之前的rtsp功能,仅仅是对demo的简单修改,(是通过保存本地文件后在读取本地文件数据再播放)。这样存在的主要问题是,如果是先保存好文件,在读取文件传给rtsp播放,有多此一举的嫌疑,而且这样人为的增加了延迟不说,有没有这么大的硬盘让我们一直实时观看呢。更好的一个方法是我们参考海思保存码流的办法,在保存前增加开关,确定是否需要保存(参考我们的配置文件,都不需要重新编译,即可选择是否保存)是否需要实时播放,将要保存的文件直接发给rtsp是个更为明智的选择。另外时间戳也不可忽视,在实时的码流中还是非常重要的
demo版本的RTSP播放
实时流协议(RTSP)是应用层协议,控制实时数据的传送 。RTSP提供了一个可扩展框架,使受控、按需传输实时数据(如音频与视频)成为可能。数据源包括现场数据与存储在剪辑中的数据。本协议旨在于控制多个数据发送会话,提供了一种选择传送途径(如UDP、组播UDP与TCP)的方法,并提供了一种选择基于RTP (RFC1889)的传送机制的方法。
RTSP没有"连接"这个概念,而由RTSP会话(session)代替(服务器端保持一个由识别符标记的会话)。RTSP会话没有绑定传输层连接(如TCP连接)。在RTSP会话期间,RTSP客户端可以打开或关闭多个到服务器端的可靠传输连接以发出RTSP请求。但也可以使用无连接传输协议,比如UDP,来发送RTSP请求。
时间戳字段是RTP首部中说明数据包时间的同步信息,是数据能以正确的时间顺序恢复的关键。时间戳的值给出了分组中数据的第一个字节的采样 时间(Sampling Instant),要求发送方时间戳的时钟是连续、单调增长的,即使在没有数据输入或发送数据时也是如此。在静默时,发送方不必发送数据,保持时间戳的增 长,在接收端,由于接收到的数据分组的序号没有丢失,就知道没有发生数据丢失,而且只要比较前后分组的时间戳的差异,就可以确定输出的时间间隔。
RTP规定一次会话的初始时间戳必须随机选择,但协议没有规定时间戳的单位,也没有规定该值的精确解释,而是由负载类型来确定时钟的颗粒,这样 各种应用类型可以根据需要选择合适的输出计时精度。
在RTP传输音频数据时,一般选定逻辑时间戳速率与采样速率相同,但是在传输视频数据时,必须使时间戳速率大于每帧的一个滴答。如果数据是 在同一时刻采样的,协议标准还允许多个分组具有相同的时间戳值。
由于RTP协议没有规定RTP分组的长度和发送数据的速度,因而需要根据具体情况调整服务器端发送媒体数据的速度。对来自设备的实时数据可 以采取等时间间隔访问设备缓冲区,在有新数据输入时发送数据的方式,时间戳的设置相对容易。对已经录制好的本地硬盘上的媒体文件,以H.263格式的文件 为例,由于文件本身不包含帧率信息,所以需要知道录制时的帧率或者设置一个初始值,在发送数据的时候找出发送数据中的帧数目,根据帧率和预置值来计算时 延,以适当的速度发送数据并设置时间戳信息。
RTCP的一个关键作用就是能让接收方同步多个RTP流,例如:当音频与视频一起传输的时候,由于编码的不同,RTP使用两个流分别进行传输,这样两个流 的时间戳以不同的速率运行,接收方必须同步两个流,以保证声音与影像的一致。为能进行流同步,RTCP要求发送方给每个传送一个唯一的标识数据源的规范名 (Canonical Name),尽管由一个数据源发出的不同的流具有不同的同步源标识(SSRC),但具有相同的规范名,这样接收方就知道哪些流是有关联的。而发送方报告报 文所包含的信息可被接收方用于协调两个流中的时间戳值。发送方报告中含有一个以网络时间协议NTP(Network Time Protocol)格式表示的绝对时间值,接着RTCP报告中给出一个RTP时间戳值,产生该值的时钟就是产生RTP分组中的TimeStamp字段的那 个时钟。由于发送方发出的所有流和发送方报告都使用同一个绝对时钟,接收方就可以比较来自同一数据源的两个流的绝对时间,从而确定如何将一个流中的时间戳 值映射为另一个流中的时间戳值。
获取时间戳部分代码还是比较重要的,这里主要关注的rtp包的时间戳,在rtsp中,播放器的1S钟的定义是和媒体的采样率有关的。
例如视频的采样率是90K,那么最小时间粒度(单位)是1/90000秒,再转换成ms就是 1/90毫秒,这个就是rtsp中的最小时间单位。
所以设备端采集的视频的时间要经过一个转换,标准的播放器才能播放
还是以90K的视频为例,设备采集到的单位是按时间tv_sec,tv_usec存储。
/* timestamp convert
t(rtsp时间戳,单位ms) = t(采集时间戳,单位秒)*90000
*/
unsigned int tv_sec, tv_usec, pts;
tv_sec = ts / 1000;
tv_usec = (ts % 1000) * 1000;
pts = tv_sec * 90000 + tv_usec *9 / 100;
对应的如果是8K采样率的音频,则转化公式是:
/* timestamp convert
t(rtsp时间戳,单位ms) = t(采集时间戳,单位秒)*8000
*/
tv_sec = ts / 1000;
tv_usec = (ts % 1000) * 1000;
pts = tv_sec * 8000 + tv_usec *8/1000;
