这篇博客介绍的是如何在Ubuntu系统下配置YOLOV5算法环境。并且运行一个融合YOLOV5的ORB-SLAM2开源代码。
安装的软件主要是anaconda,然后anaconda可以帮我们安装python、pytorch这些东西。我的ubuntu版本:ubuntu20.04.5LTS。
安装的anaconda类型:Anaconda3-2022.05
安装的python类型:python3.8.15,(原来系统自带的python是3.9.12)
安装的pytorch版本:1.13.0+cu117'
1.先去anaconda官网下载安装包,注意文件后缀是你的系统架构,比如x86、amd64或者aarch64,可以通过下面命令查看。
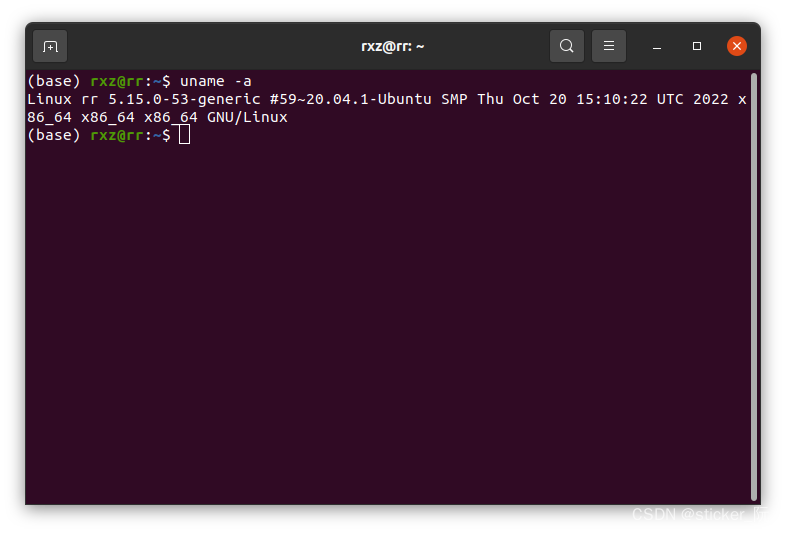
uname -a
像我的系统是这样的:
 官网链接如下:
官网链接如下:
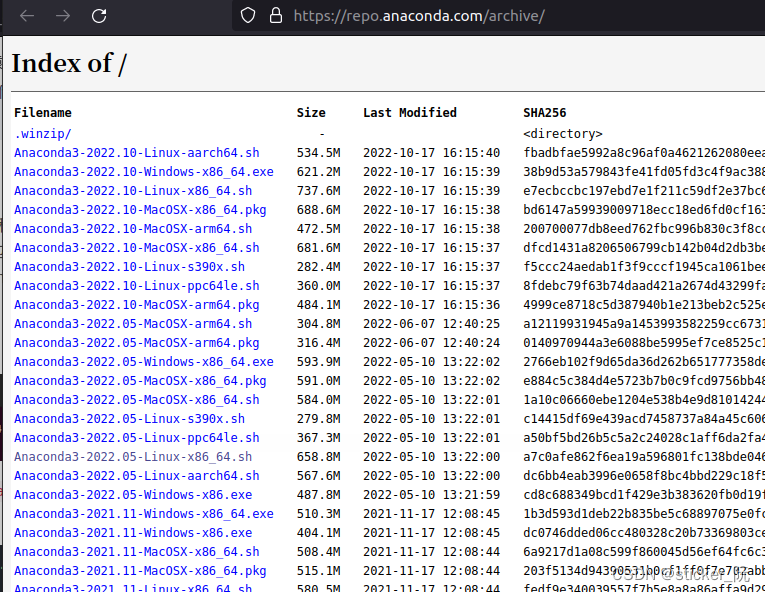
2.选择合适的文件,下载好后,进入下载目录,输入以下代码:
bash Anaconda3-2022.05-Linux-aarch64.sh
随后进行安装,会看到以下画面:

3.一直按ENTER继续,浏览许可证,审查完许可后,将要求您批准许可条款:
Do you approve the license terms? [yes|no]
键入yes接受许可,系统将提示您选择安装位置:
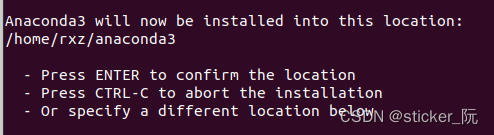
默认位置对于我们大多数用户来说已经就可以,按ENTER确认安装位置。
4.安装可能需要一些时间,完成后,脚本将询问您是否要运行conda init,键入yes。
Installation finished.
Do you wish the installer to initialize Anaconda3
by running conda init? [yes|no]
5.这会将命令行工具conda添加到系统的PATH中。要激活Anaconda安装,您可以关闭并重新打开终端,或者通过键入以下命令来将新的PATH环境变量加载到当前的shell会话中:
source ~/.bashrc
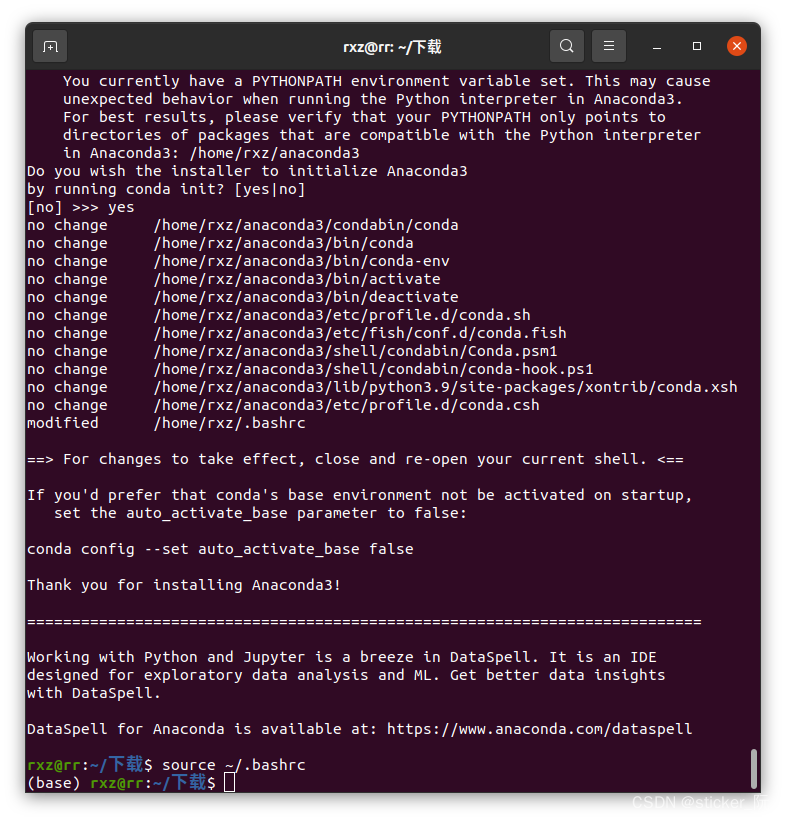
6.这样就是成功了安装了Anaconda。
1.我们创建一个python3.8的名称为yolo的环境。打开终端,输入
conda create -n yolo python=3.8
回车,输入y确定,等待创建成功即可。
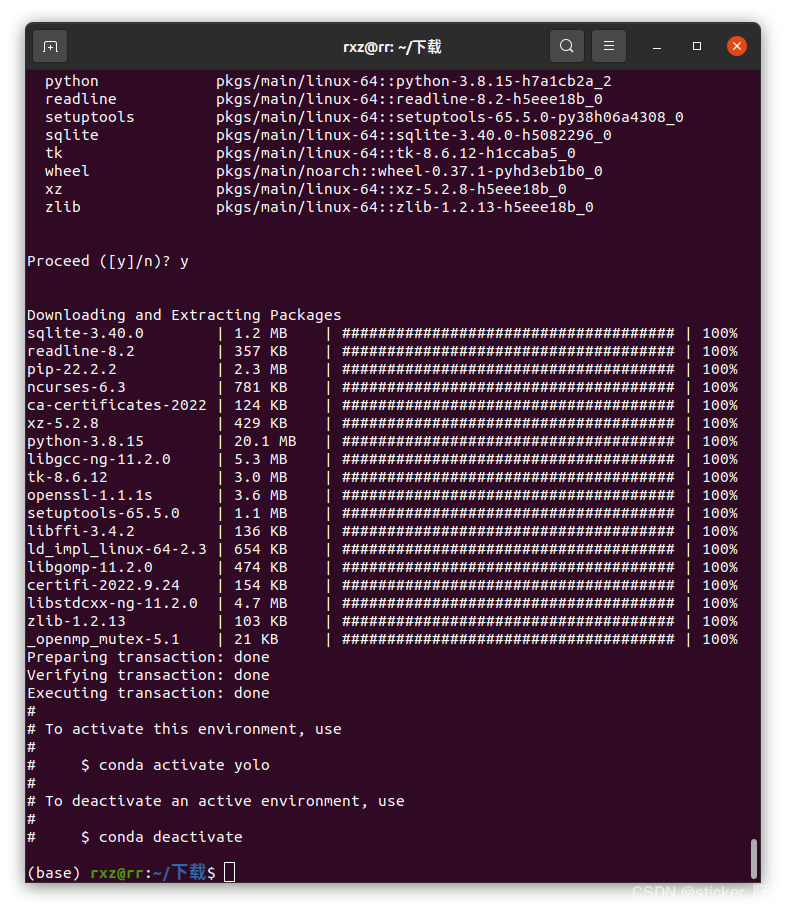
2.创建完成之后,输入命令激活环境:
conda activate yolo
3.下载YOLOV5源码
mirrors / ultralytics / yolov5 · GitCode (这个是被人提供的,里面不包含预训练模型yolov5s.pt文件,但不打紧,后面运行代码的时候会自动生成)
sticker_阮 / YOLOV5源码 · GitCode (这个我的,里面是全的),如下所示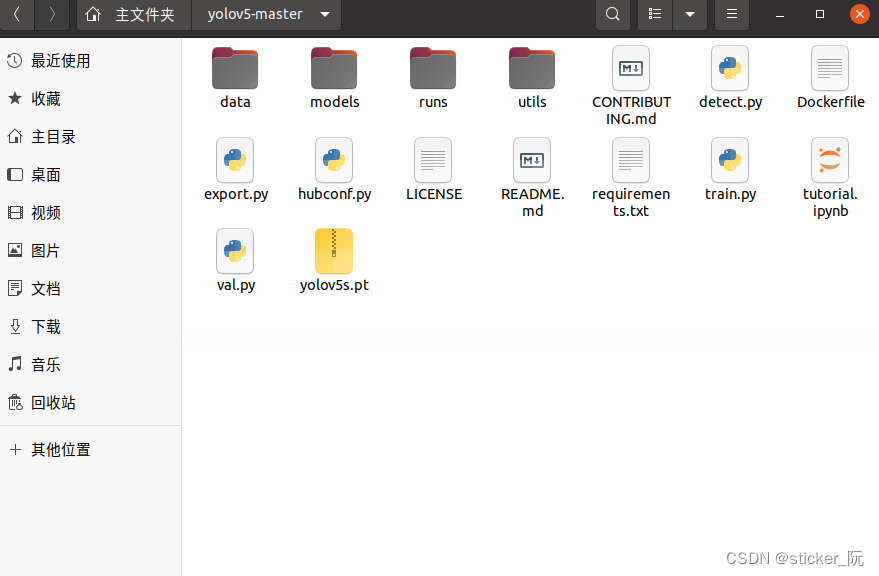
