hello~大家好,我是小楼,今天分享的话题是Go是否能实现AOP?
写Java的同学来写Go就特别喜欢将两者进行对比,就经常看到技术群里讨论,比如Go能不能实现Java那样的AOP啊?Go写个事务好麻烦啊,有没有Spring那样的@Transactional注解啊?
遇到这样的问题我通常会回复:没有、实现不了、再见。

直到看了《Go语言底层原理剖析》这本书,开始了一轮认真地探索。
AOP概念第一次是在若干年前学Java时看的一本书《Spring实战》中看到的,它指的是一种面向切面编程的思想。注意它只是一种思想,具体怎么实现,你看着办。
AOP能在你代码的前后织入代码,这就能做很多有意思的事情了,比如统一的日志打印、监控埋点,事务的开关,缓存等等。
可以分享一个我当年学习AOP时的笔记片段:

在Java中的实现方式可以是JDK动态代理和字节码增强技术。
JDK动态代理是在运行时动态地生成了一个代理类,JVM通过加载这个代理类再实例化来实现AOP的能力。
字节码增强技术可以多唠叨两句,当年学Java时第一章就说Java的特点是「一次编译,到处运行」。
但当我们真正在工作中这个特性用处大吗?好像并不大,生产中都使用了同一种服务器,只编译了一次,也都只在这个系统运行。做到一次编译,到处运行的技术底座是JVM,JVM可以加载字节码并运行,这个字节码是平台无关的一种二进制中间码。
似乎这个设定带来了一些其他的好处。在JVM加载字节码时,字节码有一次被修改的机会,但这个字节码的修改比较复杂,好在有现成的库可用,如ASM、Javassist等。
至于像ASM这样的库是如何修改字节码的,我还真就去问了Alibaba Dragonwell的一位朋友,他回答ASM是基于Java字节码规范所做的「硬改」,但做了一些抽象,总体来说还是比较枯燥的。
由于这不是本文重点,所以只是提一下,如果想更详细地了解可自行网上搜索。
之前用「扁鹊三连」的方式回复Go不能实现AOP的基础其实就是我对Java实现AOP的思考,因为Go没有虚拟机一说,也没有中间码,直接源码编译为可执行文件,可执行文件基本没法修改,所以做不了。
但真就如此吗?我搜索了一番。
还真就在Github找到了一个能实现类似AOP功能的库gohook(当然也有类似的其他库):
看这个项目的介绍:
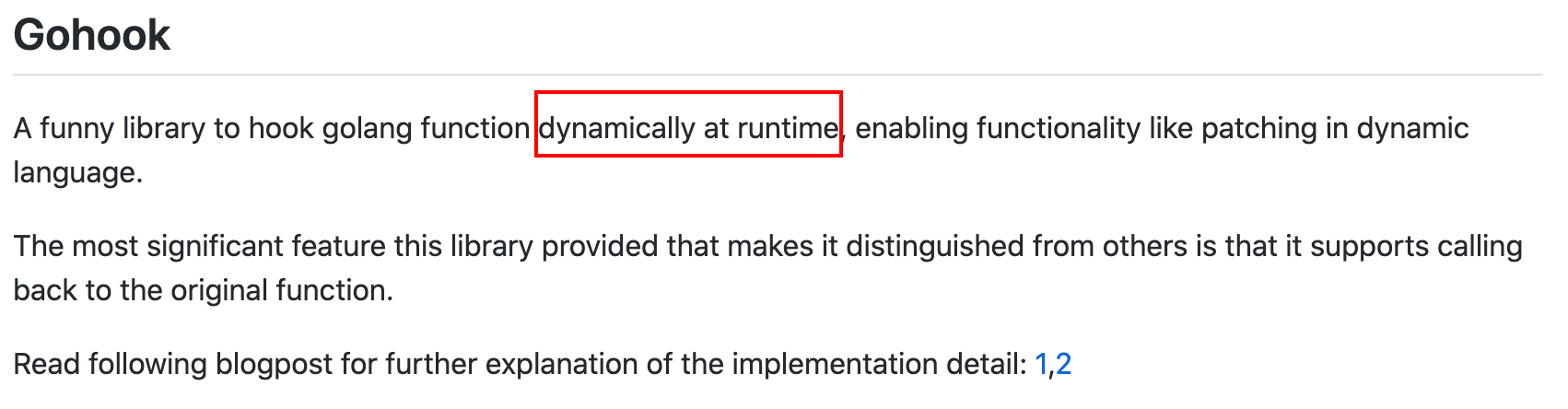
运行时动态地hook Go的方法,也就是可以在方法前插入一些逻辑。它是怎么做到的?
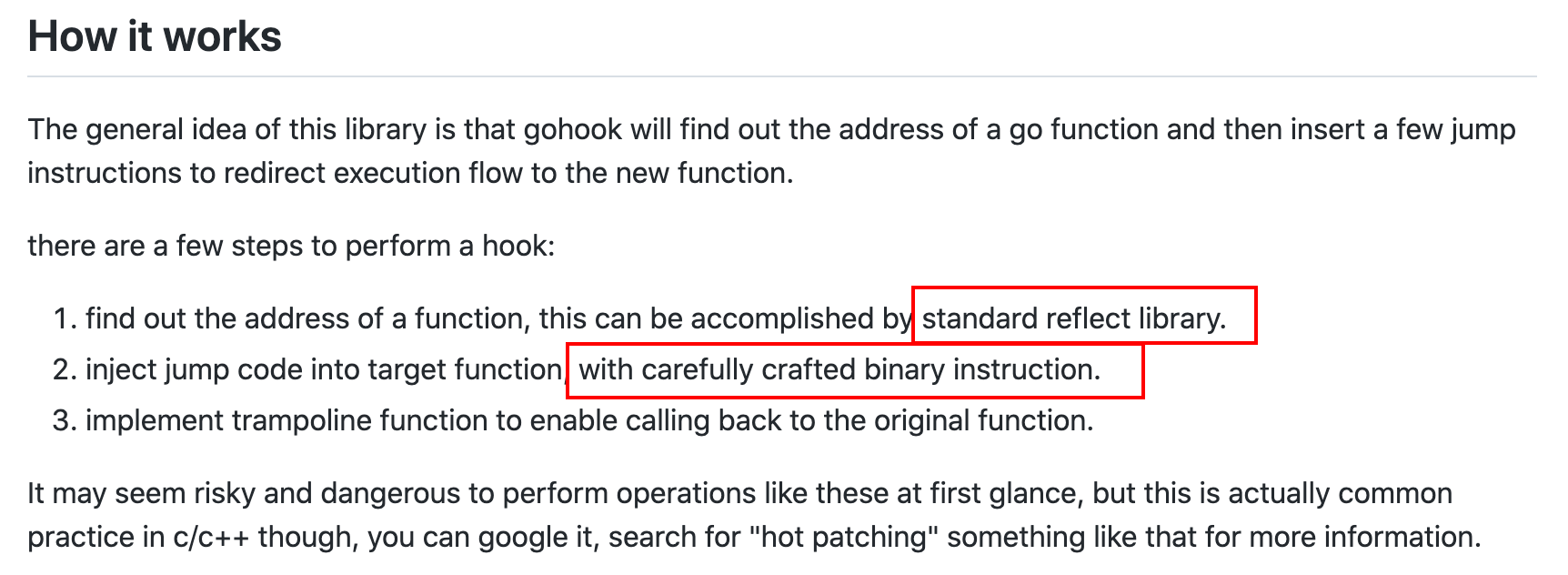
通过反射找到方法的地址(指针),然后插入一段代码,执行完后再执行原方法。听起来很牛X,但它下面有个Notes:
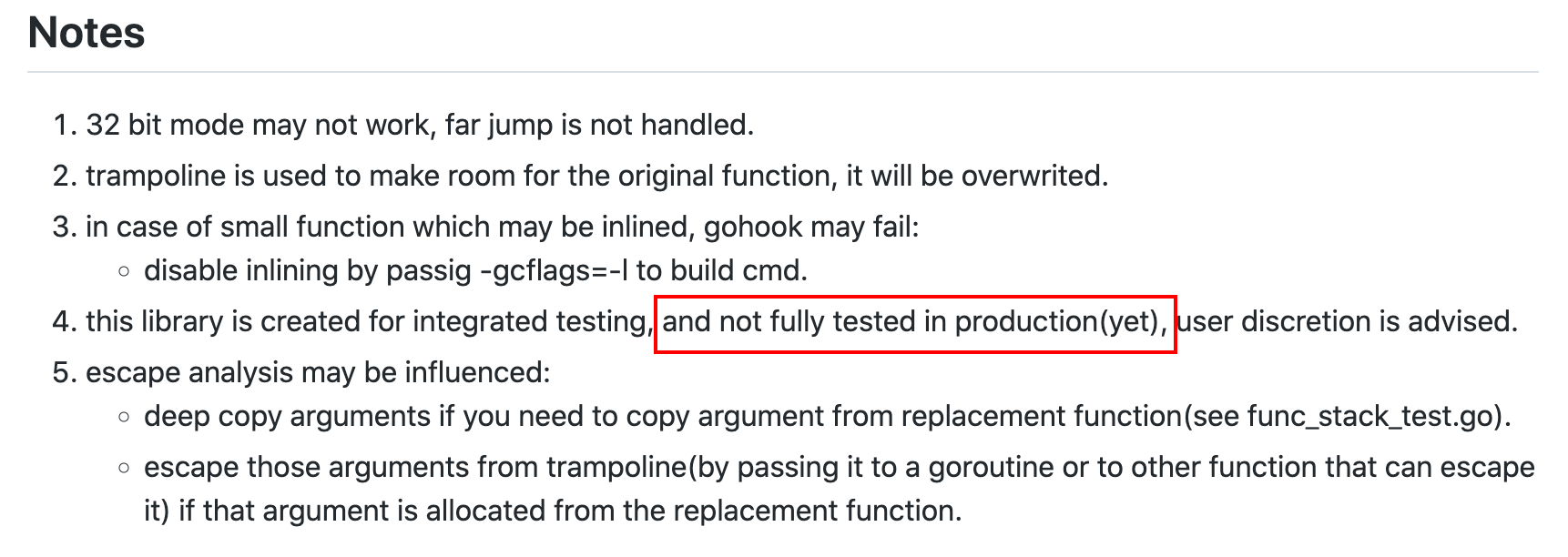
使用有一些限制,更重要的是没有完全测试,不建议生产使用。这种不可靠的方式也就不尝试了。
这种方式就是我在看《Go语言底层原理剖析》第一章看到的,其实我之前的文章也有写过关于AST的,《Cobar源码分析之AST》。
AST即抽象语法树,可以认为所有的高级编程语言都可以抽象为一种语法树,即对代码进行结构化的抽象,这种抽象可以让我们更加简单地分析甚至操作源码。
Go在编译时大概分为词法与语法分析、类型检查、通用 SSA 生成和最后的机器代码生成这几个阶段。
其中词法与语法分析之后,生成一个AST树,在Go中我们能调用Go提供的API很轻易地生成AST:
fset := token.NewFileSet()
// 这里file就是一个AST对象
file, err := parser.ParseFile(fset, "aop.go", nil, parser.ParseComments)
比如这里我的aop.go文件是这样的:
package main
import "fmt"
func main() {
fmt.Println(execute("roshi"))
}
func execute(name string) string {
return name
}
想看生成的AST长什么样,可调用下面的方法:
ast.Print(fset, file)
由于篇幅太长,我截个图感受下即可:
当然也有一些开源的可视化工具,但我觉得大可不必,想看的话Debug看下file的结构。
至于Go AST结构的介绍,也不是本文的重点,而且AST中的类型很多很多,我建议如果你想看的话直接Debug来看,对照源码比较清晰。
我们这里就实现一个简单的,在execute方法执行之前添加一条打印before的语句,接上述代码:
const before = "fmt.Println(\"before\")"
...
exprInsert, err := parser.ParseExpr(before)
if err != nil {
panic(err)
}
decls := make([]ast.Decl, 0, len(file.Decls))
for _, decl := range file.Decls {
fd, ok := decl.(*ast.FuncDecl)
if ok {
if fd.Name.Name == "execute" {
stats := make([]ast.Stmt, 0, len(fd.Body.List)+1)
stats = append(stats, &ast.ExprStmt{
X: exprInsert,
})
stats = append(stats, fd.Body.List...)
fd.Body.List = stats
decls = append(decls, fd)
continue
} else {
decls = append(decls, decl)
}
} else {
decls = append(decls, decl)
}
}
file.Decls = decls
这里AST就被我们修改了,虽然我们是写死了针对execute方法,但总归是迈出了第一步。
再把AST转换为源码输出,Go也提供了API:
var cfg printer.Config
var buf bytes.Buffer
cfg.Fprint(&buf, fset, file)
fmt.Printf(buf.String())
输出效果如下:
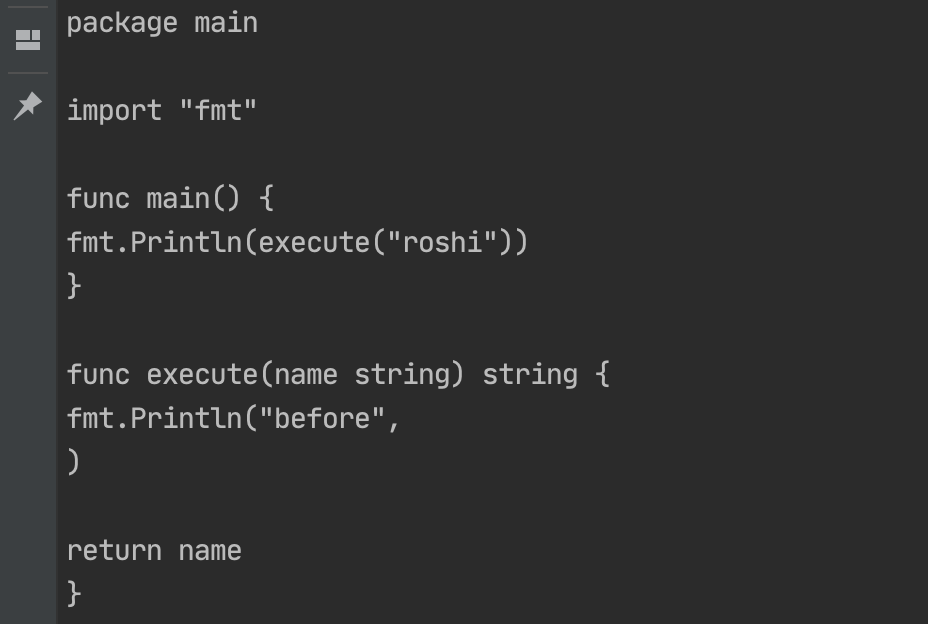
看到这里,我猜你应该有和我相同的想法,这玩意是不是可以用来格式化代码?
没错,Go自带的格式化代码工具gofmt的原理就是如此。
当我们写完代码时,可以执行gofmt对代码进行格式化:
gofmt test.go
这相比于其他语言方便很多,终于有个官方的代码格式了,甚至你可以在IDEA中安装一个file watchers插件,监听文件变更,当文件有变化时自动执行 gofmt 来格式化代码。
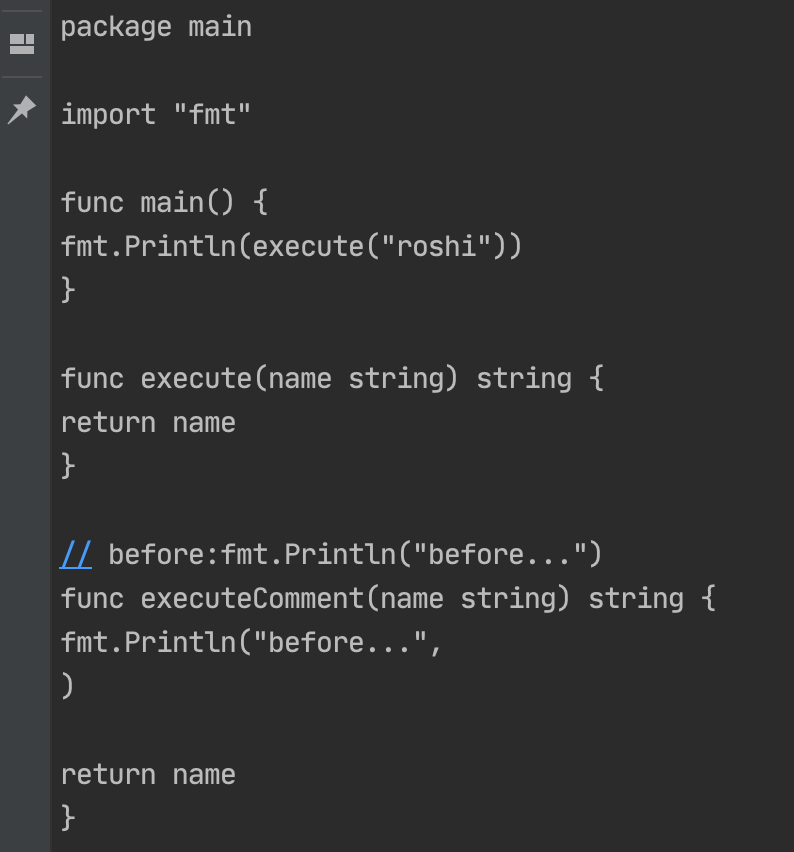
看到这里你可能觉得太简单了,我查了下资料,AST中还能拿到注释,这就厉害了,我们可以把注释当注解来玩,比如我加了 // before: 的注释,自动把这个注释后的代码添加到方法之前去。
// before:fmt.Println("before...")
func executeComment(name string) string {
return name
}
修改AST代码如下,为了篇幅,省略了打印代码:
cmap := ast.NewCommentMap(fset, file, file.Comments)
for _, decl := range file.Decls {
fd, ok := decl.(*ast.FuncDecl)
if ok {
if cs, ok := cmap[fd]; ok {
for _, cg := range cs {
for _, c := range cg.List {
if strings.HasPrefix(c.Text, "// before:") {
txt := strings.TrimPrefix(c.Text, "// before:")
ei, err := parser.ParseExpr(txt)
if err == nil {
stats := make([]ast.Stmt, 0, len(fd.Body.List)+1)
stats = append(stats, &ast.ExprStmt{
X: ei,
})
stats = append(stats, fd.Body.List...)
fd.Body.List = stats
decls = append(decls, fd)
continue
}
}
}
}
} else {
decls = append(decls, decl)
}
} else {
decls = append(decls, decl)
}
}
file.Decls = decls
跑一下看看:
虽然又是硬编码,但这不重要,又不是不能用~

但你发现,这样实现AOP有个缺点,必须在编译期对代码进行一次重新生成,理论上来说,所有高级编程语言都可以这么操作。
但这不是说毫无用处,比如这篇文章《每个 gopher 都需要了解的 Go AST》就给了我们一个实际的案例:

写到最后,我又在思考另一个问题,为什么Go的使用者没有AOP的需求呢?反倒是写Java的同学会想到AOP。
我觉得可能还是Go太年轻了,Java之所以要用AOP,很大的原因是代码已经堆积如山,没法修改,历史包袱沉重,最小代价实现需求是首选,所以会选择AOP这种技术。
反观Go还年轻,大多数项目属于造轮子期间,需要AOP的地方早就在代码中提前埋伏好了。我相信随着发展,一定也会出现一个生产可用Go AOP框架。
至于现在问我,Go能否实现AOP,我还是回答:没有、实现不了、再见。
对了,本文的完整测试代码这里可以看到:
https://github.com/lkxiaolou/all-in-one/tree/master/go-in-one/samples/tree
感谢大家,如果有点收获,点个在看、赞、关注吧,我们下期再见。
搜索关注微信公众号"捉虫大师",后端技术分享,架构设计、性能优化、源码阅读、问题排查、踩坑实践。
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定
我目前有一个reddit克隆类型的网站。我正在尝试根据我的用户之前喜欢的帖子推荐帖子。看起来K最近邻或k均值是执行此操作的最佳方法。我似乎无法理解如何实际实现它。我看过一些数学公式(例如k表示维基百科页面),但它们对我来说并没有真正意义。有人可以推荐一些伪代码,或者可以查看的地方,以便我更好地了解如何执行此操作吗? 最佳答案 K最近邻(又名KNN)是一种分类算法。基本上,您采用包含N个项目的训练组并对它们进行分类。如何对它们进行分类完全取决于您的数据,以及您认为该数据的重要分类特征是什么。在您的示例中,这可能是帖子类别、谁发布了该项
我查看了Stripedocumentationonerrors,但我仍然无法正确处理/重定向这些错误。基本上无论发生什么,我都希望他们返回到edit操作(通过edit_profile_path)并向他们显示一条消息(无论成功与否)。我在edit操作上有一个表单,它可以POST到update操作。使用有效的信用卡可以正常工作(费用在Stripe仪表板中)。我正在使用Stripe.js。classExtrasController5000,#amountincents:currency=>"usd",:card=>token,:description=>current_user.email)
虽然1.8.7的构建我似乎有一个向后移植的Shellwords::shellescape版本,但我知道该方法是1.9的一个特性,在1.8的早期版本中绝对不支持.有谁知道我在哪里可以找到(以Gem形式或仅作为片段)针对Ruby转义的Bourne-shell命令的强大独立实现? 最佳答案 您也可以从shellwords.rb中复制您想要的内容。在Ruby的颠覆存储库的主干中(即GPLv2'd):defshellescape(str)#Anemptyargumentwillbeskipped,soreturnemptyquotes.ret