北京时间:2023/3/28/7:19,周二,早八的一天,难过!终于进入C站周创作榜啦!开心!给大家推荐一首歌《盛夏的果实》,给我的感觉非常的放松,劳逸结合,音乐非它莫属,为了下周周榜可以继续前进,今天我们就来学习一下基础IO的知识吧!

从上篇博客,我们明白,重定向不过只是关闭在文件描述符表下标为0 1 2 默认打开的标准输入、标准输出和标准错误,然后把新文件打开,然后占用文件描述符表中的0 1 2 下标,因为上层并不在乎下标中的文件对象地址是否是标准输入等,而是直接向该下标中的文件对象地址写入;并且我们要明白 ,标准输入文件本质上指向的就是我们的键盘,标准输出和标准错误本质上指向的是显示器, 所以标准输出和标准错误都应该是往显示器打印的,但是如下图所示:
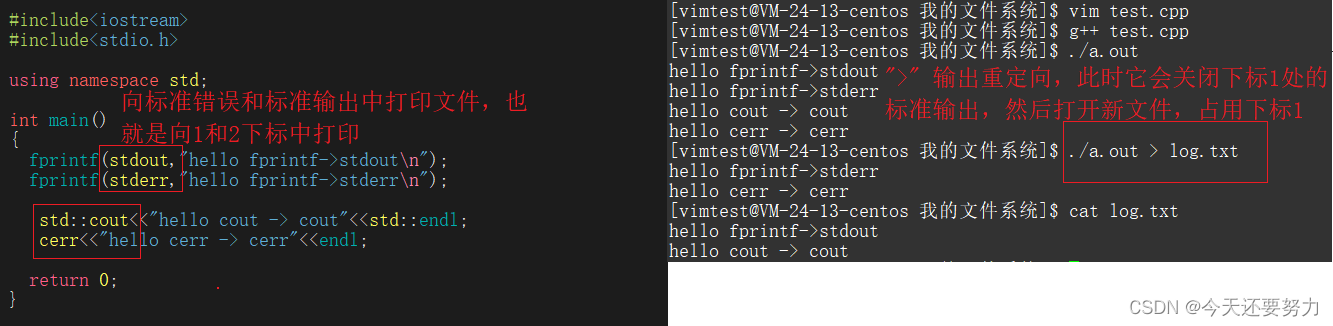
我们可以发现,当我们使用了输出重定向(“>”),此时它会把标准输出文件关闭,然后使用新打开的文件占用原标准输出的在文件描述符表中的下标处的指针指向的地址,所以可以很好的看到,当我们运行可执行程序的时候,此时向标准输出打印的内容已经看不到了,只能看到向标准错误中打印的内容,这也就表示,stdout,cout 都是往文件描述符下标为1对应的文件对象打印,stderr,cerr 都是往文件描述符下标为2对应的文件对象打印,并且此时输出重定向改的只是1下标对应的指向,并不会影响2号,所以导致2下标继续向显示器打印,因为上述的本质,标准输出和标准错误本质上都是向显示器打印,但是使用输出重定向并不会影响下标2,所以不影响向标准错误中打印的数据,所以在我们的显示器上依然可以看到标准错误需要打印的数据,但是向标准输出中打印的数据却不能在显示器上看到,而是只能在重定向的新文件中看到,也就是log.txt中看到了,因为重定向导致此时的标准输出文件地址变成了log.txt。
所以通过上述的知识,我们就可以知道,标准输出和标准错误本质上都是向显示器打印,只是路径有一些不同而已,标准输出是向文件描述符表下标为1处指针指向的文件对象写入,而标准错误是向文件描述符表下标为2处指针指向的文件对象写入,所以此时如果我们有一个需求,就是将一个程序中的正常信息,打印到logNormal.txt中,把错误消息打印到logError.txt当中,目的就是为了区别错误信息和正常信息此时应该怎么办呢?
基本思路:
将文件描述符表中的下标1和2对应的标准输出和标准错误文件给关闭,然后打开我们想要接收信息的文件,此时程序对应的错误信息和正常信息就可以很好的打印到对应的文件之中了,具体代码如下:
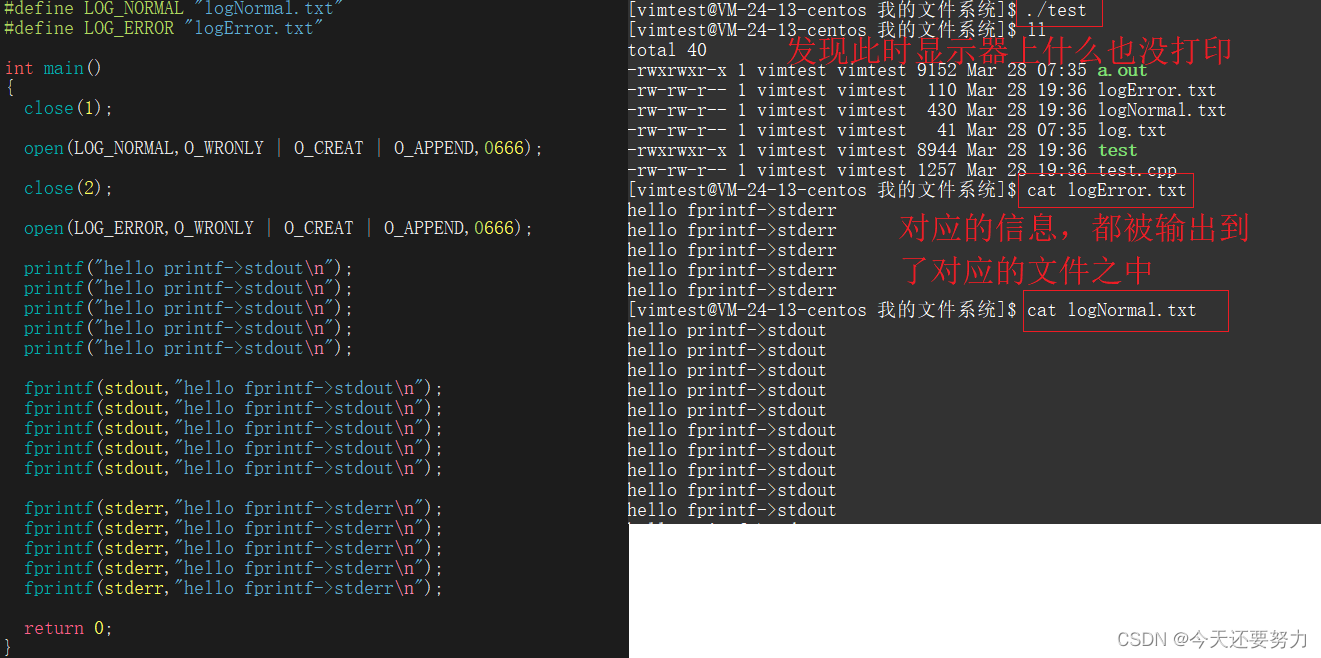
所以使用上述的方法,就可以很好的把文件中的不同类型的信息给区分开来,当然在实际中,并不需要这么麻烦,因为在Linux指令中,Linux系统已经为我们提供了重定向的接口("<",">"),我们就可以直接使用从定向的接口,来完成相应的操作,让系统自己帮我们去关闭对应的文件描述符表中的对应的下标指针指向的文件,指令:./a.out 1>logNormal.txt 2>logErrno.txt ,表示的也就是上图中的功能,本质上就是系统对我们上图所示代码通过 "<",">" 做了一定的封装效果而已,不管怎样都还是要去关闭标准输入、标准输出或者标准错误,然后打开对应的新文件,因为原理就是这样如此!
