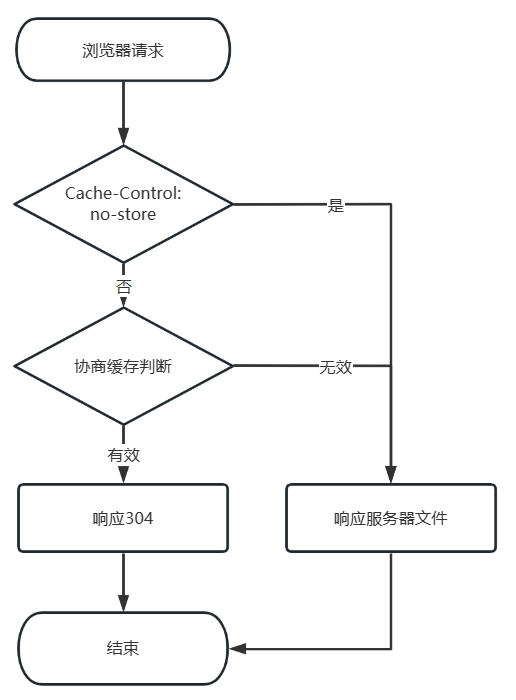
| HTTP版本 | 强制缓存 | 协商缓存 |
| HTTP/1.0 | Expires | Last-Modified |
| HTTP/1.1 | Cache-Control | ETag |
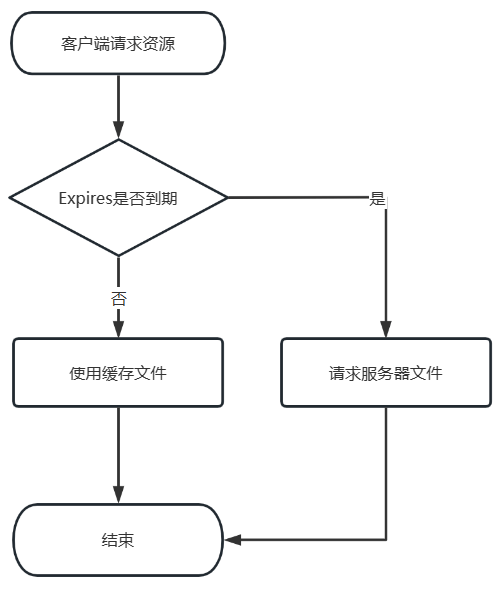 不过Expires存在的问题也显而易见。首先,使用客户端获取的GMT时间与服务器GMT时间作比较,如果客户端主动修改了系统时间,就会出现缓存命中的误差。其次,GMT时间是基于格林尼治天文台测算时间后,每隔一小时想全世界发放调时信息。观测本身存在的误差以及非实时的同步机制,都可能会导致出现缓存命中的误差。所以在HTTP/1.1版本中,使用Cache-Control中的max-age替代。
不过Expires存在的问题也显而易见。首先,使用客户端获取的GMT时间与服务器GMT时间作比较,如果客户端主动修改了系统时间,就会出现缓存命中的误差。其次,GMT时间是基于格林尼治天文台测算时间后,每隔一小时想全世界发放调时信息。观测本身存在的误差以及非实时的同步机制,都可能会导致出现缓存命中的误差。所以在HTTP/1.1版本中,使用Cache-Control中的max-age替代。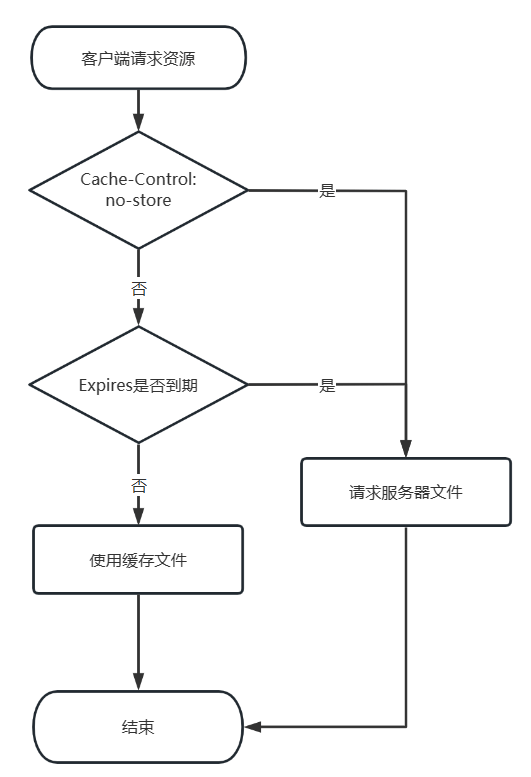
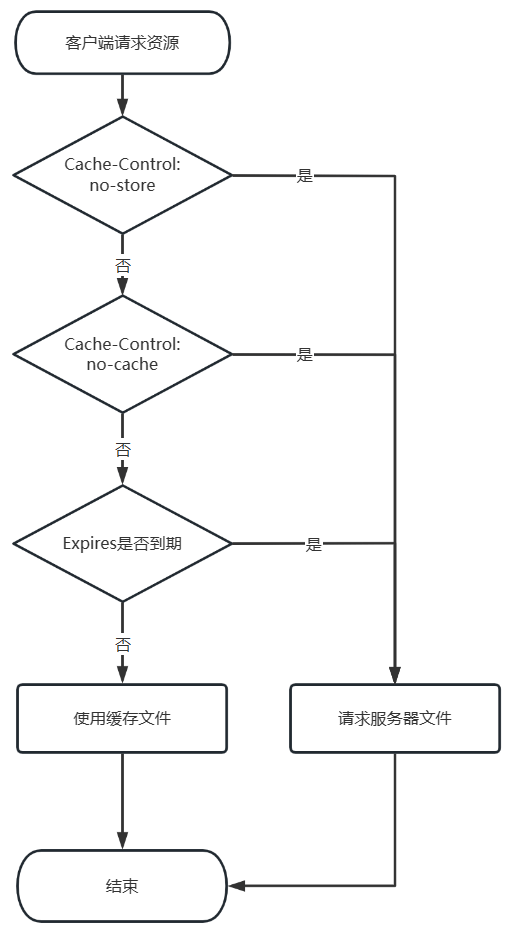
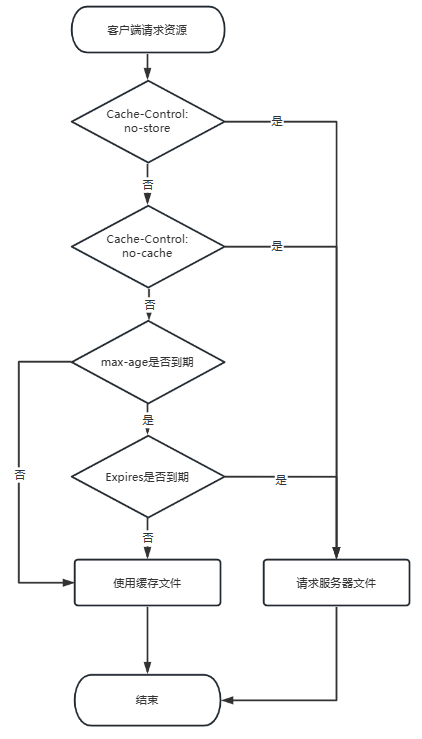
| 版本/阶段 | 请求 | 响应 |
| HTTP/1.0 | If-Modified-Since/If-Unmodified-Since | Last-Modified |
| HTTP/1.1 | If-None-Match/If-Match | ETag |
如:last-modified: Sat, 14 Jan 2023 08:40:00 GMT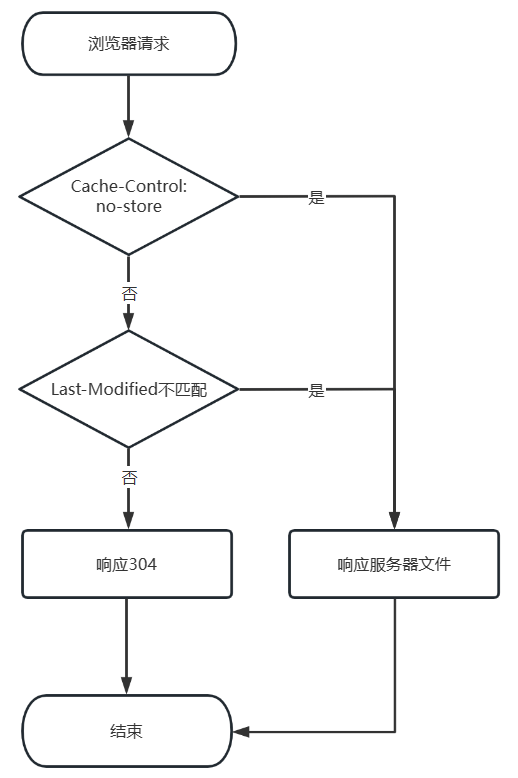 Last-Modified也是存在严重问题的。首先,Last-Modified只关注文件的最后修改时间,和文件内容无关。所以文件内容在修改后又重新恢复,也会导致文件的最后修改时间改变。此时客户端的请求则无法使用缓存。其次,Last-Modified只能监听到秒级别的文件修改,如果文件在1秒内进行了多次修改,那么响应头返回的Last-Modified的时间是不变的。此时客户端因接收到响应304,会导致资源无法及时更新,使用缓存的资源文件。因此HTTP/1.1使用了ETag来进行缓存协商。
