目录
JVM 内存区域主要分为线程私有区域【程序计数器、虚拟机栈、本地方法栈】、线程共享区域【JAVA 堆、方法区】、直接内存。

线程私有数据区域生命周期与线程相同, 依赖用户线程的启动/结束而创建/销毁
在 Hotspot VM 内, 每个线程都与操作系统的本地线程直接映射,
因此这部分内存区域的生命周期也可以说是和本地线程相同。
线程共享区域随虚拟机的启动/关闭而创建/销毁
直接内存并不是 JVM 运行时数据区的一部分, 但也会被频繁的使用: 在 JDK 1.4 引入的 NIO 提
供了基于 Channel 与 Buffer 的 IO 方式, 它可以使用 Native 函数库直接分配堆外内存, 然后使用
DirectByteBuffer 对象作为这块内存的引用进行操作(详见: Java I/O 扩展), 这样就避免了在 Java
堆和 Native 堆中来回复制数据, 因此在一些场景中可以显著提高性能

一块较小的内存空间, 是当前线程所执行的字节码的行号指示器,每条线程都要有一个独立的程序计数器,这类内存也称为“线程私有”的内存。
正在执行 java 方法的话,计数器记录的是虚拟机字节码指令的地址(当前指令的地址)。如果是 Native 方法,则为空。
这个内存区域是唯一一个在虚拟机中不会出现 OutOfMemoryError 情况的区域
是描述java方法执行的内存模型,每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
本地方法区和 Java Stack 作用类似, 区别是虚拟机栈为执行 Java 方法服务, 而本地方法栈则为Native 方法服务, 如果一个 VM 实现使用 C-linkage 模型来支持 Native 调用, 那么该栈将会是一个C 栈,但 HotSpot VM 直接就把本地方法栈和虚拟机栈合二为一
是被线程共享的一块内存区域
创建的对象和数组都保存在 Java 堆内存中
垃圾收集器进行垃圾收集的最重要的内存区域
由于现代 VM 采用分代收集算法, 因此 Java 堆从 GC 的角度还可以细分为: 新生代(Eden 区、From Survivor 区和 To Survivor 区)和老年代
即我们常说的永久代(Permanent Generation), 用于存储被 JVM 加载的类信息、常量、静态变量、即时编译器编译后的代码等数据.
HotSpot VM把GC分代收集扩展至方法区, 即使用Java堆的永久代来实现方法区, 这样 HotSpot 的垃圾收集器就可以像管理 Java 堆一样管理这部分内存, 而不必为方法区开发专门的内存管理器(永久代的内存回收的主要目标是针对常量池的回收和类型的卸载, 因此收益一般很小)
Java 堆从 GC 的角度还可以细分为: 新生代(Eden 区、From Survivor 区和 To Survivor 区)和老年代
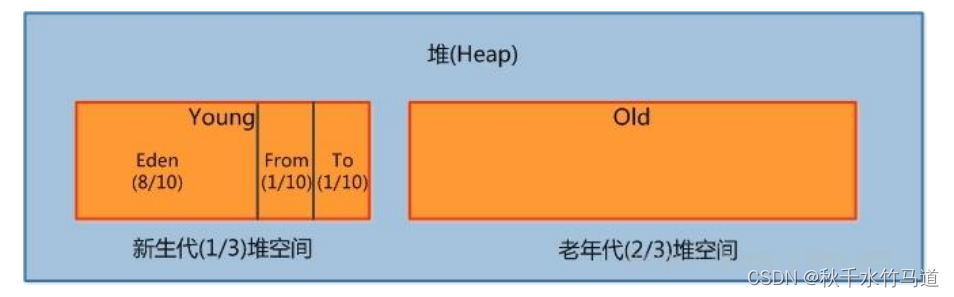
是用来存放新生的对象。一般占据堆的 1/3 空间。
由于频繁创建对象,所以新生代会频繁触发MinorGC 进行垃圾回收。新生代又分为 Eden 区、ServivorFrom、ServivorTo 三个区。
Eden 区
Java 新对象的出生地(如果新创建的对象占用内存很大,则直接分配到老年代)。当 Eden 区内存不够的时候就会触发 MinorGC,对新生代区进行一次垃圾回收
ServivorFrom
上一次 GC 的幸存者,作为这一次 GC 的被扫描者
ServivorTo
保留了一次 MinorGC 过程中的幸存者。
MinorGC 采用复制算法。
首先,把 Eden 和 ServivorFrom 区域中存活的对象复制到 ServicorTo 区域(如果有对象的年龄以及达到了老年的标准,则赋值到老年代区),同时把这些对象的年龄+1(如果 ServicorTo 不够位置了就放到老年区)
