IDEA2020.2.3版本:https://www.cnblogs.com/liugp/p/13868346.html
最新版本安装详情请参考:https://www.jb51.net/article/196349.htm
可以看我之前的文章:大数据Hadoop之——部署hadoop+hive环境(window10环境)
当然也可以部署在linux系统上,远程连接,可以参考以下两篇文章:
大数据Hadoop原理介绍+安装+实战操作(HDFS+YARN+MapReduce)
大数据Hadoop之——数据仓库Hive
可以看我之前的文章:Java-Maven详解
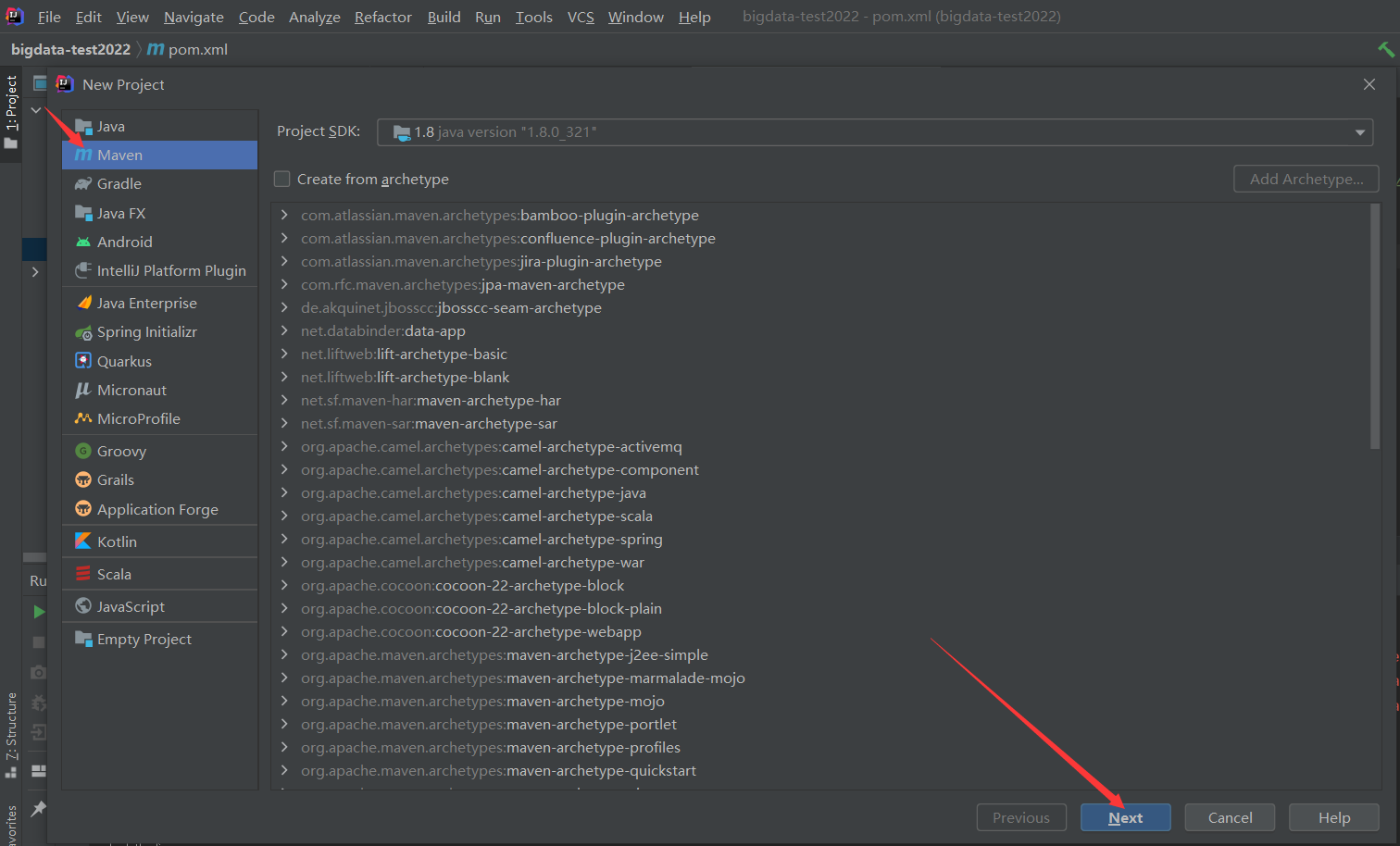
因为之前我创建过了,所以会标红
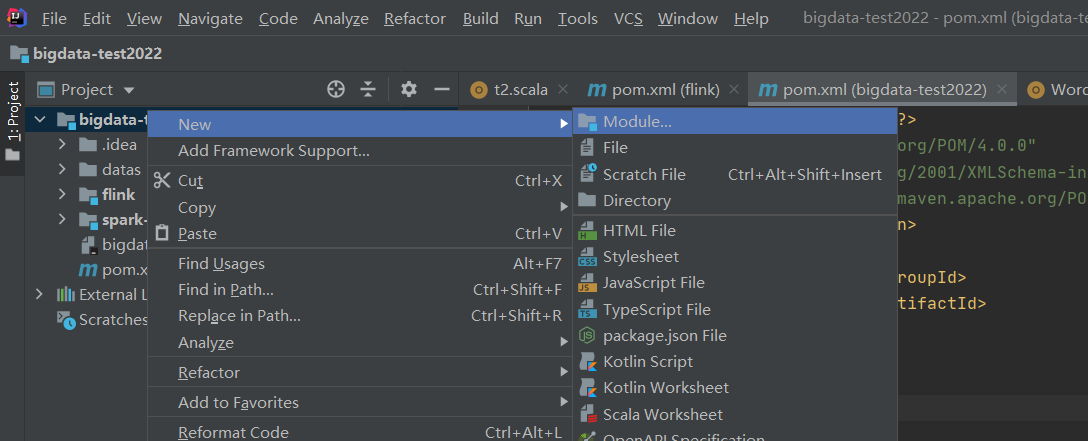
把自动生成的src删掉,以后是通过模块来管理项目,因为一个项目一般会包含很多模块。
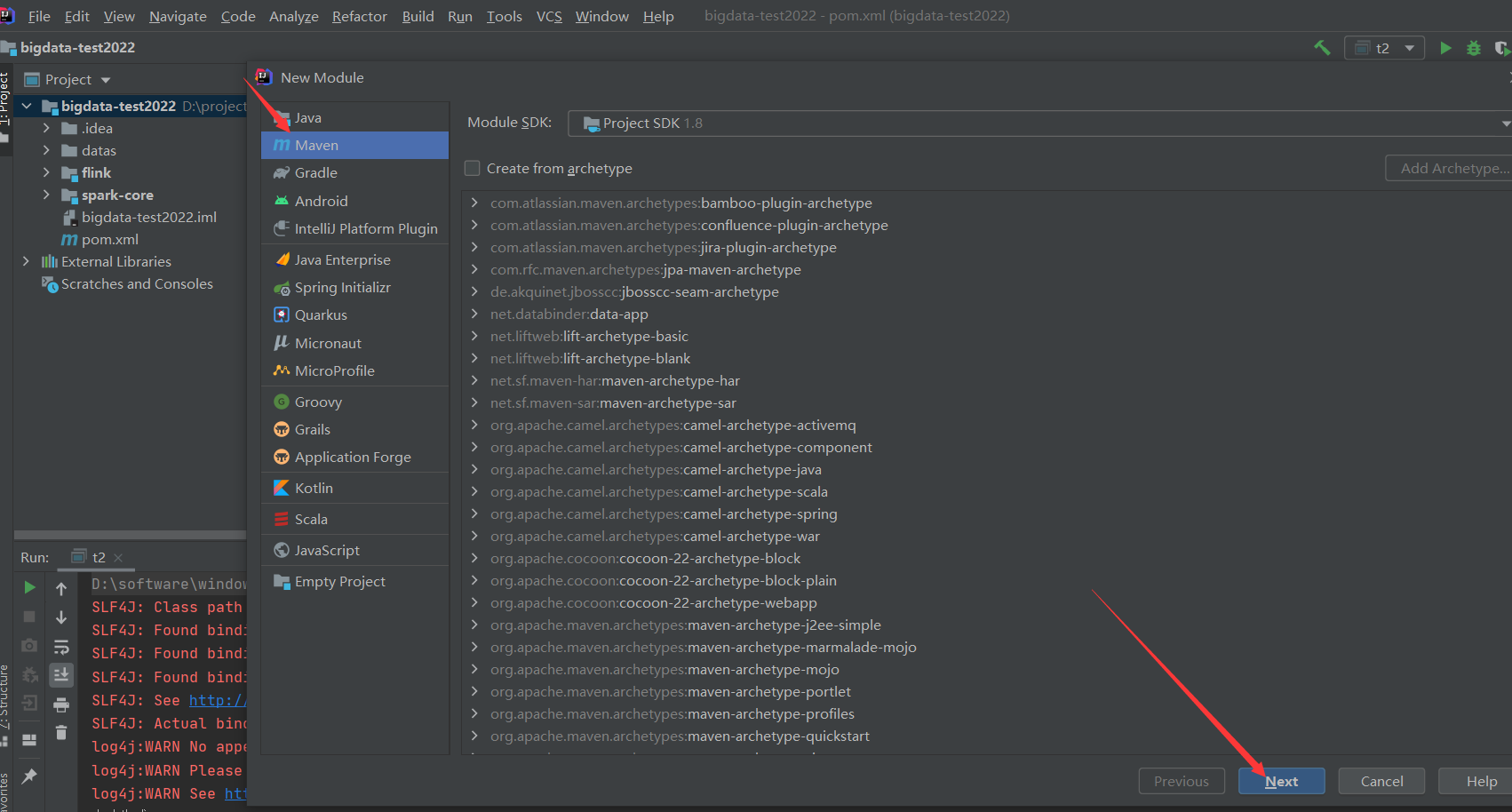
目录结构,新建没有的目录
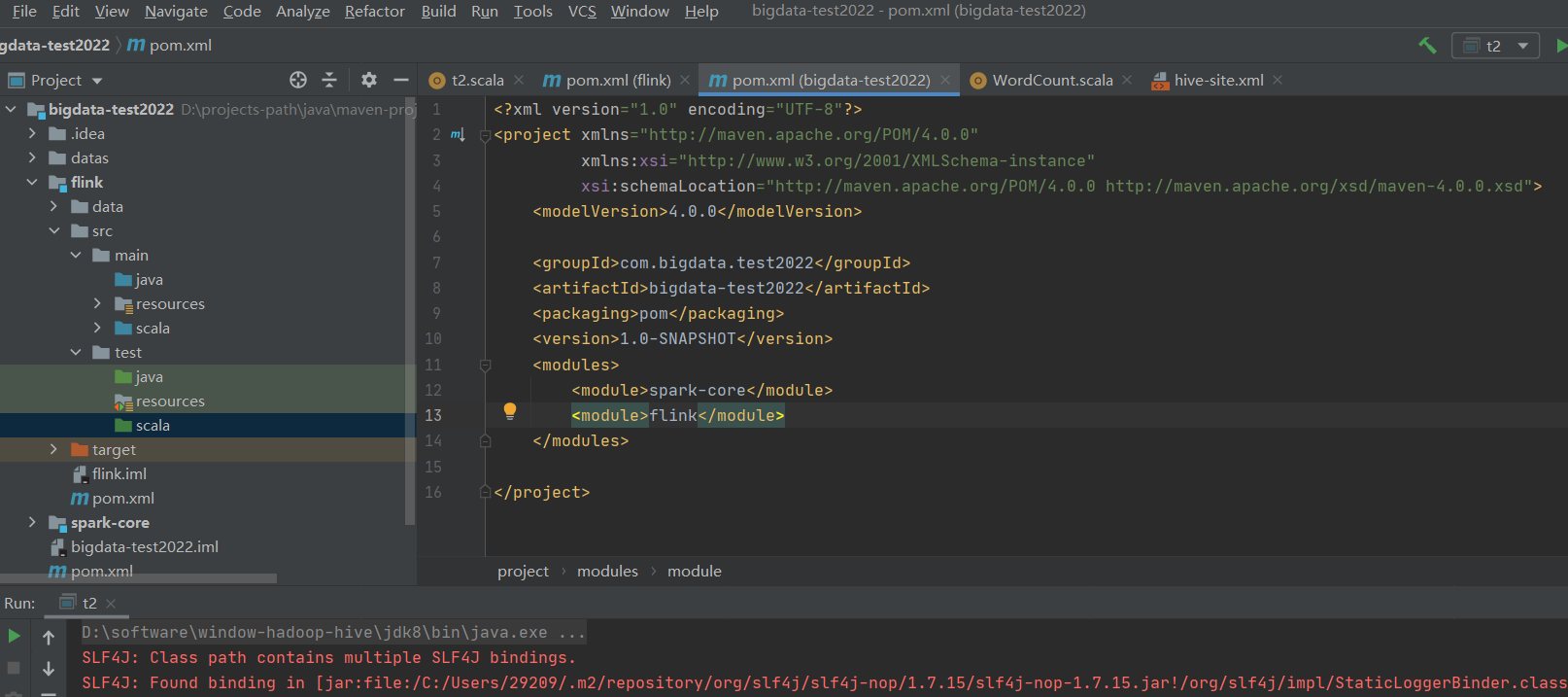
设置目录属性
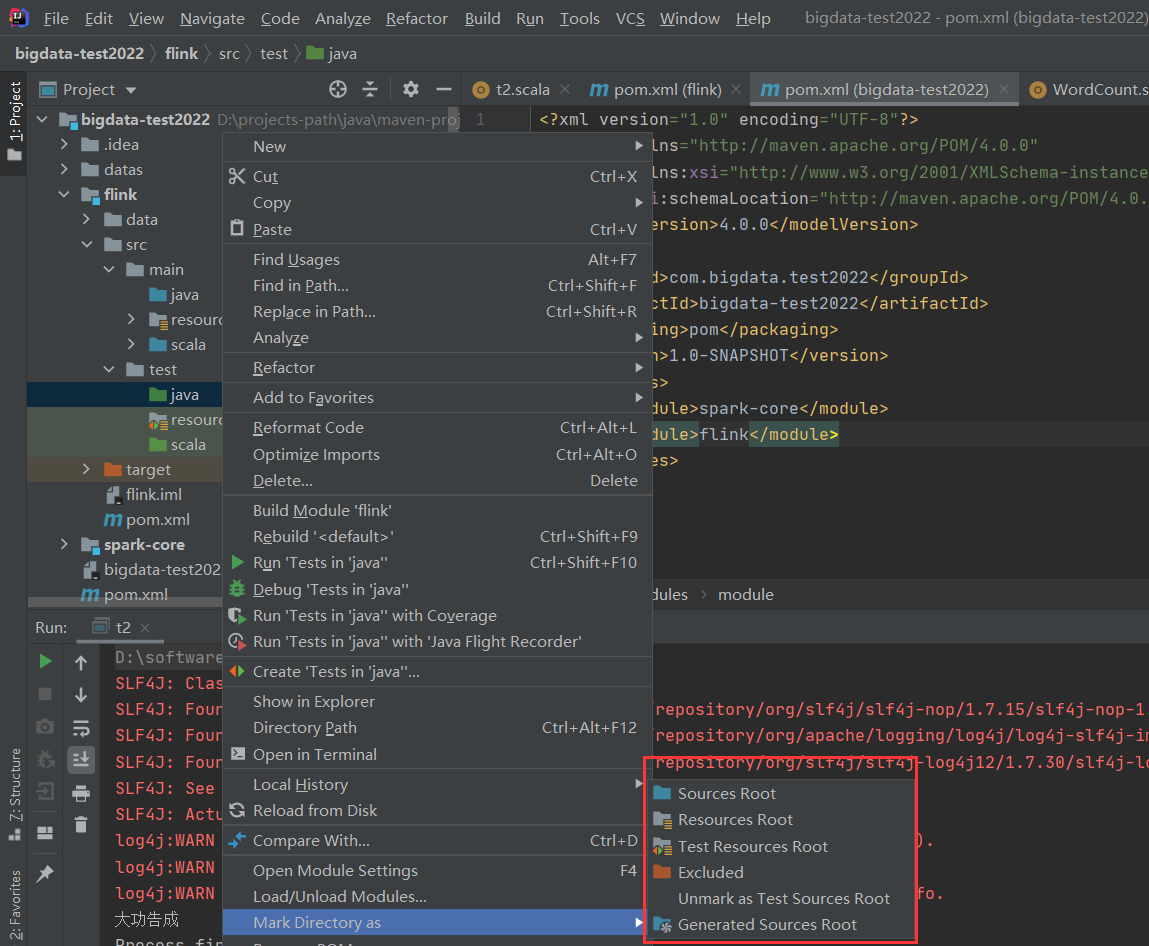
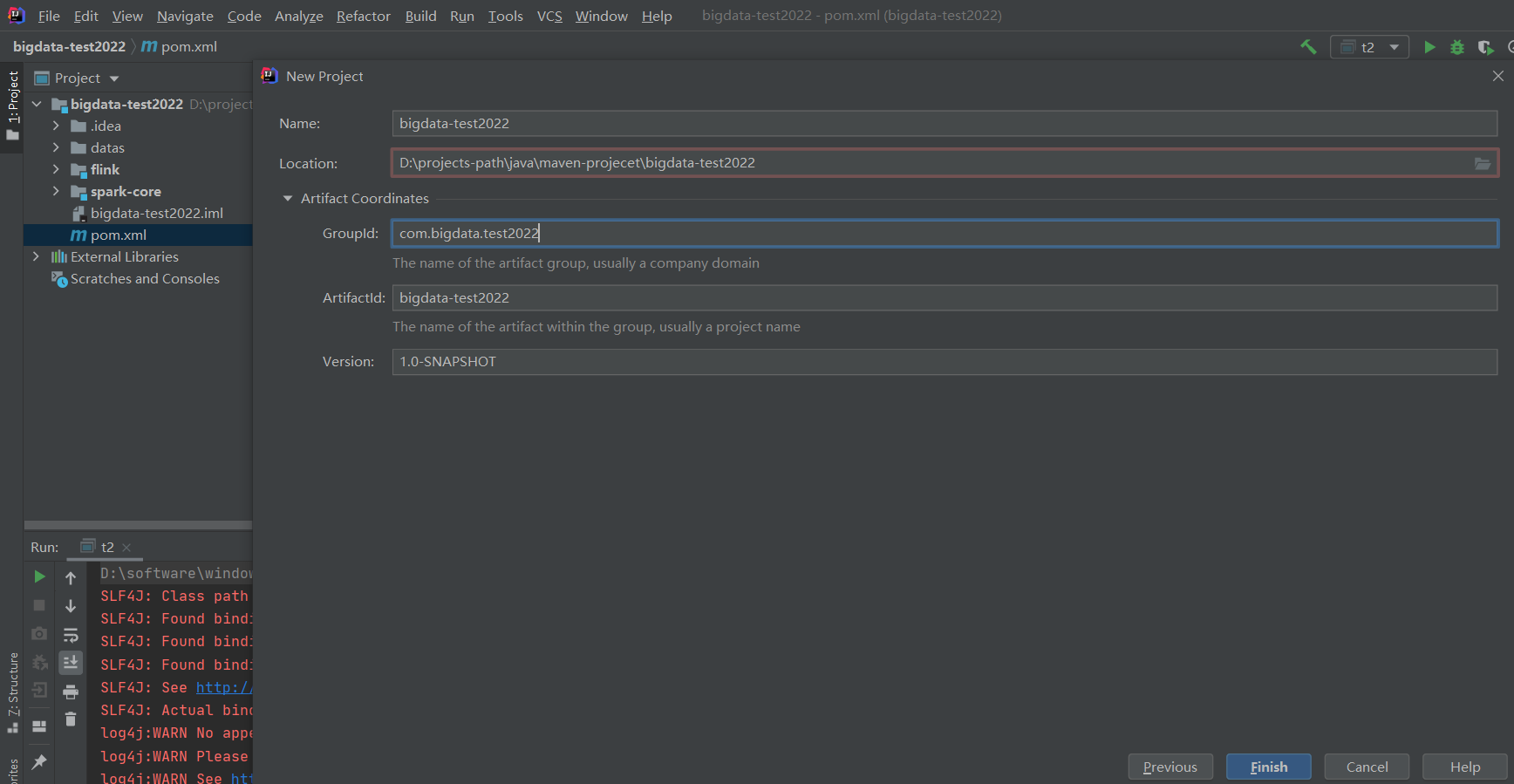
因为之前创建过项目,所以这里创建一个新项目来演示:bigdata-test2023
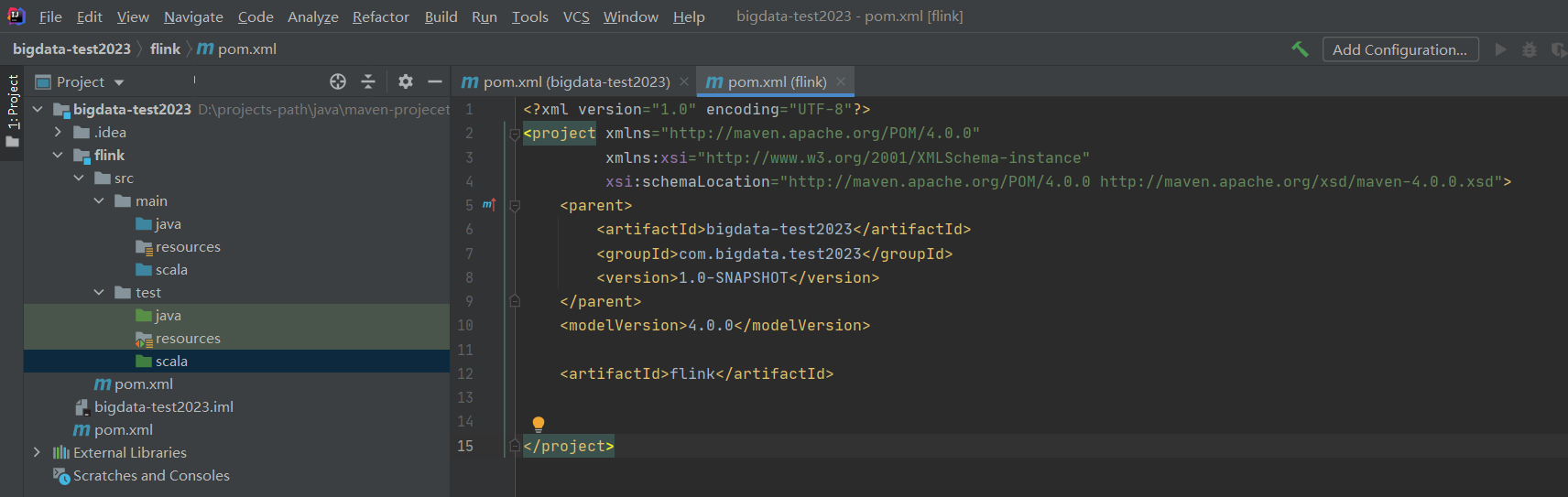
File-》Settings
intellij IDEA本来是不能开发Scala程序的,但是通过配置是可以的,我之前已经装过了,没装过的小伙伴,点击这里安装即可。
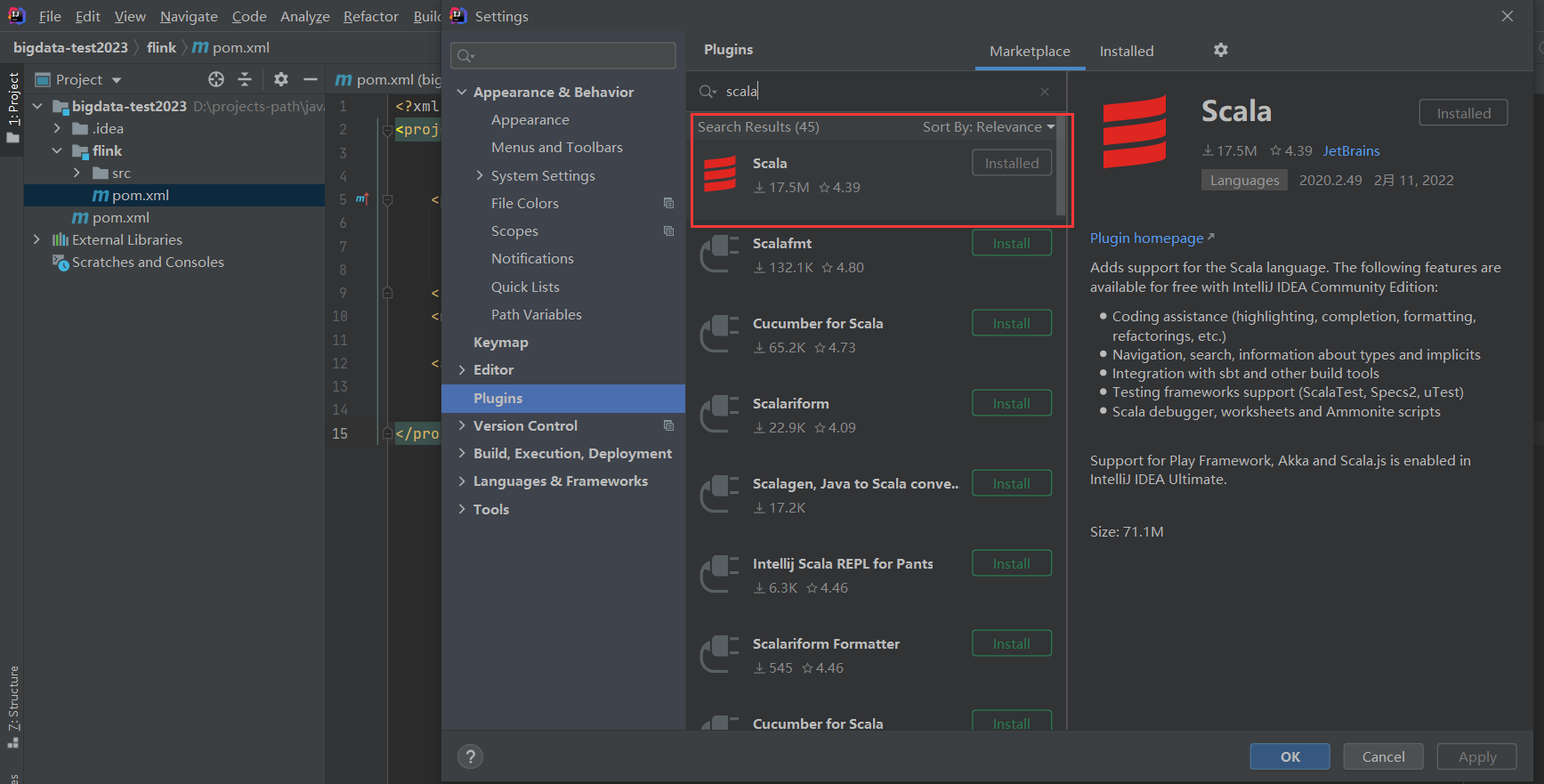
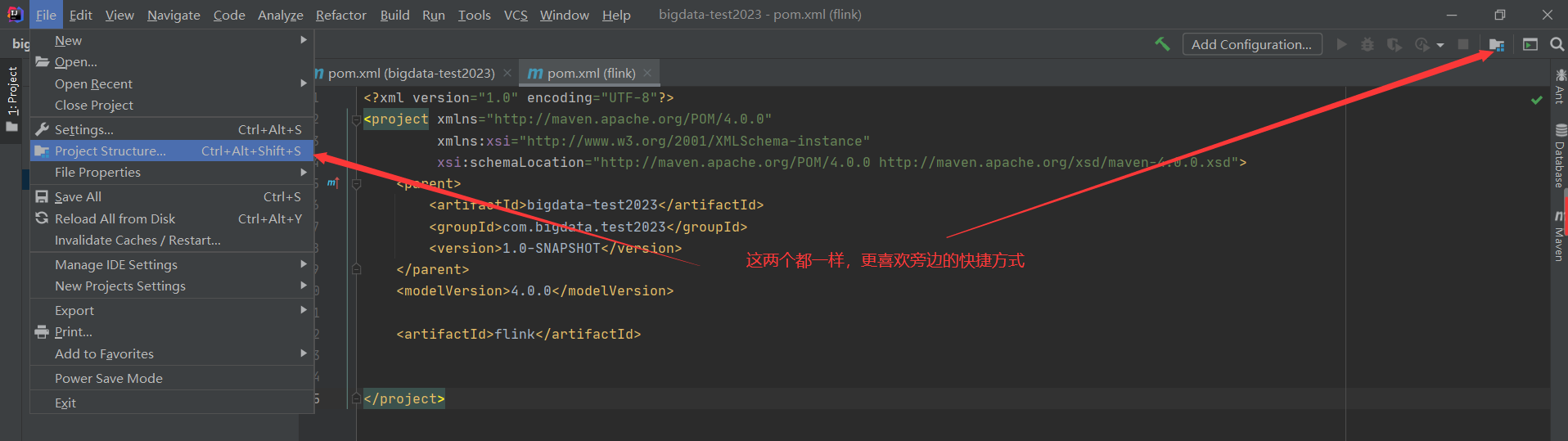
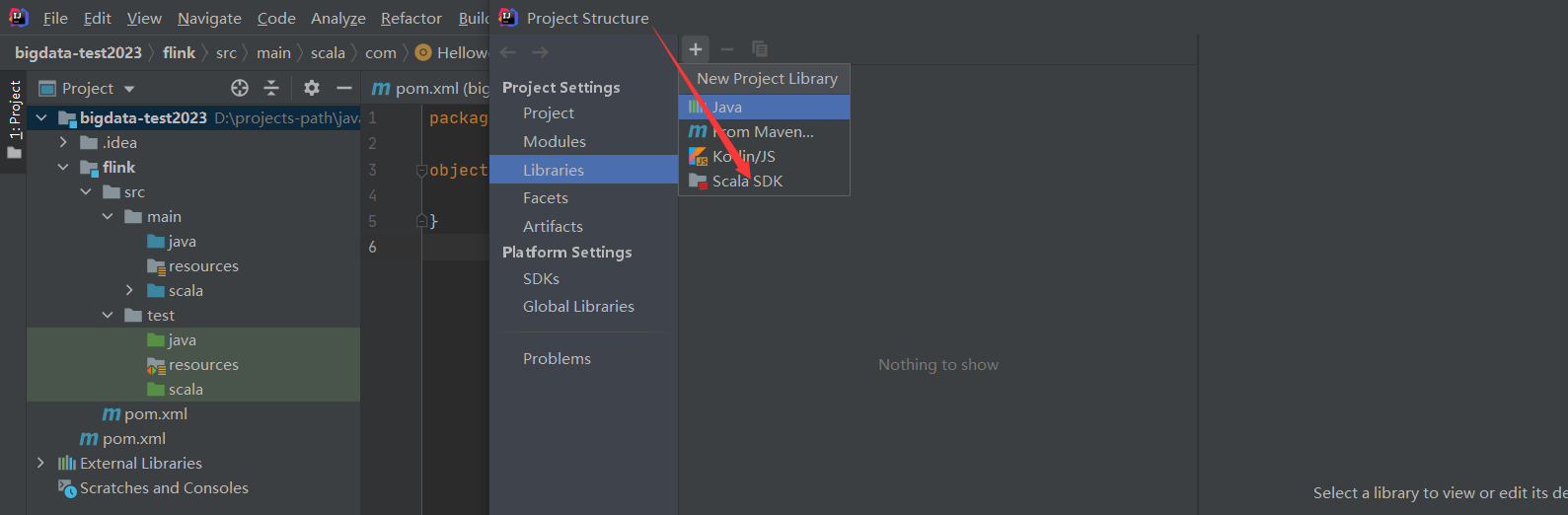
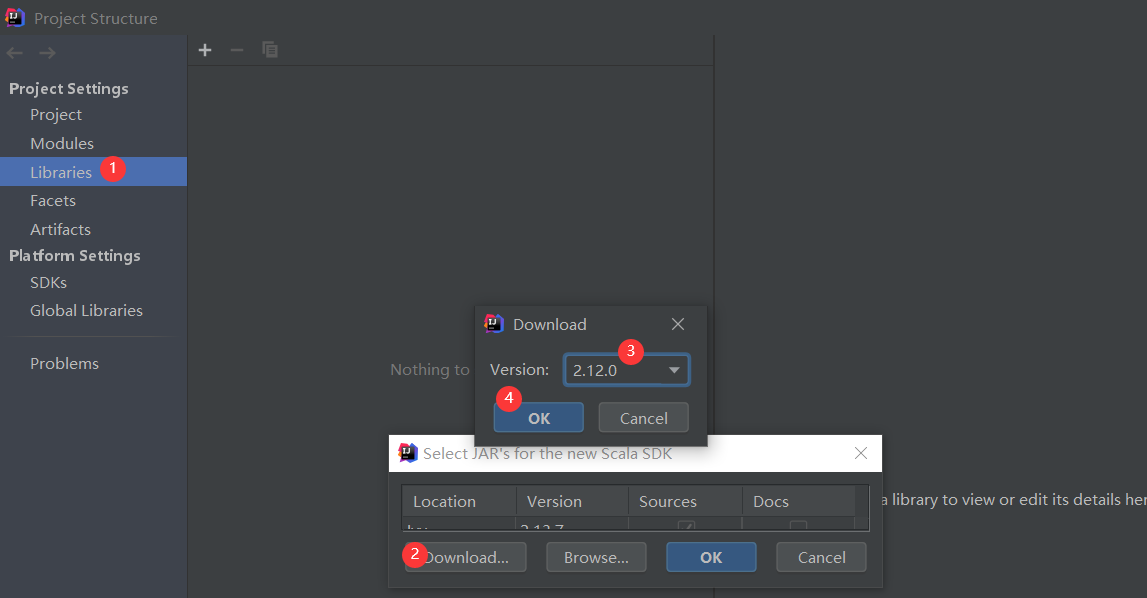
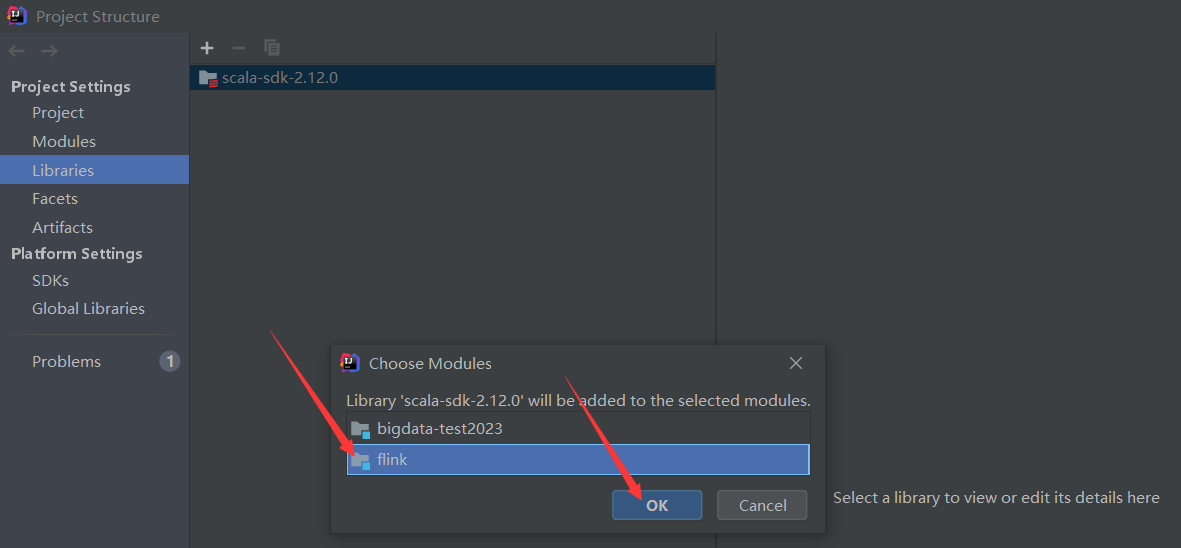
添加完scala插件之后就可以创建scala项目了
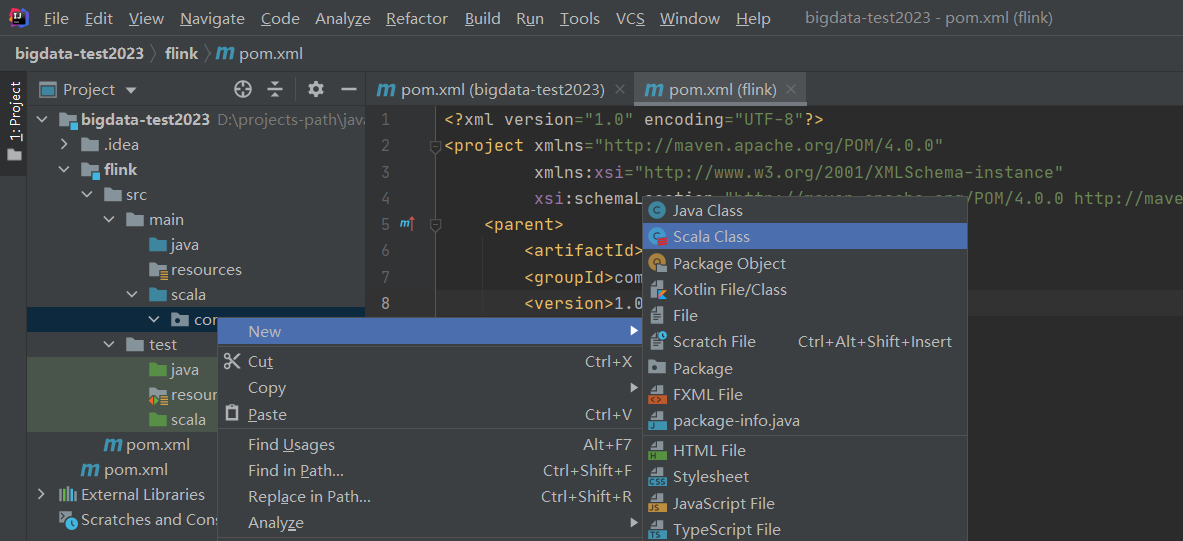
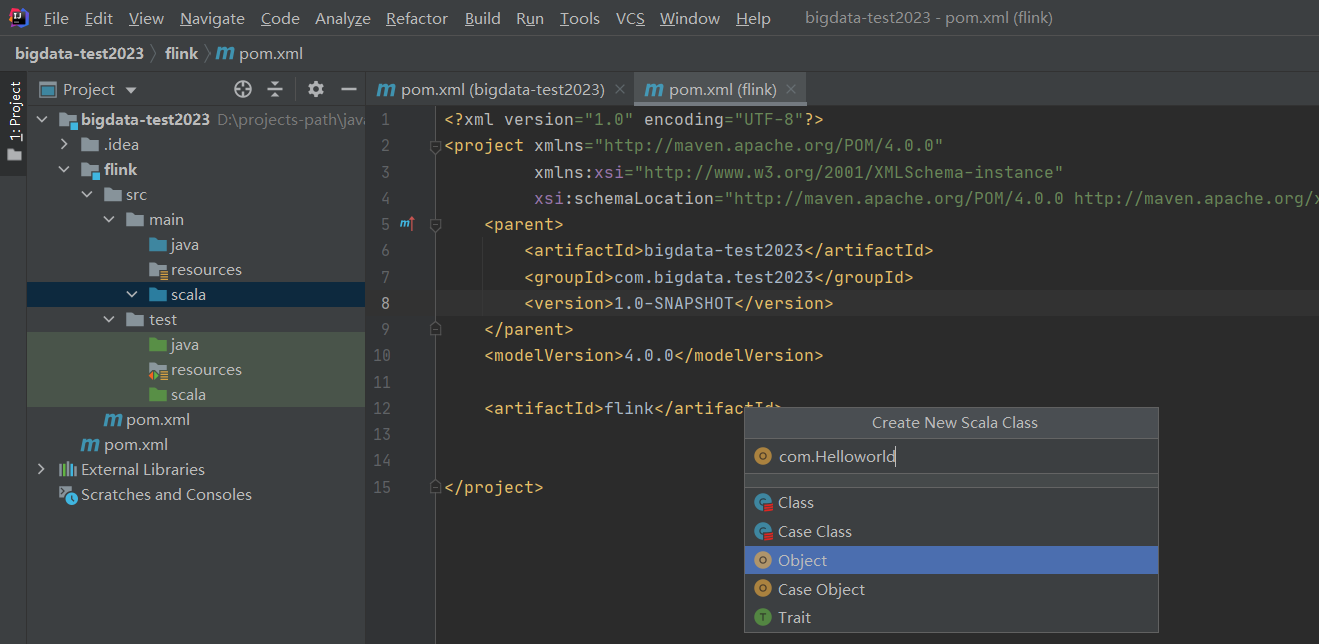
创建Object类
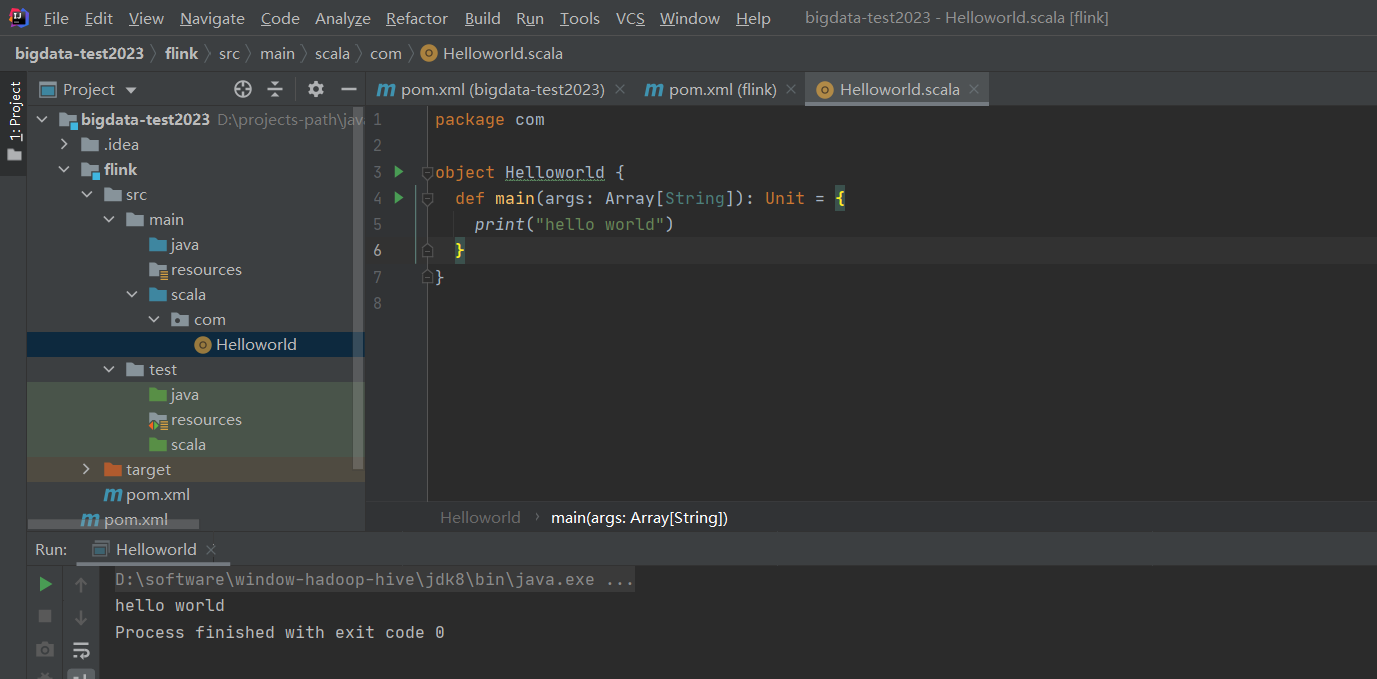
【温馨提示】类只会被编译,不能直接被执行。
在flink模块目录下pom.xml配置如下内容:
【温馨提示】这里的scala版本要与上面插件版本一致
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
【问题】IDEA 在使用Maven项目时,未加载 provided 范围的依赖包,导致启动时报错
【原因】就是 Run Application时,IDEA未加载 provided 范围的依赖包,导致启动时报错,这是IDEA的bug
【解决】在IDEA中设置
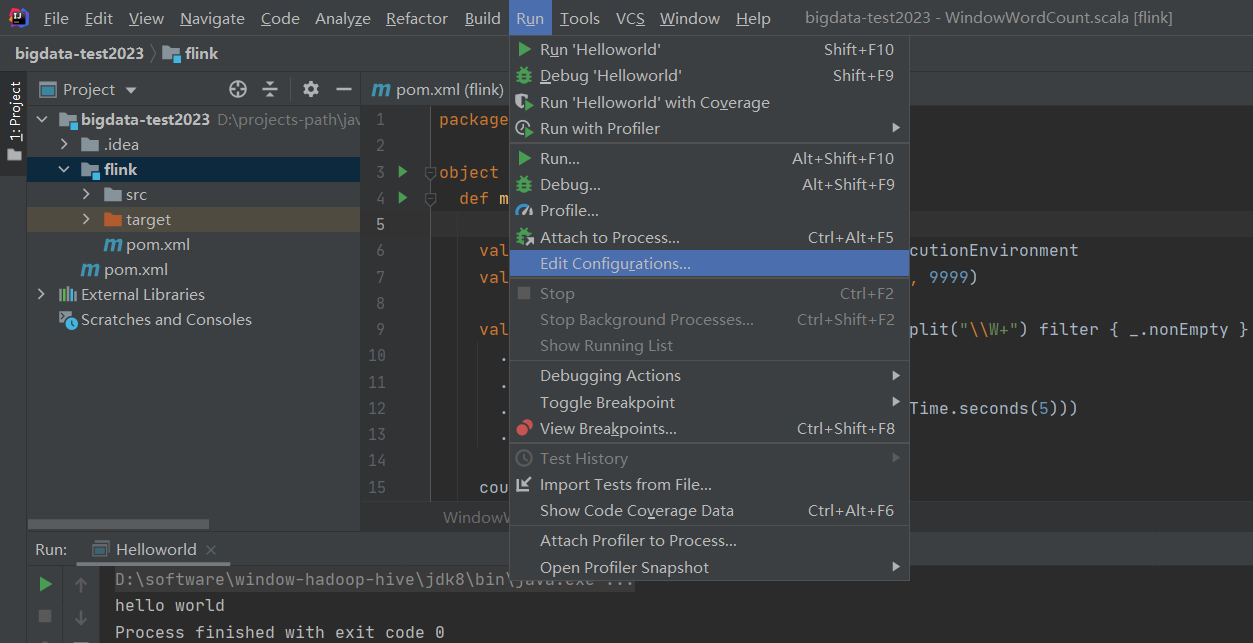
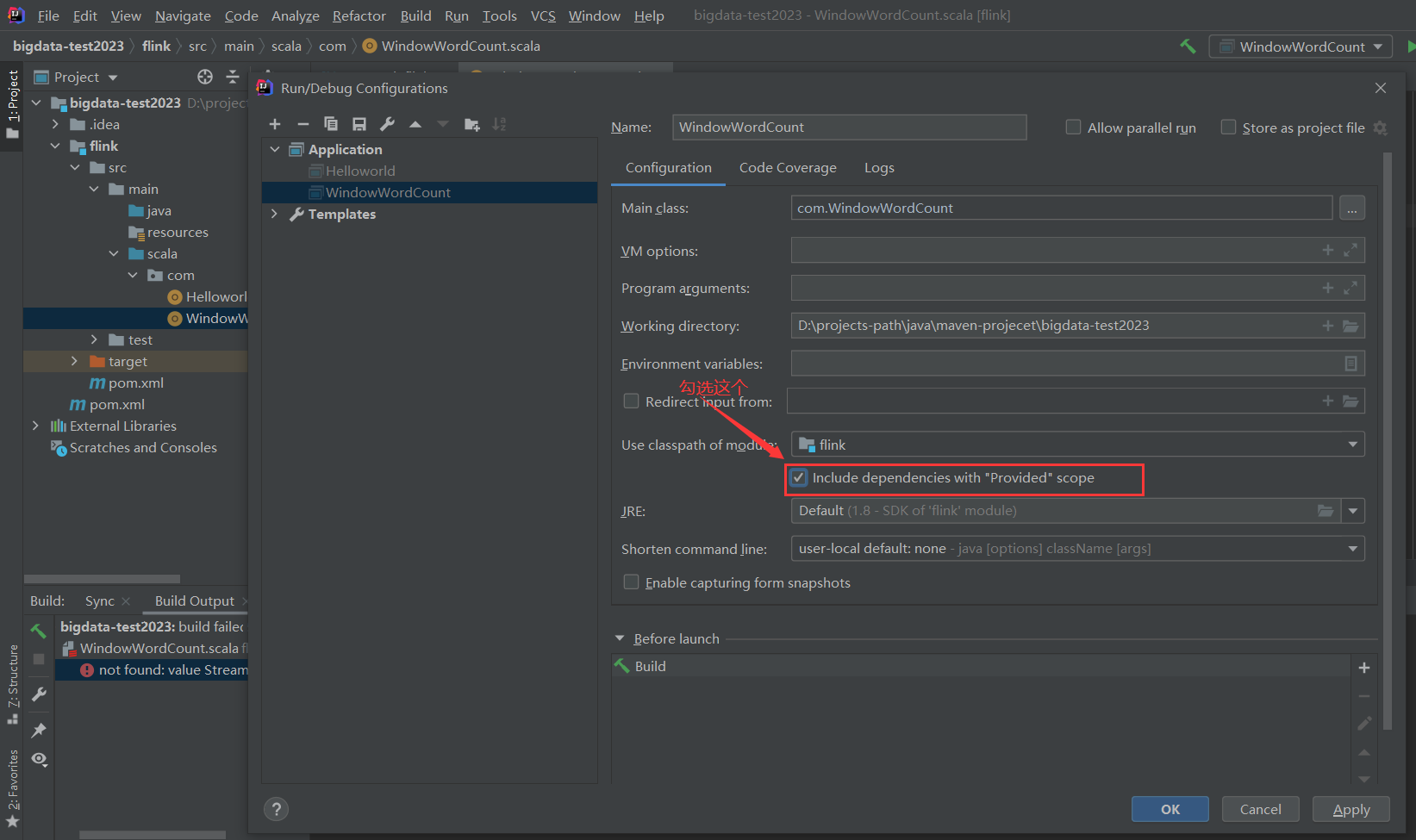
(官网示例)
package com
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
object WindowWordCount {
def main(args: Array[String]) {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("localhost", 9999)
