小熊飞桨练习册-07PaddleX寻找火箭车车,是学习目标检测小项目,本项目开发和测试均在 Ubuntu 20.04 系统下进行。
项目最新代码查看主页:小熊飞桨练习册
百度飞桨 AI Studio 主页:小熊飞桨练习册-07PaddleX寻找火箭车车
Ubuntu 系统安装 CUDA 参考:Ubuntu 百度飞桨和 CUDA 的安装
| 文件 | 说明 |
|---|---|
| train.py | 训练程序 |
| prune.py | 裁剪程序 |
| quant.py | 量化程序 |
| infer.py | 预测程序 |
| onekey.sh | 一键获取数据到 dataset 目录下 |
| onetasks.sh | 一键训练,量化脚本 |
| get_data.sh | 获取数据到 dataset 目录下 |
| check_data.sh | 检查 dataset 目录下的数据是否存在 |
| mod/args.py | 命令行参数解析 |
| mod/pdxconfig.py | PaddleX 配置 |
| mod/config.py | 配置 |
| mod/utils.py | 杂项 |
| mod/report.py | 结果报表 |
| dataset | 数据集目录 |
| doc | 文档目录 |
| output | 训练参数保存目录 |
| result | 预测结果保存目录 |
数据集来源于自己收集标注的百度飞桨公共数据集:寻找火箭车车
数据集包含训练集,验证集,测试集,相应的 VOC 格式标注文件。
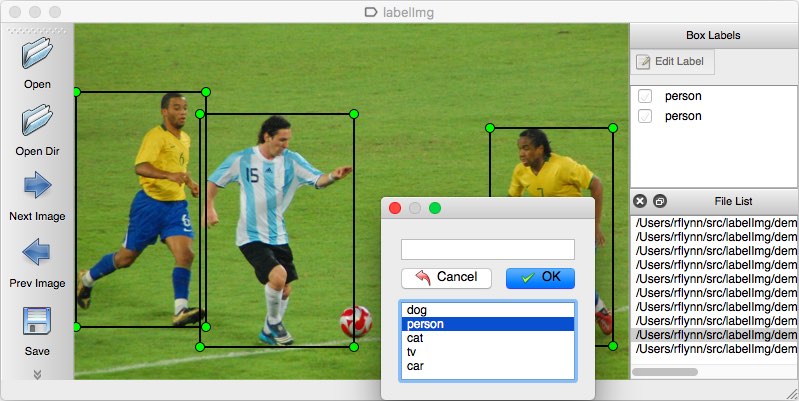
使用标注工具:labelImg
中文界面,支持 VOC 格式,COCO 格式
打开图像目录
W 是标注
D 是下一张
A 是上一张
labelImg 演示
如果运行在本地计算机,下载完数据,文件放到 dataset 目录下,在项目目录下运行下面脚本。
如果运行在百度 AI Studio 环境,查看 data 目录是否有数据,在项目目录下运行下面脚本。
bash onekey.sh
可以查看修改 mod/pdxconfig.py 文件,有详细的说明
运行 train.py 文件,查看命令行参数加 -h
python3 run/train.py \
--dataset ./dataset/road_fighter_car \
--epochs 32 \
--batch_size 1 \
--learning_rate 0.01 \
--model PicoDet \
--backbone MobileNetV3 \
--save_interval_epochs 4 \
--pretrain_weights "" \
--save_dir ./output
-h, --help show this help message and exit
--cpu 是否使用 cpu 计算,默认使用 CUDA
--num_workers 线程数量,默认 auto,为CPU核数的一半
--epochs 训练几轮,默认 4 轮
--batch_size 一批次数量,默认 16
--learning_rate 学习率,默认 0.025
--warmup_steps 默认优化器的warmup步数,学习率将在设定的步数内,从warmup_start_lr线性增长至设定的learning_rate
,默认为0。
--warmup_start_lr 默认优化器的warmup起始学习率,默认为0.0。
--lr_decay_epochs 默认优化器的学习率衰减轮数。默认为 30 60 90
--lr_decay_gamma 默认优化器的学习率衰减率。默认为0.1
--save_interval_epochs
模型保存间隔(单位: 迭代轮数)。默认为1
--save_dir 模型保存路径。默认为 ./output/
--dataset 数据集目录,默认 ./dataset/
--resume_checkpoint 恢复训练时指定上次训练保存的模型路径, 默认不会恢复训练
--train_list 训练集列表,默认 '--dataset' 参数目录下的 train_list.txt
--eval_list 评估集列表,默认 '--dataset' 参数目录下的 val_list.txt
--label_list 分类标签列表,默认 '--dataset' 参数目录下的 labels.txt
--pretrain_weights 若指定为'.pdparams'文件时,从文件加载模型权重;若为字符串’IMAGENET’,则自动下载在ImageNet图片数据上