然后,清空 Eden 和 ServicorFrom 中的对象
最后,ServicorTo 和 ServicorFrom 互换,原 ServicorTo 成为下一次 GC 时的 ServicorFrom区。
主要存放应用程序中生命周期长的内存对象。
老年代的对象比较稳定,所以 MajorGC 不会频繁执行。在进行 MajorGC 前一般都先进行了一次 MinorGC,使得有新生代的对象晋身入老年代,导致空间不够用时才触发。
当无法找到足够大的连续空间分配给新创建的较大对象时也会提前触发一次 MajorGC 进行垃圾回收腾出空间。
MajorGC 采用标记清除算法:
首先扫描一次所有老年代,标记出存活的对象,然后回收没有标记的对象。
MajorGC 的耗时比较长,因为要扫描再回收。
MajorGC 会产生内存碎片,为了减少内存损耗,我们一般需要进行合并或者标记出来方便下次直接分配。
当老年代也满了装不下的时候,就会抛出 OOM(Out of Memory)异常。
是否存在GC.disable会降低性能的情况?只要我使用的是真正的RAM而不是交换内存,就可以这样做吗?我正在使用MRIRuby2.0,据我所知,它是64位的,并且使用的是64位的Ubuntu:ruby2.0.0p0(2013-02-24revision39474)[x86_64-linux]Linux[redacted]3.2.0-43-generic#68-UbuntuSMPWedMay1503:33:33UTC2013x86_64x86_64x86_64GNU/Linux 最佳答案 GC.disable将禁用垃圾回收。像rub
我正在编写定义类的ruby扩展。如果我使用Data_Wrap_Struct()来实现我对rb_define_alloc_func()的回调,我是否需要手动标记和释放实例变量?还是仍然为我处理? 最佳答案 Ruby的GC将收集在您的Ruby对象的实例变量中引用的所有Ruby对象。您不必也不应该自己释放Ruby实例变量(即在您的扩展中使用rb_iv_set()/rb_iv_get()访问的任何对象)。但是,如果包装的Cstruct引用Ruby对象,那么您必须在传递给Data_Wrap_Struct()的mark回调中标记这些对象。(
我正在处理的代码库最近从Ruby1.9.2升级到Ruby1.9.3,从Rails3.1升级到Rails3.2.2。因为我使用的是RVM,所以我只是简单地执行了rvminstall1.9.3,我原以为这是所有必要的。当我运行时railss我得到了错误[BUG]cross-threadviolationonrb_gc()我找到了许多与此问题相关的链接。有oneonStackOverflow,但它并没有真正给出答案。最有希望的答案是ontheRVMsite:IneverycaseofthisIhaveseenthusfarithasalwaysendedupbeingthatarubygem
我正在开发一个Rails2.3、Ruby1.9.1网络应用程序,它在每个请求之前执行大量计算。对于每个请求,它都必须计算一个包含300个节点和约1000条边的图。该图及其所有节点、边和其他对象针对每个请求(~2000个对象)进行初始化-实际上,它们是使用Marshal.load(Marshal.dump())从未计算的缓存图中克隆的。性能在这里是一个很大的问题。现在整个请求平均需要150毫秒。然后我看到在请求期间,部分计算随机花费更长的时间。假设这可能是GarbageCollector启动,我将请求包装在GC.disable和GC.enable中,以便请求等待垃圾收集,直到计算和渲染完
