java或.NET以外的任何库)以进行实时可视化波形。有人知道我应该从哪里开始搜索吗? 最佳答案 要流入浏览器的数据量很大。Flash或Flex图表可能是唯一能提高内存效率的解决方案。Javascript图表往往会因大型数据集而崩溃。 关于ruby-Ruby中的波形可视化,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c
如果使用Marshal.dump写入文件,我有一个Ruby散列达到大约10兆字节。gzip压缩后约为500KB。在ruby中迭代和改变这个散列是非常快的(几分之一毫秒)。即使复制它也非常快。问题是我需要在RubyonRails进程之间共享此散列中的数据。为了使用Rails缓存(file_store或memcached)执行此操作,我需要先Marshal.dump文件,但这会在序列化文件时产生1000毫秒的延迟,在序列化文件时产生400毫秒的延迟。理想情况下,我希望能够在100毫秒内从每个进程保存和加载此哈希。一个想法是生成一个新的Ruby进程来保存这个散列,该散列为其他进程提供AP
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭6年前。Improvethisquestion是否有任何用Ruby或Python编写的生产就绪的开源Twitter克隆?我对功能丰富的实现更感兴趣,而不仅仅是简单的Twitter消息(例如:API、FBconnect、通知等)谢谢!
Unity数据可视化图表插件XCharts3.0发布历时8个多月,业余时间,断断续续,XCharts3.0总算发布了。如果要打个满意度,我给3.0版本来个80分。对于代码框架结构设计的调整改动,基本符合预期,甚是满意。相比之前的1.0和2.0版本,我认为3.0才是一个拿得出手给广大开发者使用的版本。1.0发布的时候,很兴奋,从0.1到1.0,也磨了一年,真的等不及想给大家试用了,还特地写过一篇文章以示庆祝。那个时候,1.0虽然还还不够完善,功能也不够丰富,但它是XCharts的开始,没有1.0,也就没有后面的2.0和3.0。后面的2.0发布,做了很多改进和优化,随着版本迭代,慢慢的发现有不少硬
文章目录写在前面1、下载与安装(windows)1.1、idea中配置gradle2、基础知识(Gradle6.9为例)2.1、Gradle脚本语法2.1.1、dependsOn2.1.2、创建动态任务2.1.3、增加任务行为2.1.4、参数2.1.5、Ant任务2.1.6、方法2.1.7、默认任务2.1.6、依赖任务的不同输出3、java项目中使用3.1、在已有项目中构建gradle3.2、在新建项目时构建gradle(idea)3.3、gradle项目目录结构3.4、build.gradle3.4.1、plugins3.4.2、repositories3.4.3、dependencies3
文章目录概述背景为何要存算分离优势**应用场景**存算分离产品技术流派华为JuiceFSHashDataXSKY概述背景Hadoop一出生就是奔存算一体设计,当时设计思想就是存储不动而计算(code也即是代码程序)动,负责调度Yarn会把计算任务尽量发到要处理数据所在的实例上,这也是与传统集中式存储最大的不同。为何当时Hadoop设计存算一体的耦合?要知道2006年服务器带宽只有100Mb/s~1Gb/s,但是HDD也即是磁盘吞吐量有50MB/s,这样带宽远远不够传输数据,网络瓶颈尤为明显,无奈之举只好把计算任务发到数据所在的位置。众观历史常言道天下分久必合合久必分,随着云计算技术的发展,数据
目录:一、简介二、HQL的执行流程三、索引四、索引案例五、Hive常用DDL操作六、Hive常用DML操作七、查询结果插入到表八、更新和删除操作九、查询结果写出到文件系统十、HiveCLI和Beeline命令行的基本使用十一、Hive配置一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。特点:简单、容易上手(提供了类似sql的查询语言hql),使得精通sql但是不了解Java编程的人也能很好地进行大数据分析;灵活性高,可以自定义用户函数(UDF)和
本人是音乐爱好者,从小就特别喜欢那个随着音乐跳动的方框效果,就是这个:arduino上一大把对,我忍你很久了,我就想用mpy做,全网没有,行我自己研究。果然兴趣是最好的老师,我之前有篇博客专门讲音频,有兴趣的可以回顾一下。提到可视化频谱,必然绕不开fft,大学学过这玩意,当时一心玩,老师讲的一个字都么听进去,网上教程简略扫了一下,大该就是把时域转频域的工具,我大mpy居然没有fft函数,奶奶的,先放着。音频信息如何收集?第一种傻瓜式的ADC,模拟转数字,原始粗暴,第二种,I2S库,我之前博客有讲过,数据是PCM编码。然后又去学PCM编码,一学豁然开朗,舒服,以代码为例:audio_in=I2S
我以前在Laravel4上工作过,它有一个很棒的日志查看器工具laravellogviewer查看demo我正在寻找与Rubyonrails4.2非常相似的东西,如果你们知道Rails4.2的任何好的可视化日志记录GEM,请告诉我..从代码我需要记录不同的日志级别,这个工具应该直观地组织我的日志,谢谢.. 最佳答案 这应该可以帮助您入门https://github.com/shadabahmed/logstasher如其所说Thisgemisheavilyinspiredfromlograge,butit'sfocusedonone
Iparking停车收费管理系统-可商用介绍Iparking是一款基于springBoot的停车收费管理系统,支持封闭车场和路边车场,支持微信支付宝多种支付渠道,支持多种硬件,涵盖了停车场管理系统的所有基础功能。技术栈Springboot,MybatisPlus,Beetl,Mysql,Redis,RabbitMQ,UniApp功能云端功能序号模块功能描述1系统管理菜单管理配置系统菜单2系统管理组织管理管理组织机构3系统管理角色管理配置系统角色,包含数据权限和功能权限配置4系统管理用户管理管理后台用户5系统管理租户管理多租户管理6系统管理公众号配置租户公众号配置7系统管理操作日志审计日志8系统