💗推荐阅读文章💗
- 🌸JavaSE系列🌸👉1️⃣《JavaSE系列教程》
- 🌺MySQL系列🌺👉2️⃣《MySQL系列教程》
- 🍀JavaWeb系列🍀👉3️⃣《JavaWeb系列教程》
- 🌻SSM框架系列🌻👉4️⃣《SSM框架系列教程》
🎉本博客知识点收录于🎉👉🚀《RabbitMQ系列教程》🚀—>✈️《RabbitMQ系列教程-第一章-消息中间件简介》✈️
文章目录
MQ全称为Message Queue,消息队列是消息在传递过程中的容器,消息队列常用于分布式系统之间的通信
消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题实现高性能,高可用,可伸缩和最终一致性架构;使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ以下介绍消息队列在实际应用中常用的使用场景:异步处理,应用解耦,流量削锋和消息通讯四个场景
在项目中,可将一些无需即时返回且耗时的操作提取出来,进行异步处理,而这种异步处理的方式大大的节省了服务器的请求响应时间,从而提高了系统的吞吐量。
在我们的应用中,下订单同时需要调用库存系统、支付系统等业务;

随着业务升级,需要更改业务需求,在下订单的同时需要对接积分系统进行加积分操作,因此结果变为如下:

从上图的演变我们可以知道,随着业务的不断升级,业务的不多增加,我们可能需要频繁的修改订单系统的代码,现在我们的订单系统严重和其他系统耦合在一起了,可维护差;不仅如此,当订单系统调用库存系统时,如果库存系统不能够及时响应,那么必定会造成订单系统的延迟,或者库存系统出现错误,那么也很有可能导致订单系统出现故障,系统的容错性非常低;
为了解决上述问题,我们引入了消息中间件(MQ):

当订单系统需要对接其他系统时,只需要发消息给MQ,由MQ来通知其他系统进行业务操作,订单系统只与MQ进行对接,从而解决我们上面的几个问题;
1、业务耦合
2、系统延迟
3、容错性低
在我们没有引入MQ之前的老系统中,调用订单系统,等待订单系统处理完业务逻辑之后响应客户端大概需要时间:200ms+200ms+200ms=600ms

引入了MQ队列之后只需要5ms!

这里说明一点:我们之前讲MQ概述时已经讲过,MQ适用于一些无需即时返回且耗时的操作,假设在上述架构中,订单系统需要库存系统返回某值后才能进行下一步操作则不适用于MQ;
流量削峰指的是在应用服务器面对大流量访问时,MQ可以帮助我们进行流量的限流操作,削弱流量,保证服务器的正常运行;
假设现在某电商网站搞促销活动,导致流量迅速激增,已经远远超过应用服务器的压力承受范围,此时如果不进行流量(QPS)的控制,那么应用服务器很有可能会出现故障:

为了防止过度的流量同时进入我们的应用服务器,导致应用服务器最终宕机,我们可以进行限流手段,即每秒从MQ中拉取1000个请求进行处理:

由于高并发的访问,消息会被挤压在MQ中,在高峰期过后,仍有一段时间内消息消费的速度维护在1000/s,直到积压的消息全部被消费完毕;