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.keyBy(_._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1)
counts.print()
env.execute("Window Stream WordCount")
}
}
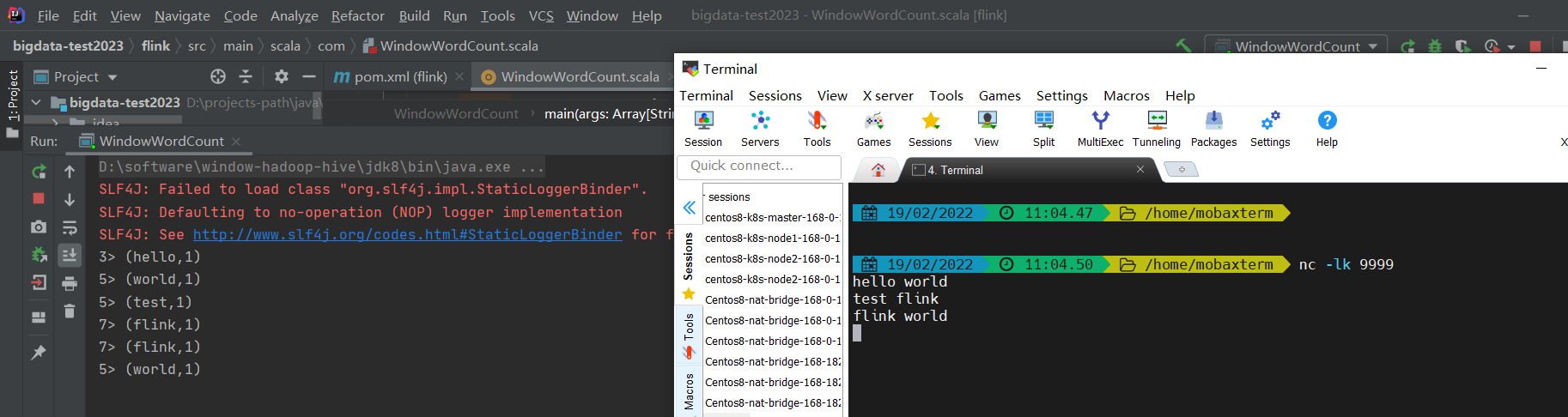
在命令行起一个9999端口的服务
$ nc -lk 9999

运行测试
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
这里使用filesystem,不需要引用相应得maven配置,像kafka,ES等连接器是需要引入相应的maven配置,但是这里使用到了format csv,所以得引入相应得配置,配置如下:
更多连接器的介绍,你看官方文档
<!-- format csv 下面会用到-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.14.3</version>
</dependency>
源码
package com
import org.apache.flink.table.api._
object TableSQL {
def main(args: Array[String]): Unit = {
val settings = EnvironmentSettings.inStreamingMode()
val tableEnv = TableEnvironment.create(settings)
// create an output Table
val schema = Schema.newBuilder()
.column("a", DataTypes.STRING())
.column("b", DataTypes.STRING())
.column("c", DataTypes.STRING())
.build()
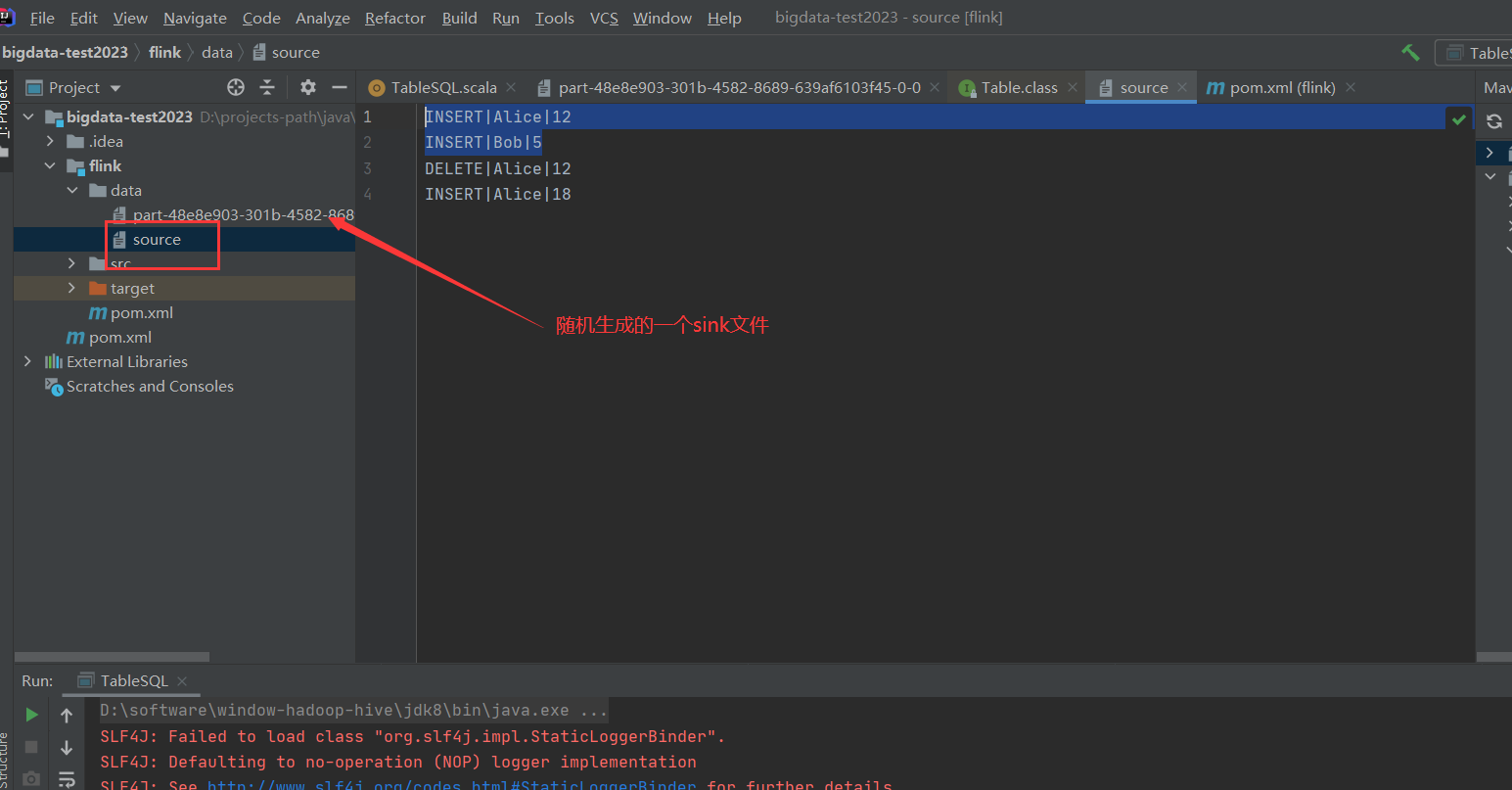
tableEnv.createTemporaryTable("CsvSourceTable", TableDescriptor.forConnector("filesystem")
.schema(schema)
.option("path", "flink/data/source")
.format(FormatDescriptor.forFormat("csv")
.option("field-delimiter", "|")
.build())
.build())
tableEnv.createTemporaryTable("CsvSinkTable", TableDescriptor.forConnector("filesystem")
.schema(schema)
.option("path", "flink/data/")
.format(FormatDescriptor.forFormat("csv")
.option("field-delimiter", "|")
.build())
.build())
// 创建一个查询语句
val sourceTable = tableEnv.sqlQuery("SELECT * FROM CsvSourceTable limit 2")
// 将查询到的数据转到下游存储
sourceTable.executeInsert("CsvSinkTable")
}
}