我有一个rubyonrails应用程序。我正在调查我的NewRelic门户中的Apdex下降情况,我发现平均有250-320毫秒的时间花在了GC执行上。这是一个非常令人不安的数字。我在下面包含了一个屏幕截图。我的Ruby版本是:ruby1.9.3p194(2012-04-20修订版35410)[x86_64-linux]任何关于调整它的建议都是理想的。这个数字应该低得多。 最佳答案 您在GC上花费了很多时间,因为您经常运行GC。默认情况下,Ruby设置适用于小型脚本而非大型应用程序的GC参数。尝试使用以下环境参数集启动您的应用:
我正在使用GC.stat来分析我们的Rails应用程序中的内存使用情况。GC.stat返回具有以下键的散列::count:heap_used:heap_length:heap_increment:heap_live_num:heap_free_num:heap_final_num有人知道这些值的确切含义吗?Ruby源代码(gc.c)中没有关于它们的文档,只有评论:“散列的内容是实现定义的,将来可能会更改。”其中一些字段在上下文中是有意义的,例如count是Ruby分配的堆数。但是heap_final_num是什么?什么是heap_increment?heap_length是最小堆大小吗
这是我目前知道的唯一询问方式。据了解,Scala使用Java虚拟机。我以为Jruby也是。Twitter将其中间件切换为Scala。他们可以做同样的事情并使用Jruby吗?他们是否可以从Jruby开始,而不是因为扩展问题导致他们首先从Ruby迁移到Scala?我不明白Jruby是什么吗?我假设因为Jruby可以使用Java,所以它可以扩展到Ruby不能的地方。在这种情况下,一切都归结为静态类型与动态类型吗? 最佳答案 Scala是“可扩展的”,因为语言可以通过库进行改进,使扩展看起来像是语言的一部分。这就是为什么actors看起来像
我一直在尝试优化一个Angular网站,但在某些路由之间切换时,我的页面响应出现大量延迟。显示的每个页面都不大,但其中包含相当数量的元素和合理数量的绑定(bind)。我已经用bindonce做了我能做的,所以我用Chrome查看了调试器,我发现我的大部分时间似乎都花在了GC上。奇怪的是,每个GC之间似乎存在巨大的差距,我正试图弄清楚这些差距到底是什么。我猜是在它实际删除项目时,小条是在进行标记和清除时,但我对分析JS的这种深度并不熟悉。我的大部分工作都是在C++/C#/Java中完成的。 最佳答案 在半秒内收集了超过20MB的垃圾。
问题添加节点,同时从DOM中删除旧节点,不会从内存中丢弃旧节点。(至少不是全部,没有明显的原因)。如何看待这种情况(你已经知道了,但无论如何..)右键单击输出区域并使用Chrome开发人员工具进行检查。单击时间轴选项卡,然后单击左上角的圆圈(点)开始录制。现在点击body元素,它将开始每300ms添加和删除项目(删除的节点应该被垃圾收集)。停止记录,将数据采样区域扩展到最大,您将在屏幕的下半部分看到绿色的节点。预期的图形将上下波动(其中向下表示节点已被GC正确丢弃)。测试页面这2个测试页面非常原始。当然,在现实生活中,开发人员使用生成大量文本的模板,这些文本应转换为DOM并注入(inj
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭4年前。Improvethisquestion更正了错误的暗示:Golang的GC执行虚拟地址空间碎片整理碎片预防策略,这使程序能够运行很长时间(如果不是永远的话)。但似乎C代码(cgo或SWIG)无法更新它的内存指针,以防它们被移动到别处。从这些策略中获益。这是真的吗?C代码不会受益于Golang的虚拟地址空间碎片整理碎片预防,最终得到碎片吗?如果那是假的,怎么办?此外,C代码加载的任何DLL代码(例如WindowsDLL)会怎样?(问题已