当前git是大部分开发团队的首选版本管理工具,一个好的流程规范可以让大家有效地合作,像流水线一样有条不紊地进行团队协作。
业界包含三种flow:
下面我们先来分析,然后再基于gitlab flow来设计一个适合我们团队的git规范。
先说git flow,大概是这样的。
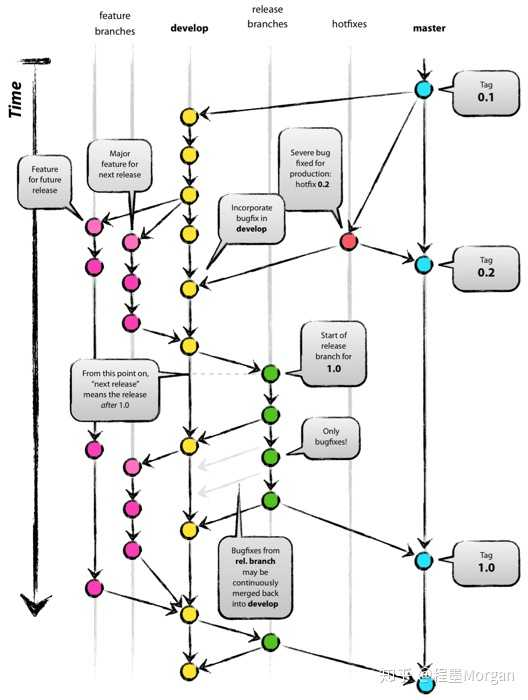
然后,我们老的git规范是参考git flow实现的。

综合考虑了开发、测试、新功能开发、临时需求、热修复,理想很丰满,现实很骨干,这一套运行起来实在是太复杂了。那么如何精简流程呢?
我们来看业界的做法,首先是github flow。
Github flow 是Git flow的简化版,专门配合”持续发布”。它是 Github.com 使用的工作流程。
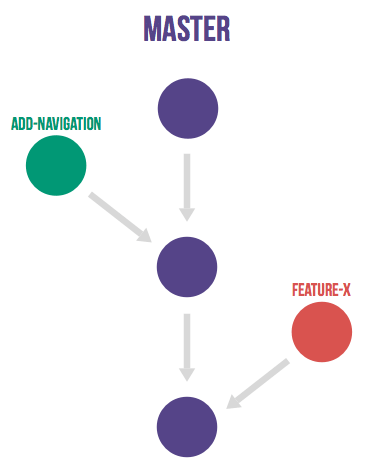
整个流程:

github flow这种方式,要保证高质量,对于贡献者的素质要求很高,换句话说,如果代码贡献者素质不那么高,质量就无法得到保证。
Gitlab flow 是 Git flow 与 Github flow 的综合。它吸取了两者的优点,既有适应不同开发环境的弹性,又有单一主分支的简单和便利。它是 Gitlab.com 推荐的做法。