<!-- Flink Dependency -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.11</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<!-- Hive Dependency -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
<scope>provided</scope>
</dependency>
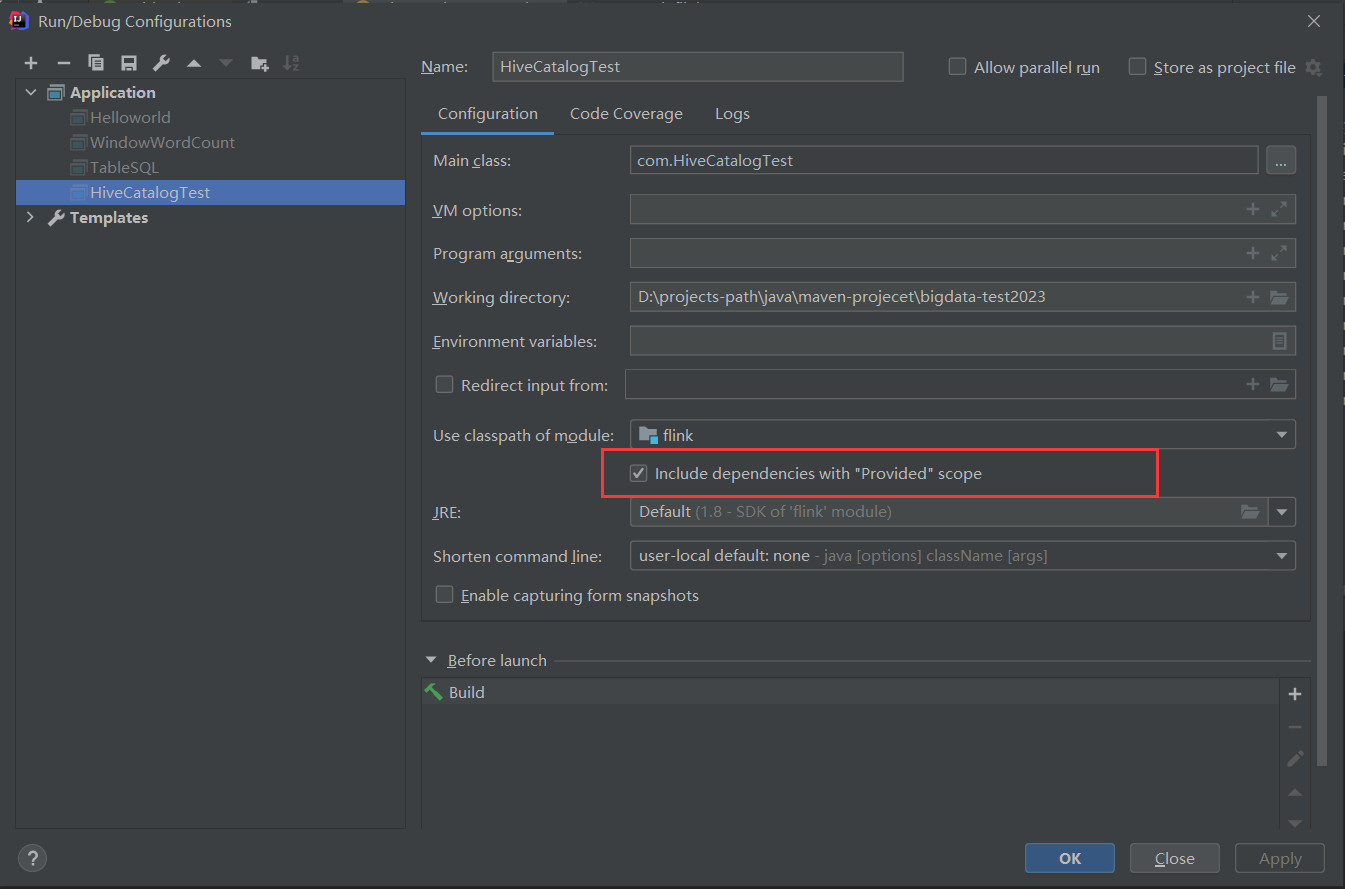
【温馨提示】在IDEA中scope设置provided的时候,必须对应的运行文件设置加载provided的依赖到classpath
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{YYYY-MM-dd HH:mm:ss} [%t] %-5p %c{1}:%L - %msg%n" />
</Console>
<RollingFile name="RollingFile" filename="log/test.log"
filepattern="${logPath}/%d{YYYYMMddHHmmss}-fargo.log">
<PatternLayout pattern="%d{YYYY-MM-dd HH:mm:ss} [%t] %-5p %c{1}:%L - %msg%n" />
<Policies>
<SizeBasedTriggeringPolicy size="10 MB" />
</Policies>
<DefaultRolloverStrategy max="20" />
</RollingFile>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console" />
<AppenderRef ref="RollingFile" />
</Root>
</Loggers>
</Configuration>
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 所连接的 MySQL 数据库的地址,hive_remote2是数据库,程序会自动创建,自定义就行 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=Asia/Shanghai</value>
</property>
<!-- MySQL 驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>MySQL JDBC driver class</description>
</property>
<!-- mysql连接用户 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>user name for connecting to mysql server</description>
</property>
<!-- mysql连接密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password for connecting to mysql server</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value>
<description>IP address (or fully-qualified domain name) and port of the metastore host</description>
</property>