处于尽量不修改sample源码的原则,我们将用于保存码流的sample拷贝出来,重新写一份
s32Ret = PLATFORM_VENC_StartGetStreamRtsp(VencChn,s32ChnNum);
if (HI_SUCCESS != s32Ret)
{
SAMPLE_PRT("RTSP Start Venc failed!\n");
goto EXIT_Grp1_VENC_H264_UnBind;
}
/*
*描述 :用于创建实时显示编码后图像线程
*参数 :VeChn[] 编码通道号
s32Cnt 通道数
*返回值:创建线程PLATFORM_VENC_GetVencStreamRtsp,传递结构体gs_stPara
*注意 :无
*/
HI_S32 PLATFORM_VENC_StartGetStreamRtsp(VENC_CHN VeChn[],HI_S32 s32Cnt)
{
HI_U32 i;
gs_stPara.bThreadStart = HI_TRUE;
gs_stPara.s32Cnt = s32Cnt;
for(i=0; i<s32Cnt; i++)
{
gs_stPara.VeChn[i] = VeChn[i];
}
return pthread_create(&gs_RtspVencPid, 0, PLATFORM_VENC_GetVencStreamRtsp, (HI_VOID*)&gs_stPara);
}
/*
*描述 :调用RTSP静态库后,用于实时显示编码后图像
*参数 :p 线程传递进来的结构体指针原型为 SAMPLE_VENC_GETSTREAM_PARA_S
*返回值:NULL
*注意 :无
*/
HI_VOID* PLATFORM_VENC_GetVencStreamRtsp(HI_VOID* p)
{
HI_S32 i;
HI_S32 s32ChnTotal;
VENC_CHN_ATTR_S stVencChnAttr;
SAMPLE_VENC_GETSTREAM_PARA_S* pstPara;
HI_S32 maxfd = 0;
struct timeval TimeoutVal;
fd_set read_fds;
HI_U32 u32PictureCnt[VENC_MAX_CHN_NUM]={0};
HI_S32 VencFd[VENC_MAX_CHN_NUM];
HI_CHAR aszFileName[VENC_MAX_CHN_NUM][64];
FILE* pFile[VENC_MAX_CHN_NUM];
char szFilePostfix[10];
VENC_CHN_STATUS_S stStat;
VENC_STREAM_S stStream;
HI_S32 s32Ret;
VENC_CHN VencChn;
PAYLOAD_TYPE_E enPayLoadType[VENC_MAX_CHN_NUM];
VENC_STREAM_BUF_INFO_S stStreamBufInfo[VENC_MAX_CHN_NUM];
prctl(PR_SET_NAME, "GetVencStream", 0,0,0);
pstPara = (SAMPLE_VENC_GETSTREAM_PARA_S*)p;
s32ChnTotal = pstPara->s32Cnt;
// printf("s32ChnTotal is %d\n", s32ChnTotal);
/******************************************
step 1: check & prepare save-file & venc-fd
检查并准备保存文件和venc fd
******************************************/
if (s32ChnTotal >= VENC_MAX_CHN_NUM)
{
SAMPLE_PRT("input count invaild\n");
return NULL;
}
for (i = 0; i < s32ChnTotal; i++)
{
/* decide the stream file name, and open file to save stream
确定视频流文件名,并打开文件以保存视频流*/
VencChn = pstPara->VeChn[i];
s32Ret = HI_MPI_VENC_GetChnAttr(VencChn, &stVencChnAttr);
if (s32Ret != HI_SUCCESS)
{
SAMPLE_PRT("HI_MPI_VENC_GetChnAttr chn[%d] failed with %#x!\n", \
VencChn, s32Ret);
return NULL;
}
enPayLoadType[i] = stVencChnAttr.stVencAttr.enType;
s32Ret = PLATFORM_VENC_GetFilePostfix(enPayLoadType[i], szFilePostfix);
if (s32Ret != HI_SUCCESS)
{
SAMPLE_PRT("PLATFORM_VENC_GetFilePostfix [%d] failed with %#x!\n", \
