项目中有几个batch需要检查所有的用户参与的活动的状态,以前是使用分页,一页一页的查出来到内存再处理,但是随着数据量的增加,效率越来越低。于是经过一顿搜索,了解到流式查询这么个东西,不了解不知道,这一上手,爱的不要不要的,效率贼高。项目是springboot 项目,持久层用的mybatis,整好mybatis的版本后,又研究了一下JPA的版本,做事做全套,最后又整了原始的JDBCTemplate 版本。废话不多说,代码如下:
a) service 层代码:
package com.example.demo.service;
import com.example.demo.bean.CustomerInfo;
import com.example.demo.mapper.UserMapper;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.cursor.Cursor;
import org.springframework.context.ApplicationContext;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.Resource;
@Slf4j
@Service
public class TestStreamQueryService {
@Resource
private ApplicationContext applicationContext;
@Resource
private UserMapper userMapper;
@Resource
private JdbcTemplate jdbcTemplate;
@Transactional
public void testStreamQuery(Integer status) {
mybatisStreamQuery(status);
}
private void mybatisStreamQuery(Integer status) {
log.info("waiting for query.....");
Cursor<CustomerInfo> customerInfos = userMapper.getCustomerInfo(status);
log.info("finish query!");
for (CustomerInfo customerInfo : customerInfos) {
//处理业务逻辑
log.info("===============>{}", customerInfo.getId());
}
}
}
需要注意的有两点:
1.是userMapper 返回的是一个Cursor类型,其实就是用游标。然后遍历这个cursor,mybatis就会按照你在userMapper里设置的fetchSize 大小,每次去从数据库拉取数据
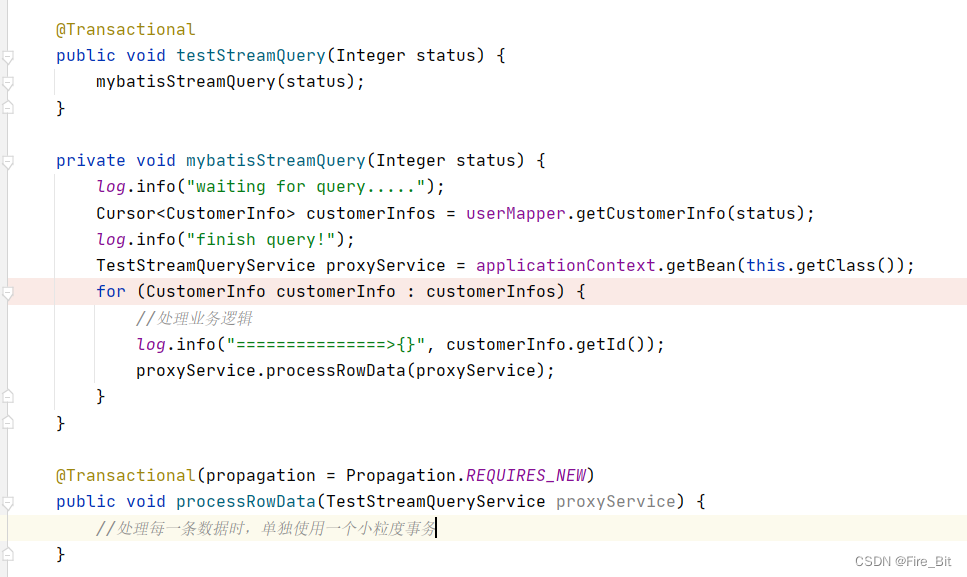
2.注意 testStreamQuery 方法上的 @transactional 注解,这个注解是用来开启一个事务,保持一个长连接(就是为了保持长连接采用的这个注解),因为是流式查询,每次从数据库拉取固定条数的数据,所以直到数据全部拉取完之前必须要保持连接状态。(顺便提一下,如果说不想让在这个testStreamQuery 方法内处理每条数据所作的更新或查询动作都在这个大事务内,那么可以另起一个方法 使用required_new 的事务传播,使用单独的事务去处理,使事务粒度最小化。如下图:)
b) mapper 层代码:
package com.example.demo.mapper;
import com.example.demo.bean.CustomerInfo;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.cursor.Cursor;
import org.springframework.stereotype.Repository;
@Mapper
@Repository
public interface UserMapper {
Cursor<CustomerInfo> getCustomerInfo(Integer status);
}
mapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.mapper.UserMapper">
<select id="getCustomerInfo" resultType="com.example.demo.bean.CustomerInfo" fetchSize="2" resultSetType="FORWARD_ONLY">
select * from table_name where status = #{status} order by id
</select>
</mapper>
UserMapper.java 无需多说,其实要注意的是mapper.xml中的配置:fetchSize 属性就是上一步说的,每次从数据库取多少条数据回内存。resultSetType属性需要设置为 FORWARD_ONLY, 意味着,查询只会单向向前读取数据,当然这个属性还有其他两个值,这里就不展开了。
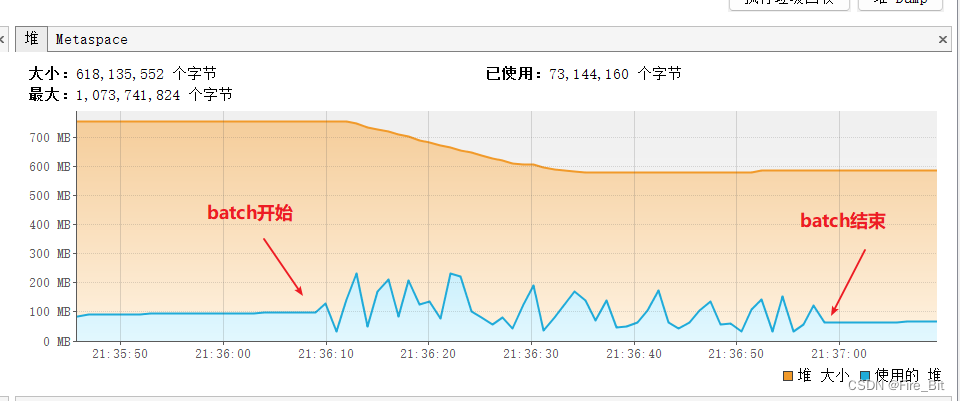
至此,springboot+mybatis 流式查询就可以用起来了,以下是执行结果截图:
c)读取200万条数据,每次fetchSize读取1000条,batch总用时50s左右执行完,速度是相当可以了,堆内存占用不超过250M,这里用的数据库是本地docker起的一个postgre, 远程数据库的话,耗时可能就不太一样了
a) service层代码:
package com.example.demo.service;
import com.example.demo.dao.CustomerInfoDao;
import com.example.demo.mapper.UserMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.ApplicationContext;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.Resource;
import javax.persistence.EntityManager;
import java.util.stream.Stream;
@Slf4j
@Service
public class TestStreamQueryService {
@Resource
private ApplicationContext applicationContext;
@Resource
private UserMapper userMapper;
@Resource
private JdbcTemplate jdbcTemplate;
@Resource
private CustomerInfoDao customerInfoDao;
@Resource
private EntityManager entityManager;
@Transactional(readOnly = true)
public void testStreamQuery(Integer status) {
jpaStreamQuery(status);
}
public void jpaStreamQuery(Integer status) {
Stream<com.example.demo.entity.CustomerInfo> stream = customerInfoDao.findByStatus(status);
stream.forEach(customerInfo -> {
entityManager.detach(customerInfo); //解除强引用,避免数据量过大时,强引用一直得不到GC 慢慢会OOM
log.info("====>id:[{}]", customerInfo.getId());
});
}
}
注意点:1. 这里的@transactional(readonly=true) 这里的作用也是保持一个长连接的作用,同时标注这个事务是只读的。
2. 循环处理数据时需要先:entityManager.detach(customerInfo); 解除强引用,避免数据量过大时,强引用一直得不到GC 慢慢会OOM。
b) dao层代码:
package com.example.demo.dao;
import com.example.demo.entity.CustomerInfo;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.QueryHints;
import org.springframework.stereotype.Repository;
import javax.persistence.QueryHint;
import java.util.stream.Stream;
import static org.hibernate.jpa.QueryHints.HINT_FETCH_SIZE;
@Repository
public interface CustomerInfoDao extends JpaRepository<CustomerInfo, Long> {
@QueryHints(value=@QueryHint(name = HINT_FETCH_SIZE,value = "1000"))
Stream<CustomerInfo> findByStatus(Integer status);
}注意点:1.dao方法的返回值是 Stream 类型
2.dao方法的注解:@QueryHints(value=@QueryHint(name = HINT_FETCH_SIZE,value = "1000")) 这个注解是设置每次从数据库拉取多少条数据,自己可以视情况而定,不可太大,反而得不偿失,一次读取太多数据数据库也是很耗时间的。。。
自此springboot + jpa 流式查询代码就贴完了,可以happy了,下面是执行结果:
c) batch读取两百万条数据,堆内存使用截图:
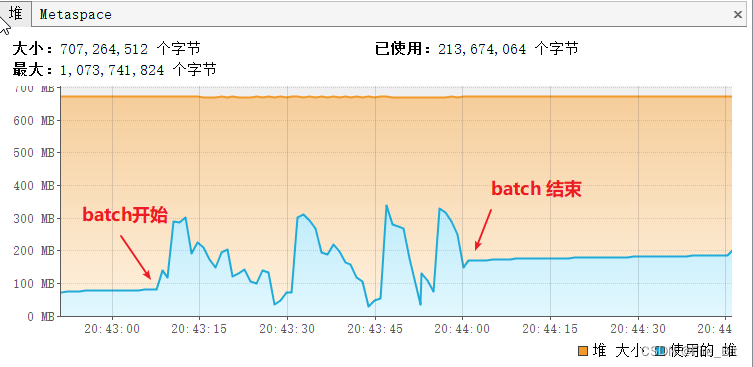
每次fetchSize拉取1000条数据,可以看到内存使用情况:初始内存不到100M,batch执行过程中最高内存占用300M出头然后被GC。读取效率:不到一分钟执行完(处理每一条数据只是打印一下id),速度还是非常快的。
d) 读取每一条数据时,不使用 entityManager.detach(customerInfo),内存使用截图:
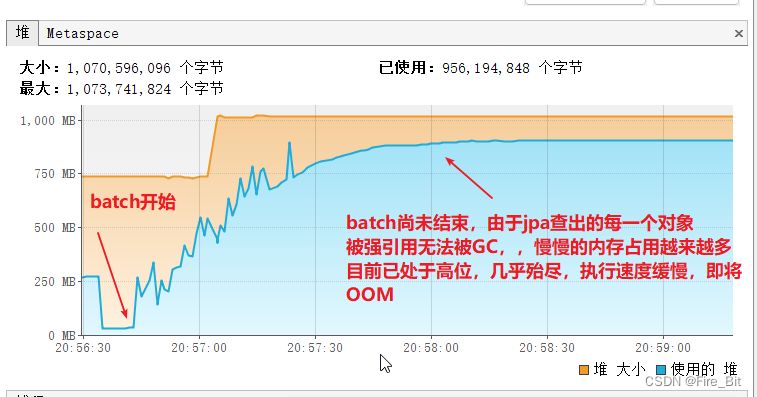
最终OOM了,这里的entityManager.detach(customerInfo) 很关键。
其实这种方式就是最原始的jdbc的方式,代码侵入性很大,逼不得已也不会使用
a) 上代码:
package com.example.demo.service;
import com.example.demo.dao.CustomerInfoDao;
import com.example.demo.mapper.UserMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.ApplicationContext;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import javax.persistence.EntityManager;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
@Slf4j
@Service
public class TestStreamQueryService {
@Resource
private ApplicationContext applicationContext;
@Resource
private UserMapper userMapper;
@Resource
private JdbcTemplate jdbcTemplate;
@Resource
private CustomerInfoDao customerInfoDao;
@Resource
private EntityManager entityManager;
public void testStreamQuery(Integer status) {
jdbcStreamQuery(status);
}
private void jdbcStreamQuery(Integer status) {
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
conn = jdbcTemplate.getDataSource().getConnection();
conn.setAutoCommit(false);
pstmt = conn.prepareStatement("select * from customer_info where status = " + status + " order by id", ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
pstmt.setFetchSize(1000);
pstmt.setFetchDirection(ResultSet.FETCH_FORWARD);
rs = pstmt.executeQuery();
while (rs.next()) {
long id = rs.getLong("id");
String name = rs.getString("name");
String email = rs.getString("email");
int sta = rs.getInt("status");
log.info("=========>id:[{}]", id);
}
} catch (SQLException throwables) {
throwables.printStackTrace();
} finally {
try {
rs.close();
pstmt.close();
conn.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
}
b) 执行结果:200万数据不到50秒执行完,内存占用最高300M

自此,针对不同的持久层框架, 使用不同的流式查询,其实本质是一样的,归根结底还是驱动jdbc做事情。以上纯个人见解,若有不当之处,请不吝指出,共同进步!
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
我目前正在尝试了解RoR。我将两个字符串传递到我的Controller中。一个是随机的十六进制字符串,另一个是电子邮件。该项目用于对数据库进行简单的电子邮件验证。我遇到的问题是当我输入如下内容来测试我的页面时:http://signup.testsite.local/confirm/da2fdbb49cf32c6848b0aba0f80fb78c/bob.villa@gmailcom我在:email的参数散列中得到的全部是'bob'。我在gmail和com之间留下了.,因为那样会导致匹配根本不起作用。我的路由匹配如下:match"confirm/:code/:email"=>"conf
我正在寻找一种方便实用的方法来将编码值添加到Ruby中的URL查询字符串。目前,我有:require'open-uri'u=URI::HTTP.new("http",nil,"mydomain.example",nil,nil,"/tv",nil,"show="+URI::encode("Rosie&Jim"),nil)pu.to_s#=>"http://mydomain.example/tv?show=Rosie%20&%20Jim"这不是我要找的,因为我需要得到“http://mydomain.example/tv?show=Rosie%20%26%20Jim”,这样show=值就
我正在尝试将种子数据从CSV文件加载到我的Rails应用程序中。我最初安装了fastercsvgem,却发现从ruby1.9开始,fastercsv已被弃用,取而代之的是CSV库。所以在收到一个非常有用的错误告诉我切换后,我切换到CSV。然而,现在我遇到了最奇怪的现象,当我加载数据时一切看起来都很正常,但我似乎无法查询字符串字段。字符串字段由看似正确的字符串填充,但我无法访问它们。我可以查询任何数字字段,结果将返回,但不会返回字符串字段。我尝试使用引号的定界符,但无济于事。我什至从我的csv文件中删除了所有引号,但我仍然无法查询字符串字段。下面是我的代码,以及一些来自Rails控制