预训练的模型权重;若为字符串’COCO’,则自动下载在COCO数据集上预训练的模型权重;若为None,则不使用预训练模型。默认为
'IMAGENET'。
--model PaddleX 模型名称
--model_list 输出 PaddleX 模型名称,默认不输出,选择后只输出信息,不会开启训练
--backbone 目标检测模型的 backbone 网络
python3 run/train.py --model_list
PaddleX 目标检测模型
['PPYOLOv2', 'PPYOLO', 'PPYOLOTiny', 'PicoDet', 'YOLOv3', 'FasterRCNN']
PPYOLOv2 backbone 网络
['ResNet50_vd_dcn', 'ResNet101_vd_dcn']
PPYOLO backbone 网络
['ResNet50_vd_dcn', 'ResNet18_vd', 'MobileNetV3_large', 'MobileNetV3_small']
PPYOLOTiny backbone 网络
['MobileNetV3']
PicoDet backbone 网络
['ESNet_s', 'ESNet_m', 'ESNet_l', 'LCNet', 'MobileNetV3', 'ResNet18_vd']
YOLOv3 backbone 网络
['MobileNetV1', 'MobileNetV1_ssld', 'MobileNetV3', 'MobileNetV3_ssld', 'DarkNet53', 'ResNet50_vd_dcn', 'ResNet34']
FasterRCNN backbone 网络
['ResNet50', 'ResNet50_vd', 'ResNet50_vd_ssld', 'ResNet34', 'ResNet34_vd', 'ResNet101', 'ResNet101_vd', 'HRNet_W18']
python3 run/prune.py \
--dataset ./dataset/road_fighter_car \
--epochs 32 \
--batch_size 1 --learning_rate 0.001 \
--save_interval_epochs 4 \
--model_dir ./output/best_model \
--save_dir ./output/prune \
--pruned_flops 0.2 \
--pretrain_weights ""
-h, --help show this help message and exit
--cpu 是否使用 cpu 计算,默认使用 CUDA
--num_workers 线程数量,默认 auto,为CPU核数的一半
--epochs 训练几轮,默认 4 轮
--batch_size 一批次数量,默认 16
--learning_rate 学习率,默认 0.025
--warmup_steps 默认优化器的warmup步数,学习率将在设定的步数内,从warmup_start_lr线性增长至设定的learning_rate
,默认为0。
--warmup_start_lr 默认优化器的warmup起始学习率,默认为0.0。
--lr_decay_epochs 默认优化器的学习率衰减轮数。默认为 30 60 90
--lr_decay_gamma 默认优化器的学习率衰减率。默认为0.1
--save_interval_epochs
模型保存间隔(单位: 迭代轮数)。默认为1
--save_dir 模型保存路径。默认为 ./output/
--dataset 数据集目录,默认 ./dataset/
--resume_checkpoint 恢复训练时指定上次训练保存的模型路径, 默认不会恢复训练
--train_list 训练集列表,默认 '--dataset' 参数目录下的 train_list.txt
--eval_list 评估集列表,默认 '--dataset' 参数目录下的 val_list.txt
--label_list 分类标签列表,默认 '--dataset' 参数目录下的 labels.txt
--model_dir 模型读取路径。默认为 ./output/best_model
--skip_analyze 是否跳过分析模型各层参数在不同的裁剪比例下的敏感度,默认不跳过
--pruned_flops 根据选择的FLOPs减小比例对模型进行裁剪。默认为 0.2
python3 run/quant.py \
--dataset ./dataset/road_fighter_car \
--epochs 32 \
--batch_size 1 \
--learning_rate 0.001 \