Gitlab flow 的最大原则叫做”上游优先”(upsteam first),即只存在一个主分支master,它是所有其他分支的”上游”。只有上游分支采纳的代码变化,才能应用到其他分支。只有紧急情况,才允许跳过上游,直接合并到下游分支。
对于”持续发布”的项目,它建议在master分支以外,再建立不同的环境分支。比如,”开发环境”的分支是master,”预发环境”的分支是pre-production,”生产环境”的分支是production。
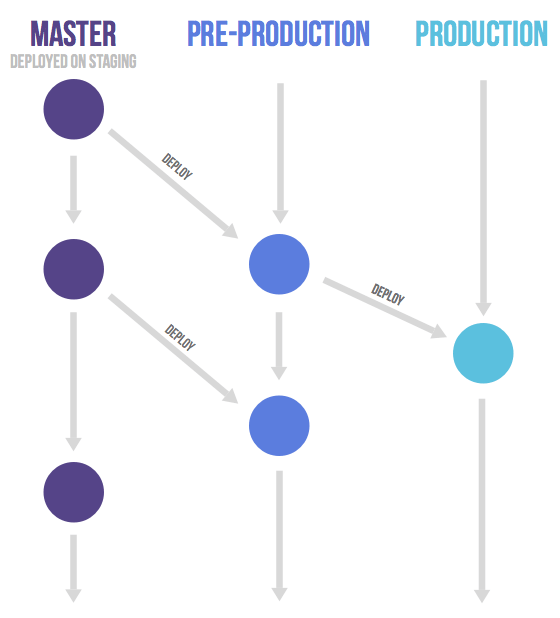
对于”版本发布”的项目,建议的做法是每一个稳定版本,都要从master分支拉出一个分支,比如2-3-stable、2-4-stable等等。

gitlab flow 如何处理hotfix? git flow之所以这么复杂,一大半原因就是把hotfix考虑得太周全了。hotfix的意思是,当代码部署到产品环境之后发现的问题,需要火速fix。gitlab flow 可以基于后续分支,修改后上线。
综合上面的介绍,我们决定采用gitlab flow,按照版本发布的模式实施,具体来说:
新建分支,比如feat-test

开发代码,增加新功能,提交:
@GetMapping(path = "/test", produces = "application/json")
@ResponseBody public Map<String, Object> test()
{ return singletonMap("test", "test");
}git commit -m "feat: add test code"
git push origin feat-test提交代码后,可以提交mr到master,申请合并代码

Note:
研发组长,打开mr,review代码,可以添加建议:
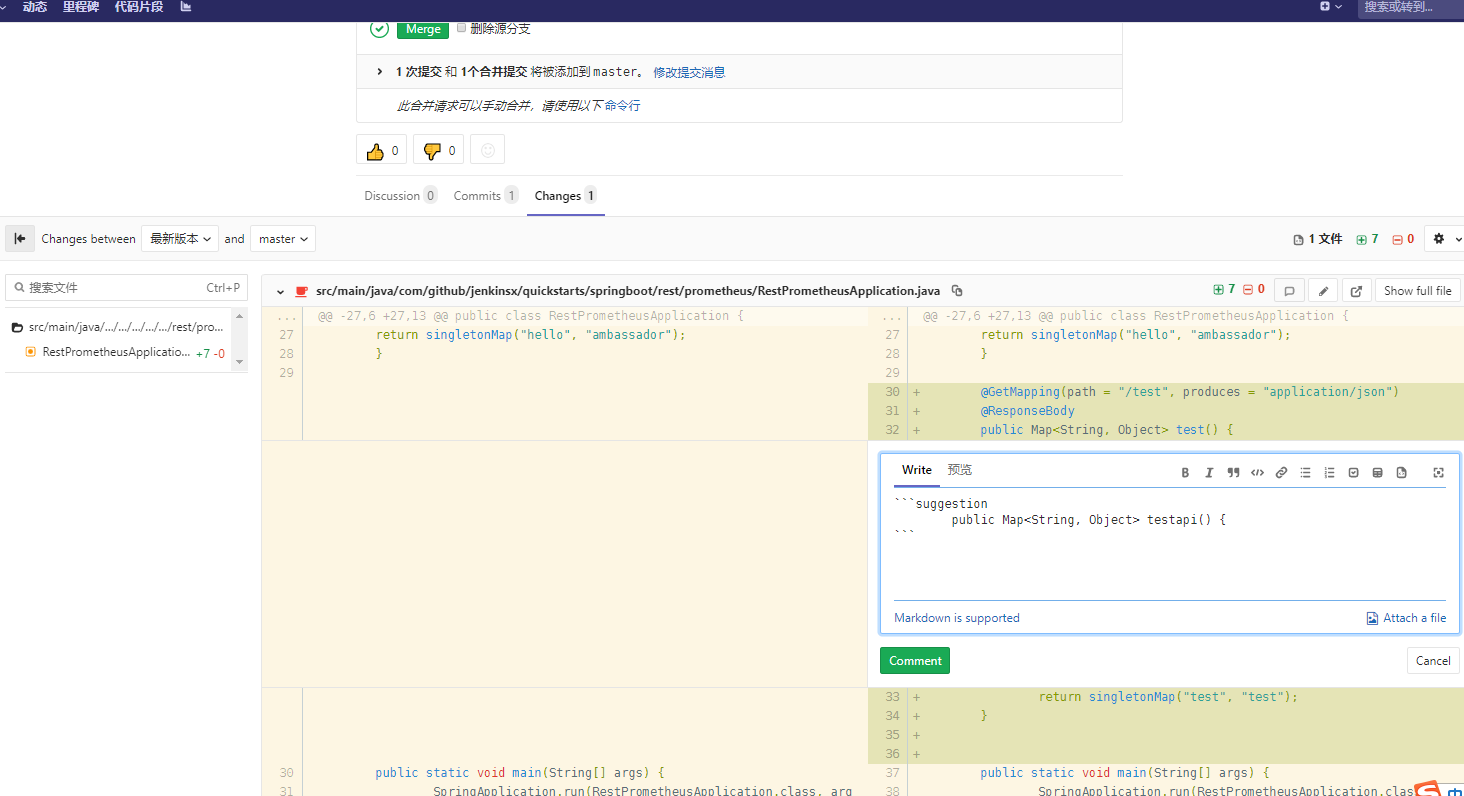
开发同学根据建议修复代码,或者线下修改后commit代码。
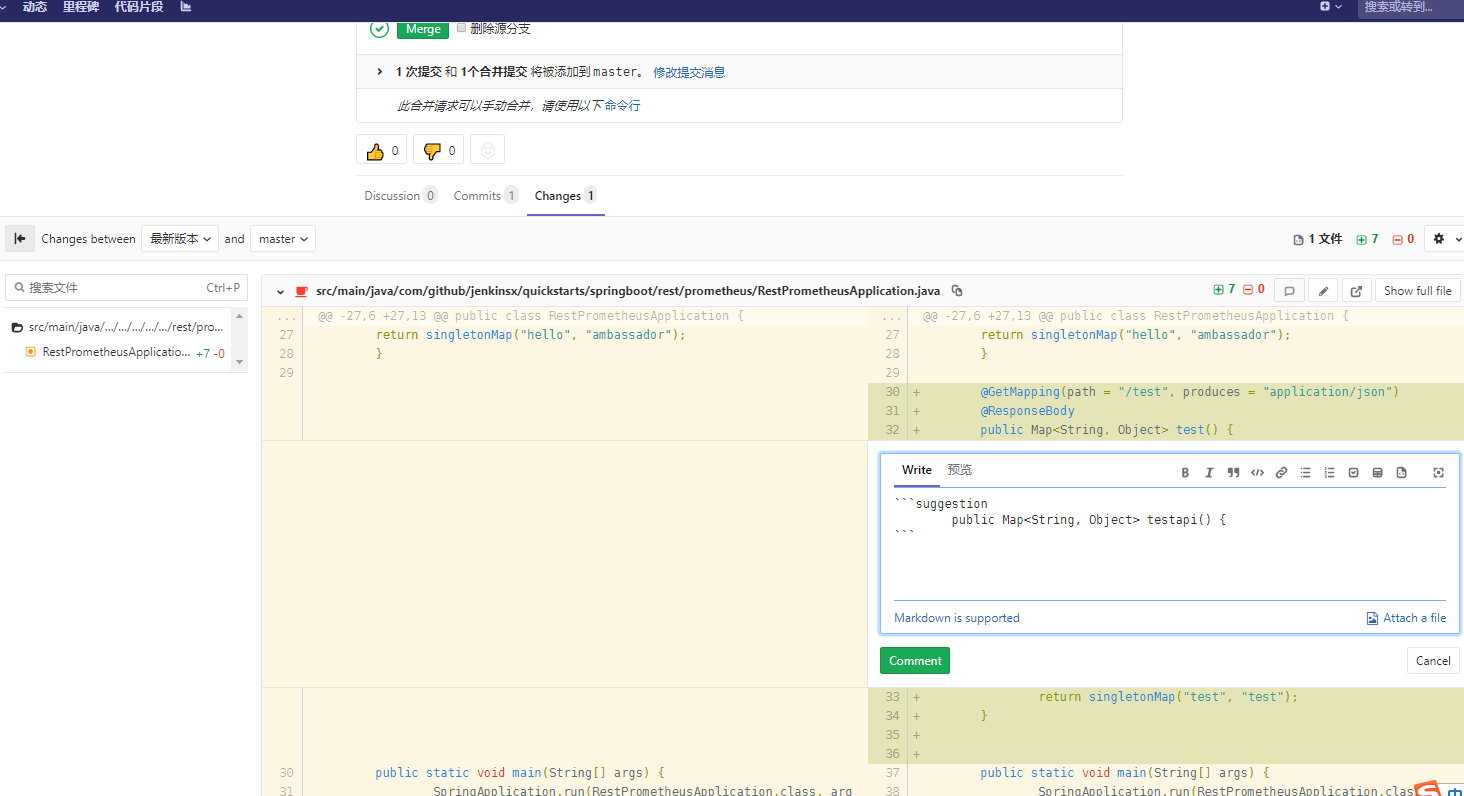
研发组长确认没有问题后,可以合并到master。
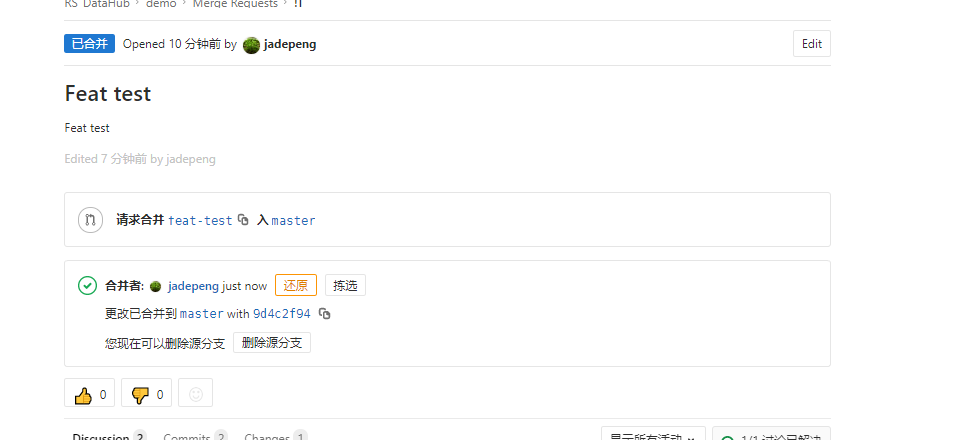
合并完成,可以删除feat分支。
新功能开发好,可以进行提测。
语义化版本号#
版本格式:主版本号.次版本号.修订号,版本号递增规则如下:
主版本号:当你做了不兼容的 API 修改,
次版本号:当你做了向下兼容的功能性新增,
修订号:当你做了向下兼容的问题修正。
先行版本号及版本编译元数据可以加到“主版本号.次版本号.修订号”的后面,作为延伸。
主版本号为0,代表还未发布正式版本。
测试发布#
master分支,自动部署到开发环境(dev)
功能开发完成,并自测通过后,代码合并到待发布版本,
分支规则:
release-version
版本规则
主版本号.次版本号
构建时,自动增加修订号:
主版本号.次版本号.修订号
从最新的master新拉一个分支release-$version,比如release-0.1
git checkout -b release-0.1
release-$version会自动构建,版本号为$version.$buildNumber
设定release-$version 分支为保护分支,不允许直接推送,只能通过merge不允许直接提交代码,接受MR。
bug修复#
需要修改bug时,从release-$version新拉分支,修改完成后再合并到release-$version分支.
Q: 从release-$version拉的分支,如何测试?
A: 这个节点定义为bug修复节点,建议开发同学优先本地测试验证,验证通过再合并到release分支。
Q: release-$version太多怎么办?