Last-Modified也是存在严重问题的。首先,Last-Modified只关注文件的最后修改时间,和文件内容无关。所以文件内容在修改后又重新恢复,也会导致文件的最后修改时间改变。此时客户端的请求则无法使用缓存。其次,Last-Modified只能监听到秒级别的文件修改,如果文件在1秒内进行了多次修改,那么响应头返回的Last-Modified的时间是不变的。此时客户端因接收到响应304,会导致资源无法及时更新,使用缓存的资源文件。因此HTTP/1.1使用了ETag来进行缓存协商。如:etag: "I82YRPyDtSi45r0Ps/eo8GbnDfg="如: if-none-match:"I82YRPyDtSi45r0Ps/eo8GbnDfg="如: if-match:"I82YRPyDtSi45r0Ps/eo8GbnDfg="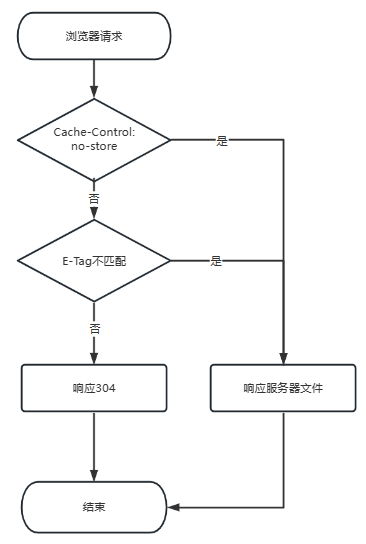

是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
我试过重新启动apache,缓存的页面仍然出现,所以一定有一个文件夹在某个地方。我没有“公共(public)/缓存”,那么我还应该查看哪些其他地方?是否有一个URL标志也可以触发此效果? 最佳答案 您需要触摸一个文件才能清除phusion,例如:touch/webapps/mycook/tmp/restart.txt参见docs 关于ruby-如何在Ubuntu中清除RubyPhusionPassenger的缓存?,我们在StackOverflow上找到一个类似的问题:
尝试在我的RoR应用程序中实现计数器缓存列时出现错误Unknownkey(s):counter_cache。我在这个问题中实现了模型关联:Modelassociationquestion这是我的迁移:classAddVideoVotesCountToVideos0Video.reset_column_informationVideo.find(:all).eachdo|p|p.update_attributes:videos_votes_count,p.video_votes.lengthendenddefself.downremove_column:videos,:video_vot
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
Rails中有没有一种方法可以提取与路由关联的HTTP动词?例如,给定这样的路线:将“users”匹配到:“users#show”,通过:[:get,:post]我能实现这样的目标吗?users_path.respond_to?(:get)(显然#respond_to不是正确的方法)我最接近的是通过执行以下操作,但它似乎并不令人满意。Rails.application.routes.routes.named_routes["users"].constraints[:request_method]#=>/^GET$/对于上下文,我有一个设置cookie然后执行redirect_to:ba