--save_interval_epochs 4 \
--model_dir ./output/best_model \
--save_dir ./output/quant
-h, --help show this help message and exit
--cpu 是否使用 cpu 计算,默认使用 CUDA
--num_workers 线程数量,默认 auto,为CPU核数的一半
--epochs 训练几轮,默认 4 轮
--batch_size 一批次数量,默认 16
--learning_rate 学习率,默认 0.025
--warmup_steps 默认优化器的warmup步数,学习率将在设定的步数内,从warmup_start_lr线性增长至设定的learning_rate
,默认为0。
--warmup_start_lr 默认优化器的warmup起始学习率,默认为0.0。
--lr_decay_epochs 默认优化器的学习率衰减轮数。默认为 30 60 90
--lr_decay_gamma 默认优化器的学习率衰减率。默认为0.1
--save_interval_epochs
模型保存间隔(单位: 迭代轮数)。默认为1
--save_dir 模型保存路径。默认为 ./output/
--dataset 数据集目录,默认 ./dataset/
--resume_checkpoint 恢复训练时指定上次训练保存的模型路径, 默认不会恢复训练
--train_list 训练集列表,默认 '--dataset' 参数目录下的 train_list.txt
--eval_list 评估集列表,默认 '--dataset' 参数目录下的 val_list.txt
--label_list 分类标签列表,默认 '--dataset' 参数目录下的 labels.txt
--model_dir 模型读取路径。默认为 ./output/best_model
python3 run/infer.py --model_dir ./output/best_model \
--predict_image ./dataset/road_fighter_car/JPEGImages/0297.jpg
-h, --help show this help message and exit
--model_dir 读取模型的目录,默认 './output/best_model'
--predict_image 预测的图像文件
--threshold score阈值,将Box置信度低于该阈值的框过滤,默认 0.5
--result_list 预测的结果列表文件,默认 './result/result.txt'
--result_dir 预测结果可视化的保存目录,默认 './result'
--show_result 显示预测结果的图像
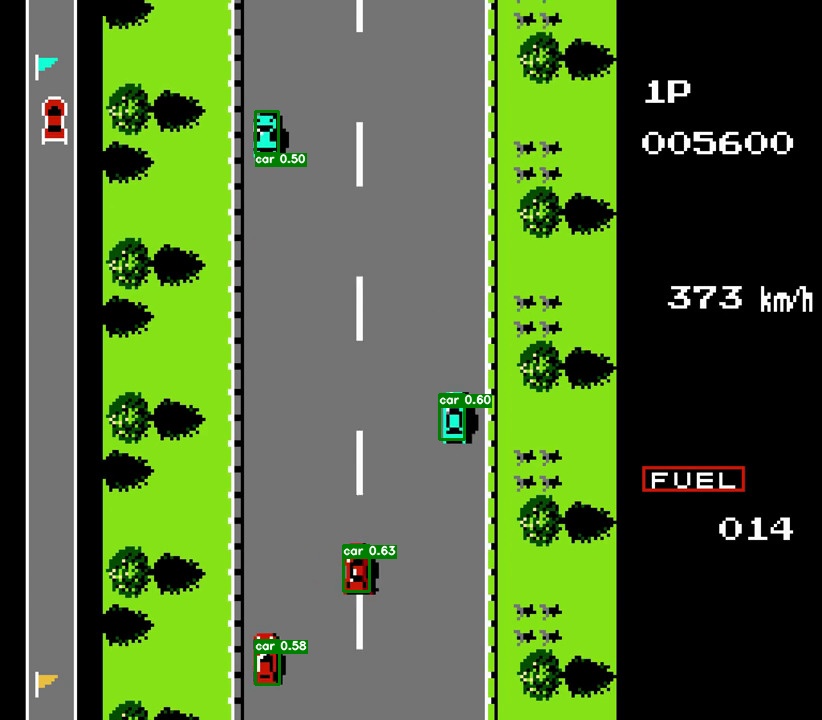
--fixed_input_shape 来指定输入大小[w,h]或者是[n,c,w,h]
paddlex --export_inference --model_dir=./output/best_model/ --save_dir=./output/inference_model --fixed_input_shape=[-1,3,608,608]
visualdl --logdir ./output/vdl_log
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
1.在Python3中,下列关于数学运算结果正确的是:(B)a=10b=3print(a//b)print(a%b)print(a/b)A.3,3,3.3333...B.3,1,3.3333...C.3.3333...,3.3333...,3D.3.3333...,1,3.3333...解析: 在Python中,//表示地板除(向下取整),%表示取余,/表示除(Python2向下取整返回3)2.如下程序Python2会打印多少个数:(D)k=1000whilek>1: print(k)k=k/2A.1000 B.10C.11D.9解析: 按照题意每次循环K/2,直到K值小于等
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭7年前。Improvethisquestion我找到的大多数库/代码都是针对RoR而不是纯ruby。即使我在谷歌上搜索纯ruby图片上传,我也会得到PureRubyOnRails;)所以...我正在寻找一个gem/library/code来做一些简单的事情:检查它是否是一个有效的图像文件将图像调整为预定义的值将其保存为jpg(来自jpeg、jpg、png、gif、bmp)
