文章目录
2023.03第29次CCF-CSP计算机认证考试
CCF计算机软件能力认证考试系统
大二菜鸟第一次参加CSP考试,发挥得很烂(其实是实力太菜了 ),考前也没看往年题目套路,有很多不甘吧,不过拟打算六月再参加一次。如果早知道题目难度是依次递增的,就不写完两题就去啃最后一题了,最后写第三题的时候都在赶,最后一题还没啃下多少分…
话不多说,接下来分享我的思路。


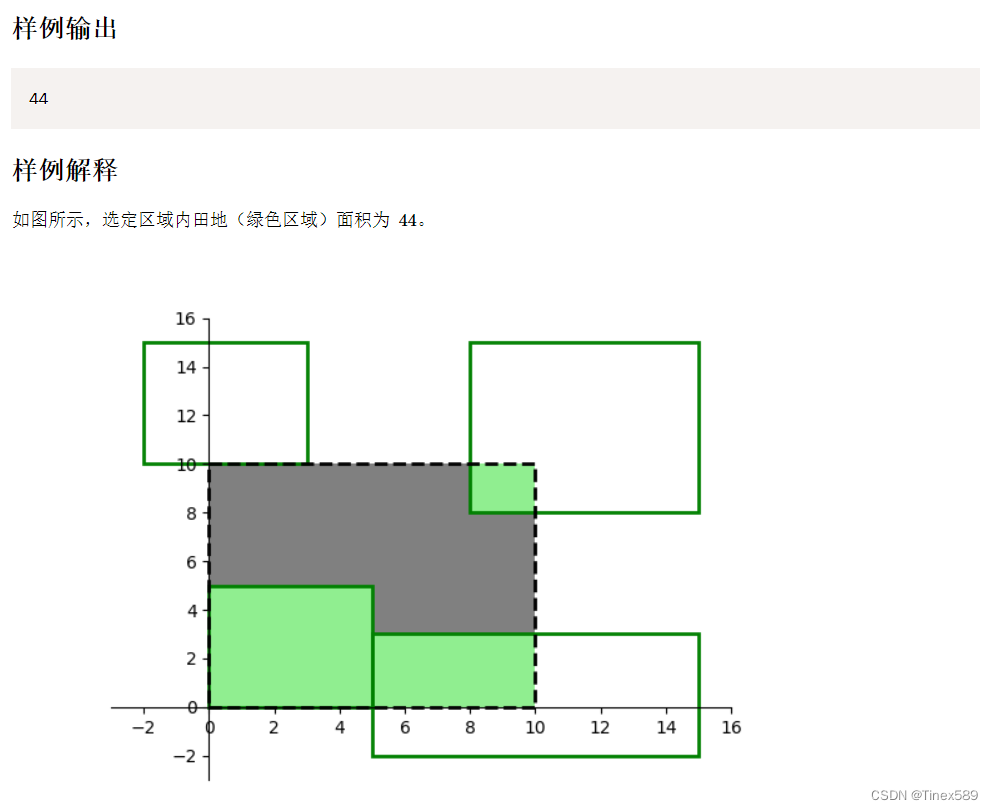

在坐标轴上给定你一个矩形,再给若干个矩形(这些矩形之间无重合部分),算出这些矩形与你的矩形的重合部分面积总和为多少。
枚举出矩形在不同情况下的不同计算方法,如在边上、被包含的情况等等,时间复杂度为O(n)。这种方法的好处在于几乎不用思考用什么算法,只需要注意边界条件。
不得不感谢出题人手下留情,给出了不会出现矩形多次覆盖同一区域的情况的条件,否则情况将会复杂一点。
思路图解:
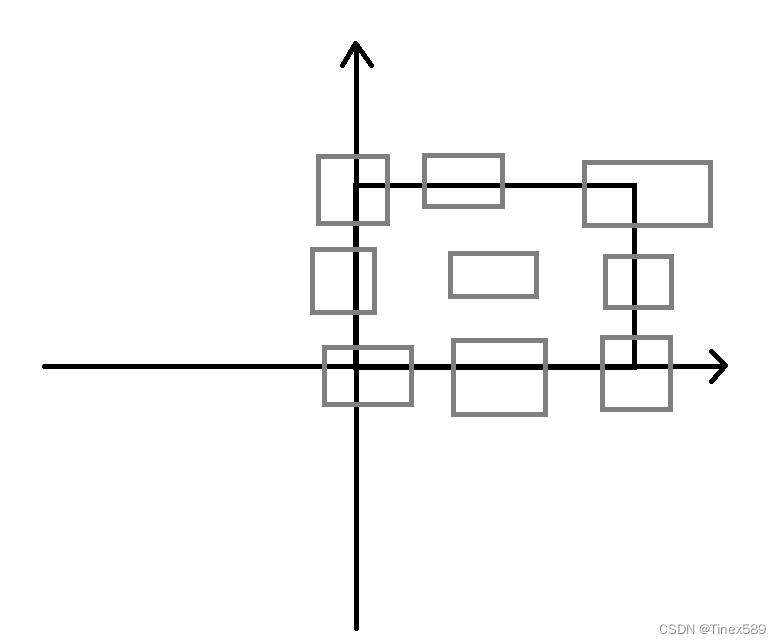
补充: 求重叠线段长度从而算出重叠面积的方法更为简便。
#include<bits/stdc++.h>
using namespace std;
int n, a, b;
long long ans;
int main()
{
int x1, x2, y1, y2;
scanf("%d%d%d", &n, &a, &b);
for(int i=0;i<n;i++)
{
scanf("%d%d%d%d",&x1,&y1,&x2,&y2);
if(x1>=0&&y1>=0&&x2<=a&&y2<=b)
ans+=(x2-x1)*(y2-y1);
else if(x1<0&&x2>0&&y1<b&&y2>b)
ans+=(b-y1)*x2;
else if(x1<a&&a<x2&&y1<b&&b<y2)
ans+=(b-y1)*(a-x1);
else if(x1<0&&0<x2&&y1<0&&0<y2)
ans+=x2*y2;
else if(x1<a&&a<x2&&y1<0&&0<y2)
ans+=(a-x1)*y2;
else if(x1>=0&&x2<=a&&y1<b&&y2>b)
ans+=(x2-x1)*(b-y1);
else if(x1<a&&x2>a&&y1>=0&&y2<=b)
ans+=(y2-y1)*(a-x1);
else if(x1>=0&&x2<=a&&y1<0&&y2>0)
ans+=(x2-x1)*y2;
else if(y1>=0&&y2<=b&&x1<0&&x2>0)
ans+=(y2-y1)*x2;
}
printf("%lld",ans);
return 0;
}
评测结果



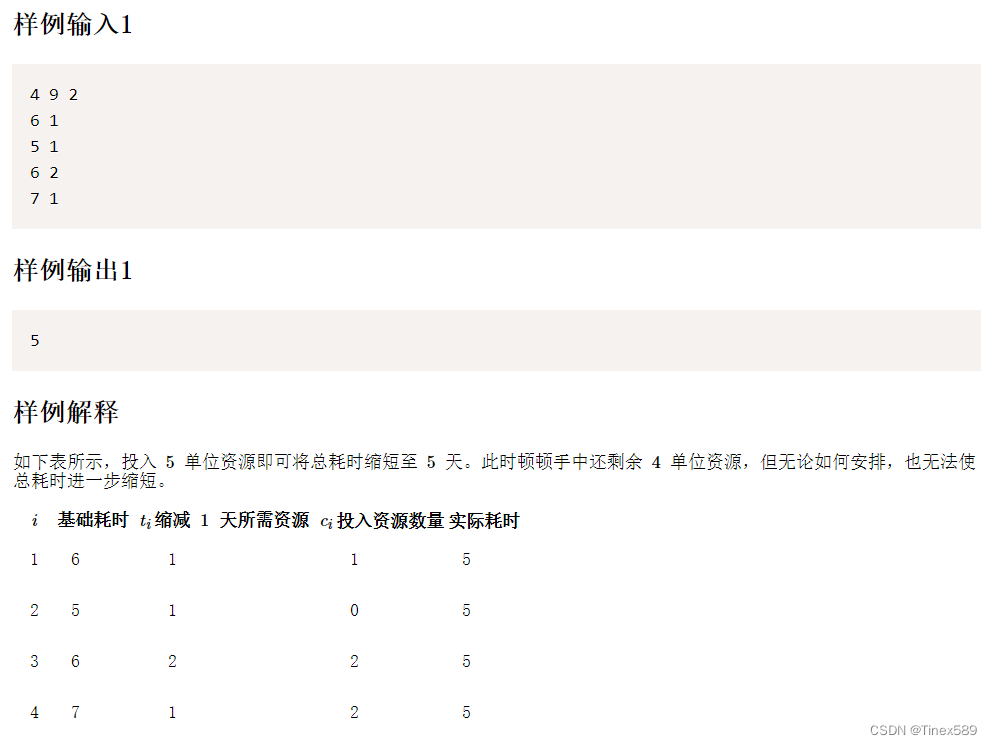

有几块田,耕完需要的时间都不同,花的资源也不同,但是所有田可以同时耕。用资源能缩短耕田的天数,但是最少不能小于k天。需要思考如何分配资源使总天数最少。
听一些大佬说是二分题。但是我没有这样做,提供一下我当时的思路。
这题让我想起木桶盛水的故事,“由长短不一的木板造出的木桶能盛多少水取决于最短的那块木板”。不过这题是反过来的,花费的总时间取决于最多天数的田,最多天数的田不变的情况下,就算分配所有资源给后面的田,需要的总时间也不变。于是我们考虑贪心法:每次分配资源给最大天数的田。
接下来,还需要考虑一个问题。如果存在若干个天数相同的田,只减少其中若干片田的时间,总时间仍不变。就是说,要使这种情况下的天数有效减少,必须同时削减所有相同天数的田,而且需要减少相同时间,使它们步伐保持一致,所以我们可以考虑合并方法,把所有具有相同天数的田所需的资源合并在一起,视为一块田。同时,在计算中削减某块田的天数后也要进行合并。
基于此,我想到了使用STL库的map。将键值对设置为<天数,所需资源>,方便将相同的天数合并它们的资源。另外,map具有自动对key进行排序的特点,正好满足我们对天数进行贪心的需求。需要注意map默认对key降序排列,所以要加greater。
map<ll,ll,greater<ll>>land;//按天数降序
在map的begin位置的是天数最大的田,要做的是将它与天数第二大的田合并资源,合并后,删除该键值对。循环执行,直到资源不够了或者所有天数都为k时结束。
m-=cost;
it1->second+=it->second;
land.erase(it->first);
还有一种情况,资源不够合并了。这时算算当前资源还能减多少天,算出来直接输出,程序结束。
ans=it->first;
while(m>=it->second)
{
m-=it->second;
ans--;
}
printf("%lld",ans);
break;
需要注意,无论是否存在天数为k的田,都需要加入key为k的键值对,以保证每次都能取出两个键值对进行合并。
land[k]+=0;//最少天数,保证每次能有两个合并
时间复杂度分析:需要分两种情况:
1.所有都能减少到k天,外层循环为O(n),即总共扫过一遍表;map.erase操作复杂度为O(logn),总共为O(nlogn)。
2.资源不够,设当前位置田在原来排第m位,则已进行mlogm次运算,内层循环不超过1e5-k次,复杂度为O(mlogm+1e5-k)。
由于m<=n,所以两种情况复杂度相差不大。
可以优化: 在每次合并操作之后让迭代器往后移一位(注意跳出循环条件和迭代器赋值需要些许改动),省去了erase,复杂度为O(n)。不过这题数据量不大,O(nlogn)和O(n)都行(map重度依赖 )。
补充:又回来补了个二分法,就当练手
这题的二分主要坑点在于多数情况下是不能直接搜到答案的(资源不能恰好分完),而是直接循环到low>high,最后停止处落在答案左侧或右侧,但一定经过答案。另外,从最小天数k到田的最大天数都是我们的搜索范围,low应该初始化为k。
对于如何找到答案,我们每次得到预测天数mid时,计算大于mid天的田全部减到mid天需要多少资源,此时有三种情况,我们用不同的返回值:
0——刚好用完,直接得出答案;
-1——资源不够;
1——资源盈余。
用这样的函数实现:
int dcs(int day)
{
int sum=0;
for(int i=n-1;land[i].first>day&&i>=0;i--)
sum+=land[i].second*(land[i].first-day);
if(m==sum) return 0;//资源刚好
else if(m<sum) return -1;//不够资源
else return 1;//资源盈余
}
在二分查找中调用这个函数,同时对返回值进行处理。最终答案如果不能恰好分配,那答案一定是在资源有盈余的情况下得出来的,所以我们用最小天数mind维护返回值为1的情况,查找结束后mind即为答案。
while(low<=high)
{
mid=(low+high)>>1;
if(dcs(mid)==0) break;
else if(dcs(mid)==1) {mind=min(mind,mid);high=mid-1;}
else low=mid+1;
}
return mind;
贪心:
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
ll n,m,k;
ll ans=-1;
map<ll,ll,greater<ll>>land;//按天数降序
int main()
{
scanf("%lld%lld%lld",&n,&m,&k);
for(int i=0;i<n;i++)
{
ll t,c;
scanf("%lld%lld",&t,&c);
land[t]+=c;
}
land[k]+=0;//最少天数,保证每次能有两个合并
map<ll,ll,greater<ll>>::iterator it=land.begin();
while(m>=it->second&&it->first>k)//资源还够减少天数,且不是全部都为最小天数
{
map<ll,ll,greater<ll>>::iterator it1=it;
it1++;
ll cost=((it->first-it1->first)*it->second);
if(m-cost<0)//不够减
{
ans=it->first;
while(m>=it->second)
{
m-=it->second;
ans--;
}
printf("%lld",ans);
break;
}
else//足够合并
{
m-=cost;
it1->second+=it->second;
land.erase(it->first);
}
it=land.begin();
}
if(ans==-1)//其实这已经说明能全部减到最小天数了
printf("%lld",it->first);
return 0;
}
评测结果(贪心)

二分:
#include<bits/stdc++.h>
using namespace std;
const int MAX_N=1e5+10;
typedef pair<int,int>pit;
int n,m,k;
pit land[MAX_N];
bool cmp(pit p1,pit p2){return p1.first<p2.first;}
int dcs(int day)
{
int sum=0;
for(int i=n-1;land[i].first>day&&i>=0;i--)
sum+=land[i].second*(land[i].first-day);
if(m==sum) return 0;//资源刚好
else if(m<sum) return -1;//不够资源
else return 1;//资源盈余
}
int binsrch()
{
int mind=1e6;
int low=k,high=land[n-1].first,mid;//mid为;
while(low<=high)
{
mid=(low+high)>>1;
if(dcs(mid)==0) break;
else if(dcs(mid)==1) {mind=min(mind,mid);high=mid-1;}
else low=mid+1;
}
return mind;
}
int main()
{
scanf("%d%d%d",&n,&m,&k);
for(int i=0;i<n;i++)
{
int t,c;
scanf("%d%d",&land[i].first,&land[i].second);
}
sort(land,land+n,cmp);
printf("%d",binsrch());
return 0;
}
评测结果(二分)






给定用户的编号和他们各自的属性名称和属性值,再给出满足题目规定的表达式的用户:
a:b——有属性a且值为b的用户集合
a~b——有属性a且值不为b的用户集合
&(a :/~ b)(c :/~ d)——先分别求括号内的用户集合,再求集合交
|(a :/~ b)(c :/~ d)——先分别求括号内的用户集合,再求集合并
这是一道模拟。数据有原子表达式、简单表达式和嵌套表达式三种。只要求拿70分的话很简单,表达式第一个字符为数字的是原子表达式,第三个字符为数字的是简单表达式。要拿到满分我们需要面对类似“&(&(3:1)(|(1:2)(2:3)))(|(&(2~5)(2~7))(2:5))”这样的字符串。
首先要做的就是解析字符串。因为怕递归可能会超时所以我这里提供一种迭代的方法(菜! 后面知道递归方法也可以解决)。逆向思维从右往左,维护一个集合栈,遇到数字则说明是原子式,立即计算,算完入栈。同一括号内,遇到“&”“|”符号就取栈顶的两个集合进行交并,运算结果再入栈,可以保证我们的运算顺序是对的(因为这两个符号和它的两个表达式相邻)。此时,表达式中的括号成为了无效字符,可以跳过。
处理字符串,我们从len-1往前搜索,每次开始前先跳过括号,如果遇到了数字,则说明接下来要处理一个原子式了,设立一个左标记把它提取出来送到base_expr函数处理,然后更新游标。如果是操作符,则需要进行集合的交并运算。
for(int r=len-1;r>=0;r--)
{
while(str[r]==')'||str[r]=='(')r--;
if(isdigit(str[r]))
{
int l=r-1;
while(l>=0&&(isdigit(str[l])||str[l]==':'||str[l]=='~'))l--;
base_expr(&str[l+1],&str[r+1]);
r=l-1;
}
//集合的交和并
if(r>=0&&str[r]=='&')
its();
else if(r>=0&&str[r]=='|')
uni();
}
因为设计到集合交并,所以使用求集合交并方便且快的bitset。每次从栈中取两个,算完再入栈。
集合的交和并:
inline void its()//交运算
{
bs b1=ss.top();
ss.pop();
b1=b1&ss.top();
ss.pop();
ss.push(b1);
}
inline void uni()//并运算
{
bs b1=ss.top();
ss.pop();
b1=b1|ss.top();
ss.pop();
ss.push(b1);
}
bitset按位表示。第m位为1,则说明集合中有编号m的用户。要使用bitset直接表示max=1e9的DN显然不合理,但是用户数量最多为2500,所以可以使用哈希用数组dnlist下标来映射DN(对应的其他DN编号也换成下标)。
用一个类型为pair二维数组lib表示用户的属性,下标和dnlist一一对应。当求断言时,在lib中找有该属性且为指定值的用户,修改bitset。但是仅仅这样我们无法求反断言式,所以要unordered_map一个属性和用户集合,表示有该属性的用户有哪些,然后我们可以在这些用户里面查找指定pair,断言时查找成功,反断言时查找失败(有该属性但不是指定值),说明满足条件,标记。
void asrt(int aname,int aval,char oper)//断言与反断言
{
bs b;
pit p(aname,aval);
if(oper==':')//断言
{
for(si it=ulib[aname].begin();it!=ulib[aname].end();it++)//获取有该属性的用户
{
if(binary_search(lib[*it].begin(),lib[*it].end(),p))
b.set(*it);
}
}
else//反断言
{
for(si it=ulib[aname].begin();it!=ulib[aname].end();it++)//获取有该属性的用户
{
if(!binary_search(lib[*it].begin(),lib[*it].end(),p))
b.set(*it);
}
}
ss.push(b);
}
最后就是提取bitset,按位映射回dnlist,内容存到ans数组,升序排序再输出。
#include<bits/stdc++.h>
using namespace std;
const int MAX_N=2510;
typedef pair<int,int> pit;
typedef set<int>::iterator si;
typedef set<int> sti;
typedef bitset<MAX_N> bs;
int n,m;
int dnlist[MAX_N];
int ans[MAX_N];
char str[2010];
vector<vector<pit>>lib;
unordered_map<int,sti>ulib;//键值对:<attname,set<DN>>
stack<bs>ss;//存每次运算结果
int mystoi(char *s,char *end)
{
int base=1,sum=0;
for(int i=end-s-1;i>=0;i--)
{
sum+=base*(s[i]-'0');
base*=10;
}
return sum;
}
inline void its()//交运算
{
bs b1=ss.top();
ss.pop();
b1=b1&ss.top();
ss.pop();
ss.push(b1);
}
inline void uni()//并运算
{
bs b1=ss.top();
ss.pop();
b1=b1|ss.top();
ss.pop();
ss.push(b1);
}
void asrt(int aname,int aval,char oper)//断言与反断言
{
bs b;
pit p(aname,aval);
if(oper==':')//断言
{
for(si it=ulib[aname].begin();it!=ulib[aname].end();it++)//获取有该属性的用户
{
if(binary_search(lib[*it].begin(),lib[*it].end(),p))
b.set(*it);
}
}
else//反断言
{
for(si it=ulib[aname].begin();it!=ulib[aname].end();it++)//获取有该属性的用户
{
if(!binary_search(lib[*it].begin(),lib[*it].end(),p))
b.set(*it);
}
}
ss.push(b);
}
void base_expr(char *expr,char *end)//解析原子表达式
{
int op=0;
while(expr[op]!=':'&&expr[op]!='~')op++;
int num1,num2;
num1=mystoi(expr,&expr[op]);
num2=mystoi(&expr[op+1],end);
asrt(num1,num2,expr[op]);
}
int main()
{
scanf("%d",&n);
lib.resize(n+1);
for(int i=1;i<=n;i++)//建表
{
int DN,attnum,attname,attv;
scanf("%d%d",&DN,&attnum);
dnlist[i]=DN;
lib[i].resize(attnum);
for(int j=0;j<attnum;j++)
