阅读目录
在日常的项目测试过程中,搭建与维护测试环境是广大测试同学的一个基础技能,相信也很少会有公司完全不让测试去碰自己的测试环境。那么工作中大量的创建、部署、管理、维护等一系列的重复操作就成为了整个测试项目中一个巨大的工作量。
面对这样一种普遍的情况,Jenkins作为持续集成的良好解决方案就可以很好的解决以上的这些问题。对于一些重复的搭建部署操作都可以通过Jenkins来进行自动化完成,无需任何人工干预,有利于减少重复过程以节省时间、费用和工作量,让测试同学腾出更多的时间与精力来关注并着眼于其他的重要测试环节。
1.此笔记的中所使用的操作系统为CentOS7.9,笔记中所涉及的软件版本有可能会因为时间的推移而导致不匹配或其他额外的操作,请大家有针对性的选择阅读与参考。
2.此笔记中的所有操作均基于root用户进行,其他用户如无权限请自行搜索(linux的基础操作这里不展开讨论),友情提示:即使有权限,也千万别在公司相关生产环境内试验探索哦。
3.本次实战中使用的是我们公司相关的业务项目,其中的代码与产品界面会做相关的脱敏操作。
1.文中产品项目为微服务架构,其他无关服务都已被简化省略,仅展示部分模块。
2.原有服务已简化,将服务器独立分为Jenkins服务器与业务服务器,不展示多余集群与节点,只需准备两台服务器即可(真机、虚拟机随意)
3.本文的主题是介绍Jenkins在持续集成中的使用方式,开发环境与所用到的软件版本可以任意指定,功能没有太大的区别,也不会影响使用。(文中使用的软件可以任意替换,任何的技术栈都可以,Jenkins除外)
服务器分为两台,Jenkins应用服务器与业务服务器,以下简称J-Server与S-Server。本文使用CentOS,J-Server中安装Jenkins即可,S-Server安装Java、Tomcat、Maven、Git即可。(这里的技术栈可以根据各自公司的业务与产品来进行随意调整,我们的项目内也有很多组合,只选取市面上最常见的来讲解)
服务器内的Jenkins安装与配置请参看之前的文章:
【Jenkins使用手册(1) —— 软件安装】
【Jenkins使用手册(2) —— 软件配置】
业务服务器内的软件安装请自行网络搜索,网上有很多优秀的教程供大家参考。这里需要介绍的是一些重要的配置操作。
1.这里为了方便Git与Server之间进行安全的项目源代码的安全传输操作,我们需要在服务器中进行设置。
在Git安装完之后使用以下命令进行Git的全局配置
git config --global user.name "你的用户名"
git config --global user.email "你的邮箱"
使用ssh-keygen命令进行密钥的生成
ssh-keygen -C 邮箱 -t rsa
这里会询问你要创建的密钥的文件名,默认名字的话就直接回车

接下来询问是否要为密钥设定密码,默认回车跳过

完成之后在用户的主目录中会有一个影藏文件夹.ssh
进入后查看刚才的密钥是否生成正确
后缀名.pbu的是公钥

然后我们进入这个公钥文件,将文件里的内容复制出来

2.在GitHub中点击设置,选择SSH and GPG keys
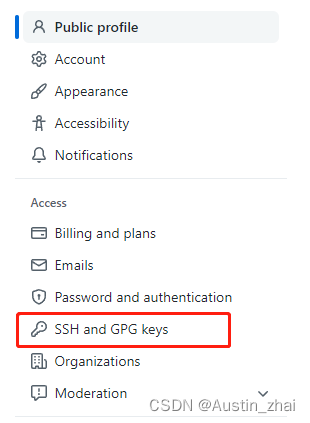
创建一个新的SSH key
Title输入你自定义的名字即可
Key输入刚才在公钥中复制的那一串字符
确定添加
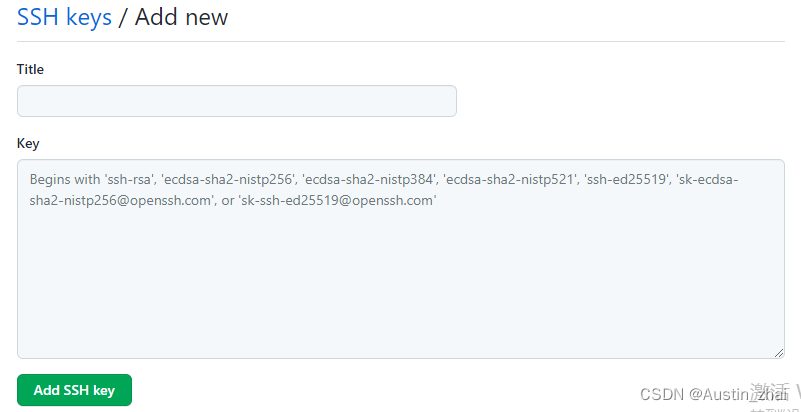
确认添加成功后Git与SSH密钥配置完成
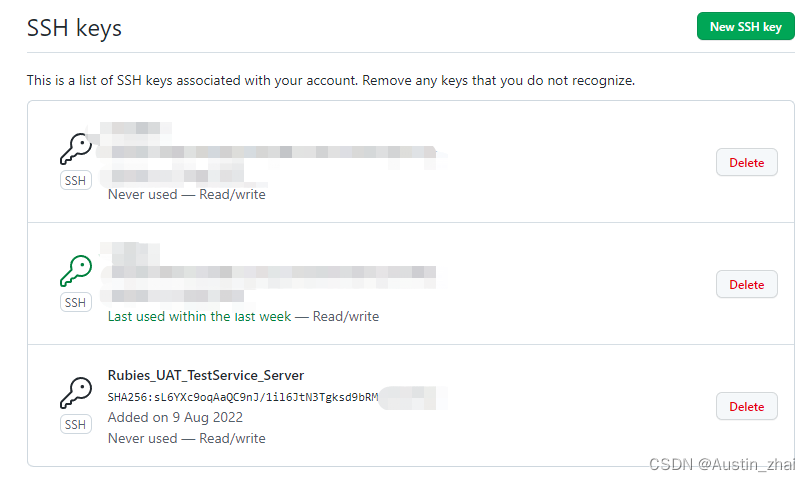
在Jenkins工作台中选择系统管理 > 节点管理
选择新建节点
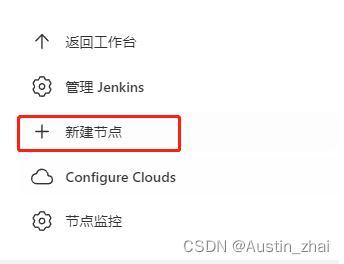
节点名称输入你指定的名称即可
如果是全新节点的话可选择固定节点
点击创建
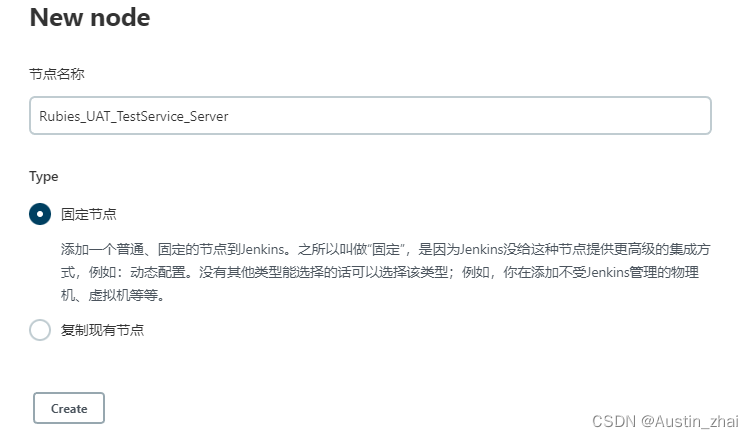
远程工作目录指的是S-Server上将执行自动化任务的路径位置
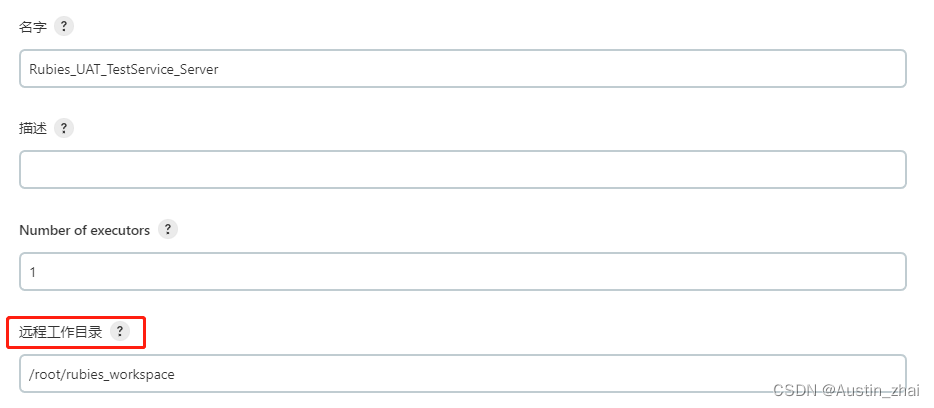
启动方式选择Launch agents via SSH
主机填入对应的S-Server的IP
凭证填入对应的S-Server登录用户名和密码(新建凭证看下面的操作)
主机密钥验证策略可以选择Non verifying Verification Strategy
没有凭证的话点击添加,选择Jenkins
其他选项不动,输入用户名和密码保存即可,之后在Credentials
下拉框里直接选择即可