stVencChnAttr.stVencAttr.enType, s32Ret);
return NULL;
}
if(PT_JPEG != enPayLoadType[i])
{
snprintf(aszFileName[i],32, "./RTSP/RTSP_chn%d%s", i, szFilePostfix);
pFile[i] = fopen(aszFileName[i], "wb");
if (!pFile[i])
{
SAMPLE_PRT("open file[%s] failed!\n",
aszFileName[i]);
return NULL;
}
}
/* Set Venc Fd. */
VencFd[i] = HI_MPI_VENC_GetFd(i);
if (VencFd[i] < 0)
{
SAMPLE_PRT("HI_MPI_VENC_GetFd failed with %#x!\n",
VencFd[i]);
return NULL;
}
if (maxfd <= VencFd[i])
{
maxfd = VencFd[i];
}
s32Ret = HI_MPI_VENC_GetStreamBufInfo (i, &stStreamBufInfo[i]);
if (HI_SUCCESS != s32Ret)
{
SAMPLE_PRT("HI_MPI_VENC_GetStreamBufInfo failed with %#x!\n", s32Ret);
return (void *)HI_FAILURE;
}
}
/******************************************
step 2: Start to get streams of each channel.
开始获取每个通道的视频流
******************************************/
while (HI_TRUE == pstPara->bThreadStart)
{
FD_ZERO(&read_fds);
for (i = 0; i < s32ChnTotal; i++)
{
FD_SET(VencFd[i], &read_fds);
}
TimeoutVal.tv_sec = 2;
TimeoutVal.tv_usec = 0;
s32Ret = select(maxfd + 1, &read_fds, NULL, NULL, &TimeoutVal);
if (s32Ret < 0)
{
SAMPLE_PRT("select failed!\n");
break;
}
else if (s32Ret == 0)
{
SAMPLE_PRT("get venc stream time out, exit thread\n");
continue;
}
else
{
for (i = 0; i < s32ChnTotal; i++)
{
if (FD_ISSET(VencFd[i], &read_fds))
{
/*******************************************************
step 2.1 : query how many packs in one-frame stream.
查询每个帧流中有多少包。
*******************************************************/
memset(&stStream, 0, sizeof(stStream));
s32Ret = HI_MPI_VENC_QueryStatus(i, &stStat);
if (HI_SUCCESS != s32Ret)
{
SAMPLE_PRT("HI_MPI_VENC_QueryStatus chn[%d] failed with %#x!\n", i, s32Ret);
break;
}
/*******************************************************
step 2.2 :suggest to check both u32CurPacks and u32LeftStreamFrames at the same time,for example:
建议同时检查u32CurPacks和u32LeftStreamFrames
if(0 == stStat.u32CurPacks || 0 == stStat.u32LeftStreamFrames)
{
SAMPLE_PRT("NOTE: Current frame is NULL!\n");
continue;
}
*******************************************************/
if(0 == stStat.u32CurPacks)
{
SAMPLE_PRT("NOTE: Current frame is NULL!\n");
continue;
}
/*******************************************************
step 2.3 : malloc corresponding number of pack nodes.