注意: ./a.out > log.txt 2>&1 意思是将标准错误和标准输出放到同一个文件中,意思:2重定向为1的地址
明白了上述,此时发现像我们以前的写法,先关闭标准输入、标准输出或者标准错误文件,然后再打开一个新文件,这样的写法是比较麻烦的,所以我们可以直接使用dup2这样的重定向函数,使用方式:int dup2(int oldfd,int newfd);,但是值得我们注意的是,此时需要把newfd和oldfd给区分一下,如下图:
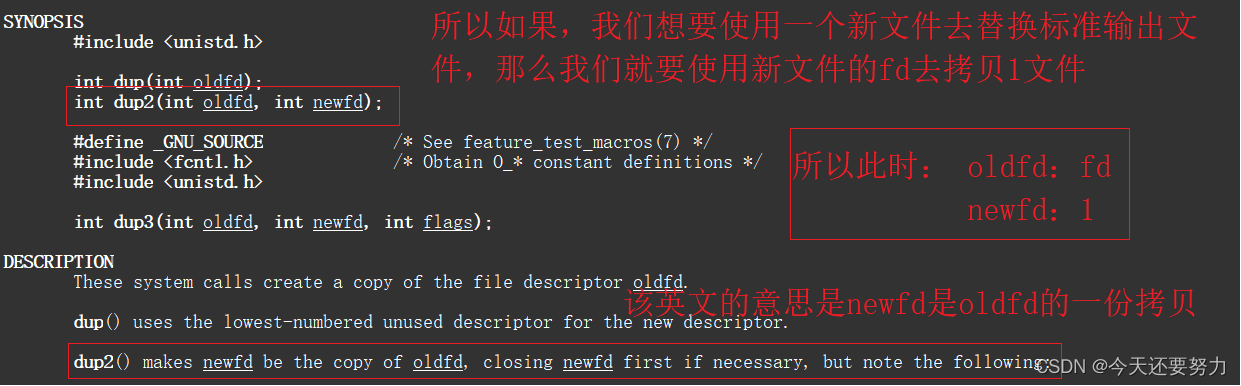
按照使用原理中的解释,表明newfd是oldfd的一份拷贝,并且因为我们是需要把新文件的fd去替换到标准输出文件(1),所以可以知道,最后剩下的肯定是新文件的fd,所以明白新文件的fd就是oldfd,具体使用如下图所示:

在上篇博客中,在讲一切皆文件的时候,我们已经浅浅的认识了一下缓冲区,所以我们承接以前的内容,来深入一下缓冲区,来看看缓冲区到底有什么用呢?
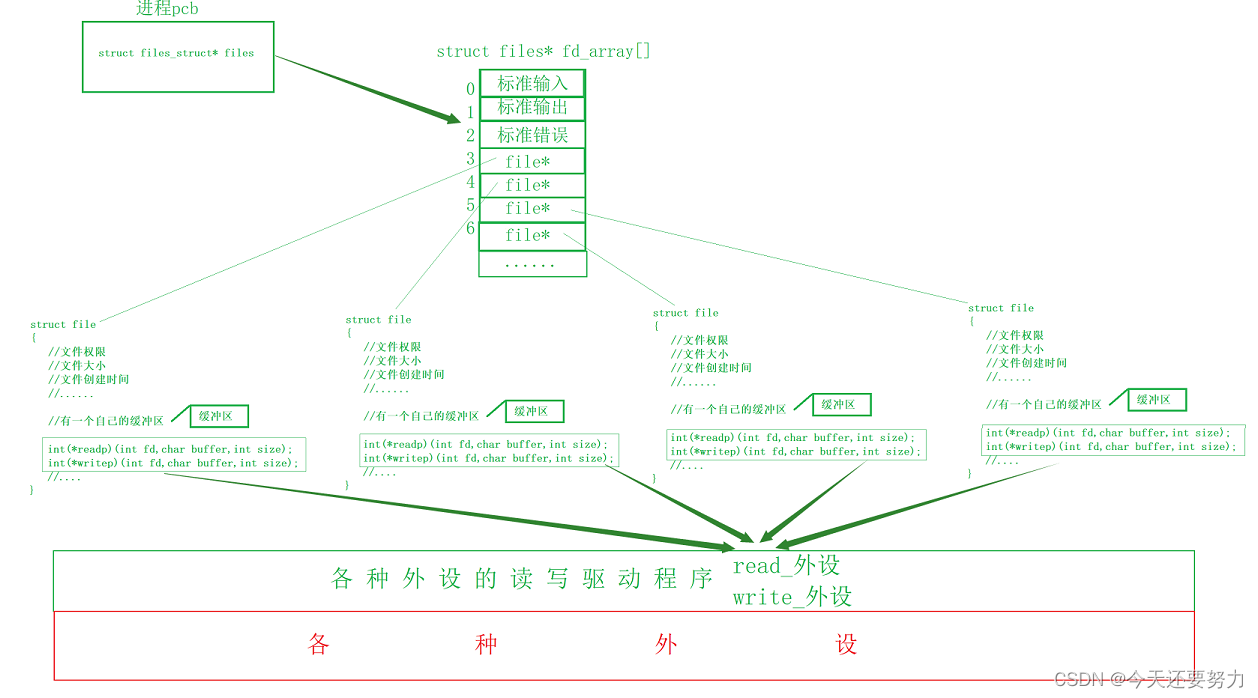
如上图,我们知道,在 struct file 文件对象中,是存在着缓冲区的概念的,并且明白,当操作系统需要写数据到相应的外设中,那么此时第一时间就是将数据拷贝到文件对象的文件缓冲区中,然后让文件对象中的相关函数指针去和外设的驱动程序进行交互,最终把文件对象中的文件缓冲区中的数据按照缓冲区对应的刷洗策略给刷新到外设中 ,所以让我们按照这个原理,来深入认识一下文件缓冲区吧!
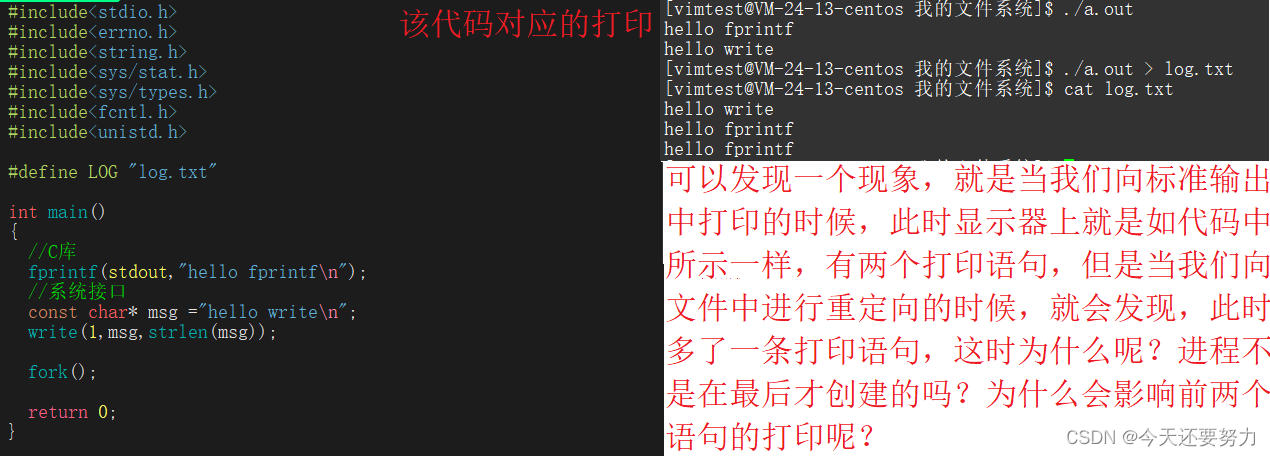
首先我们看一个现象,这个现象可以很好的证明缓冲区的刷新策略等知识!
如下图:
高能知识点:综合性非常高
要把FILE结构体和文件对象(struct file)搞明白,就要知道 struct FILE ,并不等于是 struct file ,其中,struct file是操作系统为了更好的管理文件,创建的文件对象,所以本质上,该结构体是属于系统级别的结构体,而struct FILE是用户调用系统调用接口,自己封装出来的一个结构体,本质上是属于用户级别,例:封装一个C库,然后使用C库中的库函数fprintf函数来调系统调用接口 write ,此时调用C库中的fprintf函数,它的第一步不是直接去调用系统调用,而是先malloc一个FILE结构体,因为如我们之前所说,在FILE结构体中才拥有指向文件描述符表的指针和缓冲区,所以fprintf函数想要调用write函数,前提一定是要有fd(通过指向文件描述符表的那个指针获得),其次是要有缓冲区,也就等于fprintf函数一定要有FILE结构体,然后才可以去调用write接口,并且调用write接口时,也是把FILE结构体中的fd文件描述符通过传参的形式传递给它,然后系统调用接口write才根据文件描述符找到对应的文件对象(struct file),最终把需要写入的数据拷贝到struct file文件对象对应的缓冲区中(该缓冲区目的:提高写入效率),并且根据文件对象中指向外设驱动程序的读写接口的函数指针实现将数据写入相应的外设
大致关系: C库( fprintf()->FILE->struct FILE(fd),缓冲区),表明缓冲区就是在C库中的,并且C库文件结构中,最主要的就是struct FILE结构体,因为该结构体中有缓冲区和指向文件描述符表的指针,也就是有fd,所以当我们在调用fprintf打印数据的时候,此时这个被打印的数据,并不是直接通过系统调用访问操作系统,然后找到文件描述符,然后找到对应的文件对象,然后通过文件对象写入到外设(显示器),而是只是把数据放到了对应的缓冲区当中,然后此时C库就会根据对应的缓冲区的刷新策略把缓冲区中的数据刷新到外设中(具体如何刷新到外设的)原理:调用系统调用接口write,然后根据FILE中的指向文件描述符表的指针,找到文件对象的fd,然后通过文件对象,将数据写入外设,(再次强调,FILE结构体不是文件对象结构体,虽然二者都有缓冲区,但是后者的缓冲区目的只是为了提高效率)
注意点: 就是fd是文件描述符,并不是指向文件描述符表的指针,所以此时跟C库是没什么关系的,本质上fd就是在FILE结构中的,原因,只有FILE结构中有指向文件描述符表的指针,所以FILE结构体就可以通过这个指针拿到对应的fd
C库中缓冲区的刷新策略:
(1.)全缓冲:在这种情况下,当填满标准I/O缓存后才进行实际I/O操作。全缓冲的典型代表是 对磁盘文件的读写 。
(2.)行缓冲:在这种情况下,当在输入和输出中遇到换行符时,执行真正的I/O操作。这时,我们输入的字符先存放在缓冲区,等按下回车键换行时才进行实际的I/O操作。典型代表是 标准输入(stdin) 和 标准输出(stdout) 。
(3.)无缓冲:也就是不进行缓冲,标准出错情况stderr是典型代表,这使得出错信息可以直接尽快地显示出来
所以此时可以明白,标准输入、标准输出的刷新策略是行缓冲,标准错误的刷新策略是无缓冲,普通文件采用的刷新策略是全缓冲
缓冲区最重要的意义:节省调用者的时间,本质因为系统调用需要花费时间
明白了上述的知识,所以此时关于缓冲区的第一个问题(也就是上图),就可以得到解释了,问题:为什么向标准输出中打印是两条语句,而向重定向文件中打印就是三条语句呢?原因,就是缓冲区的刷新策略,并且如果使用write接口,那么操作系统此时是直接将数据写入到文件对象中,但是如果使用的是fprintf,此时根据C库中FILE结构体中的缓冲区,此时就需要根据该缓冲区的刷新策略来把该数据刷新到文件对象中,并且此时因为,我们是向标准输出中打印,并且带了 \n ,所以此时根据C库缓冲区的原则,stdout是使用行缓冲(前提带 \n ),所以此时该fprintf函数打印的数据符合要求,所以直接就被写入到了文件对象中,然后我们再调用fork()函数创建子进程,那么此时就会因为接口都调用完了,数据也被写入完了,所以fork()函数没有现象,但是如果你是向一个重定义文件中写入,那么此时就会因为,C库中缓冲区对于普通文件的刷新策略是全缓冲(就是等buff数组满了再刷新到文件对象中),write因为是系统接口,所以同理,会直接将数据写入到文件对象,所以此时因为fprintf中的数据因为全缓冲,不能写入文件对象,所以当调用fork()函数创建了一个子进程之后,该进程也会执行对应的打印,所以导致最后出现了三条语句。
综上:缓冲区的设计非常的高级!
北京时间:2023/3/29/0:01

这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我正在尝试解析一个文本文件,该文件每行包含可变数量的单词和数字,如下所示:foo4.500bar3.001.33foobar如何读取由空格而不是换行符分隔的文件?有什么方法可以设置File("file.txt").foreach方法以使用空格而不是换行符作为分隔符? 最佳答案 接受的答案将slurp文件,这可能是大文本文件的问题。更好的解决方案是IO.foreach.它是惯用的,将按字符流式传输文件:File.foreach(filename,""){|string|putsstring}包含“thisisanexample”结果的
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称