A: 可以保留最近的10个版本。历史的打tag后,删除分支。
1.在gitlab中将主仓库fork到个人仓库
- Fork 出来的仓库完全属于你自己,你可以任意修改该仓库的代码及配置,但是除非你向项目主仓库提交 pull request,并且被接受通过,你才可以将你fork 仓库修改的代码合并到主仓库,否则不会对主仓库产生任何影响。
- 一般来讲,
pull代码,需要从主仓库拉取最新的代码;push的话,则只能严格推送到个人的子仓库。这里需要在gitlab中做好权限的分配(这是管理工作)。
2.保持个人仓库和 upstream 同步
- 这里需要注意,建议每天开发工作开始前,将
upstream的代码更新到本地
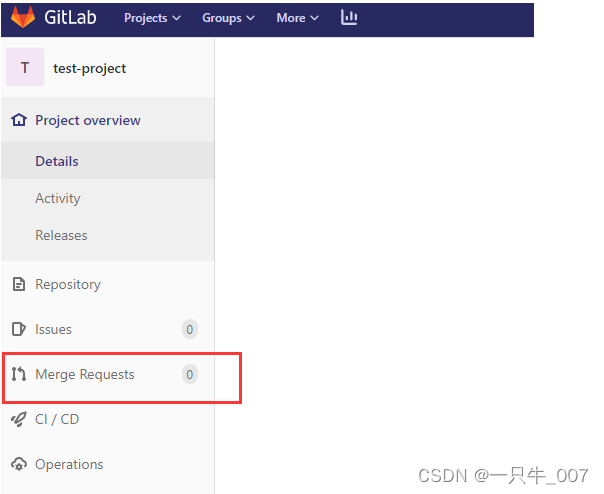
发起 pull request 或 merge request > - github -> pull request > - gitlab -> merge request > 1. 在 gitlab 的个人仓库页面的左边菜单点击merge request (👋记住是个人仓库)
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
我有一个应用需要发送用户事件邀请。当用户邀请friend(用户)参加事件时,如果尚不存在将用户连接到该事件的新记录,则会创建该记录。我的模型由用户、事件和events_user组成。classEventdefinvite(user_id,*args)user_id.eachdo|u|e=EventsUser.find_or_create_by_event_id_and_user_id(self.id,u)e.save!endendend用法Event.first.invite([1,2,3])我不认为以上是完成我的任务的最有效方法。我设想了一种方法,例如Model.find_or_cr
我似乎经常遇到一些设计问题,但我不知道是什么是真的很合适。一方面我经常听到我应该限制耦合和坚持单一职责,但当我这样做时,我常常发现它很困难到在需要时将信息获取到程序的一部分。为了例如,classSingerdefinitialize(name)@name=nameendattr:nameend那么Song应该是:classSongdefnew(singer)@singer=singerendend或classSongdefnew(singer_name)@singer_name=singer_nameendend后者耦合性小,按道理应该用。但如果我以后发现宋有什么需要了解更多歌手,我的
我需要使用ActiveMerchant库在我们的一个Rails应用程序中设置支付解决方案。尽管这个问题非常主观,但人们对主要网关(BrainTree、Authorize.net等)的体验如何?它必须:处理定期付款。有能力记入个人帐户。能够取消付款。有办法存储用户的付款详细信息(例如Authotize.netsCIM)。干杯 最佳答案 ActiveMerchant很棒,但在过去一年左右的时间里,我在使用它时发现了一些问题。首先,虽然某些网关可能会得到“支持”——但并非所有功能都包含在内。查看功能矩阵以确保完全支持您选择的网关-http
我有一个像这样的ruby散列{"stuff_attributes"=>{"1"=>{"foo"=>"bar","baz"=>"quux"},"2"=>{"foo"=>"bar","baz"=>"quux"}}}我想把它变成一个看起来像这样的散列{"stuff_attributes"=>[{"foo"=>"bar","baz"=>"quux"},{"foo"=>"bar","baz"=>"quux"}]}我还需要保留键的数字顺序,并且键的数量是可变的。上面是super简化的,但我在底部包含了一个真实的例子。执行此操作的最佳方法是什么?附言还需要递归就递归而言,这是我们可以假设的:1)
参见下面的示例,我想最好使用第二种方法,但第一种也可以。哪种方法最好,使用另一种的后果是什么?classTestdefstartp"started"endtest=Test.newtest.startendclassTest2defstartp"started"endendtest2=Test2.newtest2.start 最佳答案 我肯定会说第二种变体更有意义。第一个不会导致错误,但对象实例化完全过时且毫无意义。外部变量在类的范围内不可见:var="string"classAvar=A.newendputsvar#=>strin