每遇到一个问题,在经过努力研究明白之后,总想写点东西记录。怎奈又没这个好习惯,过了一两天这个激情就没了,想写也写不出来了。最近在做一个flink-cdc采集数据的测试和产品化开发,遇到一个数据转换的问题,折腾了我两个早上,有些心血来潮,就记录一下吧,对我是一种收获,也希望能帮到哪天像我一样遇到这个问题的同学
开始新建一张MySQL表:products
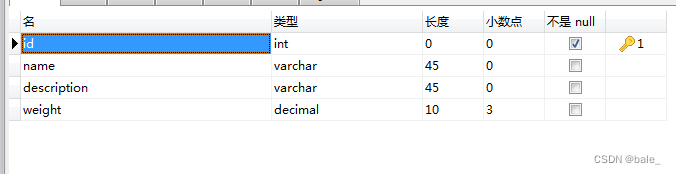
插入一些数据:

搬过来官网的示例代码
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("...")
.port(...)
.databaseList("...") // set captured database
.tableList("products") // set captured table
.username("...")
.password("...")
.deserializer(new JsonDebeziumDeserializationSchema())
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// set 4 parallel source tasks
.setParallelism(4)
.print().setParallelism(1); // use parallelism 1 for sink to keep message ordering
env.execute("Print MySQL Snapshot + Binlog");
}Run as 看打印结果,嗯? 怎么weight字段的值变这样了

开始上网查资料,各种搜索,居然找不到,这也是为什么想写篇文章记录一下的原因。
没办法,只能看源码,查了一下资料,各种自定义解码器的文章倒是挺多,但是看了一下官方提供的json解码器JsonDebeziumDeserializationSchema,那些自定义的都是一坨屎,明明有个很牛逼的不知道用好,还有人要重新自定义JSON解码器,然而又写的稀巴烂,还各种抄来抄去。
从JsonDebeziumDeserializationSchema类进去,经过多层方法调用最终看到将Object转成JSON的方法叫convertToJson
/**
* Convert this object, in the org.apache.kafka.connect.data format, into a JSON object, returning both the schema
* and the converted object.
*/
private JsonNode convertToJson(Schema schema, Object value) {
//源码略
}断点调试到这个方法中,可以看到有个LogicalTypeConverter不为空
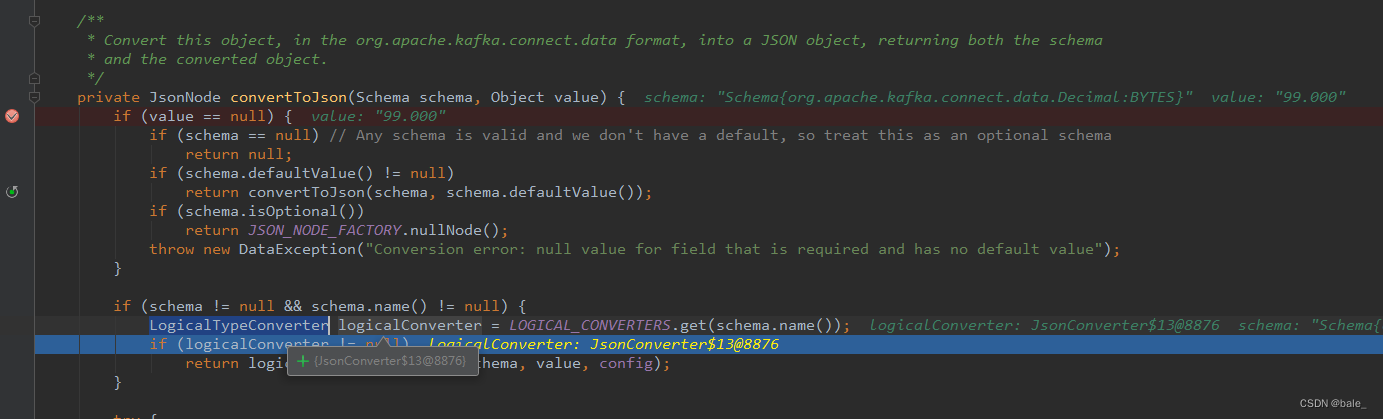
于是再进这个LOGICAL_CONVERTERS看一下 ,这里面单独定义了Decimal、Date、Time等类型的处理逻辑,其他简单类型的处理放在了TO_CONNECT_CONVERTERS中。继续断点调试可以看到Dicimal类型直接就进了BASE64的case
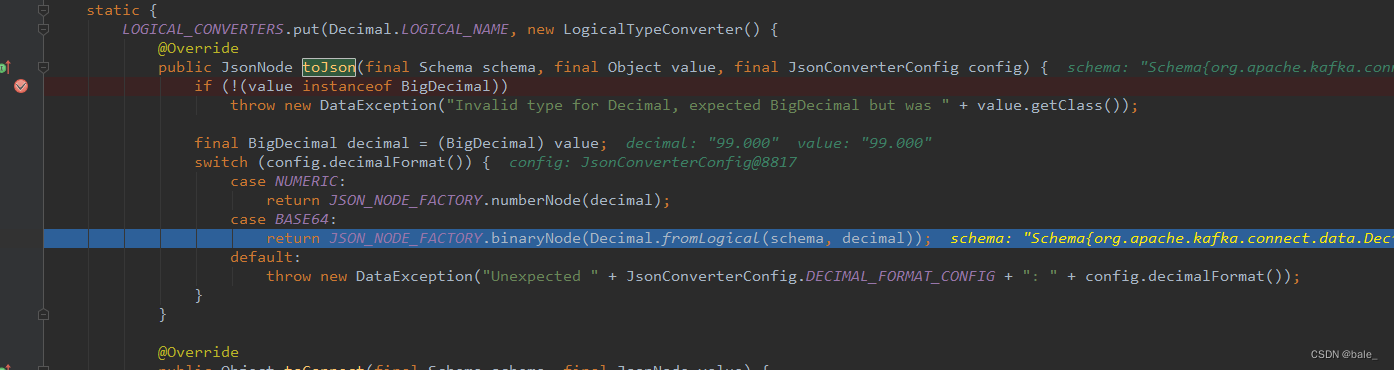
而这个类型是通过参数JsonConverterConfig传进来的,往回看,可以看到这个参数是解码器初始化的时候被实例化的,而且还接受了自定义参数customConverterConfigs
/** Initialize {@link JsonConverter} with given configs. */
private void initializeJsonConverter() {
jsonConverter = new JsonConverter();
final HashMap<String, Object> configs = new HashMap<>(2);
configs.put(ConverterConfig.TYPE_CONFIG, ConverterType.VALUE.getName());
configs.put(JsonConverterConfig.SCHEMAS_ENABLE_CONFIG, includeSchema);
if (customConverterConfigs != null) {
configs.putAll(customConverterConfigs);
}
jsonConverter.configure(configs);
}那么问题就好办了,指定Decimal的格式为NUMERIC不就可以了,于是自定义一个customConverterConfigs
public static void main(String[] args) throws Exception {
Map config = new HashMap();
config.put(JsonConverterConfig.DECIMAL_FORMAT_CONFIG, DecimalFormat.NUMERIC.name());
JsonDebeziumDeserializationSchema jdd = new JsonDebeziumDeserializationSchema(false, config);
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("...")
.port(...)
.databaseList("...") // set captured database
.tableList("products") // set captured table
.username("...")
.password("...")
.deserializer(jdd)
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// set 4 parallel source tasks
.setParallelism(4)
.print().setParallelism(1); // use parallelism 1 for sink to keep message ordering
env.execute("Print MySQL Snapshot + Binlog");
}在Run as 看打印结果,这下Happy了

可以看到已经变成想要的结果了。
后来进入产品化开发,打包到flink集群测试执行,采集oracle的时候总是同步不成功,同步成功了,也有一些字段的值变成空了,继续看了一下原表字段类型,才明白还是数值类型的问题,主键是number类型,同步之后类型还是被编码成BASE64,数仓的表是数字类型,不能插入。于是还得再测试验证一下,创建一张有各种number类型字段的表
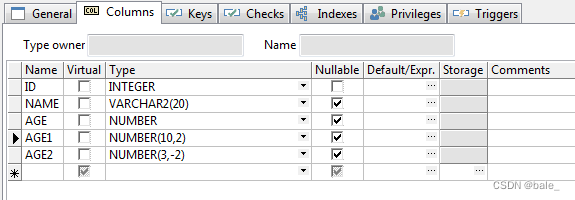
简单插入两条数据

读取方法
public static void main(String[] args) throws Exception {
Map config = new HashMap();
config.put(JsonConverterConfig.DECIMAL_FORMAT_CONFIG, DecimalFormat.NUMERIC.name());
JsonDebeziumDeserializationSchema jdd = new JsonDebeziumDeserializationSchema(false, config);
SourceFunction<String> sourceFunction = OracleSource.<String>builder()
.hostname("...")
.port(...)
.database("...") // monitor XE database
.schemaList("...") // monitor inventory schema
.tableList("...") // monitor products table
.username("...")
.password("...")
.deserializer(jdd) // converts SourceRecord to JSON String
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(sourceFunction)
.print()
.setParallelism(1)
; // use parallelism 1 for sink to keep message ordering
env.execute();
}看执行输出

更奇怪了,又去对JsonDebeziumDeserializationSchema一通研究,发现number类型,没设置p、s时,Flink-CDC读取的记录中就已经变成了Struct类型,通过解码器解决不了问题了。但是看到解码器可以通过设置includeSchema=true返回Schema,那是不是可以根据返回的Schema 的type判断是数值类型在取出value来Base64解码.....! 但是,类似这样想法的代码写法,在项目中实在是太多了,我不想也沦为这种垃圾代码的制造者。
继续查一下吧,是这个提问(请教大佬们,oracle cdc的NUMBER类型,打印出来为什么变成字符串了呢,怎么转换回去?-问答-阿里云开发者社区-阿里云)启发了我,虽然回答中那个参数试了一下无效,但是我找到了正确答案,后来还再次回答了这个问题
于是到Flink-CDC官网(Oracle CDC Connector — CDC Connectors for Apache Flink® documentation)看看有没有什么参数可以控制这个类型的转换
可以看到,Flink-CDC提供的参数都比较简单,于是再去debezium看看
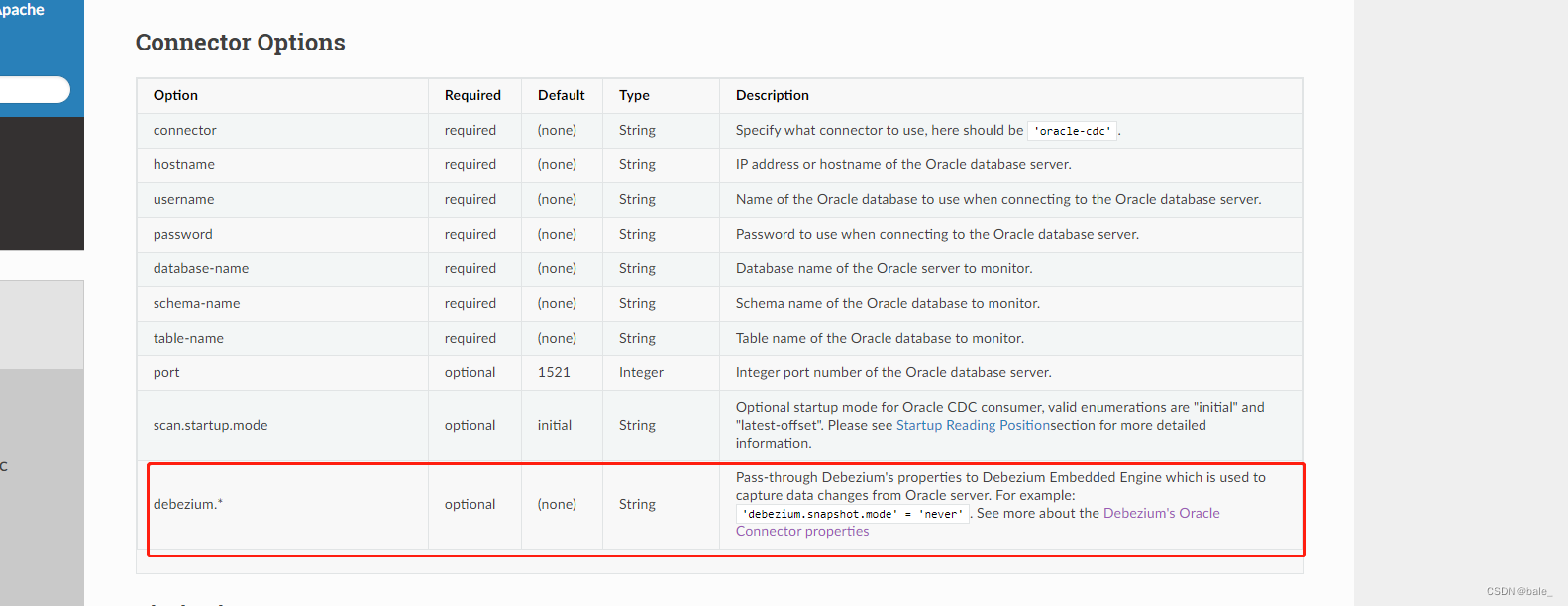
到debezium网站找啊找啊找,找到了一个神奇的和我想像中一样的参数,它叫decimal.handling.mode
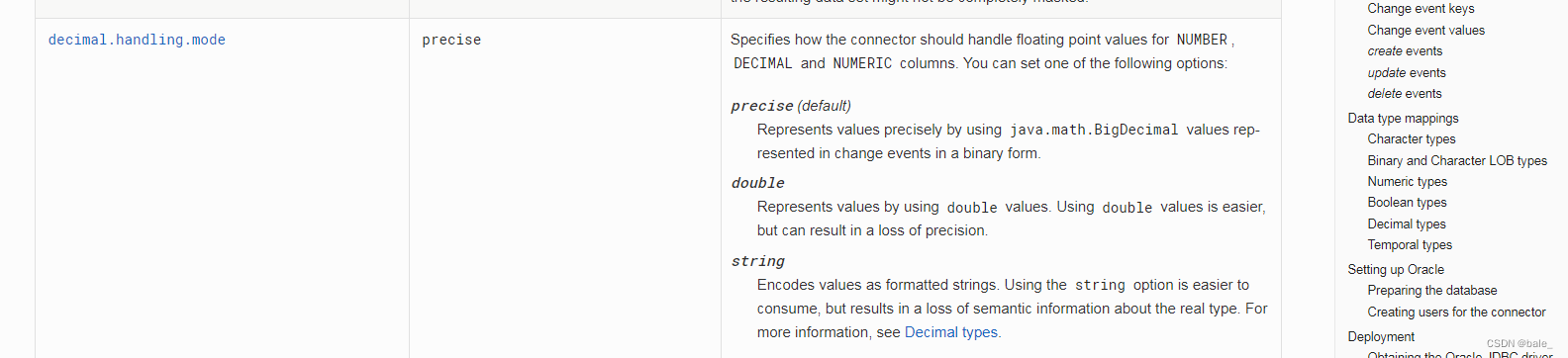
可以看到这个参数默认值 是precise,还有其他两个可选值double和string
看看说明,简单理解一下
precise 以java中的精确类型来表示值
double 使用比较容易,但是会造成精度损失
string 也比较容易使用,但是会造成字段语意信息丢失
那么我直接整个string不就完美了,转成json就只有值了,我管你什么语意
果断试一下
public static void main(String[] args) throws Exception {
Properties prop = new Properties();
prop.put("decimal.handling.mode", "string");
SourceFunction<String> sourceFunction = OracleSource.<String>builder()
.hostname("...")
.port(...)
.database("...") // monitor XE database
.schemaList("...") // monitor inventory schema
.tableList("...") // monitor products table
.username("...")
.password("...")
.debeziumProperties(prop)
.deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(sourceFunction)
.print()
.setParallelism(1)
; // use parallelism 1 for sink to keep message ordering
env.execute();
}看到结果,瞬间通透了

还看了一下debezium的其他参数,非常多,还需要持续的学习
结论不重要,学习的过程很重要
后续补充:
后来又遇到money类型的转换问题,设置decimal.handling.mode=string,money类型的字段还是变成base64编码的字符串
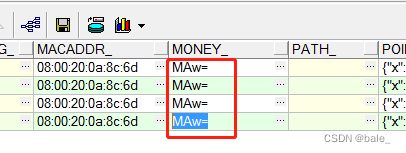
如果从flink-cdc的网站连接进入debezium,打开的文档是1.6版本的,而且从flink-cdc的源码工程看,最新的flink-cdc2.3使用的debezium还是1.6.4.Final版本的。
此时从debezium文档可以看到decimal.handling.mode设置只有decimal和number列,全网页搜索money没有这个关键字

试着往之后的版本搜索,一直到1.8版本的,可以看到有money了
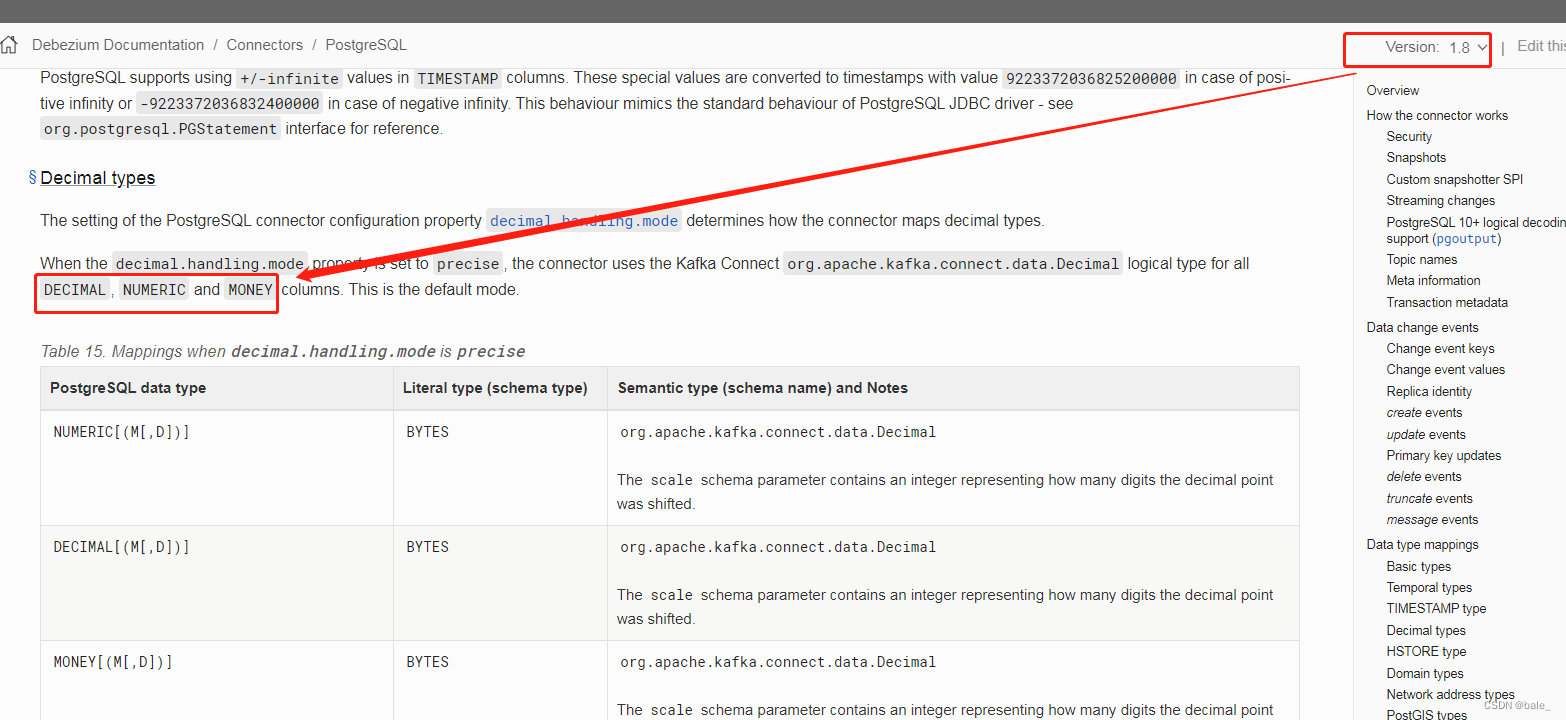
然后排除flink-cdc中的debezium依赖,从新引入1.8版本依赖,decimal.handling.mode设置就对money有效了
postgresql示例:
<properties>
<flink.cdc>2.2.1</flink.cdc>
<debezium.version>1.8.0.Final</debezium.version>
</properties>
<dependencies>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-postgres-cdc</artifactId>
<version>${flink.cdc}</version>
<exclusions>
<exclusion>
<artifactId>debezium-core</artifactId>
<groupId>io.debezium</groupId>
</exclusion>
<exclusion>
<artifactId>debezium-connector-postgres</artifactId>
<groupId>io.debezium</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-core</artifactId>
<version>${debezium.version}</version>
</dependency>
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-connector-postgres</artifactId>
<version>${debezium.version}</version>
</dependency>
</dependencies>
终极解决方案:
如果工程只采集postgresql,通过排除flink-cdc依赖的 debezium1.6,引入debezium1.8可以解决money类型被转成base64格式问题。但是,如果工程中还同时集成了采集mysql,oracle等,这样做会引起其他兼容问题,所以不用排出依赖重新引入了。文章最开始的通过json解码器设置dicimal类型解码规则重新用起来,在结合decimal.handling.mode设置完美解决问题
Properties prop = new Properties();
prop.put("decimal.handling.mode", "string");
Map config = new HashMap();
config.put(JsonConverterConfig.DECIMAL_FORMAT_CONFIG, DecimalFormat.NUMERIC.name());
JsonDebeziumDeserializationSchema jdd = new JsonDebeziumDeserializationSchema(true, config);
SourceFunction<String> sourceFunction = PostgreSQLSource.<String>builder()
.hostname("..")
.port(5432)
.database("..") // monitor postgres database
.schemaList("..") // monitor inventory schema
.tableList("..") // monitor products table
.username("..")
.password("...")
.debeziumProperties(prop)
.decodingPluginName("pgoutput")
.deserializer(jdd) // converts SourceRecord to JSON String
.build();
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
在我的Rails(2.3,Ruby1.8.7)应用程序中,我需要将字符串截断到一定长度。该字符串是unicode,在控制台中运行测试时,例如'א'.length,我意识到返回了双倍长度。我想要一个与编码无关的长度,以便对unicode字符串或latin1编码字符串进行相同的截断。我已经了解了Ruby的大部分unicode资料,但仍然有些一头雾水。应该如何解决这个问题? 最佳答案 Rails有一个返回多字节字符的mb_chars方法。试试unicode_string.mb_chars.slice(0,50)
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%