【温馨提示】这里使用jdk8,这里不要用其他jdk了,可能会出现一些其他问题的,我用jdk11有些包就找不到,好像jdk9都不行
http://www.oracle.com/technetwork/java/javase/downloads/index.html
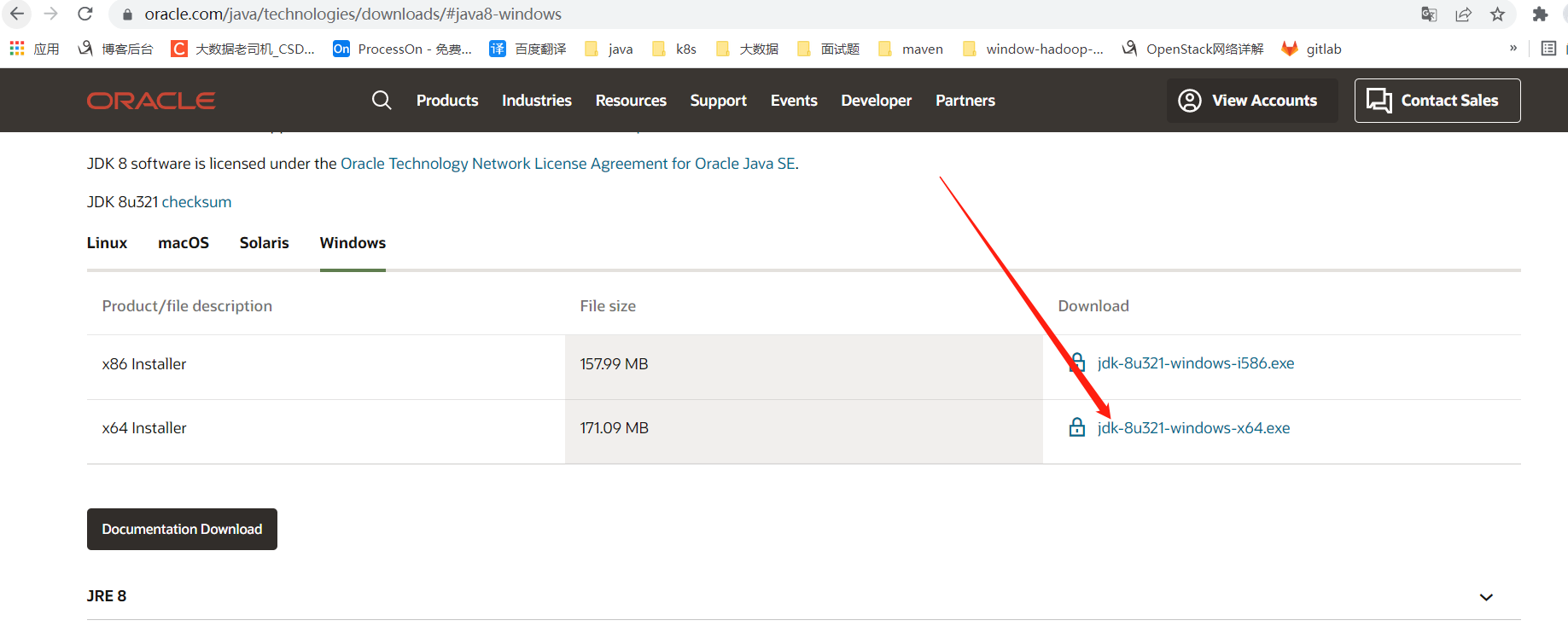
按正常下载是需要先登录的,这里提供一个不用登录下载的方法
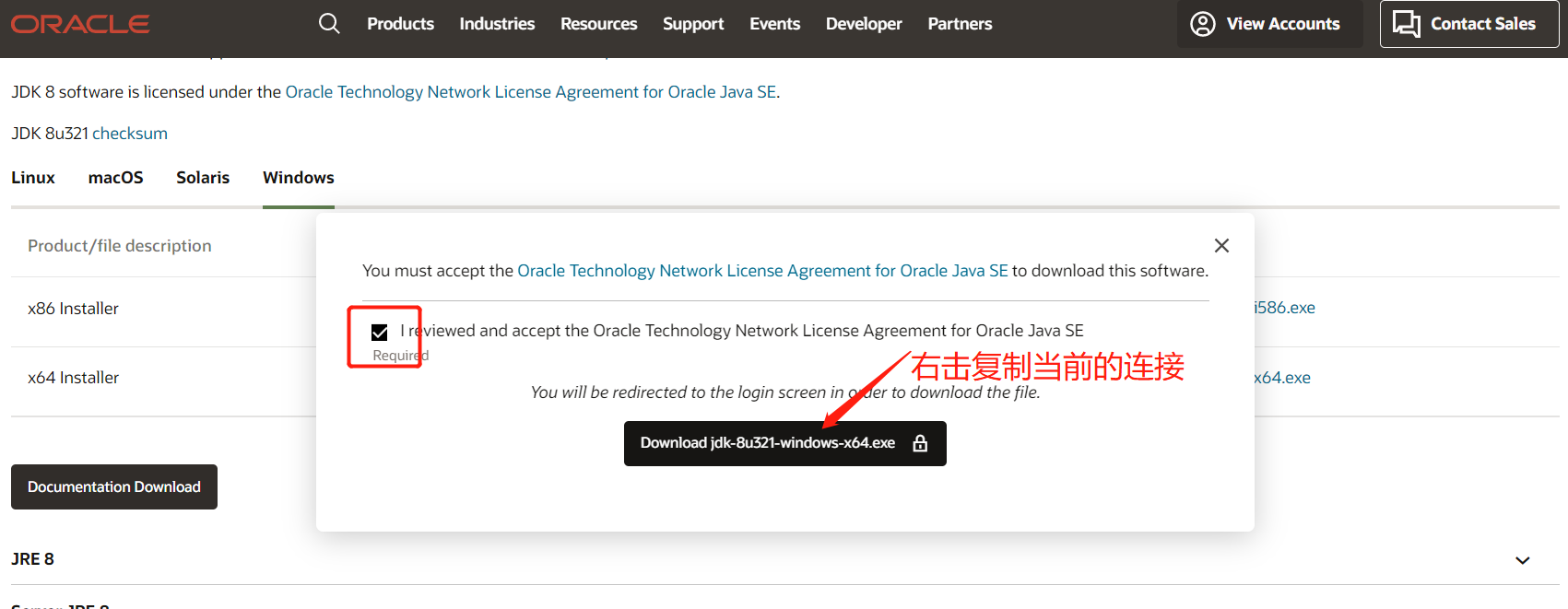
连接如下:https://www.oracle.com/webapps/redirect/signon?nexturl=https://download.oracle.com/
otn/java/jdk/8u321-b07/df5ad55fdd604472a86a45a217032c7d/jdk-8u321-windows-x64.exe
其实只要后半部分,再把标红的otn换成otn-pub就可以直接下载了
下载完后就是傻瓜式安装了