4.修改相应文件
在下载好的yolov5-master文件夹下找到requirements.txt文件,修改成以下形式:
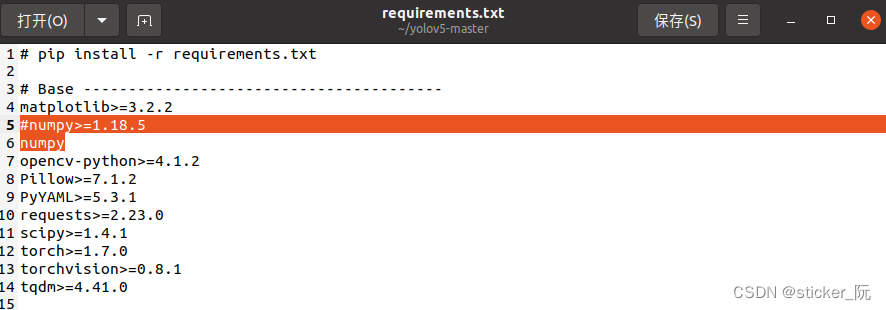
5.随后在yolov5-master文件夹下打开终端,并输入以下命令,来添加依赖:
pip3 install -U -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
可能会出现的错误:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
daal4py 2021.5.0 requires daal==2021.4.0, which is not installed.
conda-repo-cli 1.0.4 requires pathlib, which is not installed.
anaconda-project 0.10.2 requires ruamel-yaml, which is not installed.
numba 0.55.1 requires numpy<1.22,>=1.18, but you have numpy 1.23.5 which is incompatible.