<!-- host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>localhost</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>
<!-- hs2端口 默认是1000,为了区别,我这里不使用默认端口-->
<property>
<name>hive.server2.thrift.port</name>
<value>10001</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>true</value>
</property>
</configuration>
【温馨提示】必须启动metastore和hiveserver2服务,不清楚的小伙拍可以参考我之前的文章:大数据Hadoop之——部署hadoop+hive环境(window10环境)
$ hive --service metastore
$ hive --service hiveserver2
【问题】Hadoop和hive-exec-3.1.2的Guava的版本冲突导致Flink任务启动异常
【解决】删掉%HIVE_HOME%\lib目录下的guava-19.0.jar,再把%HADOOP_HOME%\share\hadoop\common\lib\guava-27.0-jre.jar复制到%HIVE_HOME%\lib目录下。
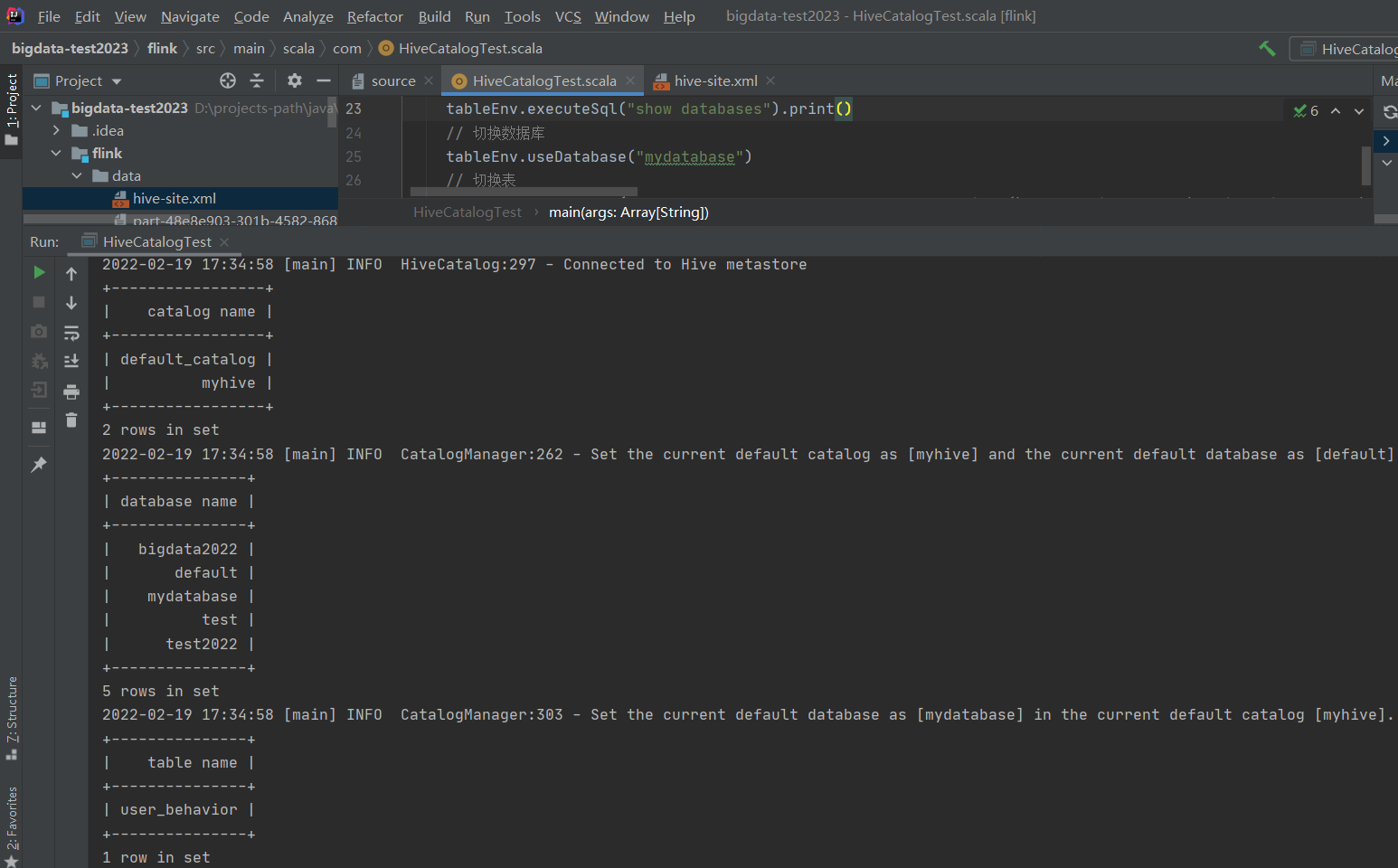
package com
import org.apache.flink.table.api.{EnvironmentSettings, TableEnvironment}
import org.apache.flink.table.catalog.hive.HiveCatalog
object HiveCatalogTest {
def main(args: Array[String]): Unit = {
val settings = EnvironmentSettings.inStreamingMode()
val tableEnv = TableEnvironment.create(settings)
val name = "myhive"
val defaultDatabase = "default"
val hiveConfDir = "flink/data/"
val hive = new HiveCatalog(name, defaultDatabase, hiveConfDir)
// 注册catalog,会话结束自动消失
tableEnv.registerCatalog("myhive", hive)
// 显示有多少个catalog
tableEnv.executeSql("show catalogs").print()
// 切换到myhive 的catalog
tableEnv.useCatalog("myhive")
// 创建库,已经持久化到hive了,会话结束依然存在
tableEnv.executeSql("CREATE DATABASE IF NOT EXISTS mydatabase")
// 显示有多少个database
tableEnv.executeSql("show databases").print()
// 切换数据库
tableEnv.useDatabase("mydatabase")
// 切换表