$ java -version

官网下载:https://hadoop.apache.org/release/3.1.3.html
下载各种版本地址入口:https://hadoop.apache.org/release.html

下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz

验证
$ hadoop --version

data和tmp目录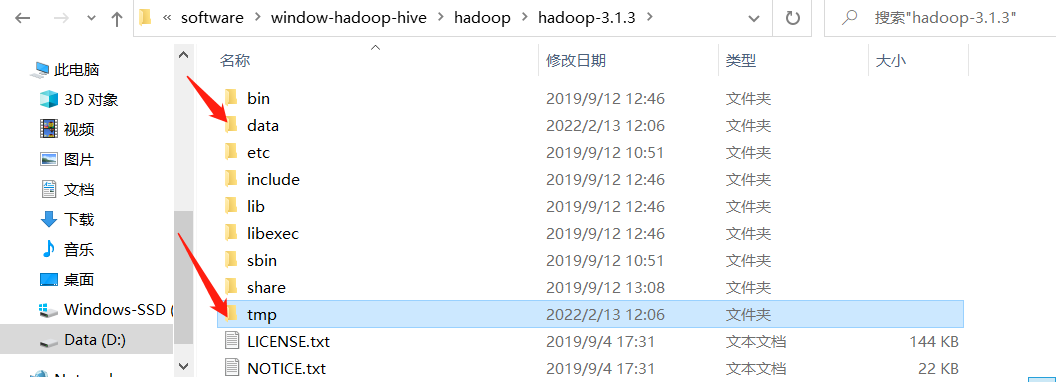
data文件夹下面再创建namenode和datanode目录
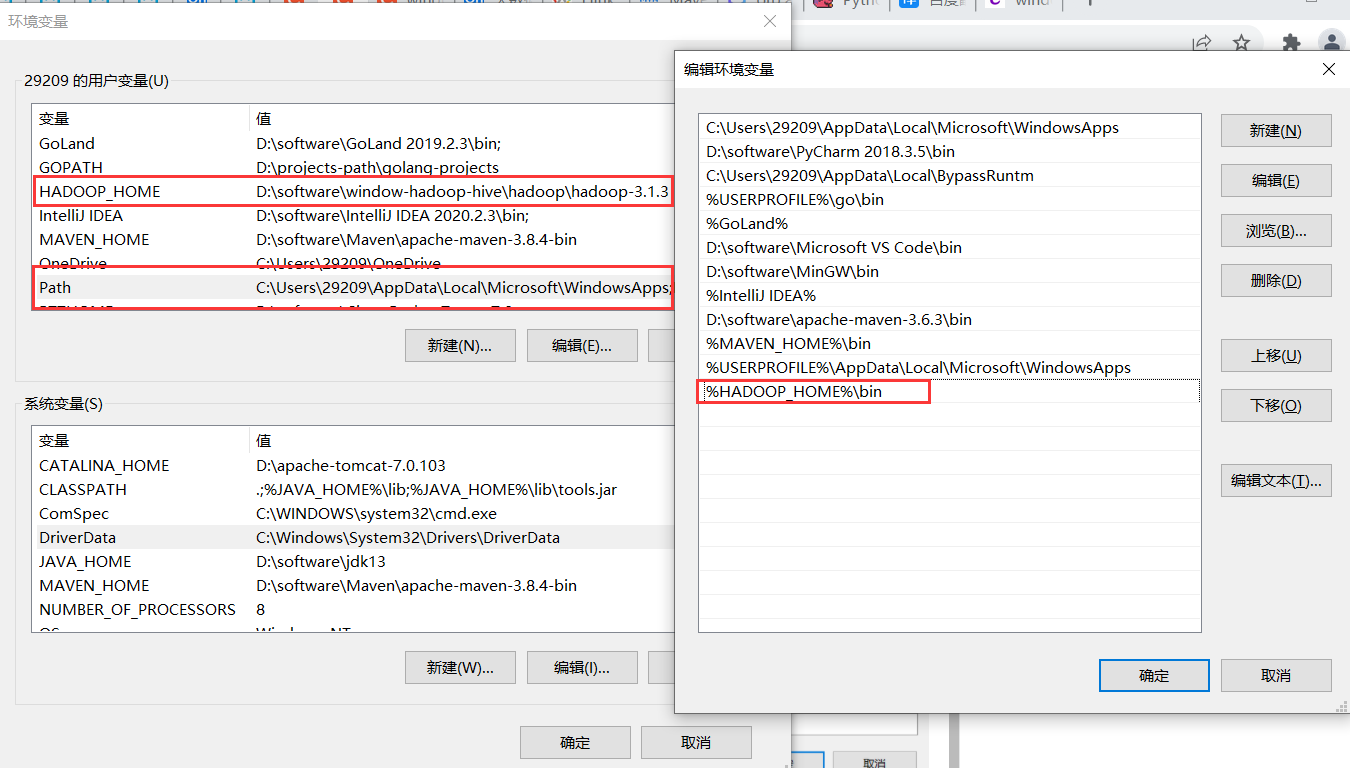
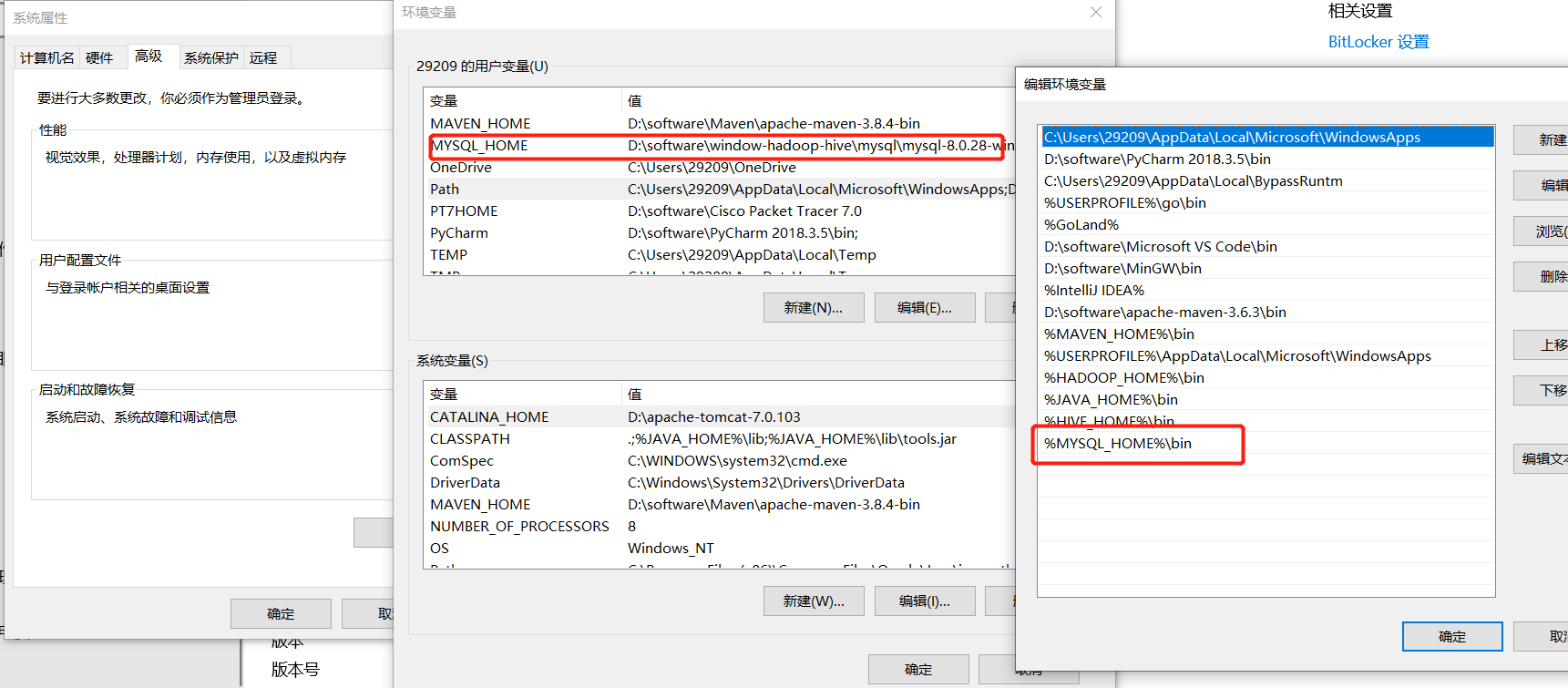
配置文件目录:$HADOOP_HOME\etc\hadoop
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/software/window-hadoop-hive/hadoop/hadoop-3.1.3/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/software/window-hadoop-hive/hadoop/hadoop-3.1.3/data/datanode</value>
</property>
</configuration>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>
$ hdfs namenode -format
打开winutils文件,把里面的bin文件复制到hadoop的安装路径,替换掉原来的bin文件
下载:apache-hadoop-3.1.0-winutils
也可以去GitHub上下载其它对应版本