添加完成后点击对应的节点名称,进入节点
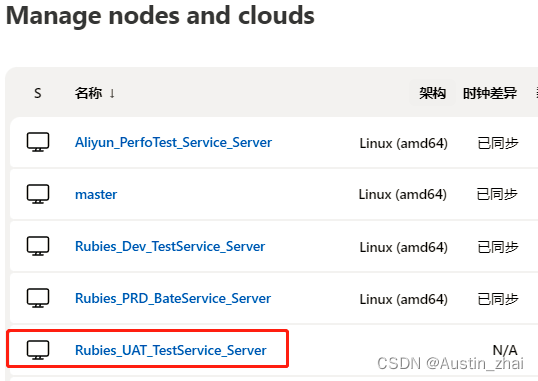
点击重启代理

启动完成后,日志提示启动成功后返回列表查看节点状态,显示同步则表示节点启动成功
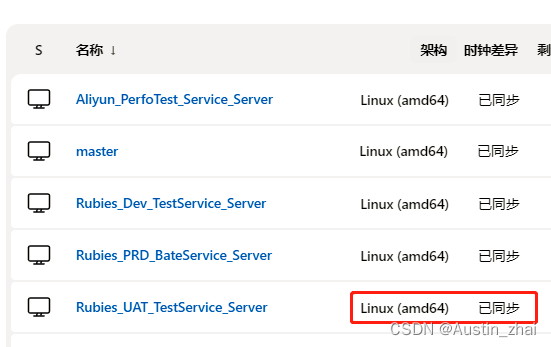
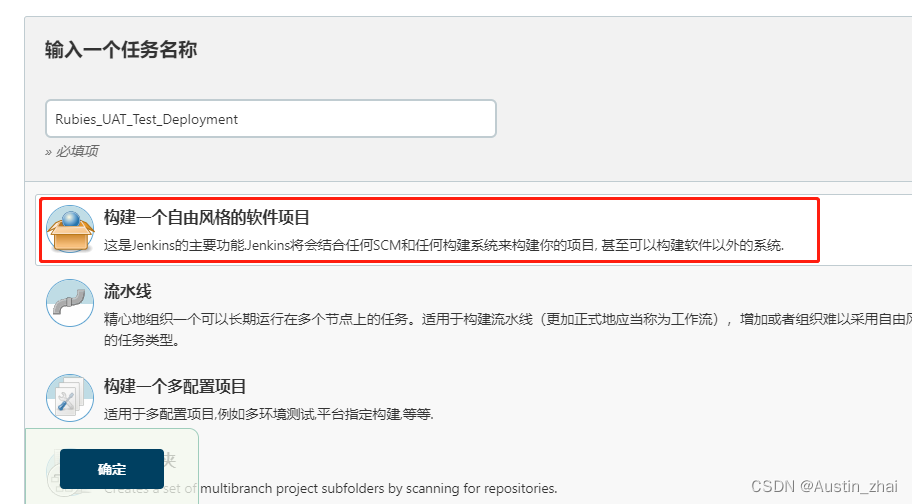
点击节点后选择新建任务