tableEnv.executeSql("CREATE TABLE IF NOT EXISTS user_behavior (\n user_id BIGINT,\n item_id BIGINT,\n category_id BIGINT,\n behavior STRING,\n ts TIMESTAMP(3)\n) WITH (\n 'connector' = 'kafka',\n 'topic' = 'user_behavior',\n 'properties.bootstrap.servers' = 'hadoop-node1:9092',\n 'properties.group.id' = 'testGroup',\n 'format' = 'json',\n 'json.fail-on-missing-field' = 'false',\n 'json.ignore-parse-errors' = 'true'\n)")
tableEnv.executeSql("show tables").print()
}
}
看下面通过hive客户端连接查看上面程序创建的库和表,依然是存在的
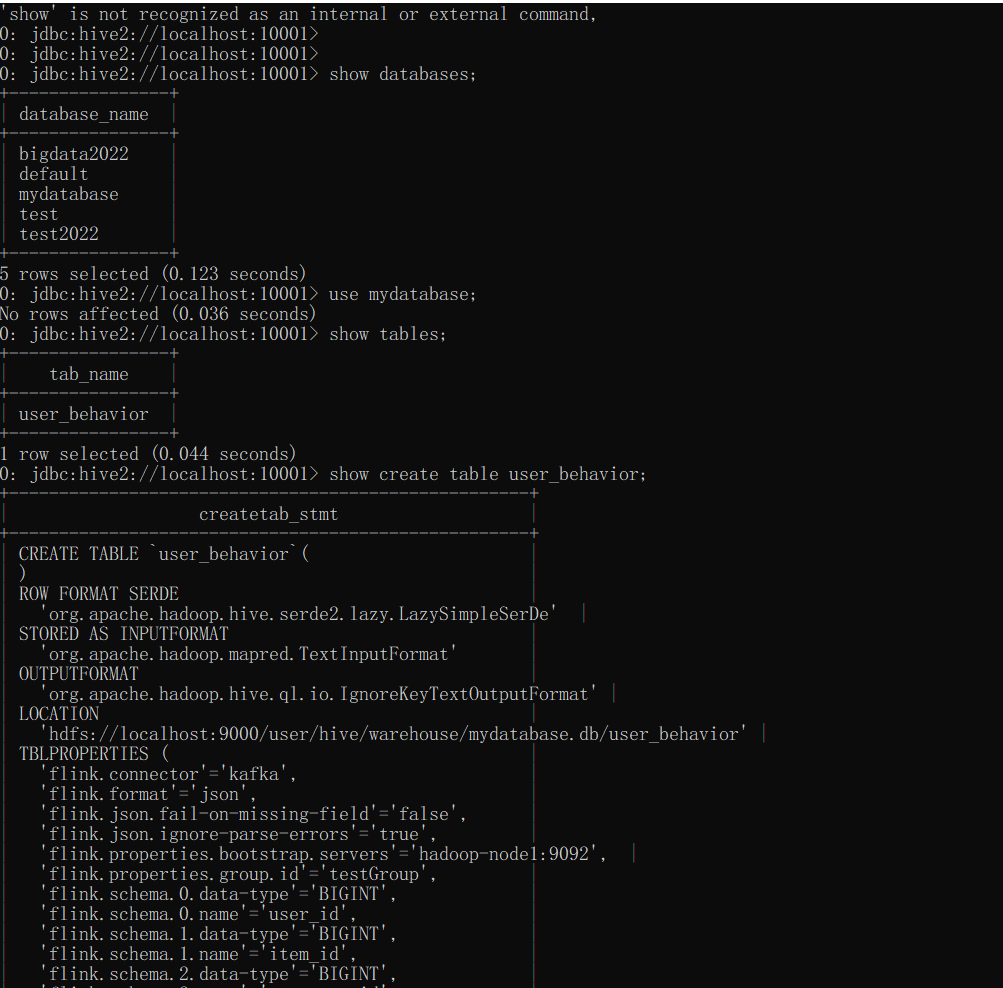
从上面验证显示,一切ok,记得开发的时候引入连接器的时候需要引入对应的maven配置
下载地址:https://flink.apache.org/downloads.html
flink-1.14.3:https://dlcdn.apache.org/flink/flink-1.14.3/flink-1.14.3-bin-scala_2.12.tgz
【温馨提示】在新版中start-cluster.cmd和flink.cmd已经找不到了,但是可以从以前的版本中复制过来。下载下面的老版本
flink-1.9.1:https://archive.apache.org/dist/flink/flink-1.9.1/flink-1.9.1-bin-scala_2.11.tgz
其实主要从flink-1.9.1中copy以下两个文件到新版本中
下载比较慢,所以我这里还是提供一下这两个文件
flink.cmd::###############################################################################
:: Licensed to the Apache Software Foundation (ASF) under one
:: or more contributor license agreements. See the NOTICE file
:: distributed with this work for additional information
:: regarding copyright ownership. The ASF licenses this file
:: to you under the Apache License, Version 2.0 (the
:: "License"); you may not use this file except in compliance
:: with the License. You may obtain a copy of the License at
::
:: http://www.apache.org/licenses/LICENSE-2.0
::
:: Unless required by applicable law or agreed to in writing, software
:: distributed under the License is distributed on an "AS IS" BASIS,
:: WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
:: See the License for the specific language governing permissions and
:: limitations under the License.