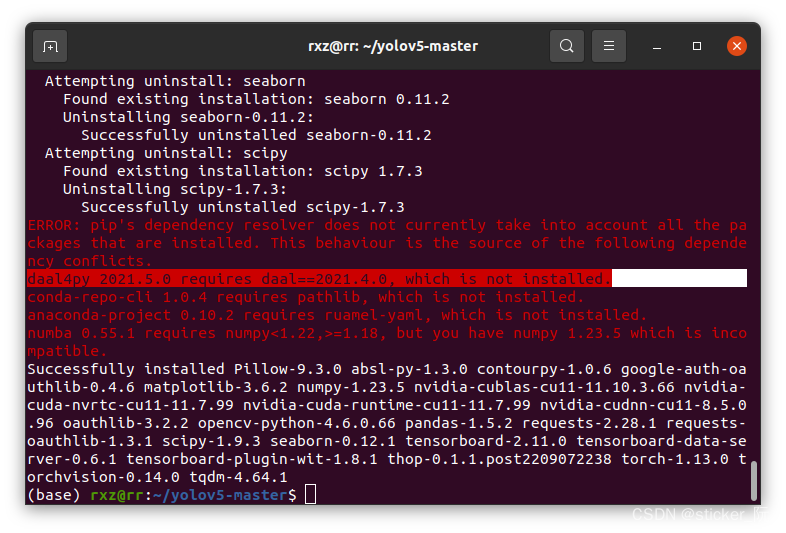
解决方法:按照错误提示,安装相应版本的包
pip install daal==2021.4.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pathlib
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple ruamel-yaml
依赖安装好后如下:
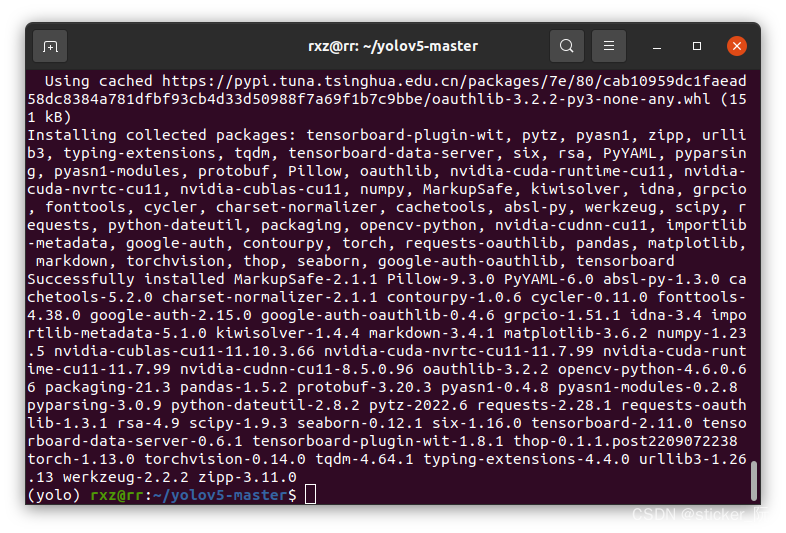
至此,yolo所需的环境配置完成。
参考链接:
各种错误_steven_bingo的博客-CSDN博客_daal==2021.4.0
6.测试
(1).先进入创建好的yolo环境
conda activate yolo
在yolov5-master文件下打开终端,并输入以下命令:
python detect.py --source data/images/zidane.jpg
这时候,最后的效果会保存在runs/detect/下
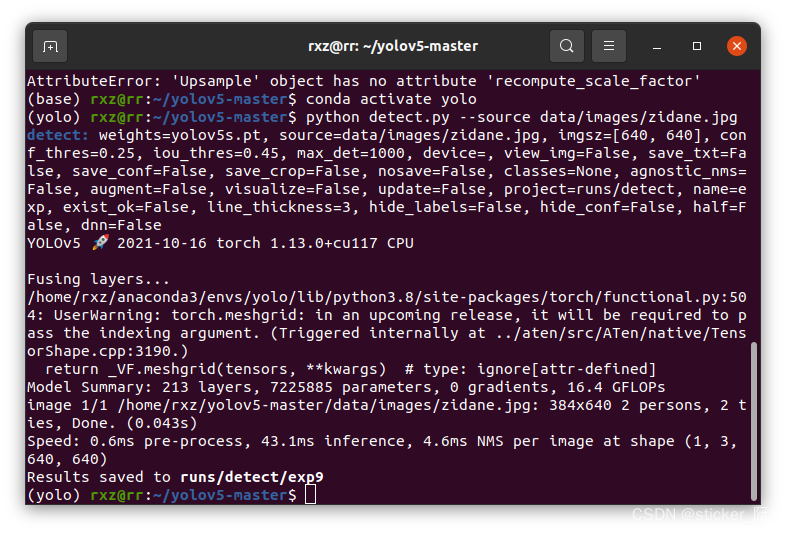

(在这个时候,如果之前下的是别人的代码,会生成run文件夹)
如果出现以下问题:
AttributeError: 'Upsample' object has no attribute 'recompute_scale_factor'
参考:
一步真实解决AttributeError: ‘Upsample‘ object has no attribute ‘recompute_scale_factor‘_蓝胖胖▸的博客-CSDN博客
(2)第二个测试是利用VS code跑的
首先找到detect.py文件,修改以下代码中的source:改成0则为调用电脑自带的摄像头。
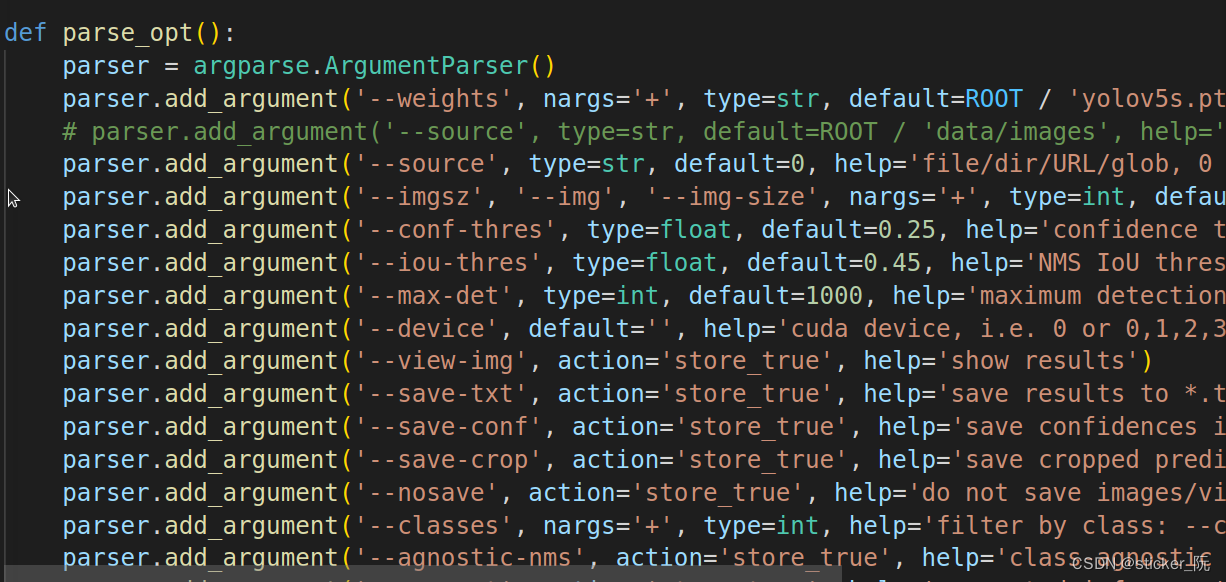
然后终端进入我们创建的yolo环境,输入python detect.py即可运行。
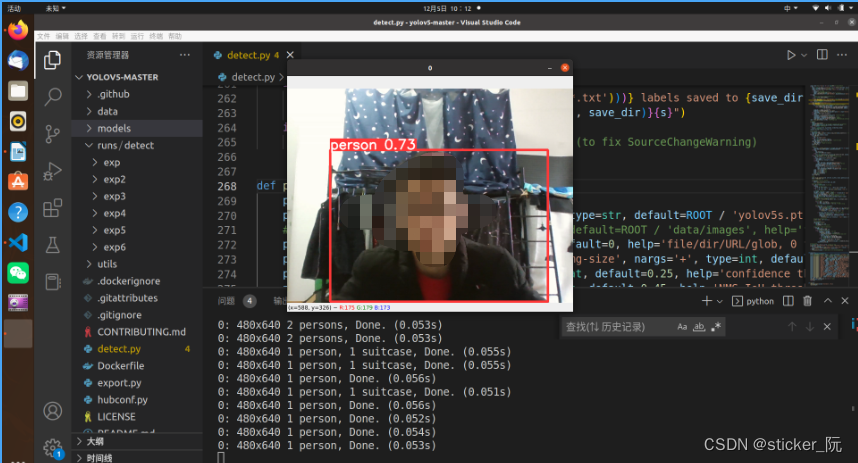
conda的一些指令:
(1)conda activate yolo //激活(进入)yolo虚拟环境中
或 source activate yolo
(2)conda list //查看在虚拟环境中安装的包
(3)python //查看虚拟环境中python 的版本
import torch
torch._version_//查看torch版本
ctrl+D退出python
(4)如果安装了独显
nvidia-smi //可查看是否安装成功
或看
python
>>>import torch
>>>torch.cuda.is_available //查看是否为true
(5)conda deactivate //退出当前虚拟环境
(6)conda env list//查看创建的虚拟环境有哪些
7.接下来将YOLOV5代码加入到ORB-SLAM2中
源代码和相关数据集可见以下链接:
sticker_阮 / YOLOv5融合orb-SLAM2 · GitCode
如果按照我之前的环境配置,那么运行这个代码就比较简单了。下载我的源代码,还需要下载一个associate.py来处理rgb.txt和depth.txt,生成配对的文件associate.txt,输入以下指令:
python associate.py rgb.txt depth.txt > associate.txt
如果出现以下报错
Traceback (most recent call last):
File "associate.py", line 118, in <module>
matches = associate(first_list, second_list,float(args.offset),float(args.max_difference))
File "associate.py", line 97, in associate
first_keys.remove(a)
AttributeError: 'dict_keys' object has no attribute 'remove'
由于Python2和python3语法的差别,需要将associate.py中第86行87行的
first_keys = first_list.keys() second_keys = second_list.keys()修改为:
first_keys = list(first_list.keys()) second_keys = list(second_list.keys())
最后,打开orbslam_addsemantic-main文件夹终端,输入以下命令即可:
在终端输入的指令:
加YOLOV5算法:
./Examples/RGB-D/rgbd_tum Vocabulary/ORBvoc.txt Examples/RGB-D/TUM3.yaml /home/rxz/rgbd_dataset_freiburg3_walking_xyz /home/rxz/rgbd_dataset_freiburg3_walking_xyz/associate.txt detect_result/TUM_f3xyz_yolov5m/detect_result/
纯ORB-SLAM2算法:
./Examples/RGB-D/rgbd_tum Vocabulary/ORBvoc.txt Examples/RGB-D/TUM3.yaml /home/rxz/rgbd_dataset_freiburg3_walking_xyz /home/rxz/rgbd_dataset_freiburg3_walking_xyz/associate.txt
参考链接:
SLAM TUM数据集associate.py使用及错误解决_月逐丶的博客-CSDN博客
Ubuntu20.04部署yolov5目标检测算法,无人车/无人机应用_振华OPPO的博客-CSDN博客_yolo可以部署到无人机上么
https://blog.csdn.net/weixin_51745352/article/details/124646456
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
这是一道面试题,我没有答对,但还是很好奇怎么解。你有N个人的大家庭,分别是1,2,3,...,N岁。你想给你的大家庭拍张照片。所有的家庭成员都排成一排。“我是家里的friend,建议家庭成员安排如下:”1岁的家庭成员坐在这一排的最左边。每两个坐在一起的家庭成员的年龄相差不得超过2岁。输入:整数N,1≤N≤55。输出:摄影师可以拍摄的照片数量。示例->输入:4,输出:4符合条件的数组:[1,2,3,4][1,2,4,3][1,3,2,4][1,3,4,2]另一个例子:输入:5输出:6符合条件的数组:[1,2,3,4,5][1,2,3,5,4][1,2,4,3,5][1,2,4,5,3][
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
GivenIamadumbprogrammerandIamusingrspecandIamusingsporkandIwanttodebug...mmm...let'ssaaay,aspecforPhone.那么,我应该把“require'ruby-debug'”行放在哪里,以便在phone_spec.rb的特定点停止处理?(我所要求的只是一个大而粗的箭头,即使是一个有挑战性的程序员也能看到:-3)我已经尝试了很多位置,除非我没有正确测试它们,否则会发生一些奇怪的事情:在spec_helper.rb中的以下位置:require'rubygems'require'spork'
是否有可能:before_filter:authenticate_user!||:authenticate_admin! 最佳答案 before_filter:do_authenticationdefdo_authenticationauthenticate_user!||authenticate_admin!end 关于ruby-on-rails-before_filter运行多个方法,我们在StackOverflow上找到一个类似的问题: https://