如上图,如果订单系统给其他系统发送完毕消息后,某个系统处理失败,该如何保证数据的一致性?
当我们一个接口多次消费一个消息时,我们需要保证这个操作无论被操作多少次其结果是一样的,这个时候我们就需要保证接口的幂等性;
幂等:一个操作任意执行多次与执行一次的结果是相同的
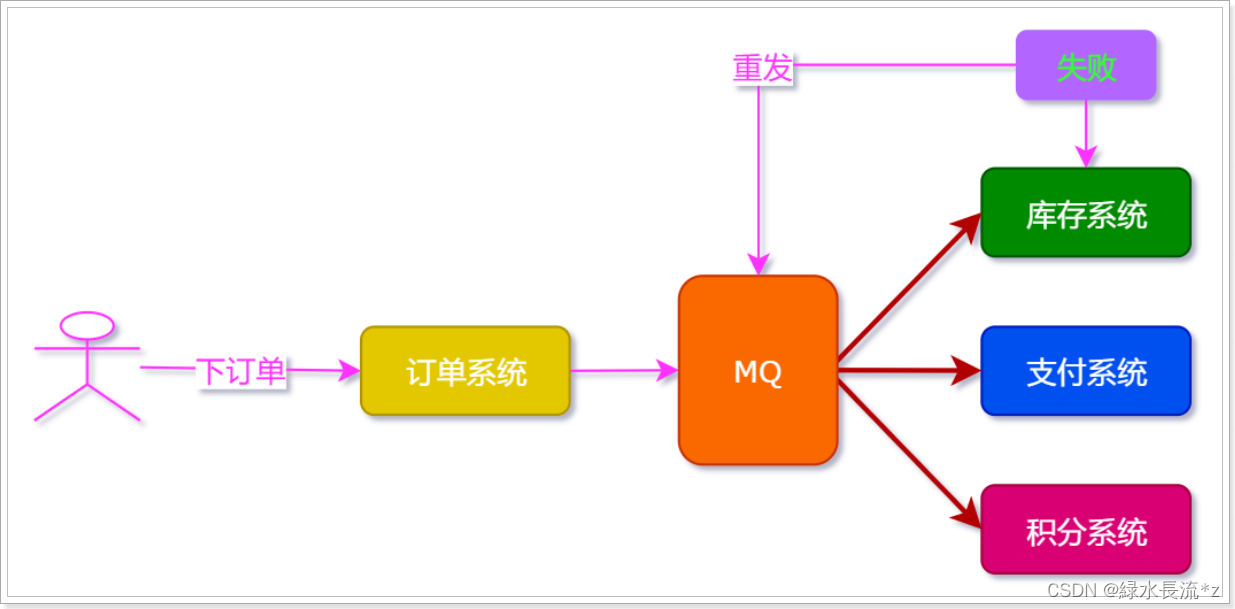
在上述系统中,如果执行库存系统出现问题,那么订单系统会重发消息,但是支付和积分系统是没有任何问题的,但由于消息的重发,导致支付和积分系统再次消费一次消息;
系统引入的外部依赖越多,系统稳定性越差。一旦 MQ 宕机,就会对业务造成影响。如何保证MQ的高可用?
MQ 的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过 MQ 进行异步调用。需要保证MQ带来的一系列问题
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义 | 自定义协议,社区封装了http协议支持 |
| 客户端支持语言 | 官方支持Erlang,Java,Ruby等,社区产出多种API,几乎支持所有语言 | Java,C,C++,Python,PHP,Perl,.net等 | Java,C++(不成熟) | 官方支持Java,社区产出多种API,如PHP,Python等 |
| 单机吞吐量 | 万级(其次) | 万级(最差) | 十万级(最好) | 十万级(次之) |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 功能特性 | 并发能力强,性能极其好,延时低,社区活跃,管理界面丰富 | 老牌产品,成熟度高,文档较多 | MQ功能比较完备,扩展性佳 | 只支持主要的MQ功能,毕竟是为大数据领域准备的。 |
AMQP是基于消息传输的一个应用层协议,JMS准确的来说是Java操作MQ的一套API,类似于JDBC,第三方厂商(MySQL厂商、MQ厂商)进行功能的实现,Java则使用JMS对厂商进行规范;
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
您认为可以作为插件很好地存在于您的Rails应用程序中必须实现的哪些行为?您过去曾搜索过哪些插件功能但找不到?哪些现有的Rails插件可以改进或扩展,如何改进或扩展? 最佳答案 我希望在管理界面中看到一个引擎插件,它提供了应用程序中所有模型的仪表板摘要,以及可配置的事件图表。 关于ruby-on-rails-您希望看到哪些Rails插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questio
所以,Ruby1.9.1现在是declaredstable.Rails应该与它一起工作,并且正在慢慢地将gem移植到它。它具有native线程和全局解释器锁(GIL)。自从GIL到位后,原生线程是否比1.9.1中的绿色线程有任何优势? 最佳答案 1.9中的线程是原生的,但它们被“放慢了速度”,一次只允许一个线程运行。这是因为如果线程真的并行运行,它会混淆现有代码。优点:IO现在在线程中是异步的。如果一个线程阻塞在IO上,那么另一个线程将继续执行直到IO完成。C扩展可以使用真正的线程。缺点:任何非线程安全的C扩展都可能存在使用Thre
我刚读了这个答案Convertingupper-casestringintotitle-caseusingRuby.有如下一行代码"abc".split(/(\W)/).map(&:capitalize).join&:capitalize到底是什么?在我自己将它放入irb之前,我会告诉你,它不是有效的ruby语法。它必须是某种Proc对象,因为Array#map通常需要一个block。但事实并非如此。如果我单独将它放入irb,我会得到syntaxerror,unexpectedtAMPER。 最佳答案 foo(&a_proc_o
我目前有一个reddit克隆类型的网站。我正在尝试根据我的用户之前喜欢的帖子推荐帖子。看起来K最近邻或k均值是执行此操作的最佳方法。我似乎无法理解如何实际实现它。我看过一些数学公式(例如k表示维基百科页面),但它们对我来说并没有真正意义。有人可以推荐一些伪代码,或者可以查看的地方,以便我更好地了解如何执行此操作吗? 最佳答案 K最近邻(又名KNN)是一种分类算法。基本上,您采用包含N个项目的训练组并对它们进行分类。如何对它们进行分类完全取决于您的数据,以及您认为该数据的重要分类特征是什么。在您的示例中,这可能是帖子类别、谁发布了该项
使用FileUtils方法有什么好处http://ruby-doc.org/core/classes/FileUtils.html比等效的Bash命令? 最佳答案 除此之外,您不必担心确保您的目标平台安装了您正在使用的特定工具这一事实,以及正确引用shell异常的问题(如果您的目标是特别有问题的)Windows和Unix-alikes——尽管有Cygwin、GNUWin32等),如果你使用Ruby的FileUtils,你有一个Ruby函数调用的中等大小的开销,而如果你使用外部实用程序,你有相当大的开销来启动一个外部进程的每一次“调用
很难说出这里要问什么。这个问题模棱两可、含糊不清、不完整、过于宽泛或夸夸其谈,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开,visitthehelpcenter.关闭9年前。在Ruby中,空字符串""对于条件判断是真值。我看到很多人都在为这个事实而苦苦挣扎。RubyonRails的blank?是克服这个问题的一种尝试。另一方面,当这种规范变得方便时,并不是立即显而易见的。是否有任何用例使这一事实变得方便,或者如果不是这样,是否会存在理论上的问题?
西安华为OD面试体验开始投简历技术面试进展工作进展开始投简历去年一整年一直在考研和工作之间纠结,感觉自己的状态好像当时的疫情一样差劲。之前刚毕业的时候投了个大厂的简历,结果一面写算法的时候太拉跨了,虽然知道时dfs但是代码熟练度不够,放在平时给足时间自己可以调试通过,但是熟练度不够那面试当时就写不出来被刷了。说真的算法学到后期我感觉最重要的是熟练度和背板子(对于我这种普通玩家来说),面试题如果一上来短时间内想不出思路就完蛋了。然后由于当时找的工作不是很理想就又想考研了。但是考研是有风险的,我自我感觉自己可能冲不上那个学校,而找工作一个没成可以继续找嘛。本着抱着试试看的态度在boss上投了简历,
在我们的项目中,我们有一些“被遗忘的”类存在了很长一段时间。那些类已被其他类替代,但我们忘记删除它们。是否有一些自动化的方法/工具可以发现Ruby{onRails}应用程序中没有使用哪些类?谢谢! 最佳答案 这个问题已经被提出了很多次,但是最好的答案都在这里:FindunusedcodeinaRailsapp我个人喜欢日志解析:https://stackoverflow.com/a/14161807但在任何情况下,您都可以创建自己的记录器,扩展ActiveRecord::Base以创建一个观察器,该观察器将最常用的模块存储在数据库中
我进行了一些谷歌搜索,似乎缺少用于jRuby的IDE。我读过TextMate和Sublime,但它们不提供调试或代码完成功能。有人可以提出建议吗(或者这项技术还处于起步阶段)? 最佳答案 有几个选项;我更喜欢JetBrains'IntelliJ(RubyMine).AptanahasanEclipseplugin.NetBeansusedtohaveofficialsupport,不确定currentstate是什么是。 关于ruby-哪些IDE可用于jRuby?,我们在StackOve