::###############################################################################
@echo off
setlocal
SET bin=%~dp0
SET FLINK_HOME=%bin%..
SET FLINK_LIB_DIR=%FLINK_HOME%\lib
SET FLINK_PLUGINS_DIR=%FLINK_HOME%\plugins
SET JVM_ARGS=-Xmx512m
SET FLINK_JM_CLASSPATH=%FLINK_LIB_DIR%\*
java %JVM_ARGS% -cp "%FLINK_JM_CLASSPATH%"; org.apache.flink.client.cli.CliFrontend %*
endlocal
start-cluster.bat::###############################################################################
:: Licensed to the Apache Software Foundation (ASF) under one
:: or more contributor license agreements. See the NOTICE file
:: distributed with this work for additional information
:: regarding copyright ownership. The ASF licenses this file
:: to you under the Apache License, Version 2.0 (the
:: "License"); you may not use this file except in compliance
:: with the License. You may obtain a copy of the License at
::
:: http://www.apache.org/licenses/LICENSE-2.0
::
:: Unless required by applicable law or agreed to in writing, software
:: distributed under the License is distributed on an "AS IS" BASIS,
:: WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
:: See the License for the specific language governing permissions and
:: limitations under the License.
::###############################################################################
@echo off
setlocal EnableDelayedExpansion
SET bin=%~dp0
SET FLINK_HOME=%bin%..
SET FLINK_LIB_DIR=%FLINK_HOME%\lib
SET FLINK_PLUGINS_DIR=%FLINK_HOME%\plugins
SET FLINK_CONF_DIR=%FLINK_HOME%\conf
SET FLINK_LOG_DIR=%FLINK_HOME%\log
SET JVM_ARGS=-Xms1024m -Xmx1024m
SET FLINK_CLASSPATH=%FLINK_LIB_DIR%\*