当然如果自己有时间也有兴趣的话,可以自己去编译
把它复制到上一级目录,即
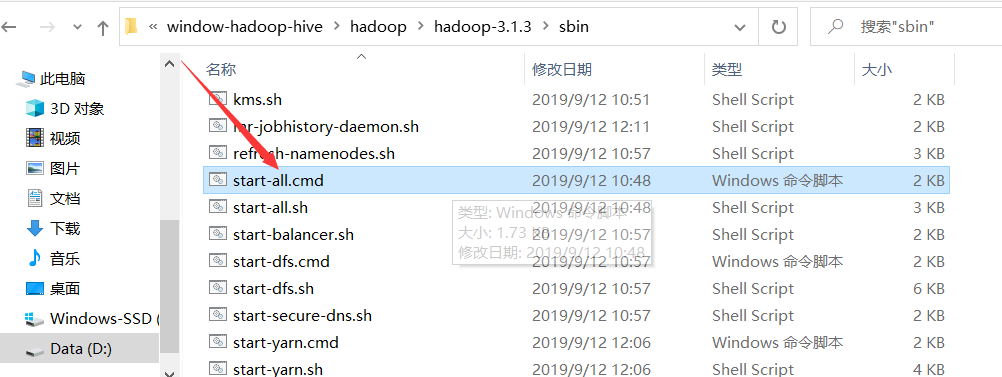
【温馨提示】回到hadoop安装bin目录下,右击
以管理员的身份运行start-all.cmd文件,要不然会报权限问题
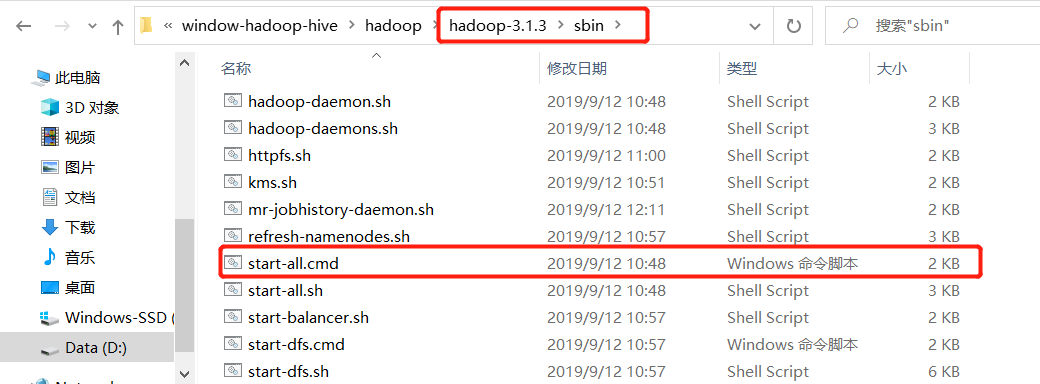
出现下面四个窗口就是 成功了,注意每个窗口标题的后面的名称,比如yarn nodemanager,如果没有出现则是失败
