DDD受到行业热捧的一个原因是:它设法寻找到一个在软件系统生命周期内稳固不变的点,由它构成架构、协同、交流的基础,帮助我们更好的应对软件中的不确定性。
而API作为对外暴露的接口,也是需要保持高稳定性的组件。最好能像领域模型一样稳定。于是通过领域模型驱动获得API的设计(Domain Model Driven API Desin),就成了一种非常自然的选择。
要从数据角度,而不是行为角度去构建API,这样可以保证构建的API能够和领域模型结合地更加紧密。
继续以极客时间为例,如果从行为角度去构建API,可以参考催化剂的模型,因为这种建模方法中包含了交互:
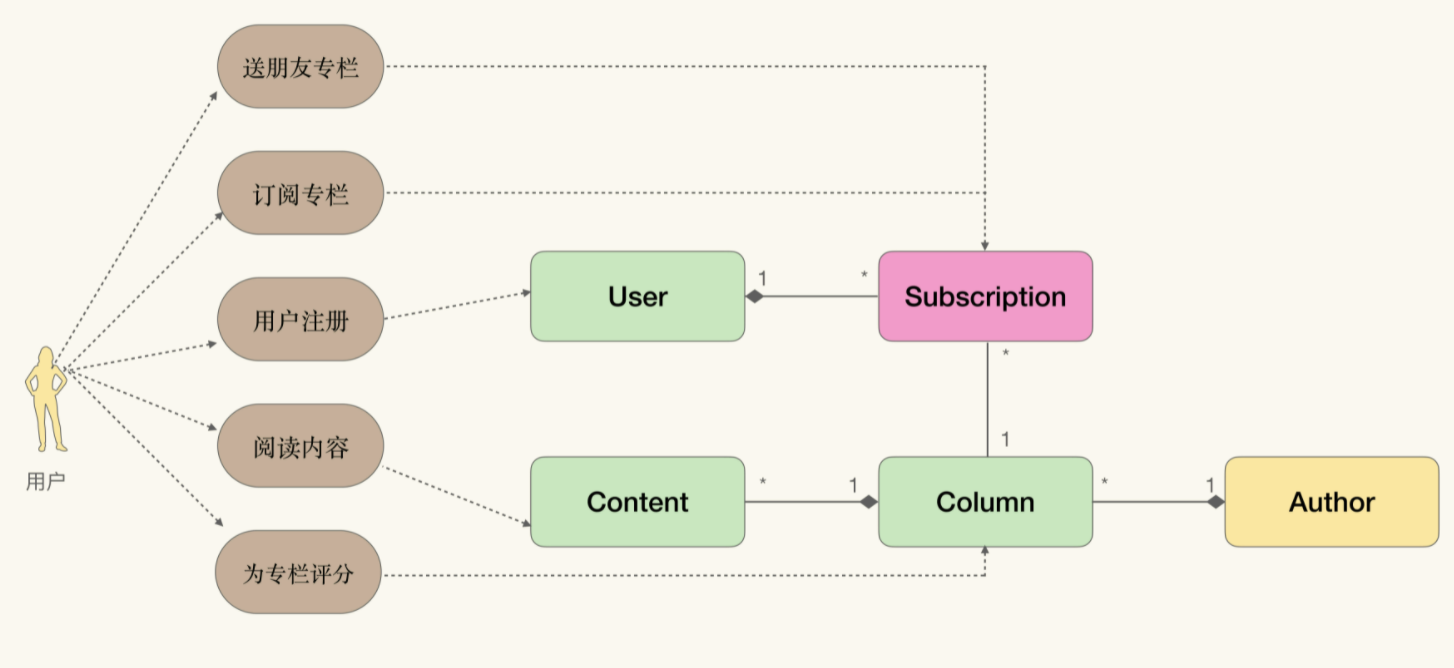
从行为角度去设计API,那么会着眼于从人机交互上入手,寻找系统提供了什么服务,并针对这些服务进行API设计,结果类似这样:
SendGift(...)
SubscriptionColumn(...)
RegisterUser(...)
ReadColumn(...)
RateColumn(...)
这种API风格被称为PRC风格(Remote Procedure Call Style),在1980年代逐渐成为分布式系统的默认风格。优点是简单直接,提供什么功能都在接口里说清楚了;但从模型的角度讲,除非严格使用催化剂方法,否则RPC风格与模型之间有所隔阂,结合地不够紧密,表现在:
换一个角度看待交互行为:在操作之后,对交互背后的模型带来了什么样的改动。
怎么表示这些API呢?可以先使用URI表示需要修改的对象,然后再说明我们希望这个对象发生什么样的改变。
比如/users表示系统中所有的用户,那么注册新用户,就是新增一条数据,可以用POST /users表示。
通过URI与标准HTTP方法,就可以从数据角度构造与RPC等价的API。模型是从数据变化的角度描述业务的,具体的业务流程反而被隐藏了,那么从数据角度去构造API,自然比从行为角度出发更符合领域模型的特点。
RPC风格实际上是面向过程的编程风格,数据中没有逻辑,要通过过程完成对数据的操作。而数据风格的API,则更多是面向对象风格。
RESTful API是为数不多的从数据角度描述API的方法之一,我们选择它来进行领域驱动API设计。
将领域模型映射为RESTful API,可以按这四步进行:
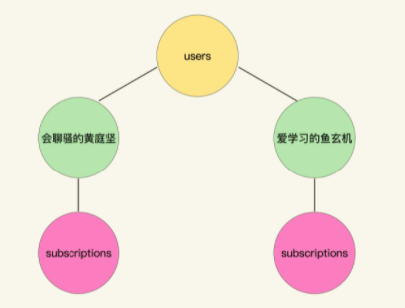
URI的路径可以看做是对某种层次结构遍历的结果,比如/users/爱学习的鱼玄机/subscriptions,就可以认为是对下面的图结构右侧分支遍历的结果:
这个图实际上是将User-Subscriptions聚合进行实例化之后,再将实例与领域对象结合在一起得到的:
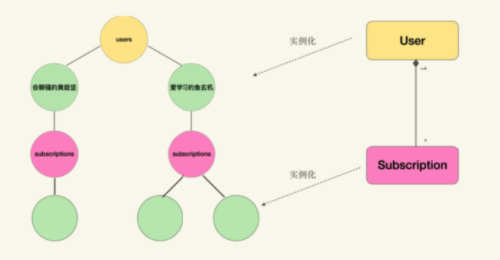
那么看到路径/users/爱学习的鱼玄机/subscriptions或者它的模板化形式/users/{user_id}/subscriptions时,就可以还原出路径背后的领域模型,也就是User-Subscriptions的一对多聚合关系。
通过实例化方式,将领域模型展开成对象图,然后在这种对象图上遍历,就能得到可以表示领域模型的URI路径模板。当然,在理解了实例化与领域模型之间的关系后,也可以直接从领域模型出发来设计URI。
这个过程主要依赖聚合关系,所以需要在领域模型中寻找聚合边界。
比如极客时间专栏的领域模型中,存在两个聚合边界:
对于User-Subscriptions聚合,可以设计如下URI模板
其中,1、3表示集合逻辑,无需实例化;2、4表示实体逻辑,需要实例化模型,将它们从概念具象化到某个特定的个体。
在根据领域模型得到了URI模板后,就需要围绕着URI进行API设计了。过程比较简单,只需构造这样一张表格,表格中包含:角色、HTTP方法、URI、业务场景。
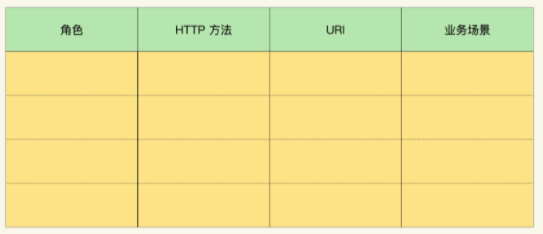
然后只需填入角色、URI,然后按照穷举法,填入所有的HTTP方法,比如对于/users/{uid}/subscriptions,可以有四行,分别对应GET\POST\PUT\DELETE。
下一步就是寻找业务方反馈,帮助我们判断这些由HTTP方法和URI组成的行为是否存在合理的业务场景。
比如经过讨论,认为/users/{uid}/subscriptions的PUT、DELETE不存在业务场景。
这个过程与角色=目标-实体法类似,其中业务场景是目标,实体则是通过URI表示的领域模型。所以这样的API建模过程,同时也在帮助我们展开业务维度,更好地将领域模型作为统一语言。
RESTful API是指符合REST架构风格的API设计,而REST架构风格是对互联网规模架构的提炼与总结。这一切源自Roy Fielding提出的一个问题:既然互联网是人类迄今为止构造的最大的软件应用,那么到底是什么样的结构原则,支撑了如此规模的异构且互联的系统呢?我们能从中学习到什么,以帮助我们更好地构建软件?
Roy Fielding将互联网定义为分布式超媒体信息获取系统,是由超媒体描述的、分布式的信息系统。在这个系统中,信息分布在不同的服务器中,并由超媒体联通。换句话说:分布式超媒体是互联网的集成策略。
分布式超媒体可以实现客户端与服务器之间的渐进式服务消费(Progressive Service Consumption),在客户端的多样性和API的稳定性之间,取得了完美的平衡。
在智能手机流行前,大部分手机浏览器不具备完整执行js的能力,从技术角度讲,CSS、JS都可以看做是对当前页面的增强,CSS增强了当前页面的视觉效果、JS增强了当前页面的交互。
假设极客时间专栏的某篇文章,文本形式是默认服务,此外还有音频、视频形式的增强服务,那么可以在超媒体格式中这样描述这些关联资源:
<article>
<title>***</title>
<p>...</p>
<link href=".../chapter11.mp3" rel="voice">
<link href=".../chapter11.mp4" rel="video">
</article>
如果现在有三个客户端,分别是阅读器、听书播放器、视频播放器,那么这些客户端就可以根据超媒体拿到自己需要的服务资源而忽略其它资源。
通过使用超媒体,可以用同样的API,支撑起完全不同的客户端,通过超媒体描述的增强服务,让客户端与服务器之间形成了一种协商与匹配的关系,客户端按需索取。
超媒体有两个构成要素,只要具备这两个要素,都可以看做超链接,比如html中的link:
json格式没有提供默认的链接格式,而Internet的一个标准提案HAL(Hypertext Application Language)对此做了定义。
JSON HAL规范示例:
{
"_links":{
"self":{"href":"/users/1"},
"subscriptions":{"href":"/users/1/subscriptions"},
},
"username":"fakeUser"
}
这里self表明获取当前资源的uri,也是PrimaryURI,和ID等价,可以作为 当前资源的标识符,也可以用于缓存。这里self的作用还不明显,但如果是/users资源,那么只能通过self的地址来获取某个user的详情。
subscriptions表示了User-Subscriptions聚合关系。对于聚合根而言,需要为所有的聚合对象提供链接。
借助这种方式,可以将常用数据与全量数据设计成渐进式消费的两种不同服务。再配合缓存,性能也不会受太大影响。REST架构大量依赖缓存来缓解性能问题,能否有效地利用缓存会决定REST架构的成败,所以在构造资源的时候,也需要将缓存当做必须考虑的特性,详加设计。
互联网架构的精髓:服务器永远不需要考虑客户端的需求,把客户端的额外需求,当做渐进式服务消费的需求,只需要提供对应的链接,剩下的就交给客户端自行处理,通过将集成与订制推向客户端,从而保证服务端的稳定。
最后一步就是,将API作为模型的另一种表现形式,将其映射回所需支撑的业务流程之中,与业务方一起验证这些API是否能够满足所有的需求。
参考资料
极客时间:如何落地业务建模 徐昊
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何