SET logname_jm=flink-%username%-jobmanager.log
SET logname_tm=flink-%username%-taskmanager.log
SET log_jm=%FLINK_LOG_DIR%\%logname_jm%
SET log_tm=%FLINK_LOG_DIR%\%logname_tm%
SET outname_jm=flink-%username%-jobmanager.out
SET outname_tm=flink-%username%-taskmanager.out
SET out_jm=%FLINK_LOG_DIR%\%outname_jm%
SET out_tm=%FLINK_LOG_DIR%\%outname_tm%
SET log_setting_jm=-Dlog.file="%log_jm%" -Dlogback.configurationFile=file:"%FLINK_CONF_DIR%/logback.xml" -Dlog4j.configuration=file:"%FLINK_CONF_DIR%/log4j.properties"
SET log_setting_tm=-Dlog.file="%log_tm%" -Dlogback.configurationFile=file:"%FLINK_CONF_DIR%/logback.xml" -Dlog4j.configuration=file:"%FLINK_CONF_DIR%/log4j.properties"
:: Log rotation (quick and dirty)
CD "%FLINK_LOG_DIR%"
for /l %%x in (5, -1, 1) do (
SET /A y = %%x+1
RENAME "%logname_jm%.%%x" "%logname_jm%.!y!" 2> nul
RENAME "%logname_tm%.%%x" "%logname_tm%.!y!" 2> nul
RENAME "%outname_jm%.%%x" "%outname_jm%.!y!" 2> nul
RENAME "%outname_tm%.%%x" "%outname_tm%.!y!" 2> nul
)
RENAME "%logname_jm%" "%logname_jm%.0" 2> nul
RENAME "%logname_tm%" "%logname_tm%.0" 2> nul
RENAME "%outname_jm%" "%outname_jm%.0" 2> nul
RENAME "%outname_tm%" "%outname_tm%.0" 2> nul
DEL "%logname_jm%.6" 2> nul
DEL "%logname_tm%.6" 2> nul
DEL "%outname_jm%.6" 2> nul
DEL "%outname_tm%.6" 2> nul
for %%X in (java.exe) do (set FOUND=%%~$PATH:X)
if not defined FOUND (
echo java.exe was not found in PATH variable
goto :eof
)
echo Starting a local cluster with one JobManager process and one TaskManager process.
echo You can terminate the processes via CTRL-C in the spawned shell windows.
echo Web interface by default on http://localhost:8081/.
start java %JVM_ARGS% %log_setting_jm% -cp "%FLINK_CLASSPATH%"; org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint --configDir "%FLINK_CONF_DIR%" > "%out_jm%" 2>&1
start java %JVM_ARGS% %log_setting_tm% -cp "%FLINK_CLASSPATH%"; org.apache.flink.runtime.taskexecutor.TaskManagerRunner --configDir "%FLINK_CONF_DIR%" > "%out_tm%" 2>&1
endlocal
启动flink集群很简单,只要双击start-cluster.bat
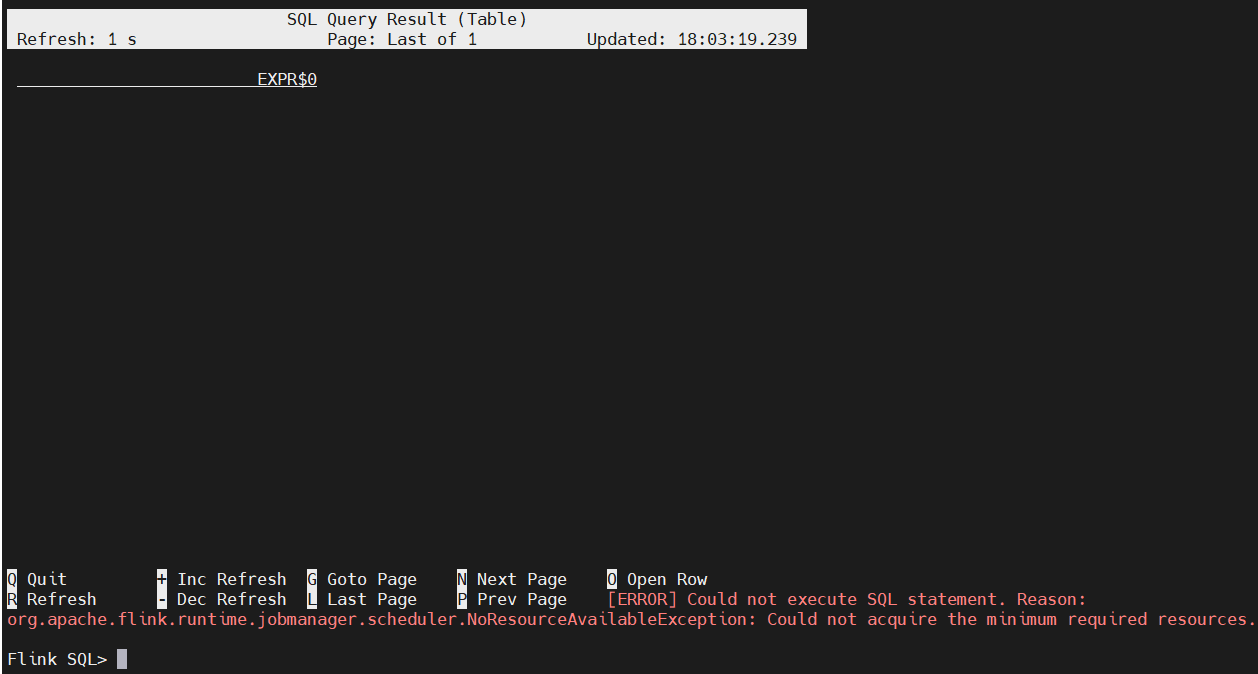
通过sql客户端验证一下
$ SELECT 'Hello World';
【错误】NoResourceAvailableException: Could not acquire the minimum required resources
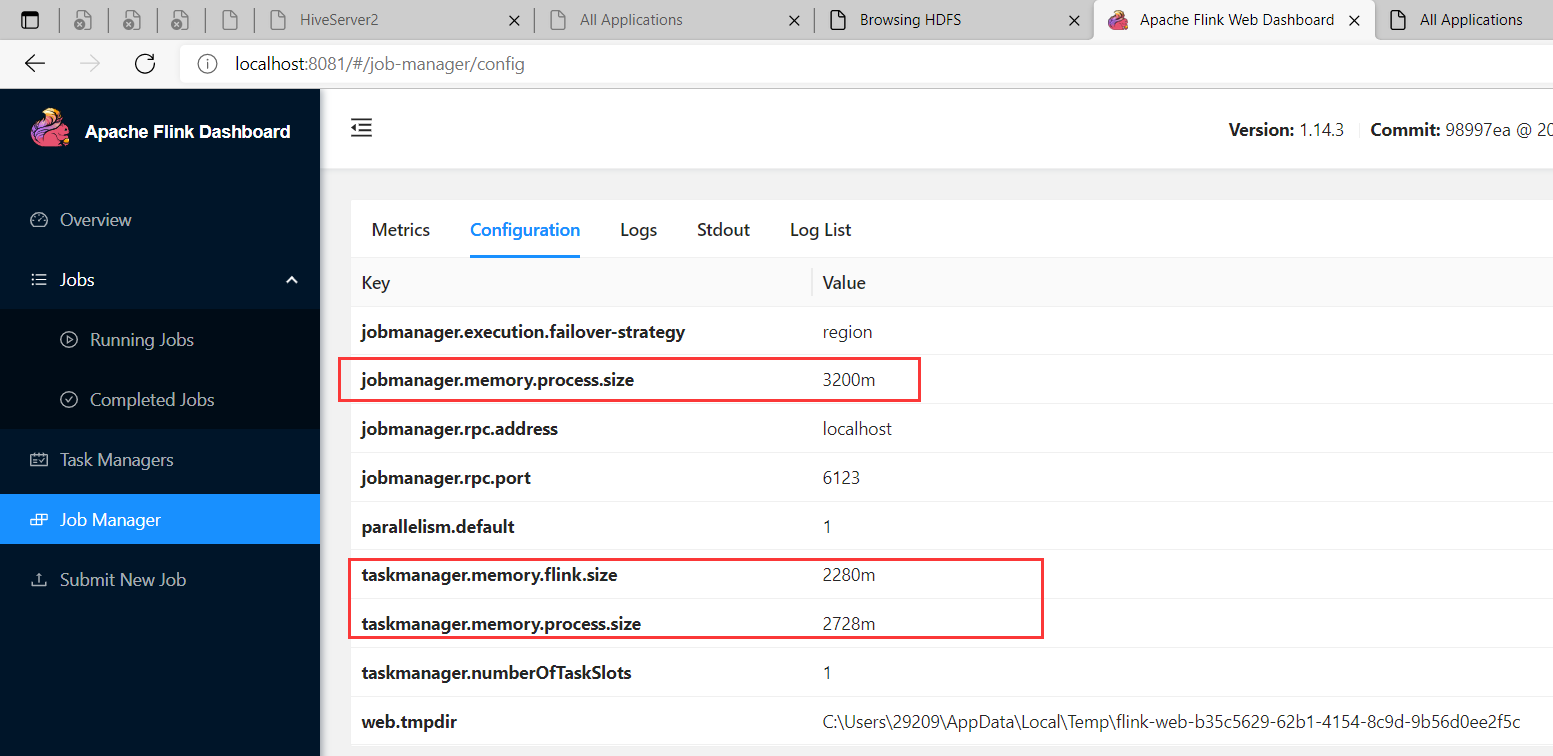
【解决】是因为资源太小,不足以跑任务,扩大配置,修改如下配置:
jobmanager.memory.process.size: 3200m
taskmanager.memory.process.size: 2728m
taskmanager.memory.flink.size: 2280m
但是我这里调大了还是太小了,自己电脑配置有限,如果有小伙伴的配置高,可以再调大验证一下。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>bigdata-test2023</artifactId>
<groupId>com.bigdata.test2023</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>flink</artifactId>
<!-- DataStream API maven settings begin -->
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<!-- DataStream API maven settings end -->
<!-- Table and SQL maven settings begin-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<!-- 上面已经设置过了 -->
<!--<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.14.3</version>
</dependency>
<!-- Table and SQL maven settings end-->
<!-- Hive Catalog maven settings begin -->
<!-- Flink Dependency -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.11</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<!-- Hive Dependency -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
<scope>provided</scope>
</dependency>
<!-- Hive Catalog maven settings end -->
<!--hadoop start-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<!--hadoop end-->
</dependencies>
</project>
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{YYYY-MM-dd HH:mm:ss} [%t] %-5p %c{1}:%L - %msg%n" />
</Console>
<RollingFile name="RollingFile" filename="log/test.log"
filepattern="${logPath}/%d{YYYYMMddHHmmss}-fargo.log">
<PatternLayout pattern="%d{YYYY-MM-dd HH:mm:ss} [%t] %-5p %c{1}:%L - %msg%n" />
<Policies>
<SizeBasedTriggeringPolicy size="10 MB" />
</Policies>
<DefaultRolloverStrategy max="20" />
</RollingFile>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console" />
<AppenderRef ref="RollingFile" />
</Root>
</Loggers>
</Configuration>
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 所连接的 MySQL 数据库的地址,hive_remote2是数据库,程序会自动创建,自定义就行 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=Asia/Shanghai</value>
</property>
<!-- MySQL 驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>MySQL JDBC driver class</description>
</property>
<!-- mysql连接用户 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>user name for connecting to mysql server</description>
</property>
<!-- mysql连接密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password for connecting to mysql server</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value>
<description>IP address (or fully-qualified domain name) and port of the metastore host</description>
</property>
<!-- host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>localhost</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>
<!-- hs2端口 默认是1000,为了区别,我这里不使用默认端口-->
<property>
<name>hive.server2.thrift.port</name>
<value>10001</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>true</value>
</property>
</configuration>
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>bigdata-test2023</artifactId>
<groupId>com.bigdata.test2023</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>flink</artifactId>
<!-- DataStream API maven settings begin -->
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<!-- DataStream API maven settings end -->
<!-- Table and SQL maven settings begin-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<!-- 上面已经设置过了 -->
<!--<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.14.3</version>
</dependency>
<!-- Table and SQL maven settings end-->
<!-- Hive Catalog maven settings begin -->
<!-- Flink Dependency -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.11</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<!-- Hive Dependency -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
<scope>provided</scope>
</dependency>
<!-- Hive Catalog maven settings end -->
<!--hadoop start-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<!--hadoop end-->
</dependencies>
</project>
【温馨提示】其实
log4j2.xml和hive-site.xml不区分java和scala的,为了方便这里还是再复制一份。
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{YYYY-MM-dd HH:mm:ss} [%t] %-5p %c{1}:%L - %msg%n" />
</Console>
<RollingFile name="RollingFile" filename="log/test.log"
filepattern="${logPath}/%d{YYYYMMddHHmmss}-fargo.log">
<PatternLayout pattern="%d{YYYY-MM-dd HH:mm:ss} [%t] %-5p %c{1}:%L - %msg%n" />
<Policies>
<SizeBasedTriggeringPolicy size="10 MB" />
</Policies>
<DefaultRolloverStrategy max="20" />
</RollingFile>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console" />
<AppenderRef ref="RollingFile" />
</Root>
</Loggers>
</Configuration>
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 所连接的 MySQL 数据库的地址,hive_remote2是数据库,程序会自动创建,自定义就行 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=Asia/Shanghai</value>
</property>
<!-- MySQL 驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>MySQL JDBC driver class</description>
</property>
<!-- mysql连接用户 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>user name for connecting to mysql server</description>
</property>
<!-- mysql连接密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password for connecting to mysql server</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value>
<description>IP address (or fully-qualified domain name) and port of the metastore host</description>
</property>
<!-- host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>localhost</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>
<!-- hs2端口 默认是1000,为了区别,我这里不使用默认端口-->
<property>
<name>hive.server2.thrift.port</name>
<value>10001</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>true</value>
</property>
</configuration>
关于更多大数据的内容,请耐心等待~

我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf