文章目录
工作中每天都会和excel打交道,遇到最多的文件格式是xlsx格式和csv格式。如果通过人工处理excel一些重复操作,不仅耗时而且容易出错,通过脚本的方式可以节省很多时间,而且可以重复利用。日常工作中用到最多的是使用几个库对文档进行读写的操作,对于写xlwt是创建一个新的workbook存储被写入的数据,openpyxl是可以基于已有的workbook进行修改。下面是工作中常用的脚本总结:

import csv
"""读取csv文件数据,保存在一个list里面,list里面是字典,key是表头,value是值"""
file = r'E:\test\test.csv'
list_data = []
with open(file, 'r', newline='', encoding='utf-8') as csvFile:
reader = list(csv.reader(csvFile))
data_title=reader[0]
for i in range(1,len(reader)):
data_value=reader[i]
list_data.append(dict(zip(data_title,data_value)))
print(list_data)
list_title = ['a', 'b', 'c']
list_data = [['1', '2', '3'], [4, 5, 6]]
file_path = r'E:\test\test.csv'
with open(file_path, 'w', newline='') as csv_file:
csv_writer = csv.writer(csv_file)
# 写表头
csv_writer.writerow(list_title)
# 写表格的除了表头的数据
for list_item in list_data:
csv_writer.writerow(list_item)
file_path = r'E:\test\test.xlsx'
sheet_name = 'Sheet1'
sheet_obj = openpyxl.load_workbook(file_path).get_sheet_by_name(sheet_name)
nrows = sheet_obj.max_row
ncols = sheet_obj.max_column
key_list = []
final_list = []
for i in range(1, ncols + 1):
# 获取第一行表头的数据
key_list.append((sheet_obj.cell(1, i).value).lower())
for i in range(2, nrows + 1):
value_list = []
for j in range(1, ncols + 1):
# 获取除了表头的其他行的数据
value_item = sheet_obj.cell(i, j).value
value_list.append(value_item)
# 表头的数据和其他行的数据合并成字典
list_dict = dict(zip(key_list, value_list))
# 将字典放到数组中
final_list.append(list_dict)
print(final_list)
new_case_book = openpyxl.Workbook()
new_sheet = new_case_book.create_sheet('test')
excel_title = ['a', 'b', 'c']
# 写入表头的数据
new_sheet.append(excel_title)
list_result = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# 写入其他行需要的数据
for i in list_result:
new_sheet.append(i)
max_column = new_sheet.max_column
max_row = new_sheet.max_row
# 设置表格的格式
for i in range(1, max_column + 1):
column = get_column_letter(i)
# 设置列宽
new_sheet.column_dimensions[column].width = 30
for j in range(1, max_row + 1):
# 设置单元格字符格式
new_sheet[f'{column}{j}'].font = Font(name='Microsoft Tai Le')
# 设置单元格对齐
new_sheet[f'{column}{j}'].alignment = Alignment(wrap_text=True, horizontal='left', vertical='top')
new_case_book.save(file_path)
修改xlsx文件,使用openpyxl load_workbook后,直接赋予值给指定的单元格即可,如:
new_sheet[A1]='Dazhuang'
有一份用例id和测试数据关联的文档和一份用例id和用例描述等其他信息关联的文档,现在想把两份文档合并,考虑到有共同的用例id,可以先将用例文档复制一份,用于编辑,测试数据文档通过用例id与用例相关联,将测试数据写在最后一列,详细示例和代码如下:
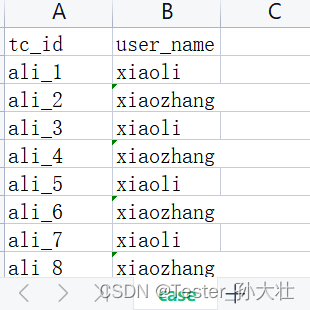
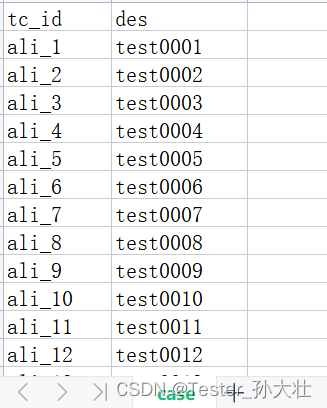
想到使用xlrd和xlutils.copy处理,生成新的文件,代码如下:
import xlrd
from xlutils.copy import copy
if __name__ == '__main__':
# 取文件和保存文件的路径
cases = r'E:\test\xlutils\test_cases.xls'
users = r'E:\test\xlutils\tc_user.xls'
new_case = r'E:\test\xlutils\case_new.xls'
# xlrd获取原始的workbook对象,并创建副本,xlsx用openpyxl打开
case_book = xlrd.open_workbook(cases)
new_case_book = copy(case_book)
# 打开对应的sheet页
case_sheet = case_book.sheet_by_name('case')
user_sheet = xlrd.open_workbook(users).sheet_by_index(0)
# 获取用例sheet页的行号和列号,如果通过openpyxl,则是max_row,max_column获取行数和列数
case_rows = case_sheet.nrows
case_cols = case_sheet.ncols
# 获取user sheet页的行号
user_rows = user_sheet.nrows
# 获取新的workbook的case页
new_case_sheet = new_case_book.get_sheet('case')
# 在新的workbook的sheet页创建user列,xlrd的第一行是0,openpyxl的第一行是1
new_case_sheet.write(0, case_cols, 'user')
for i in range(1, case_rows):
for j in range(1, user_rows):
# 匹配tc_id一致
if case_sheet.cell(i, 0).value == user_sheet.cell(j, 0).value:
# 写数据到user列
new_case_sheet.write(i, case_cols, user_sheet.cell(j, 1).value)
new_case_book.save(new_case)
最后效果图:
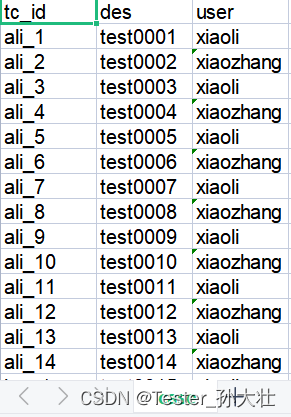
工作中可能测试用例分布在不同的sheet页,这时候手工分析测试数据,不太方便。
考虑用xlrd和openpyxl可以读取xls和xlsx,pandas直接获取sheet页中的特定列并将sheet页作为对象保存在DataFrame中,示例和详细代码如下。
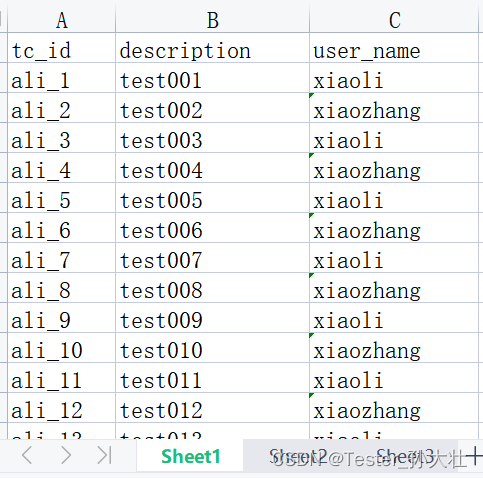
代码如下:
test_data = r'E:\test\test_case.xls'
data_results = r'E:\test\result.csv'
# 通过xlrd获取所有sheet,如果是xlsx文档可以通过openpyxl打开,worksheets方法获取所有sheet对象
# 也可以通过pandas操作
# 如下示例为通过pandas
# sheets = pandas.read_excel(test_data, sheet_name=None,engine='openpyxl')
sheets = xlrd.open_workbook(test_data).sheet_names()
# pandas创建一个data模板
all_data = pandas.DataFrame()
for i in sheets:
try:
# pandas提取模板中的数据,因为默认的引擎是xlrd,处理xlsx需要加参数engine='openpyxl'
df = pandas.read_excel(test_data, i, usecols=['tc_id', 'user_name'])
# 数据模板中添加测试数据
all_data = all_data.append(df)
except Exception:
print('sheet did not have according columns')
all_data.to_csv(data_results)
结果如下图:

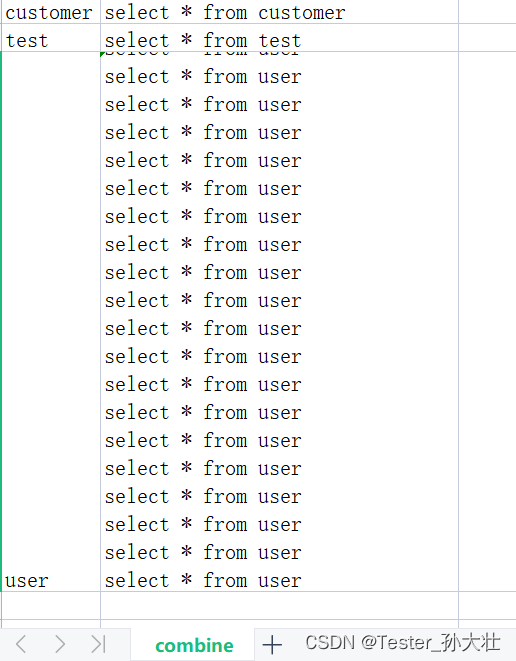
有一大堆sql文件(类似下图),每个sql文件都有不超过20条常用的sql语句,工作中如果单独去看每个文件,不太方便也不利于集中分析和管理,想到将文件集中保存在excel中,一开始想到用xlwt处理,无奈xlwt处理的时候报出如下异常 String longer than 32767 characters ,意思是长度超出了xlwt处理的限制,最后选用xlsxwriter处理,代码如下:

path = r'E:\test\db'
path_save = r'E:\test\db\combine.xls'
save_file = xlsxwriter.Workbook(path_save)
save_sheet = save_file.add_worksheet('combine')
files = os.listdir(path)
num = 0
for file in files:
#将文件名保存在第一列
save_sheet.write(num, 0, str.split(file, '.')[0])
#将文件内容保存在第二列
save_sheet.write(num, 1, open(path + '\\' + file).read())
num += 1
save_file.close()
处理效果类似于下图:
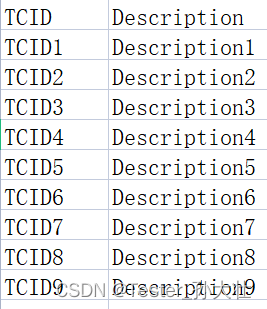
测试工作常常需要留下证据,excel管理是不错的选择,但是excel中的证据如果没有测试用例和描述等信息,看留下的证据往往是一头雾水,手中正好有一份测试用例文档,可以将用例ID作为sheet页的名称,用例描述等信息保存在sheet页中,使用xlrd进行读,xlwt进行写,示例和代码如下:
测试用例大概如下图:
代码如下:
import xlrd
import xlwt
if __name__ == '__main__':
# 测试用例的路径
tc_path = r'E:\test\testcase.xls'
# 生成测试evidence模板的路径
ev_path = r'E:\test\evidence.xls'
# 测试用例的sheetName
sheet_name = 'Sheet1'
# 测试用例需要生成测试模板的起始行
row_begin_index = 2
# 测试用例需要生成测试模板的终止行
row_end_index = 10
# 测试用例ID所在列
tc_id_col = 1
# 测试用例必要信息的起始列
col_begin_index = 2
# 测试用例必要信息的终止列
col_end_index = 3
# 生成文件的单元格格式
style = xlwt.easyxf('font:name Microsoft Tai Le,height 200;align: wrap on,vert centre,horiz left;')
# 新的excel book的实例对象
evidence_book = xlwt.Workbook()
# 新的excel的sheet对象
sheet_object = xlrd.open_workbook(tc_path).sheet_by_name(sheet_name)
# 通过xlrd读取测试用例excel,xlwt写入新的book中
for i in range(row_begin_index - 1, row_end_index):
# p=0用于i新的book中从第1列开始写数据
p = 0
new_sheet_name = sheet_object.cell(i, tc_id_col - 1).value
new_sheet = evidence_book.add_sheet(new_sheet_name, cell_overwrite_ok=True)
for j in range(col_begin_index - 1, col_end_index - 1):
new_sheet.write(0, p, sheet_object.cell(0, j).value, style)
new_sheet.write(1, p, sheet_object.cell(i, j).value, style)
# 列的宽度
new_sheet.col(p).width = 256 * 50
p += 1
evidence_book.save(ev_path)
处理后的效果如下:
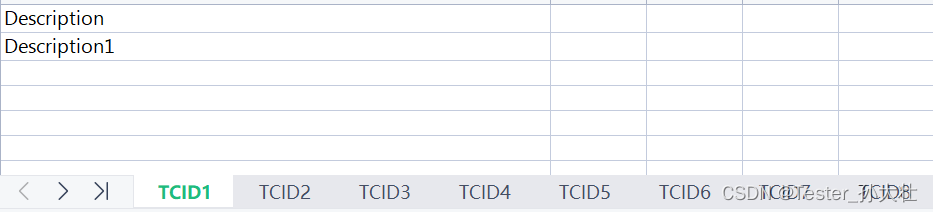
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty