文章目录
择时交易是指利用某种方法来判断大势的走势情况,是上涨还是下跌或者是盘整。如果判断是上涨,则买入持有;如果判断是下跌,则卖出清仓;如果判断是震荡,则进行高抛低吸,这样可以获得远远超越简单买入持有策略的收益率,所以择时交易是收益率最高的一种交易方式。
量化择时就是利用数量化的方法,通过对各种宏观微观指标的量化分析,试图找到影响大盘走势的关键信息,并且对未来走势进行预测
| 量化择时方法 | 简介 |
|---|---|
| 趋势择时 | 基本思想来自于技术分析,技术分析认为趋势存在延续性,因此只要找到趋势方向,跟随操作即可。趋势择时的主要指标有MA、MACD、DMA等 |
| 市场情绪择时 | 利用投资者的热情程度来判断大势方向,当情绪热烈,积极入市时,大盘可能会继续涨;当投资者情绪低迷、不断撤出市场的时候,大盘可能继续下跌。 |
| 有效资金模型 | 与选股模型中的资金流模型类似,其是通过判断推动大盘上涨或者下跌的有效资金来判断走势,因为在顶部和底部时资金效果具有额外的推动力。 |
| 牛熊线择时 | 思想就是将大盘的走势划分为两根线,一根为牛线,一根为熊线。在牛熊线之间时大盘不具备方向性,如果突破牛线,则可以认为是一波大的上涨趋势的到来;如果突破熊线,则可以认为是一波大的下跌趋势到来。 |
| Hurst指数 | Hurst指数是分形理论在趋势判断中的应用,分形市场理论认为,资本市场是由大量具有不同投资期限的投资者组成的,且信息对不同投资者的交易周期有着不同的影响。利用Hurst指数可以将市场的转折点判断出来,从而实现择时。 |
| SVM | 是一种分类技术,具有效率高、推广性能好的优点,SVM择时就是利用SVM技术进行大盘趋势的模式识别,将大盘区分为几个明显的模式,从而找出其中的特征,然后利用历史数据学习的模型来预测未来的趋势。 |
| SWARCH模型 | 是海通证券开发的一种利用宏观经济指标来判断大盘的策略,该模型主要刻画了货币供应量M2和大盘走势之间的关系,揭示我国证券市场指数变化与货币供应量之间的相关关系。 |
| 异常指标择时 | 主要处理一些特殊情况下的择时,例如,在大盘出现顶点或者低点的时候,有些指标容易出现异常数据,这段介绍了市场噪声、行业集中度和兴登堡凶兆3个策略。 |
技术分析的理论基础基于三项市场假设:市场行为涵盖一切信息;价格沿趋势移动;历史会重演。
技术指标是技术分析中使用最多的一种方法,通过考虑市场行为的多个方面建立一个数学模型,并给出完整的数学计算公式,从而得到一个体现证券市场的某个方面内在实质的数字,即所谓的技术指标值。
葛南维移动平均线八大法则。其中,四条用来研判买进时机,四条用来研判卖出时机移动平均线在价格之下,而且又呈上升趋势时是买进时机;反之,平均线在价格线之上,又呈下降趋势时则是卖出时机。
交叉择时法则,即当一条短期均线从下向上穿过长期均线时,形成所谓金叉,此时应该做多;而当一长期均线从上向下穿过短期均线时,形成所谓死叉,此时应该做空或空仓
MACD指标是根据均线的构造原理,通过分析短期(常用为12日)指数移动平均线与长期(常用为26日)指数移动平均线之间的聚合与分离状况,对买进、卖出时机做出判断的技术指标,是一种典型的趋势型指标。
MACD的计算
(1)计算短期(S日)指数移动平均线和长期(L日)指数移动平均线EMA1、EMA2。
(2)计算离差值DIF=EMA1-EMA2。
(3)计算DIF的N日指数移动平均线,即DEA。
(4)计算MACD=2*(DIF-DEA)。在MACD的计算和测试中,需要设定的参数主要包括短期均线和长期均线的计算天数S、L,以及DEA的计算天数M
MACD的运用
(1)DIFF、DEA均为正,DIFF向上突破DEA,买入信号。
(2)DIFF、DEA均为负,DIFF向下跌破DEA,卖出信号。
(3)DEA线与K线发生背离,行情反转信号。
(4)分析MACD柱状线,由红变绿(正变负),卖出信号;由绿变红,买入信号。
DMA是依据快慢两条移动平均线的差值情况来分析价格趋势的一种技术分析指标。
它主要通过计算两条基准周期不同的移动平均线的差值,来判断当前买入卖出的能量的大小和未来价格走势的趋势。
DMA的计算
(1)计算短期(S日)移动均线和长期(L日)移动均线MA1、MA2。
(2)计算平均线差DMA=MA1-MA2。
(3)计算DMA的M日移动平均线,即AMA。在DMA的计算中,需要设定的参数主要是短期均线和长期均线的计算天数S、L,以及AMA的计算天数M。
DMA的运用
(1)DMA向上交叉其平均线AMA时,买进。
(2)DMA向下交叉其平均线AMA时,卖出。
(3)DMA与股价产生背离时的交叉信号,可信度较高
TRIX指标是根据移动平均线理论,对一条平均线进行三次平滑处理,再根据这条移动平均线的变动情况来预测股价的长期走势。
TRIX的计算
(1)计算N日的指数移动平均线EMA。
(2)对上述EMA再进行两次N日指数移动平均后得到TR。
(3)计算TRIX=(TR-昨日TR)/昨日TR*100。
(4)计算TRIX的M日简单移动平均MATRIX。在TRIX的计算中,需要设定的参数主要是三次移动平均的天数N,以及MATRIX的计算天数M。
TRIX的运用
(1)TRIX由下往上交叉其平均线时,为长期买进信号。
(2)TRIX由上往下交叉其平均线时,为长期卖出信号。
固定均线是最简单的情况,虽然效果很好,但是也有很大的缺点。
通常均线总是有一个给定的参数,如10日均线、60日均线,其中10日均线变化快一点,60日均线变化慢一点。这个参数是由人给定的,一旦给定了,在整个画线的过程中不管行情怎么变动都不会变化。
比如,在市场反复震荡时短期均线频繁地转向,而在市场快速上升或者下跌时长期均线反应迟钝,这就会造成频繁发出错误开平仓信号。
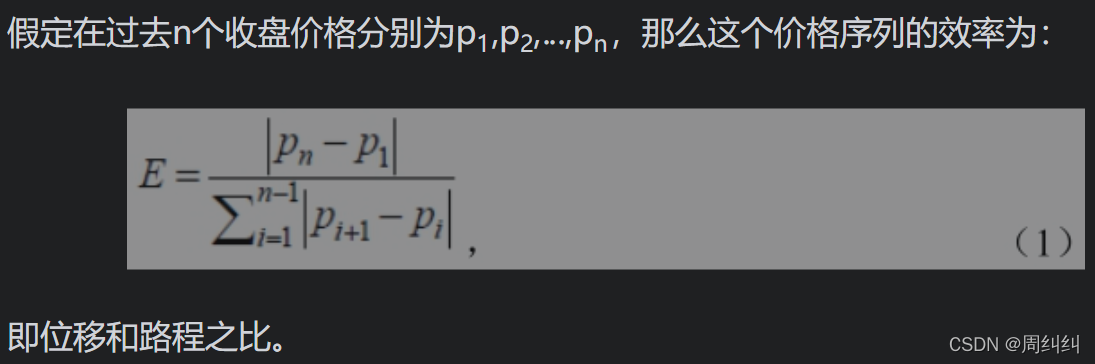
1)价格轨迹的效率
一般来说,投资者都有这样的经验,就是在震荡多的走势上要使用较慢的均线,在趋势快速展开的走势上需要用更快的均线。
在行情的走势图中,可以大致分为两种走势:一种是一直上攻的走势,被称为高效率的,因为每一天收盘价格的变动都直接贡献于总的涨幅;另一种是反复震荡的走势,被称为低效率的,很多次收盘价格的变化相互抵消。类似于物理学中路程和位移的概念,如果走过的路程很长,但是位移很小,在实现位移的目标考量下,这样的运动可以称为低效率的。
价格轨迹的效率定义:
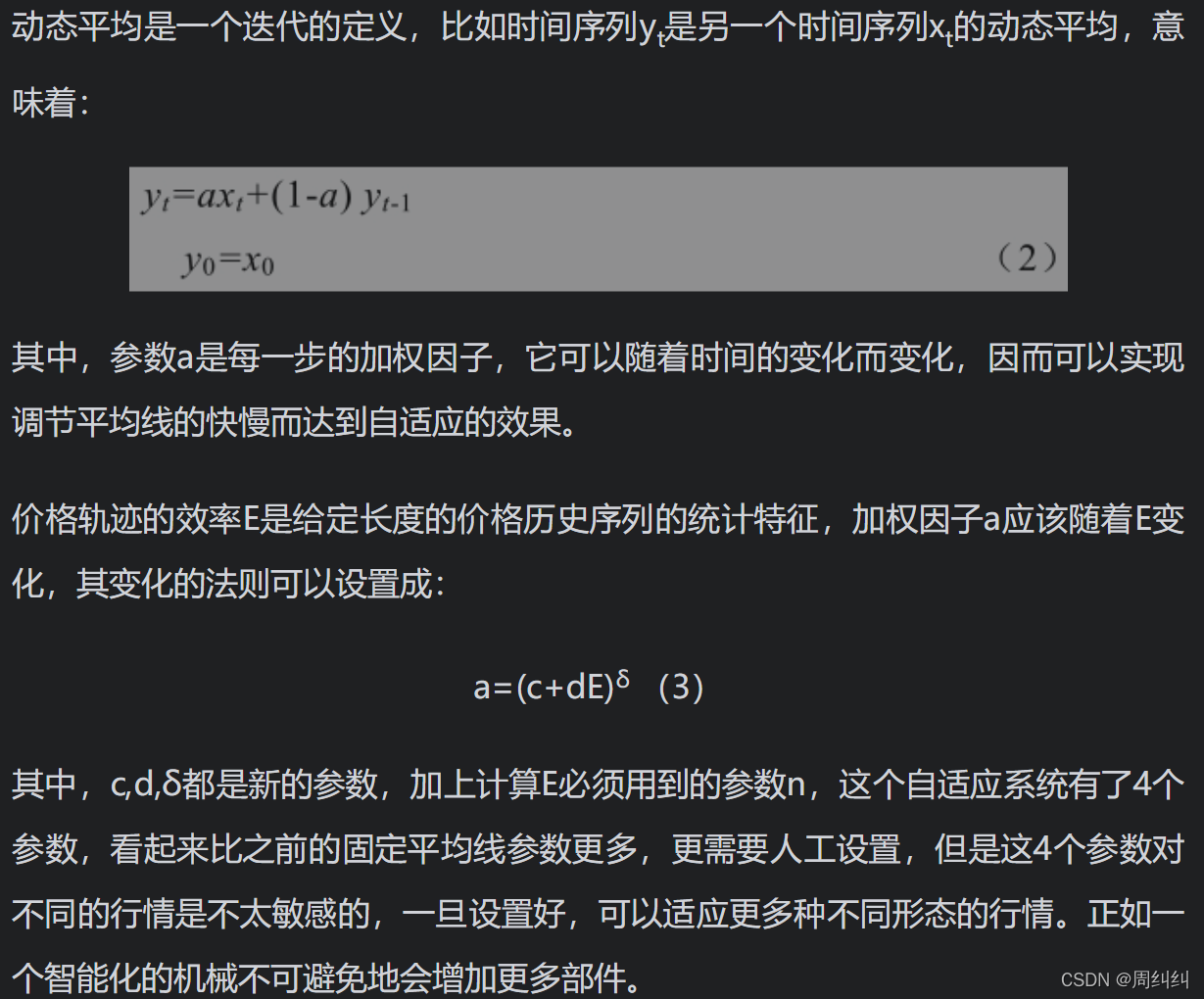

根据自适应均线的买卖策略是:
(1)自适应均线自下向上拐头,买进。
(2)自适应均线自上向下拐头,卖出。
拐头与否可以这样定义,自适应均线的每一个周期的增长率如果从正值变为负值,即为下拐头;从负值变为正值,即为上拐头。
我正在使用这个:4.times{|i|assert_not_equal("content#{i+2}".constantize,object.first_content)}我之前声明过局部变量content1content2content3content4content5我得到的错误NameError:wrongconstantnamecontent2这个错误是什么意思?我很确定我想要content2=\ 最佳答案 你必须用一个大字母来调用ruby常量:Content2而不是content2。Aconstantnamestart
我有一个单表继承设置,我有一个Controller(我觉得有多个Controller会重复)。但是,对于某些方法,我想调用模型的子类。我想我可以让浏览器发送一个参数,我会针对该参数编写一个case语句。像这样的东西:case@model[:type]when"A"@results=Subclass1.search(params[:term])when"B"@results=Subclass2.search(params[:term])...end或者,我了解到Ruby的所有技巧都可以用字符串创建模型。像这样的东西:@results=params[:model].constantize.
在我的Rails应用程序中,我收到来自brakeman的以下安全警告。使用模型属性调用的不安全反射方法常量化。这是我的代码正在执行的操作。chart_type=Chart.where(id:chart_id,).pluck(:type).firstbeginChartPresenter.new(chart_type.camelize.constantize.find(chart_id))rescueraise"Unabletofindthechartpresenter"end根据我的研究,我还没有找到任何具体的解决方案。我听说你可以创建一个白名单,但我不确定brakeman在寻找什么。
文章目录1.价差套利原理1.1概述1.2以BTC为例2.投研分析3.veighna的价差交易回测引擎4.实盘交易1.价差套利原理1.1概述在数字货币交易市场,我们会发现大多数行情下,相同币种之间的不同交割合约会存在一定的价差,由于它们属于同一品种,本身价值不会有任何差别,而且涨跌趋势一致,相关性高。那么如果在它们价差低的时候买入,价差高的时候卖出,这样我们就可以赚取中间的这部分差价。不过在实际交易过程中,我们还需要考虑到交易滑点、手续费、极端行情下,价差走出趋势特征…1.2以BTC为例图一、不同合约的比特币行情图由上图可以看出比特币远月合约与永续合约之间存在一定的价差。图二、某一时刻比特币价差
量化交易-因子有效性分析一、因子的IC分析2.信息系数3.举例4.因子处理4.1去极值4.2标准化4.3市值中性化一、因子的IC分析判断因子与收益的相关性强度分析结果因子平均收益ICmeanICstdIC>0.02:IC大约0.02的比例,越大越严格IR:信息比率(历史表现的稳定性),IR=ICmean/ICstd2.信息系数定义:某一期的IC指的是该期因子暴露度和股票下期的实际回报值在横截面上的相关系数。因子暴露度:因子本身数值周期一天:该期的因子值(2023.1.11)、下期(2023.1.12)收益率(截面数据)计算方式:斯皮尔曼相关系数(RankIC)斯皮尔曼相关系数表明X(独立变量)
我想用JavaScript编写需要大量数值计算的应用程序。但是,我对客户端JavaScript中类似线性代数的高效计算的状态感到非常困惑。似乎有很多方法,但没有明确表明它们已经准备就绪。他们中的大多数似乎对允许计算的向量和矩阵的大小有限制。WebGL显然允许在GPU上进行矢量和矩阵计算,但我不清楚限制。Attemptedwrappers这个库周围似乎限制了矩阵和向量的大小。这是实际限制(浏览器不支持其他任何东西)还是开发限制(需要有人编写代码)?WebCLWebCL是提议的OpenCL浏览器级实现,但是appearstobestuckindevelopment.WebGPUApple最
假设我有以下XML(我的实际XML的高度简化示例):AmsterdamLondonParisAmsterdamBerlin现在我想知道hotelLocation中的值是否确实作为城市存在。我试图在一个XPath语句中做到这一点://hotelLocation=//city但是,如果其中一个hotelLocations匹配,这将返回“true”,而不是我只希望它在all时返回true>hotelLocations存在于cities实体中。知道一个XPath语句是否可行吗? 最佳答案 insteadIonlywantittogivetr
比方说,我有这个xml文件:1.0假设我想用它的系列元素做一些事情,我想把“向量化可向量化”的建议付诸实践......我导入XML库并执行以下操作:R>library("XML")R>docTimeSeriesNodeseriesNodeslength(seriesNodes)[1]3R>(function(x){length(xmlElementsByTagName(x[['series']],'event'))}+)(seriesNodes)[1]6R>而且我不明白为什么我应该只得到将函数应用于第一个元素的结果:我曾期望三个值,就像seriesNodes的长度一样,如下所示:R>m
我有一个包含名为“InvoiceXML”的XMLTYPE列的表。此列中的数据是XML格式:当我做一个SELECT...FORXMLPATH(''),ROOT('Invoices')我最终得到:如何停止列名InvoiceXML出现在输出中? 最佳答案 declare@Ttable(invoiceXMLxml)insertinto@Tvalues('')insertinto@Tvalues('')select(selectT.invoiceXML)from@TasTforxmlpath(''),root('Invoices')编辑1子查
参考书目:深入浅出Python量化交易实战在机器学习里面的X叫做特征变量,在统计学里面叫做协变量也叫自变量,在量化投资里面则叫做因子,所谓多因子就是有很多的特征变量。本次带来的就是多因子模型,并且使用的是机器学习的强大的非线性模型,集成学习里面的随机森林和LGBM模型,带来因子的选择策略和股票的选择策略。由于股票数据的获取都需要第三方库或者是专业的量化投资框架,很多第三方库某些功能需要收费(Tushare),而免费的一些库(证券宝)获取的数据特征变量又没那么多。所以这里是用聚宽量化投资框架,是可以免费使用一些功能的(只需要注册一个账号)。这里获取数据就采用聚宽平台的功能了。数据获取本次使用