输入自定义的任务名称并选择构建自由风格的软件项目
确定添加
描述中输入任务相关的一些说明(非必须),这里还是推荐大家填写一下,很多必备的信息甚至备注都可以放在里面,方便其他测试人员快速的对任务有一个了解。
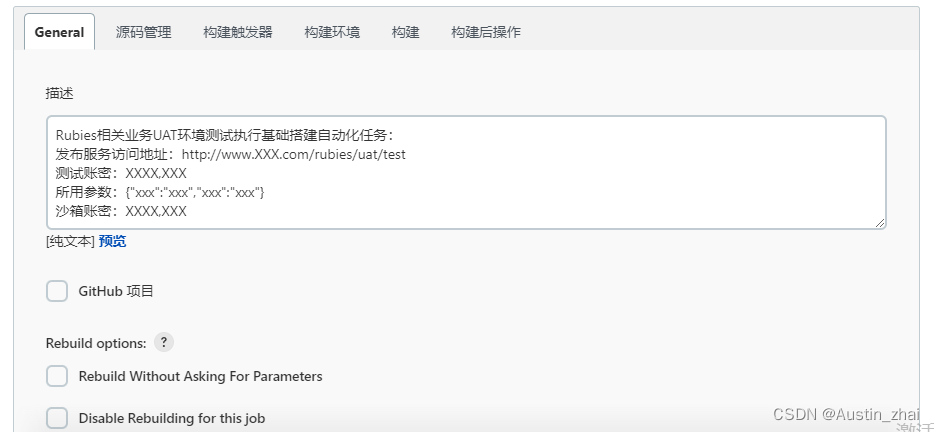
如果每个节点内的环境不是集群或业务有所不同的话还是建议勾上限“制项目的运行节点”的选项,并指定对应的服务节点。
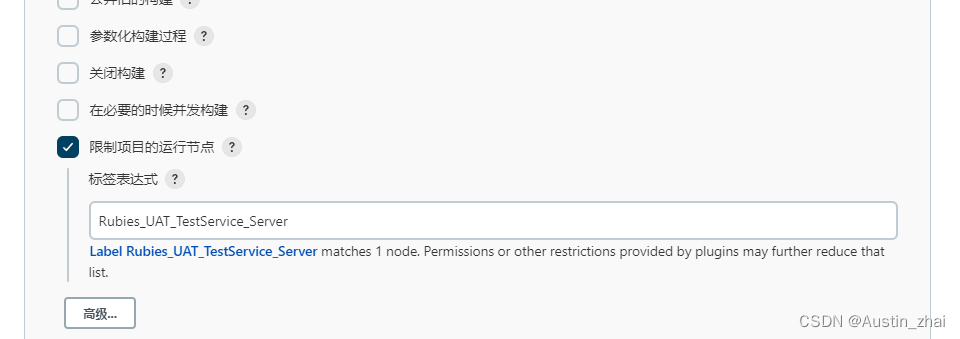
在源码管理中选择Git