我正在使用Heroku(heroku.com)来部署我的Rails应用程序,并且正在构建一个iPhone客户端来与之交互。我的目的是将手机的唯一设备标识符作为HTTPheader传递给应用程序以进行身份验证。当我在本地测试时,我的header通过得很好,但在Heroku上它似乎去掉了我的自定义header。我用ruby脚本验证:url=URI.parse('http://#{myapp}.heroku.com/')#url=URI.parse('http://localhost:3000/')req=Net::HTTP::Post.new(url.path)#boguspara
我试图在我的网站上实现使用Facebook登录功能,但在尝试从Facebook取回访问token时遇到障碍。这是我的代码:ifparams[:error_reason]=="user_denied"thenflash[:error]="TologinwithFacebook,youmustclick'Allow'toletthesiteaccessyourinformation"redirect_to:loginelsifparams[:code]thentoken_uri=URI.parse("https://graph.facebook.com/oauth/access_token
我是Ruby的新手。我试过查看在线文档,但没有找到任何有效的方法。我想在以下HTTP请求botget_response()和get()中包含一个用户代理。有人可以指出我正确的方向吗?#PreliminarycheckthatProggitisupcheck=Net::HTTP.get_response(URI.parse(proggit_url))ifcheck.code!="200"puts"ErrorcontactingProggit"returnend#Attempttogetthejsonresponse=Net::HTTP.get(URI.parse(proggit_url)
我正在尝试解析网页,但有时会收到404错误。这是我用来获取网页的代码:result=Net::HTTP::getURI.parse(URI.escape(url))如何测试result是否为404错误代码? 最佳答案 像这样重写你的代码:uri=URI.parse(url)result=Net::HTTP.start(uri.host,uri.port){|http|http.get(uri.path)}putsresult.codeputsresult.body这将打印状态码和正文。