malloc对应的包节点数。
*******************************************************/
stStream.pstPack = (VENC_PACK_S*)malloc(sizeof(VENC_PACK_S) * stStat.u32CurPacks);
if (NULL == stStream.pstPack)
{
SAMPLE_PRT("malloc stream pack failed!\n");
break;
}
/*******************************************************
step 2.4 : call mpi to get one-frame stream
调用mpi获取一个帧流
*******************************************************/
stStream.u32PackCount = stStat.u32CurPacks;
s32Ret = HI_MPI_VENC_GetStream(i, &stStream, HI_TRUE);
if (HI_SUCCESS != s32Ret)
{
free(stStream.pstPack);
stStream.pstPack = NULL;
SAMPLE_PRT("HI_MPI_VENC_GetStream failed with %#x!\n", \
s32Ret);
break;
}
/*******************************************************
step 2.5 : save frame to file
将框架保存到文件
*******************************************************/
// SAMPLE_PRT("before if(PT_JPEG == enPayLoadType[i])!\n");
if(PT_JPEG == enPayLoadType[i])
{
// SAMPLE_PRT("after if(PT_JPEG == enPayLoadType[i])!\n");
snprintf(aszFileName[i],32, "stream_chn%d_%d%s", i, u32PictureCnt[i],szFilePostfix);
pFile[i] = fopen(aszFileName[i], "wb");
if (!pFile[i])
{
SAMPLE_PRT("open file err!\n");
return NULL;
}
}
#ifndef __HuaweiLite__
if(saveEnable)
{
if(i==rtsp_playchl)
{
s32Ret = PLATFORM_VENC_SendStream(pFile[rtsp_playchl], &stStream);
}
else
{
s32Ret = PLATFORM_VENC_SaveStream(pFile[i], &stStream);
}
}
else
{
if(i==rtsp_playchl)
{
s32Ret = PLATFORM_VENC_SendStream(pFile[rtsp_playchl], &stStream);
}
else
{
}
}
// printf("rtsp_savechl is %d,playchl is %d\n", i,rtsp_playchl);
#else
s32Ret = SAMPLE_COMM_VENC_SaveStream_PhyAddr(pFile[i], &stStreamBufInfo[i], &stStream);
#endif
if (HI_SUCCESS != s32Ret)
{
free(stStream.pstPack);
stStream.pstPack = NULL;
SAMPLE_PRT("save stream failed!\n");
break;
}
/*******************************************************
step 2.6 : release stream
释放视频流
*******************************************************/
s32Ret = HI_MPI_VENC_ReleaseStream(i, &stStream);
if (HI_SUCCESS != s32Ret)
{
SAMPLE_PRT("HI_MPI_VENC_ReleaseStream failed!\n");
free(stStream.pstPack);
stStream.pstPack = NULL;
break;
}
/*******************************************************
step 2.7 : free pack nodes
释放包节点
*******************************************************/
free(stStream.pstPack);
stStream.pstPack = NULL;
u32PictureCnt[i]++;
if(PT_JPEG == enPayLoadType[i])
{
fclose(pFile[i]);
}
}
}
}
}
/*******************************************************
* step 3 : close save-file
*******************************************************/
for (i = 0; i < s32ChnTotal; i++)
{
if(PT_JPEG != enPayLoadType[i])
{
fclose(pFile[i]);
}
}
return NULL;
}