这里在仓库URL中输入项目的源代码下载地址,基于之前已经添加过SSH key了,下载的方式就在Git上选择SSH。在此之前大家记得把自己的项目或产品源代码push至对应的Git仓库并保证S-Sever可以clone代码至本地。
(这里根据自己公司的业务来进行选择,无论是公有仓库还是私有仓库,云还是私有化部署的仓库)
另外如果是第一次在新任务中创建仓库URL,记得在下面多创建一次仓库URL
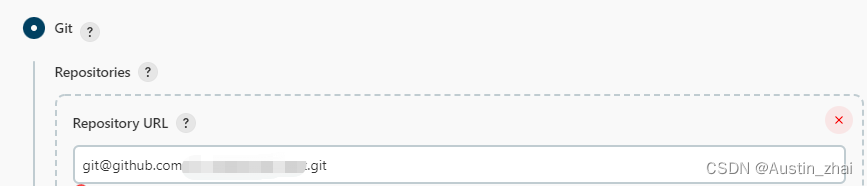
凭证之前已经添加过了,直接选择S-Server的账密记录即可
这里选择源代码在Git上所对应的分支,默认为master分支,我的项目源代码在main分支上,这边就输入*/main
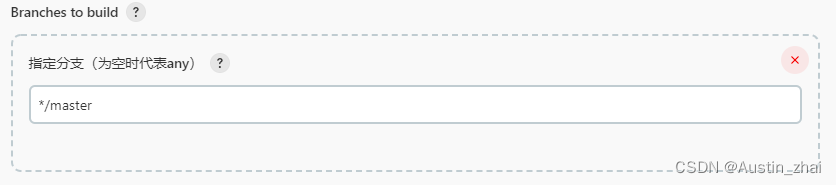
在扩展行为中选择新增
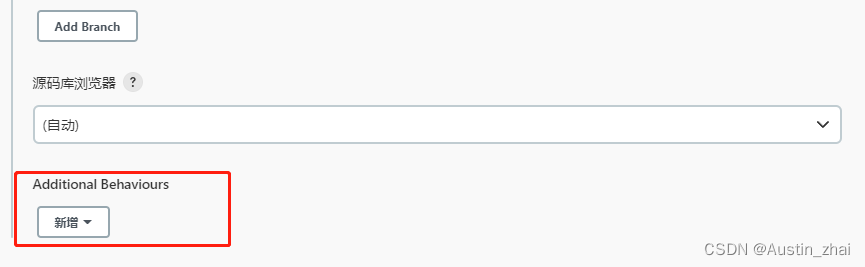
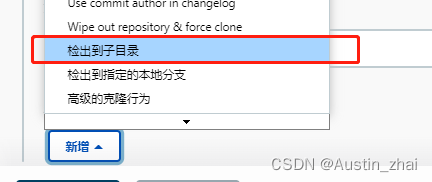
选择“检出到子目录”,英文选项(check out to a sub-directory)
输入自己定义的子目录名字即可