你好,Stackoverflow的人们,我经营一个网站,为用户寻找最便宜的书籍购买地点。这对于单本书来说很容易,但对于多本书来说,有时在一家商店购买一本书而在另一家商店购买另一本书会更便宜。目前我找到了销售用户列表中所有书籍的最便宜的商店,但我想要一个更智能的系统。这里有更多信息:一本书的价格对于一家商店来说是不变的。运费可能会有所不同,具体取决于书籍的数量或书籍的总值(value)。每个商店对象都可以获取一组书籍并返回运费。通常,并非每家书店都出售每一本书。不确定在这里链接到我的站点是否很酷,但它列在我的用户配置文件中。我希望能够找到最便宜的商店和书籍组合。我担心这需要一种蛮力方法-
我正在寻找FaradayMiddleware的示例,它可以处理请求中的http(状态代码)错误以及网络超时。在阅读了Faraday及其中间件的文档后,我了解到这是中间件的用例之一……我只是不知道实现应该是什么样子。谢谢 最佳答案 Faraday默认有一个错误处理中间件:faraday.useFaraday::Response::RaiseError例如:require'faraday'conn=Faraday.new('https://github.com/')do|c|c.useFaraday::Response::RaiseEr
我在第三个练习中停留在第四个RailsforZombies实验室。这是我的任务:创建将创建新僵尸的操作,然后重定向到创建的僵尸的显示页面。我有以下参数数组:params={:zombie=>{:name=>"Greg",:graveyard=>"TBA"}}我写了下面的代码作为解决方案:defcreate@zombie=Zombie.create@zombie.name=params[:zombie[:name]]@zombie.graveyard=params[:zombie[:graveyard]]@zombie.saveredirect_to(create_zombie_path
我试图掌握延续的概念,我从Wikipediaarticle中找到了几个像这样的小教学示例。:(definethe-continuation#f)(define(test)(let((i0));call/cccallsitsfirstfunctionargument,passing;acontinuationvariablerepresentingthispointin;theprogramastheargumenttothatfunction.;;Inthiscase,thefunctionargumentassignsthat;continuationtothevariablethe
有没有办法知道我的gem的根路径?我正在尝试从gems路径中的yaml加载默认配置。如何使用ruby获取gems根目录? 最佳答案 给定以下项目结构:your_gem/lib/your_gem.rb这是我的做法:#your_gem.rbmoduleYourGemdefself.rootFile.expand_path'../..',__FILE__endendRuby2.0引入了Kernel#__dir__方法;它提供了一个相当短的解决方案:#your_gem.rbmoduleYourGemdefself.rootFile.di
我开始为我正在从事的项目构建RESTAPI,这让我对使用RoR构建API的最佳方法进行了一些研究。我很快发现,默认情况下,模型对世界开放,可以通过URL调用,只需在URL末尾放置一个“.xml”并传递适当的参数。那么接下来的问题来了。如何保护我的应用程序以防止未经授权的更改?在做一些研究时,我发现了几篇关于attr_accessible的文章。和attr_protected以及如何使用它们。我发现谈论这些的特定URL于07年5月发布(here)。与ruby的所有事物一样,我确信从那时起事物已经发生了变化。所以我的问题是,这仍然是在RoR中保护RESTAPI的最佳方式吗?如果不是,您
被广泛引用的RIPHashrocketpost似乎暗示HashRocket语法(:foo=>"bar")被弃用,取而代之的是新的RubyJSON风格的哈希(foo:"bar"),但我找不到任何明确的引用资料说明HashRocket形式实际上在Ruby1.9中已被弃用/不建议使用。 最佳答案 该博文的作者过于戏剧化和愚蠢,=>是stillquitenecessary.特别是:对于不是有效标签的符号,您必须使用火箭::$set=>x有效,但$set:x无效。在Ruby2.2+中,您可以使用引号解决此问题:'$set':xwilldoTh