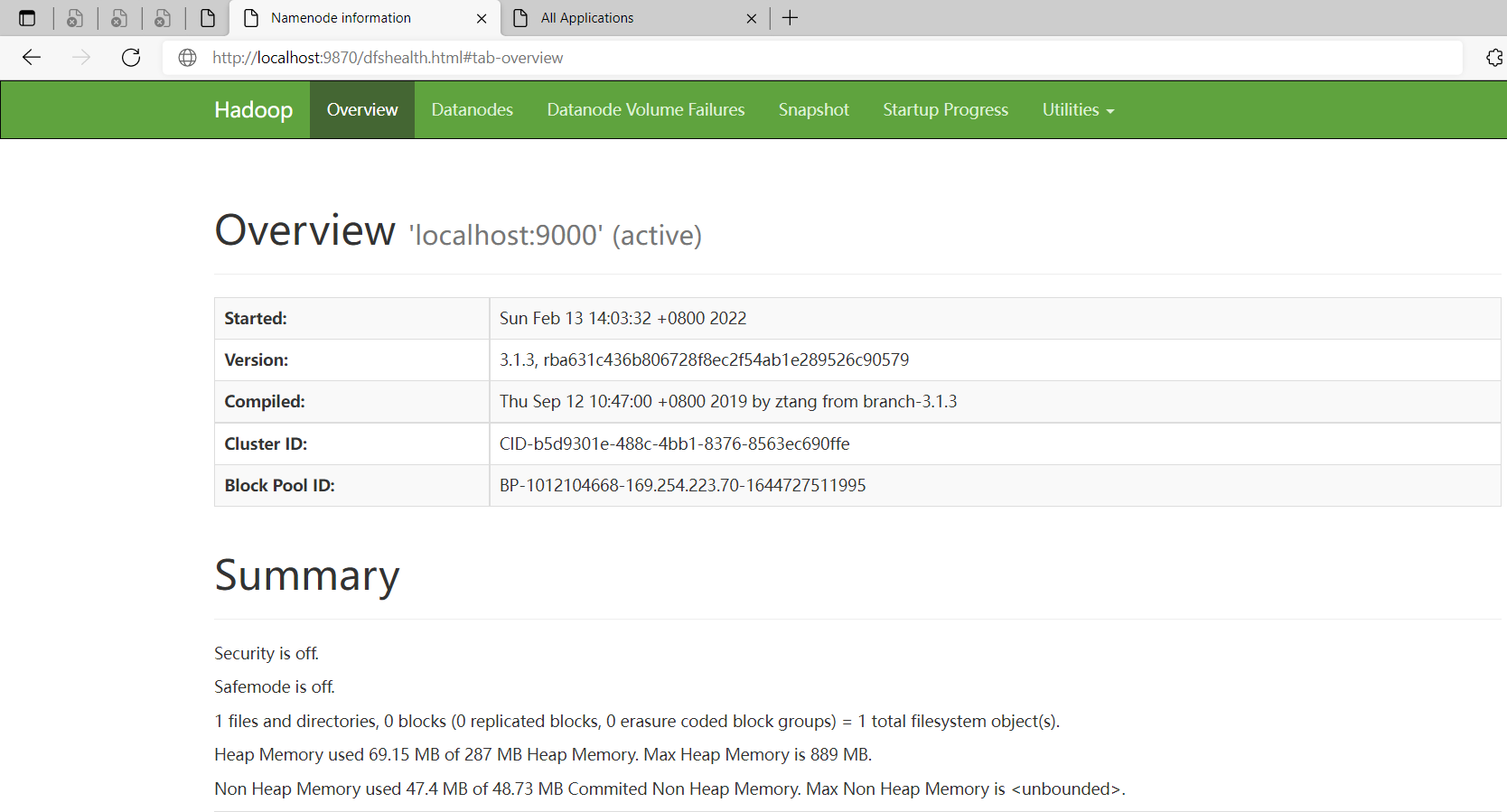
hdfs web 地址:http://localhost:9870/
yarn web 地址:http://localhost:8088/
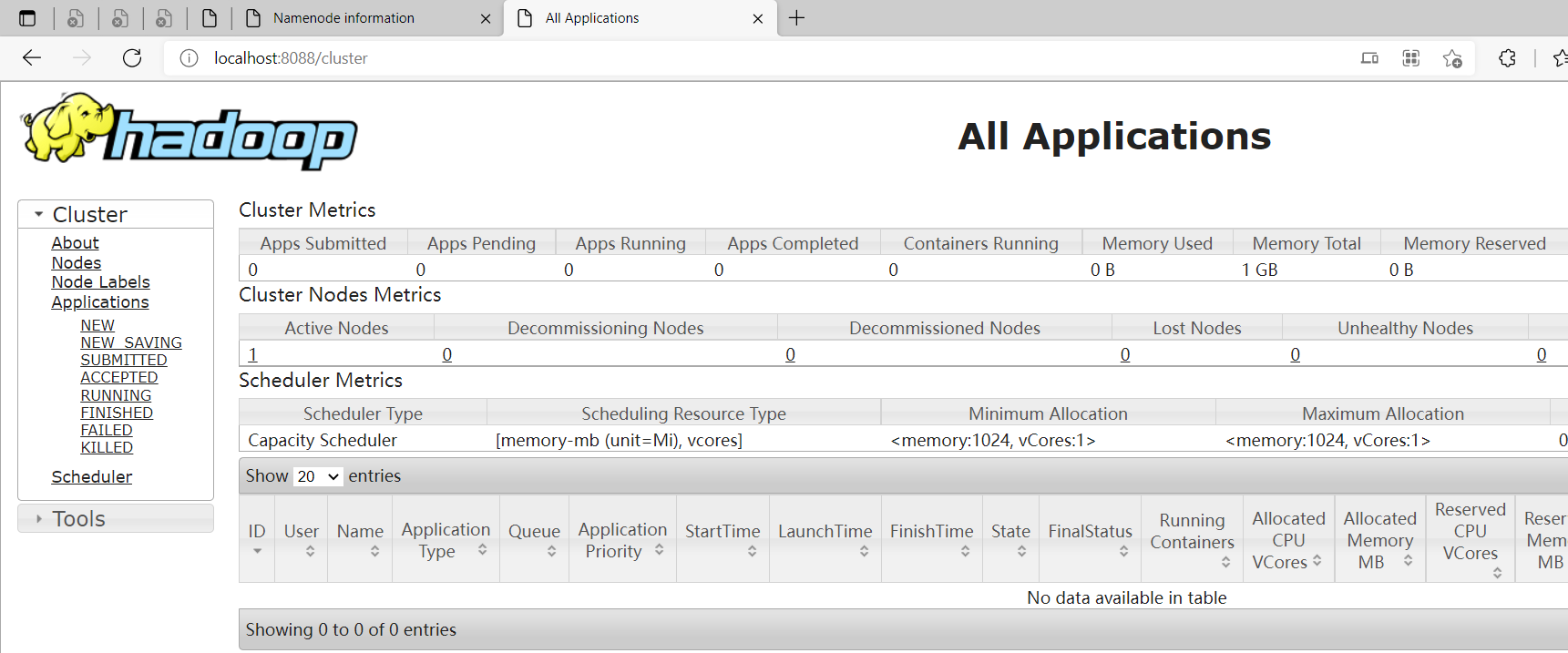
到此为止window版本的hadoop就安装成功了
各版本下载地址:http://archive.apache.org/dist/hive
这选择最新版本

hive 3.1.2版本下载地址:http://archive.apache.org/dist/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz

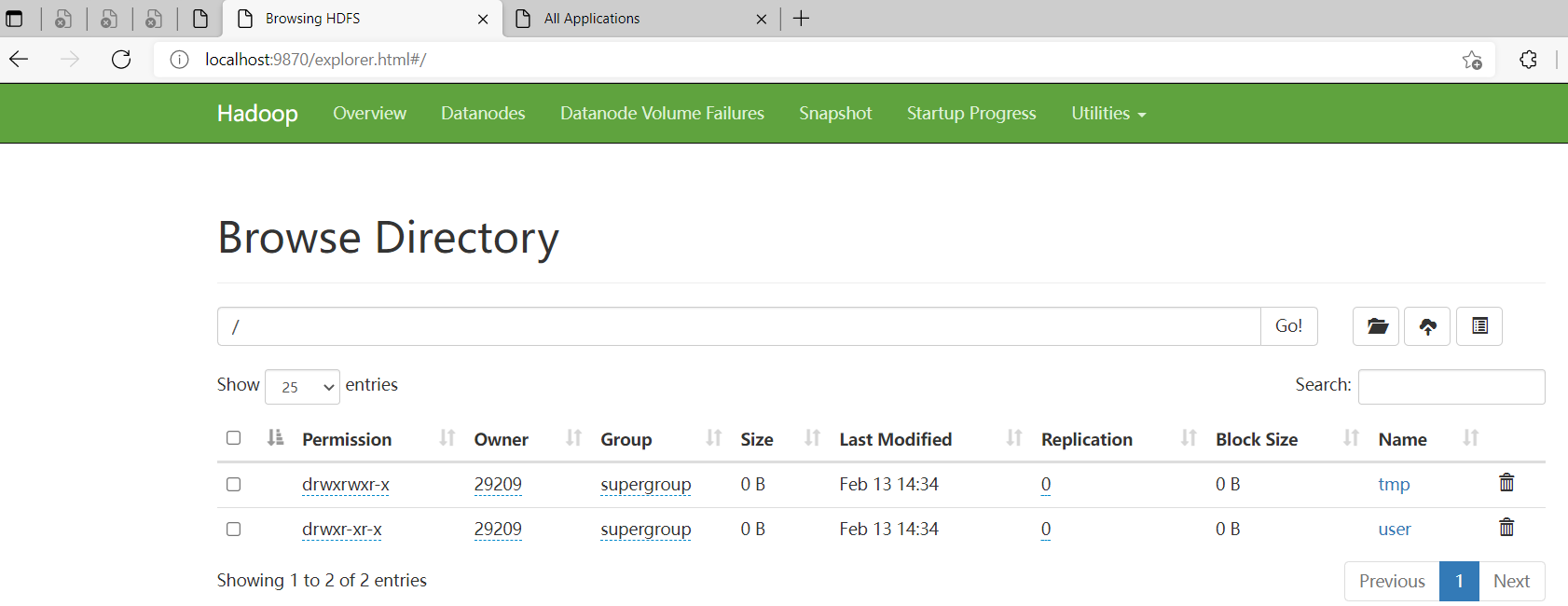
$ hadoop fs -mkdir /tmp
$ hadoop fs -mkdir /user/
$ hadoop fs -mkdir /user/hive/
$ hadoop fs -mkdir /user/hive/warehouse
$ hadoop fs -chmod g+w /tmp
$ hadoop fs -chmod g+w /user/hive/warehouse

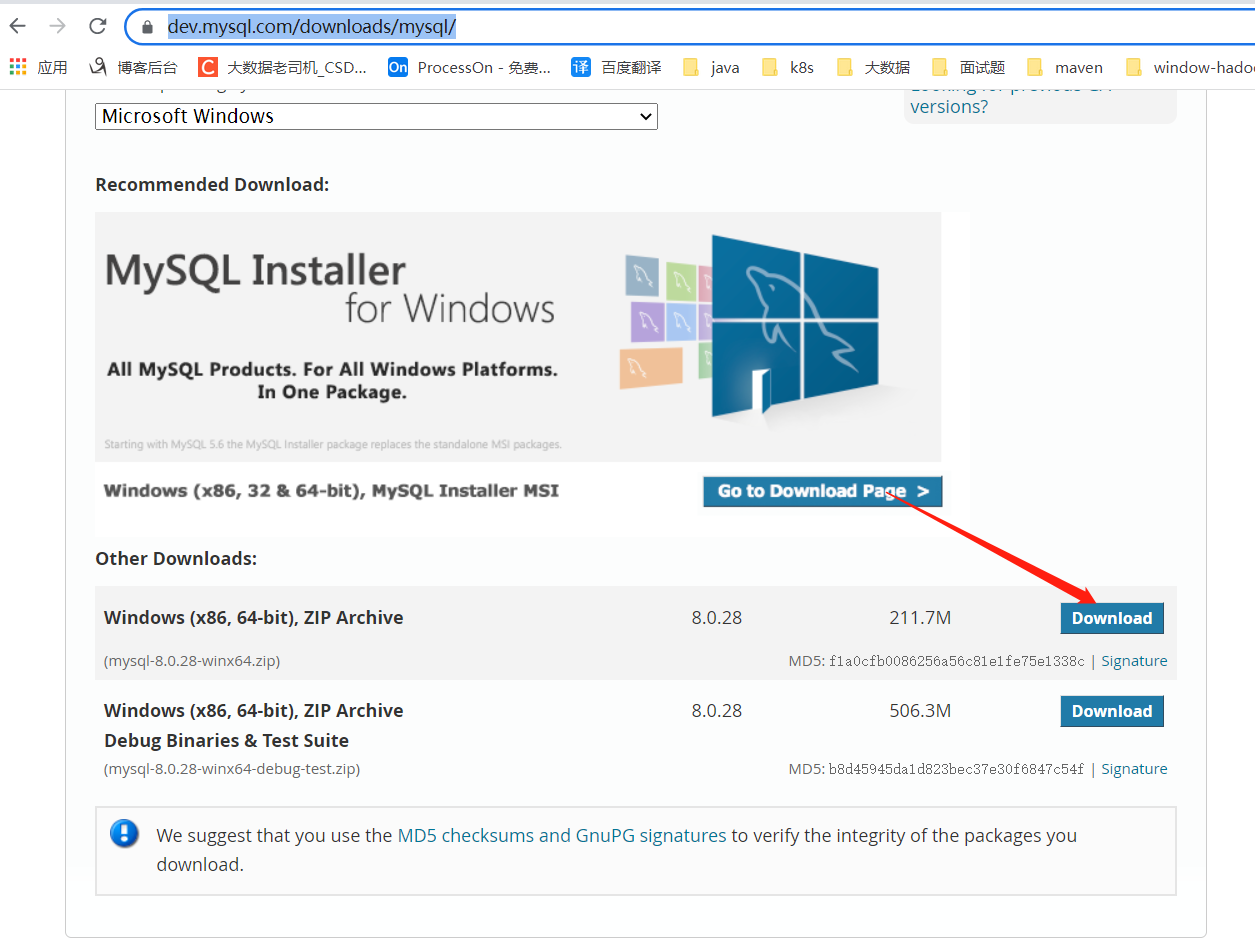
官网下载:https://dev.mysql.com/downloads/mysql/

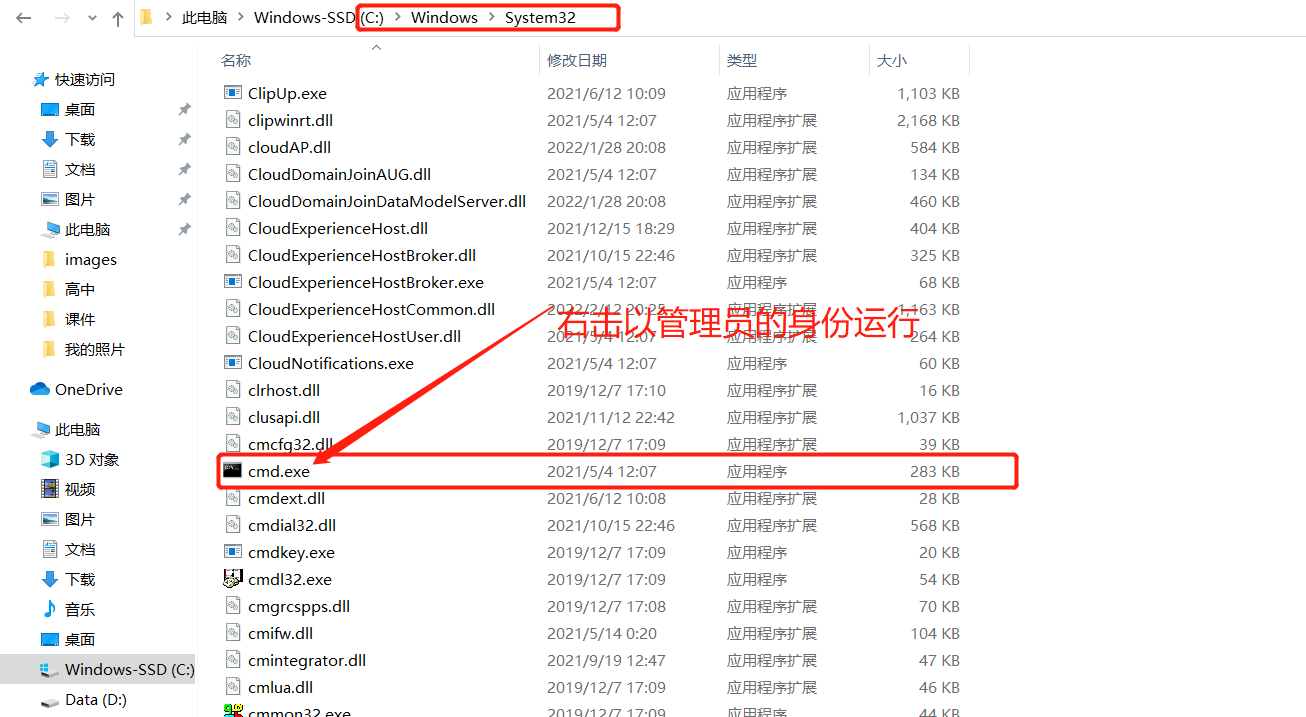
【温馨提示】右键以管理员身份运行cmd,否则在安装时会报权限的错,会导致安装失败的情况。

# 切换到mysql bin目录下执行
# cd D:\software\window-hadoop-hive\mysql\mysql-8.0.28-winx64\bin
# d:
$ mysqld --initialize --console

$ mysqld --install mysql

$ net start mysql

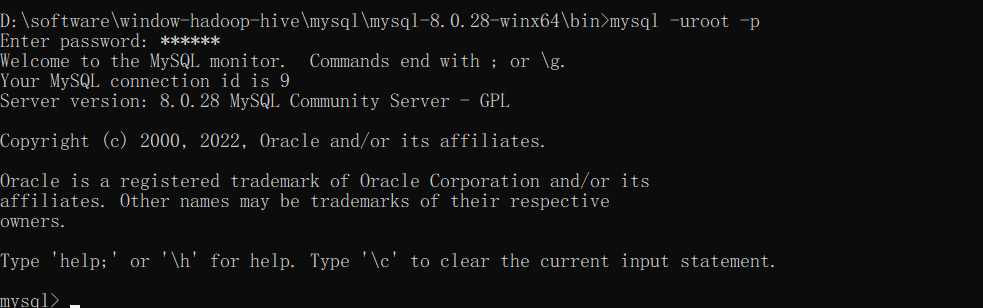
$ mysql -uroot -p
#输入上面初始化的密码
$ net stop mysql
$ mysqld --console --skip-grant-tables --shared-memory
mysql【温馨提示】由于上面的命令行被mysql的服务给占用,我们得重新开启一个新的命令行
$ mysql
$ update user set authentication_string = '' where user='root' ;
net start mysql 重新启动mysql服务$ net start mysql
mysql -uroot -p 然后按enter键,输入密码继续按enter键(这里密码已经被清空)$ mysql -uroot -p
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
FLUSH PRIVILEGES;

【问题】如果mysql工具出现错误:
Authentication plugin 'caching_sha2_password' cannot be loaded
【原因】
很多用户在使用Navicat Premium 12连接MySQL数据库时会出现Authentication plugin 'caching_sha2_password' cannot be loaded的错误。
出现这个原因是mysql8 之前的版本中加密规则是mysql_native_password,而在mysql8之后,加密规则是caching_sha2_password, 解决问题方法有两种,一种是升级navicat驱动,一种是把mysql用户登录密码加密规则还原成mysql_native_password.
【解决】
# 管理员权限运行命令
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';
FLUSH PRIVILEGES;
$ mysql -uroot -p
配置文件目录D:\software\window-hadoop-hive\hive\apache-hive-3.1.2-bin\conf有4个默认的配置文件模板拷贝成新的文件名
hive-default.xml.template----->hive-site.xml
hive-env.sh.template----->hive-env.sh
hive-exec-log4j.properties.template----->hive-exec-log4j2.properties
hive-log4j.properties.template----->hive-log4j2.properties
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
--><configuration>
<!--hive的临时数据目录,指定的位置在hdfs上的目录-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<!--hive的临时数据目录,指定的位置在hdfs上的目录-->
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
<description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.</description>
</property>
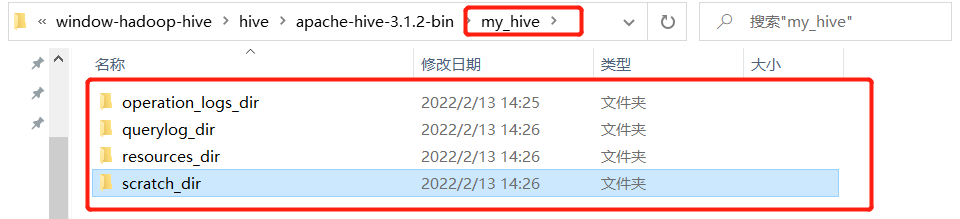
<!-- scratchdir 本地目录 -->
<property>
<name>hive.exec.local.scratchdir</name>
<value>D:/software/window-hadoop-hive/hive/apache-hive-3.1.2-bin/my_hive/scratch_dir</value>
<description>Local scratch space for Hive jobs</description>
</property>
<!-- resources_dir 本地目录 -->
<property>
<name>hive.downloaded.resources.dir</name>
<value>D:/software/window-hadoop-hive/hive/apache-hive-3.1.2-bin/my_hive/resources_dir/${hive.session.id}_resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<!-- querylog 本地目录 -->
<property>
<name>hive.querylog.location</name>
<value>D:/software/window-hadoop-hive/hive/apache-hive-3.1.2-bin/my_hive/querylog_dir</value>
<description>Location of Hive run time structured log file</description>
</property>
<!-- operation_logs 本地目录 -->
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>D:/software/window-hadoop-hive/hive/apache-hive-3.1.2-bin/my_hive/operation_logs_dir</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>
<!-- 数据库连接地址配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?serverTimezone=UTC&useSSL=false&allowPublicKeyRetrieval=true</value>
<description>
JDBC connect string for a JDBC metastore.
</description>
</property>
<!-- 数据库驱动配置 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!-- 数据库用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<!-- 数据库访问密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<!-- 解决 Caused by: MetaException(message:Version information not found in metastore. ) -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
<!-- 自动创建全部 -->
<!-- hive Required table missing : "DBS" in Catalog""Schema" 错误 -->
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
<description>Auto creates necessary schema on a startup if one doesn't exist. Set this to false, after creating it once.To enable auto create also set hive.metastore.schema.verification=false. Auto creation is not recommended for production use cases, run schematool command instead.</description>
</property>
</configuration>
# Set HADOOP_HOME to point to a specific hadoop install directory
export HADOOP_HOME=D:\software\window-hadoop-hive\hadoop\hadoop-3.1.3
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=D:\software\window-hadoop-hive\hive\apache-hive-3.1.2-bin\conf
# Folder containing extra libraries required for hive compilation/execution can be controlled by:
export HIVE_AUX_JARS_PATH=D:\software\window-hadoop-hive\hive\apache-hive-3.1.2-bin\lib
【温馨提示】2.2.0版本之后就不提供cmd相关文件了,所以得去下载apache-hive-2.2.0-src.tar.gz,把这个版本里的bin目录文件替换到hive安装bin目录下。
这里将mysql-connector-java-*.jar拷贝到安装目录lib下
下载地址:https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.28/mysql-connector-java-8.0.28.jar

$ hive --service schematool -dbType mysql -initSchema


执行指令:stall-all.cmd,上面其实已经验证过了,启动是没问题的
$ hive --service metastore
另起一个cmd窗口验证
$ hive
create databases test;
show databases;
【温馨提示】hive命令会慢慢不再使用了,以后就用beeline,如果对hive不了解的,可以看我之前的文章:大数据Hadoop之——数据仓库Hive
在Hive服务安装目录的%HIVE_HOME%\conf\hive-site.xml配置文件中添加以下配置:
<!-- host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>localhost</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>
<!-- hs2端口 默认是10000,为了区别,我这里不使用默认端口-->
<property>
<name>hive.server2.thrift.port</name>
<value>10001</value>
</property>
在Hadoop服务安装目录的%HADOOP_HOME%\etc\hadoop\core-site.xml配置文件中添加以下配置:
<property>
<name>hadoop.proxyuser.29209.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.29209.groups</name>
<value>*</value>
</property>
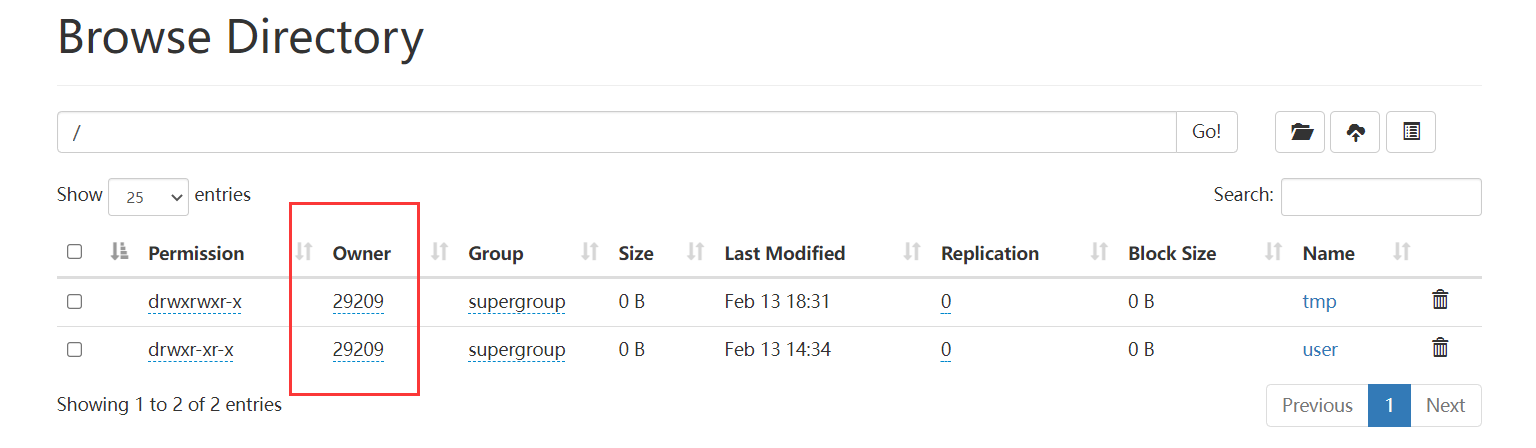
【注意】hadoop.proxyuser.29209.hosts和hadoop.proxyuser.29209.hosts,其中
29209是连接beeline的用户,将29209替换成自己的用户名即可,其实这里的用户就是我本机的用户,也是上面创建文件夹的用户,这个用户是什么不重要,它就是个超级代理。
启动hiveserver2 之前必须重启hive服务
$ hive --service metastore
$ hive --service hiveserver2
【问题】java.lang.NoClassDefFoundError: org/apache/tez/dag/api/SessionNotRunning
【解决】在hive 配置文件hive-site.xml添加如下配置:
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
<description>Whether HiveServer2 Active/Passive High Availability be enabled when Hive Interactive sessions are enabled.This will also require hive.server2.support.dynamic.service.discovery to be enabled.</description>
</property>
重启hiveserver2
$ hive --service metastore
$ hive --service hiveserver2
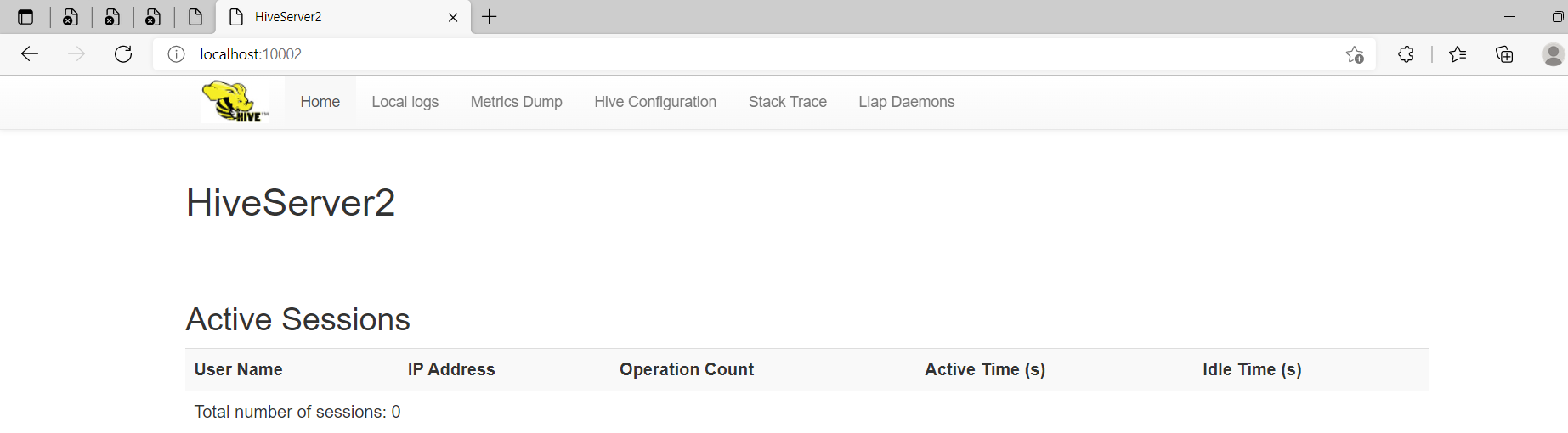
HiveServer2 web:http://localhost:10002/
$ beeline
【问题一】Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hive/jdbc/JdbcUriParseException
【解决】Hadoop缺少hive-jdbc-***.jar,将Hive安装目录下的lib文件夹中的hive-jdbc-3.1.2.jar包复制到Hadoop安装目录\share\hadoop\common\lib下

【问题二】Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/hive/conf/HiveConf
【解决】Hive安装目录下,将hive-common-3.1.2.jar复制到Hadoop安装目录的\share\hadoop\common\lib下

$ beeline
!connect jdbc:hive2://localhost:10001
29209
# 下面这句跟上面等价,都可以登录
$ %HIVE_HOME%\bin\beeline.cmd -u jdbc:hive2://localhost:10001 -n 29209
【问题三】Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hive/service/cli/HiveSQLException。
【解决】把Hive安装目录下,将hive-service-3.1.2.jar复制到Hadoop安装目录的\share\hadoop\common\lib下。
再重启登录
$ hive --service metastore
$ hive --service hiveserver2
$ %HIVE_HOME%\bin\beeline.cmd -u jdbc:hive2://localhost:10001 -n 29209

正常登录,一切OK,更多关于大数据的知识,请耐心等待~
我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m