sample的保存文件是在for循环里分别保存每个通道的码流信息,我们要实时播放自然不能让其他通道的码流乱入进来,所以我们在引入rtsp_playchl播放通道这个变量,又可以通过我们好用的配置文件随时想播放的通道,当然播放的时候最好也不要影响我们本地保存的功能,我们把原本的保存函数也做修改
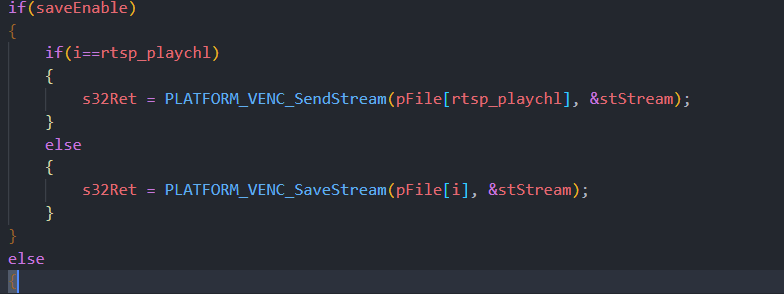
直接发送出去,有全局的保存开关,也可以决定是否保存,这个函数是有码流时while1进的,随时可以更新
/******************************************************************************
*描述 :发送文件
*参数 :pFd 文件描述符
pstStream 帧码流类型结构体。
*返回值:成功返回0
*注意 :无
******************************************************************************/
HI_S32 PLATFORM_VENC_SendStream(FILE* pFd,VENC_STREAM_S* pstStream)
{
HI_S32 i;
int status = 0;
for (i = 0; i < pstStream->u32PackCount; i++)
{
ts=rtsp_get_reltime();
rtsp_tx_video(session[0],(pstStream->pstPack[i].pu8Addr + pstStream->pstPack[i].u32Offset), pstStream->pstPack[i].u32Len , ts);
rtsp_do_event(demo);
if(saveEnable)
{
fwrite(pstStream->pstPack[i].pu8Addr + pstStream->pstPack[i].u32Offset,
pstStream->pstPack[i].u32Len - pstStream->pstPack[i].u32Offset, 1, pFd);
fflush(pFd);
}
}
return HI_SUCCESS;
}
当然rtsp的配置部分也做了简单修改,初始化部分只需要做
create_rtsp_demo,创建一个端口
create_rtsp_session,在创建好一个用来播放的节点,vlc播放器打开时匹配同名路径
rtsp_set_video,设置码流信息,默认h264
while(1)
{
rtsp_get_reltime();获取时间戳
rtsp_tx_video 发送码流
rtsp_do_event发送码流
}
rtsp_del_session删除节点
rtsp_del_demo删除端口
/*
*描述 :用于rtsp实时播放的线程
*参数 :NULL
*返回值:无
*注意 :加载文件platform.ini rtsp://192.168.119.164:8554/mnt/sample/venc/rtsp.264
*/
void *video_play_rtsp_task(void* arg)
{
cpu_set_t mask;//cpu核的集合
cpu_set_t get;//获取在集合中的cpu
int num = sysconf(_SC_NPROCESSORS_CONF);
printf("frame_check_task:system has %d processor(s)\n", num);
CPU_ZERO(&mask);//置空
CPU_SET(3, &mask);//设置亲和力值
if (pthread_setaffinity_np(pthread_self(), sizeof(mask), &mask) < 0)//设置线程CPU亲和力
{
fprintf(stderr, "set thread affinity failed\n");
}
if (pthread_getaffinity_np(pthread_self(), sizeof(get), &get) < 0)//获取线程CPU亲和力
{
fprintf(stderr, "get thread affinity failed\n");
}
printf("rtsp ts is %lld\n", rtsp_ts);
demo = create_rtsp_demo(8554);//rtsp sever socket
if (NULL == demo) {
SAMPLE_PRT("rtsp new demo failed!\n");
// return 0;
}
// session[0] = rtsp_new_session(demo, "/mnt/sample/venc/rtsp.264");//对应rtsp session
session[0] = create_rtsp_session(demo, "/mnt/sample/venc/RTSP/RTSP_chn0.h264");//对应rtsp session
if (NULL == session[0]) {
printf("rtsp_new_session failed\n");
// continue;
}
printf("==========> rtsp://192.168.119.200:8554/mnt/sample/venc/RTSP/RTSP_chn0.h264 <===========\n" );
ts = rtsp_get_reltime();
// signal(SIGINT, sig_proc);
getchar();
return 0;
}
这样做后在不保存多路码流的情况下已经非常稳定且低延时了,为了尽善尽美,引入缓冲池来播放来缓存码流会是更好的选择,具体做法关注后续更新rtsp3
我一直在寻找一种以编程方式或通过命令行将mp3转换为aac的方法,但没有成功。理想情况下,我有一段代码可以从我的Rails应用程序中调用,将mp3转换为aac。我安装了ffmpeg和libfaac,并能够使用以下命令创建aac文件:ffmpeg-itest.mp3-acodeclibfaac-ab163840dest.aac当我将输出文件的名称更改为dest.m4a时,它无法在iTunes中播放。谢谢! 最佳答案 FFmpeg提供AAC编码功能(如果您已编译它们)。如果您使用的是Windows,则可以从here获取完整的二进制文件。
参考文章搭建文章gitte源码在线体验可以注册两个号来测试演示图:一.整体介绍 介绍SignalR一种通讯模型Hub(中心模型,或者叫集线器模型),调用这个模型写好的方法,去发送消息。 内容有: ①:Hub模型的方法介绍 ②:服务器端代码介绍 ③:前端vue3安装并调用后端方法 ④:聊天室样例整体流程:1、进入网站->调用连接SignalR的方法2、与好友发送消息->调用SignalR的自定义方法 前端通过,signalR内置方法.invoke() 去请求接口3、监听接受方法(渲染消息)通过new signalR.HubConnectionBuilder().on
我如何用ruby编写一个脚本,当从命令行执行时播放mp3文件(背景音乐)?我试过了run="mplayer#{"/Users/bhushan/resume/m.mp3"}-aosdl-vox11-framedrop-cache16384-cache-min20/100"system(run)但它也不起作用,以上是播放器特定的。如果用户没有安装mplayer怎么办。有没有更好的办法? 最佳答案 我一般都是这样pid=fork{exec'mpg123','-q',file} 关于ruby
我希望Ruby的解析器会进行这种微不足道的优化,但似乎并没有(谈到YARV实现,Ruby1.9.x、2.0.0):require'benchmark'deffib1a,b=0,1whileb由于这两种方法除了在第二种方法中使用预定义常量而不是常量表达式外是相同的,因此Ruby解释器似乎在每个循环中一次又一次地计算幂常数。是否有一些Material说明为什么Ruby根本不进行这种基本优化或只在某些特定情况下进行? 最佳答案 很抱歉给出了另一个答案,但我不想删除或编辑我之前的答案,因为它下面有有趣的讨论。正如JörgWMittag所说,
在Rails3.x应用程序中,我正在使用net::ssh并向远程pc运行一些命令。我想向用户的浏览器显示实时日志。比如,如果两个命令在net中运行::ssh执行即echo"Hello",echo"Bye"被传递然后"Hello"应该在执行后立即显示在浏览器中。这是代码我在rubyonrails应用程序中使用ssh连接和运行命令Net::SSH.start(@servers['local'],@machine_name,:password=>@machine_pwd,:timeout=>30)do|ssh|ssh.open_channeldo|channel|channel.requ
我正在尝试从数据库中读取大量单元格(超过100.000个)并将它们写入VPSUbuntu服务器上的csv文件。碰巧服务器没有足够的内存。我正在考虑一次读取5000行并将它们写入文件,然后再读取5000行,等等。我应该如何重构我当前的代码以使内存不会被完全消耗?这是我的代码:defwrite_rows(emails)File.open(file_path,"w+")do|f|f该函数由sidekiqworker调用:write_rows(user.emails)感谢您的帮助! 最佳答案 这里的问题是,当您调用emails.each时,
文章目录前言约束硬约束的轨迹优化Corridor-BasedTrajectoryOptimizationBezierCurveOptimizationOtherOptions软约束的轨迹优化Distance-BasedTrajectoryOptimization优化方法前言可以看看我的这几篇Blog1,Blog2,Blog3。上次基于MinimumSnap的轨迹生成,有许多优点,比如:轨迹让机器人可以在某个时间点抵达某个航点。任何一个时刻,都能数学上求出期望的机器人的位置、速度、加速度、导数。MinimumSnap可以把问题转换为凸优化问题。缺点:MnimumSnap可以控制轨迹一定经过中间的
我对为我的RubyonRails3.1.3应用优化我的Unicorn设置的方法很感兴趣。我目前正在高CPU超大实例上生成14个工作进程,因为我的应用程序在负载测试期间似乎受CPU限制。在模拟负载测试中,每秒大约20个请求重放请求,我的实例上的所有8个内核都达到峰值,盒子负载飙升至7-8个。每个unicorn实例使用大约56-60%的CPU。我很好奇可以通过哪些方式对其进行优化?我希望能够每秒将更多请求汇集到这种大小的实例上。内存和所有其他I/O一样完全正常。在我的测试过程中,CPU越来越低。 最佳答案 如果您受CPU限制,您希望使用
美团外卖搜索工程团队在Elasticsearch的优化实践中,基于Location-BasedService(LBS)业务场景对Elasticsearch的查询性能进行优化。该优化基于Run-LengthEncoding(RLE)设计了一款高效的倒排索引结构,使检索耗时(TP99)降低了84%。本文从问题分析、技术选型、优化方案等方面进行阐述,并给出最终灰度验证的结论。1.前言最近十年,Elasticsearch已经成为了最受欢迎的开源检索引擎,其作为离线数仓、近线检索、B端检索的经典基建,已沉淀了大量的实践案例及优化总结。然而在高并发、高可用、大数据量的C端场景,目前可参考的资料并不多。因此
3559操作自记录0502ubuntu操作日志sudoapt-getinstallcmake-qt-guiwhereisaarch64-himix100-linux-gccaarch64-himix100-linux-gcc:/opt/hisi-linux/x86-arm/aarch64-himix100-linux/bin/aarch64-himix100-linux-gcc然后把同级的gnu放进来了,然后confige,然后generate然后make(没有输出安全通过),然后makeinstallhaitu@ubuntu:~/eigen-3.4.0/aarch_eigen$cdbuild