在构建中选择增加构建步骤,选择执行shell
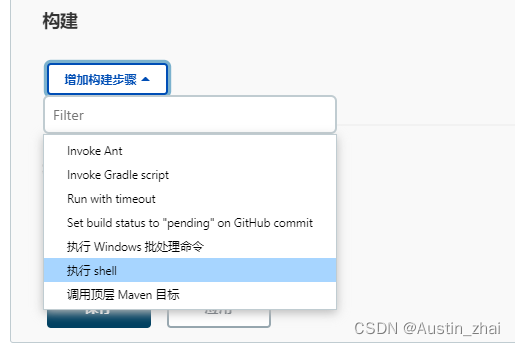
自动化任务的流程示意图
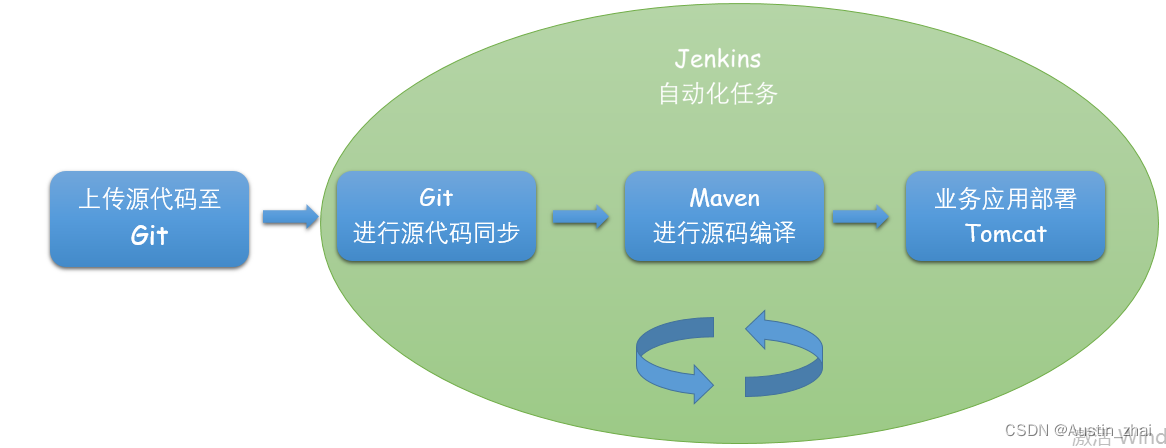
基于以上的技术栈,我们执行以下shell命令
方便Jenkins进行后台运行
BUILD_ID=dontkillme
设置两个全局变量,第一个可以返回工作目录所在位置,也就是刚才Jenkins中设置的远程目录;第二个可以返回Tomcat的安装位置,方便后续脚本内的Tomcat相关服务的操作。
export WORK_PATH=`pwd`
export TOMCAT_PATH=`S-Server内的tomcat安装路径`
sh $WORK_PATH/build.sh
点击保存后,点击任务名

进入后点击左侧的立即构建

点击任务队列中对应的任务
选择控制台输出或直接查看状态图标
最后显示Finished: SUCCESS 就表示构建成功了
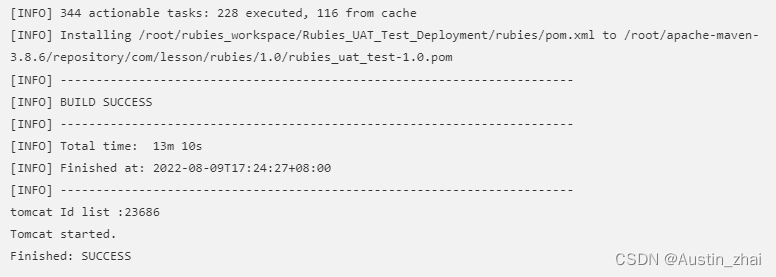
至此一个测试环境就通过Jenkins的自动任务构建完成了,大家可以通过对应的服务IP和端口进行访问验证。
以上只是展示了如何通过Jenkins来进行测试环境的快速自动化搭建,后续会对实战中的一些细节来进行讲解。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在使用Sequel构建一个愿望list系统。我有一个wishlists和itemstable和一个items_wishlists连接表(该名称是续集选择的名称)。items_wishlists表还有一个用于facebookid的额外列(因此我可以存储opengraph操作),这是一个NOTNULL列。我还有Wishlist和Item具有续集many_to_many关联的模型已建立。Wishlist类也有:selectmany_to_many关联的选项设置为select:[:items.*,:items_wishlists__facebook_action_id].有没有一种方法可以
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r