林顺利,腾讯云原生产品经理,负责分布式云产品迭代和注册节点客户扩展,专注于云原生混合云新形态的推广实践。
企业在持续业务运维过程中,感受到腾讯云 TKE 带来的便捷性和极致的使用体验,将新业务的发布以及老业务都迁移到云上 TKE 来实现。但很多企业数据中心建设较为早期,选型上采取了自建 IDC 机房的方案,长久以来的 IDC 运营维护和企业上云的诉求产生了冲突和矛盾
1、资源难利旧/利用率低
2、运维成本高
3、难以统一调度
如何解决企业 IDC 和上云的冲突问题?这似乎在过去已经有了答案 - 混合云部署。但是当下,我们面临的是云原生的新场景而非单纯的上云,因此,我们基于传统混合云的解决方案进一步深入思考,首创出 IDC 轻量级云原生解决方案 - 注册节点 :IDC 节点和 TKE 打通,云上作为管控面来提供管理、调度、监控能力,云下 IDC 作为支撑面来实际承载业务运行。在满足企业资源利旧、托管运维、混合部署/调度等云化场景的同时,将云上关于降本增效的核心特性下沉到 IDC 节点实现无缝集成,进一步促进了 IDC 节点资源的有效、高效利用。

TKE 注册节点的核心特性
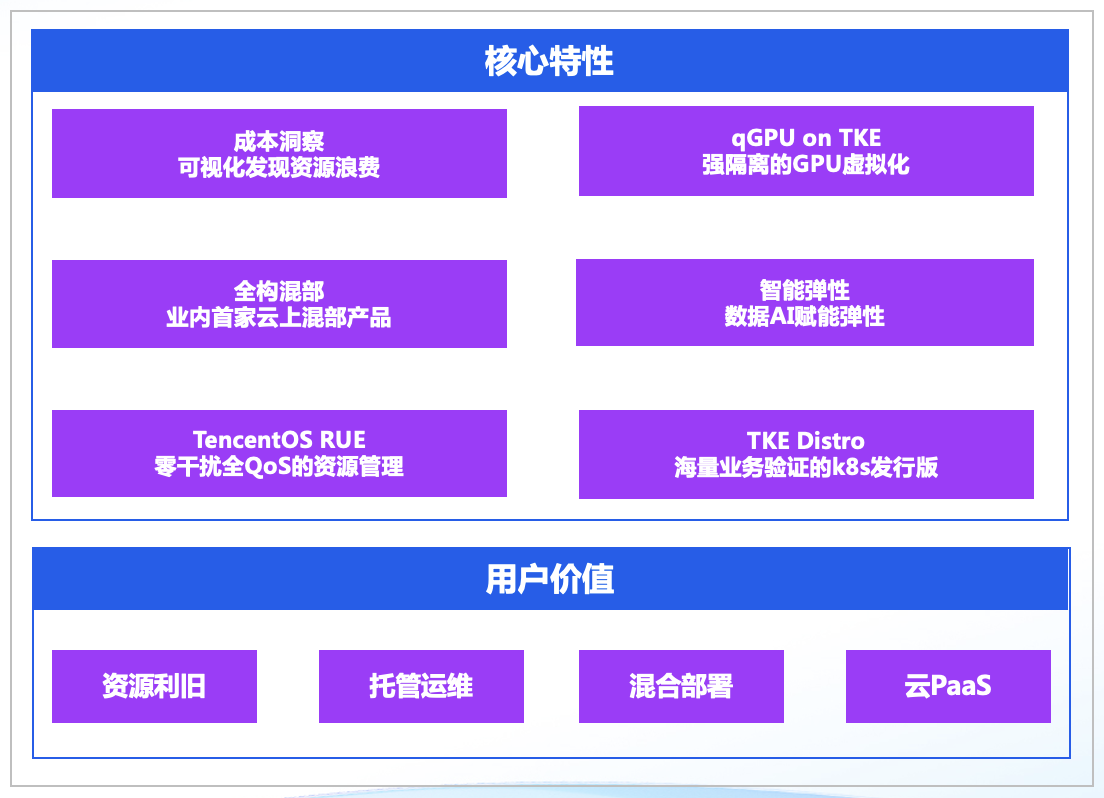
注册节点已经支持腾讯上万台 IDC 节点,CPU 累计超过500w核,成为 IDC 节点轻量上云新范式。在上云同时,平台侧借助云原生资产大盘的资源监控和 crane 的专有调度能力,提升了 IDC 节点的资源利用率,节点资源平均水位值由 15% 迁越至 50%。
TKE 注册节点是针对混合云部署场景,全新升级的节点产品形态,解决了企业在 IDC 运维过程中面临的各类问题:
资源利旧和利用率提升
充分利用 IDC 资源,并通过 Request 推荐、动态调度、节点超卖等能力进一步提升 IDC 资源的利用率。同时针对于 GPU 资源使用,提供厘核级算力隔离与多优先级混部。
节点托管运维
免去在本地搭建、运维 k8s 集群的成本,无缝集成腾讯云云原生相关服务,涵盖日志、监控、审计、存储、容器安全等能力,用户仅需要运维本地服务器即可,并提供节点声明式运维的能力,支持节点快速升级及回滚。
云上云下统一调度
支持在单集群内同时调度本地节点与云上 CVM 节点,便于将云下业务拓展至云上,同时无需引入多集群管理。
IDC 注册节点托管至云上,作为 TKE 的worker节点承载业务,天然实现了资源利旧;控制面在云上 TKE,集群组件的运维、升级、持续运营都由 TKE 自动化实现。
基于 Crane 的专有调度器提供了节点超卖的能力,用户可以自主配置节点的放大系数,业务动态调度至放大节点上,提升了节点的装箱率并进一步提升了节点的利用率。
云上节点和注册节点通过不同的节点池来进行管理,业务资源调度时可指定节点池和节点类型,可以实现云上云下相互弹性。
企业 IDC 中存在各类急需有效利旧的服务器节点,包括 闲置节点、老旧节点、退保节点等,这些节点面临诸多问题:
通过注册节点的方案,企业在极短时间内就能够完成 IDC 节点接入 TKE 的动作(单节点10min内接入),使用 TKE 服务。并且,进一步
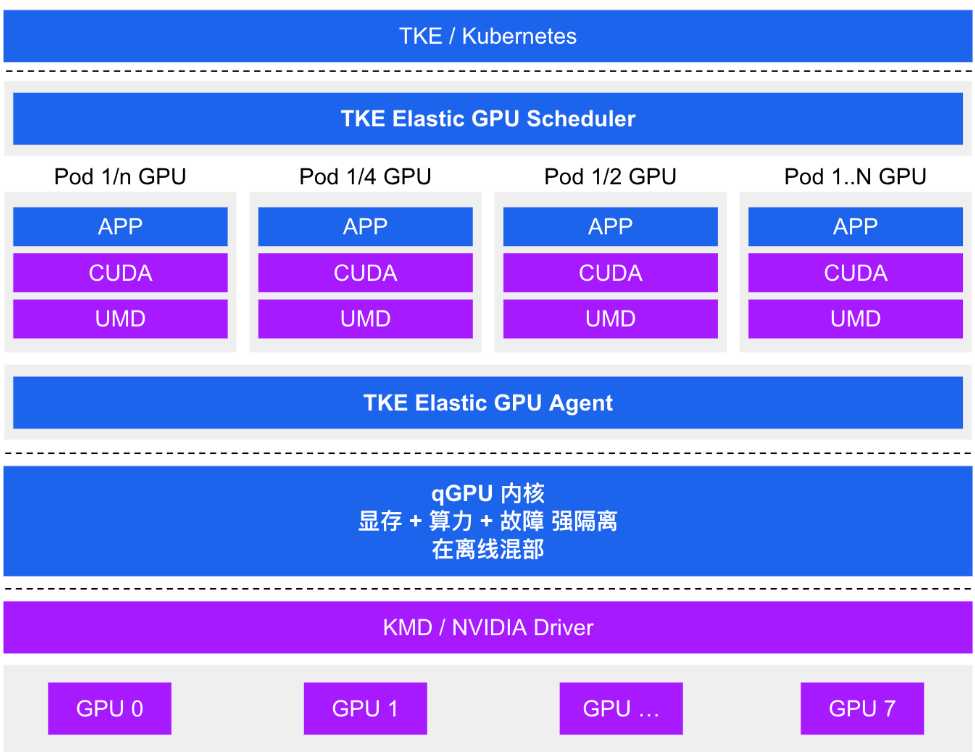
当用户业务 pod 需要使用 GPU 资源且使用量较低甚至不满1卡时,如果采用 Kubernetes 原生的GPU 配额机制会造成资源浪费。
注册节点无缝集成了腾讯云 qGPU 技术,支持在多个容器间共享 GPU 卡并提供容器间显存与算力强隔离的能力,从而在更小粒度使用 GPU 卡的基础上,保证业务安全,达到提高 GPU 使用率、降低用户成本的目的。依赖底层强大的 qGPU 隔离技术,可做到 GPU 显存和算力的强隔离,共享使用 GPU 的同时,保证业务性能与资源不受干扰。
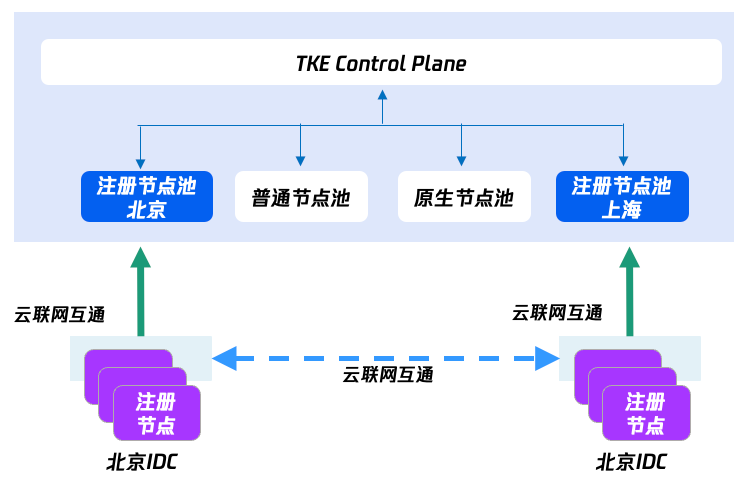
用户在不同地域中都有存量的 IDC 机房场景下,想要实现统一的资源管理难度非常大,每个地域新建管理平面和业务发布流程增加了运维日常工作复杂度。
注册节点方案可以帮助用户将不同地域的 IDC 注册到同一个 TKE 集群中进行统一的管理运维,统一了管控入口,降低了运维的复杂度。
负载+高可用的多集群、多套方案的运维成本高,而公有云和 IDC 资源的隔离性,天然适合用来企业落地业务的容灾场景,用户急需探寻如何通过云上云下实现容灾调度的需求。
注册节点方案中,业务可以自定义调度模式,用户可以自主选择将服务调度至云上还是云下,云上云下相互弹性,满足单集群容灾场景。

- IDC 节点操作系统:tencent os 2.4、3.1 ;
- TKE 标准集群:版本 v1.18及以上;网络插件类型为 cillium overlay;
- 网络打通:IDC 和 TKE 专线打通;
TKE标准集群,进入集群详情页 > 选择左侧菜单栏中的节点管理 > 节点池 > 点击新建节点池,选择注册节点池并填写对应参数提交。
节点池创建完成后进入节点池 > 点击新增节点,复制命令并到IDC主机上执行即可。
腾讯云TKE中提供了3种节点运维的新范式:
3种节点类型分别面向客户不同的业务场景,TKE实现了一个集群中同时纳管这3种节点新范式和TKE普通节点的统一管理、调度方案。这也是腾讯云原生一贯的科技与人文观念,用融合的形态帮助客户解决各类业务支撑的问题、持续关注降低用户的运维成本。
我们希望通过企业渐进式上云最佳方案注册节点,最低成本的实现 IDC 业务原地云原生,用户可以便捷的、分钟级的获得云上云原生的能力,实现降本增效。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
如何使此根路径转到:“/dashboard”而不仅仅是http://example.com?root:to=>'dashboard#index',:constraints=>lambda{|req|!req.session[:user_id].blank?} 最佳答案 您可以通过以下方式实现:root:to=>redirect('/dashboard')match'/dashboard',:to=>"dashboard#index",:constraints=>lambda{|req|!req.session[:user_id].b
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
我需要根据字符串路径的长度将字符串路径数组转换为符号、哈希和数组的数组给定以下数组:array=["info","services","about/company","about/history/part1","about/history/part2"]我想生成以下输出,对不同级别进行分组,根据级别的结构混合使用符号和对象。产生以下输出:[:info,:services,about:[:company,history:[:part1,:part2]]]#altsyntax[:info,:services,{:about=>[:company,{:history=>[:part1,:pa
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我在我的项目中有一个用户和一个管理员角色。我使用Devise创建了身份验证。在我的管理员角色中,我没有任何确认。在我的用户模型中,我有以下内容:devise:database_authenticatable,:confirmable,:recoverable,:rememberable,:trackable,:validatable,:timeoutable,:registerable#Setupaccessible(orprotected)attributesforyourmodelattr_accessible:email,:username,:prename,:surname,:
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
我似乎经常遇到一些设计问题,但我不知道是什么是真的很合适。一方面我经常听到我应该限制耦合和坚持单一职责,但当我这样做时,我常常发现它很困难到在需要时将信息获取到程序的一部分。为了例如,classSingerdefinitialize(name)@name=nameendattr:nameend那么Song应该是:classSongdefnew(singer)@singer=singerendend或classSongdefnew(singer_name)@singer_name=singer_nameendend后者耦合性小,按道理应该用。但如果我以后发现宋有什么需要了解更多歌手,我的
Organization和Image具有一对一的关系。Image有一个名为filename的列,它存储文件的路径。我在Assets管道中包含这样一个文件:app/assets/other/image.jpg。播种时如何包含此文件的路径?我已经在我的种子文件中尝试过:@organization=...@organization.image.create!(filename:File.open('app/assets/other/image.jpg'))#Ialsotried:#@organization.image.create!(filename:'app/assets/other/i