{
scanf("%d%d",&attname,&attv);
lib[i][j]=pit(attname,attv);
ulib[attname].insert(i);
}
sort(lib[i].begin(),lib[i].end());
}
scanf("%d",&m);
for(int i=0;i<m;i++)
{
scanf("%s",str);
int len=strlen(str);
for(int r=len-1;r>=0;r--)
{
while(str[r]==')'||str[r]=='(')r--;
if(isdigit(str[r]))
{
int l=r-1;
while(l>=0&&(isdigit(str[l])||str[l]==':'||str[l]=='~'))l--;
base_expr(&str[l+1],&str[r+1]);
r=l-1;
}
//集合的交和并
if(r>=0&&str[r]=='&')
its();
else if(r>=0&&str[r]=='|')
uni();
}
if(!ss.empty())
{
int index=0;
bs ansbs=ss.top();
for(int i=1;i<=n;i++)
if(ansbs[i]==1)
ans[index++]=dnlist[i];
sort(ans,ans+index);
for(int i=0;i<index;i++)
printf("%d ",ans[i]);
}
printf("\n");
while(!ss.empty())ss.pop();
}
return 0;
}
评测结果(好险啊 )

后面可能还会分析历年的csp题目。实力实在有限,但在分析的过程中也学到了很多。
另外就是,都看到这里了,能不能给个小小的赞鼓励一下——
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
所有题目均有五种语言实现。C实现目录、C++实现目录、Python实现目录、Java实现目录、JavaScript实现目录题目n行m列的矩阵,每个位置上有一个元素你可以上下左右行走,代价是前后两个位置元素值差的绝对值.另外,你最多可以使用一次传送阵(只能从一个数跳到另外一个相同的数)求从走上角走到右下角最少需要多少时间。输入描述:第一行两个整数n,m,分别代表矩阵的行和列。后面n行,每行m个整数,分别代表矩阵中的元素。输出描述:一个整数,表示最少需要多少时间。
我正在运行:ruby1.9.3p0,rails3.1.1,设计1.4.9,Devise_ldap_authenticatable0.4.10我正在使用Devise通过ldap服务器验证我的Rails应用程序。我使用用户名而不是电子邮件进行身份验证,所以我表中的电子邮件字段自然是空白的。在ldap中查询email,官方的做法是在用户模型中加入这段代码:before_save:get_ldap_emaildefget_ldap_emailself.email=Devise::LdapAdapter.get_ldap_param(self.username,"mail")end这段代码失败了
昨晚看到IDEA官推宣布IntelliJIDEA2023.1正式发布了。简单看了一下,发现这次的新版本包含了许多改进,进一步优化了用户体验,提高了便捷性。至于是否升级最新版本完全是个人意愿,如果觉得新版本没有让自己感兴趣的改进,完全就不用升级,影响不大。软件的版本迭代非常正常,正确看待即可,不持续改进就会慢慢被淘汰!根据官方介绍:IntelliJIDEA2023.1针对新的用户界面进行了大量重构,这些改进都是基于收到的宝贵反馈而实现的。官方还实施了性能增强措施,使得Maven导入更快,并且在打开项目时IDE功能更早地可用。由于后台提交检查,新版本提供了简化的提交流程。IntelliJIDEA
集成背景我们当前集群使用的是ClouderaCDP,Flink版本为ClouderaVersion1.14,整体Flink安装目录以及配置文件结构与社区版本有较大出入。直接根据Streampark官方文档进行部署,将无法配置FlinkHome,以及后续整体Flink任务提交到集群中,因此需要进行针对化适配集成,在满足使用需求上,尽量提供完整的Streampark使用体验。集成步骤版本匹配问题解决首先解决无法识别Cloudera中的FlinkHome问题,根据报错主要明确到的事情是无法读取到Flink版本、lib下面的jar包名称无法匹配。修改对象:修改源码:(解决无法匹配clouderajar
目录1. 研究范围定义2. 流程中台市场分析3. 厂商评估:微宏科技4. 入选证书 1. 研究范围定义近年来,随着外部市场环境快速变化、客户需求愈发多样,企业逐渐意识到,自身业务需要更加敏捷、高效,具备根据市场需求快速迭代的能力。业务流程的自动化能够帮助企业实现业务的敏捷高效,因此受到越来越多企业的关注。企业的“自动化武器库”品类丰富,包括低/零代码平台、RPA、BPM、AI等。企业可以使用多项自动化工具,但结果往往是各项自动化工具处于各自的“自动化烟囱”之中,仅能实现碎片式自动化。例如,某企业的IT团队可能在使用低代码平台、财务团队可能在使用RPA、呼叫中心则可能在使用聊天机器人。自动
自从2019年OpenApplicationModel诞生以来,KubeVela已经经历了几十个版本的变化,并向现代应用程序交付先进功能的方向不断发展。最近,KubeVela完成了向CNCF孵化项目的晋升,标志着社区的发展来到一个新的里程碑。今天,KubeVela社区内活跃着大量来自全球的开发者,共同推动KubeVela项目的落地和发展。在即将开幕的KubeCon+CloudNatvieConEurope2023上,我们惊喜地发现,连续3天,KubeVela项目的贡献者、企业用户和来自阿里云的核心维护者,将从不同角度展对KubeVela项目的分享。让我们先睹为快!🎙️BuildingaPlat
我正在开发一个内部Rails应用程序,这是一个(除其他外)CRM应用程序,因此它包含客户和其他联系人的姓名、地址等。一个巧妙的功能是允许客户端(例如电子邮件程序和地址簿应用程序)获取/搜索这些联系人(即只是简单的只读访问)。我的想法是为此使用LDAP或CardDAV,但我无法获得有关如何实现它的太多(最近)信息。对于CardDAV,我基本上什么都没发现。对于LDAP,我发现了大量LDAP客户端gem和插件,但只有少数LDAP服务器实现。到目前为止我发现的是theplainRubyLDAPserver和LDAP-ActiveRecord-gateway,它建立在前者之上。后者听起来很合适
我想知道其他人是如何实现这个场景的。我有一个内部Rails应用程序(库存管理、标签打印、运输等)。我正在重写系统的安全性,导致旧方法变得难以维护(用户表、密码、角色)——我使用了restful_authentication和角色。它是大约3年前实现的。我已经使用ruby-ldap-net实现了AuthLogic来对用户进行身份验证(与我之前与其他框架/语言的挣扎相比,实际上这非常容易)。下一步是角色。我已经在ActiveDirectory中定义了组——所以我不想在我的Rails应用程序中运行一个单独的角色系统,我只想重用ActiveDirectory组——因为系统的那一部分已经被维