如果你对这篇文章感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。
这些生成式 AI 的整体功能为:输入「文字」,返回「图像」,即 Text-to-image Generator:

生成器的内部框架如下所示:

三个模块通常是分开训练,再组合起来,得到 Text-to-image Generator。
上述框架为通用框架,即均包含上述三个模块,例如 Stable Diffusion:

DALL-E series:

Imagen:

GPT、Bert 均可当作文字 Encoder,其对最终结果的影响非常大。如下图所示(来自 Imagen 论文实验图):

上述结果中的 FID 用于衡量生成图片的好坏,即利用一个 CNN 网络 (Inception Network),得到一系列原始图像 (x) 与其对应生成图像 (g) 的特征表示,并假设该特征表示服从高斯分布,因此可以得到原始图像的高斯分布
N
(
μ
x
,
Σ
x
)
\mathcal{N}(\mu_x,\Sigma_x)
N(μx,Σx) 与生成图像的高斯分布
N
(
μ
g
,
Σ
g
)
\mathcal{N}(\mu_g,\Sigma_g)
N(μg,Σg),并将两个分布之间的 Fréchet distance 作为最终的 FID 结果(越小越好),即:
FID
(
x
,
g
)
=
∥
μ
x
−
μ
g
∥
2
2
+
Tr
(
Σ
x
+
Σ
g
−
2
(
Σ
x
Σ
g
)
1
2
)
.
\text{FID}(x,g)=\|\mu_x-\mu_g\|_2^2 + \operatorname{Tr}\left(\Sigma_x+\Sigma_g-2\left(\Sigma_x \Sigma_g\right)^{\frac{1}{2}}\right).
FID(x,g)=∥μx−μg∥22+Tr(Σx+Σg−2(ΣxΣg)21).
上述的 FID-10K 表示采样 10K 张图片后,计算 FID,因此 FID 的计算需要大量图片。

CLIP 是一个使用了 400 million image-text paris 训练得到的模型,该模型可以用于给 (Text, Generated Image) 打分,即将 Text, Image 分别丢进 Text Encoder 和 Image Encoder 中,其产生的 Embedding 越相近,CLIP Score 越高。

Generation Model 的训练需要 (Text, Image) 成对的数据,但 Decoder 的训练不需要文字资料,因此可供其训练的数据是更多的。
如果 Decoder 的输入是图片的压缩版本,即小图(例如 Imagen),则其训练过程为:将任意一张图片降采样得到一张小图,随后使用(小图,原图)的 pair 进行训练,如下所示:

如果 Decoder 的输入 Latent Representation(例如 Stable Diffusion 与 DALL-E),则训练过程为:训练一个 Auto-encoder,并将其中的 Decoder 作为框架中的模块。
Auto-encoder 的训练过程也非常直接,其 Encoder 负责得到图片的 Latent Representation,Decoder 负责根据 Latent Representation 生成对应图片,训练目标是原始图片与生成的图片越接近越好。
通常来说原图尺寸为 (H, W, 3),Latent Representation 的大小为 (h, w, c),其中 h 与 w 分别小于 H 和 W。

在 Diffusion Model 中,我们不断地在图片上加噪音,得到一张随机图后,再逐步地去噪,最终训练出去噪的模型,如下所示:

而在 Generation Model 中,噪声不是加在图片上,而是加在中间产物上,即 Decoder 的输入 Latent Representation 上,如下所示:

随后训练一个 Noise Predictor,输入为「第 x 步 + 第 x 步对应的加噪结果 + Text Embedding」,输出为第 x 步所加的噪声。

最后在生成图片时,输入为「Text Embedding + 随机高斯噪声」,每次识别出具体的噪声,再一步一步执行去噪,即可得到最终的 Latent Representation,再输入至 Decoder 即可。
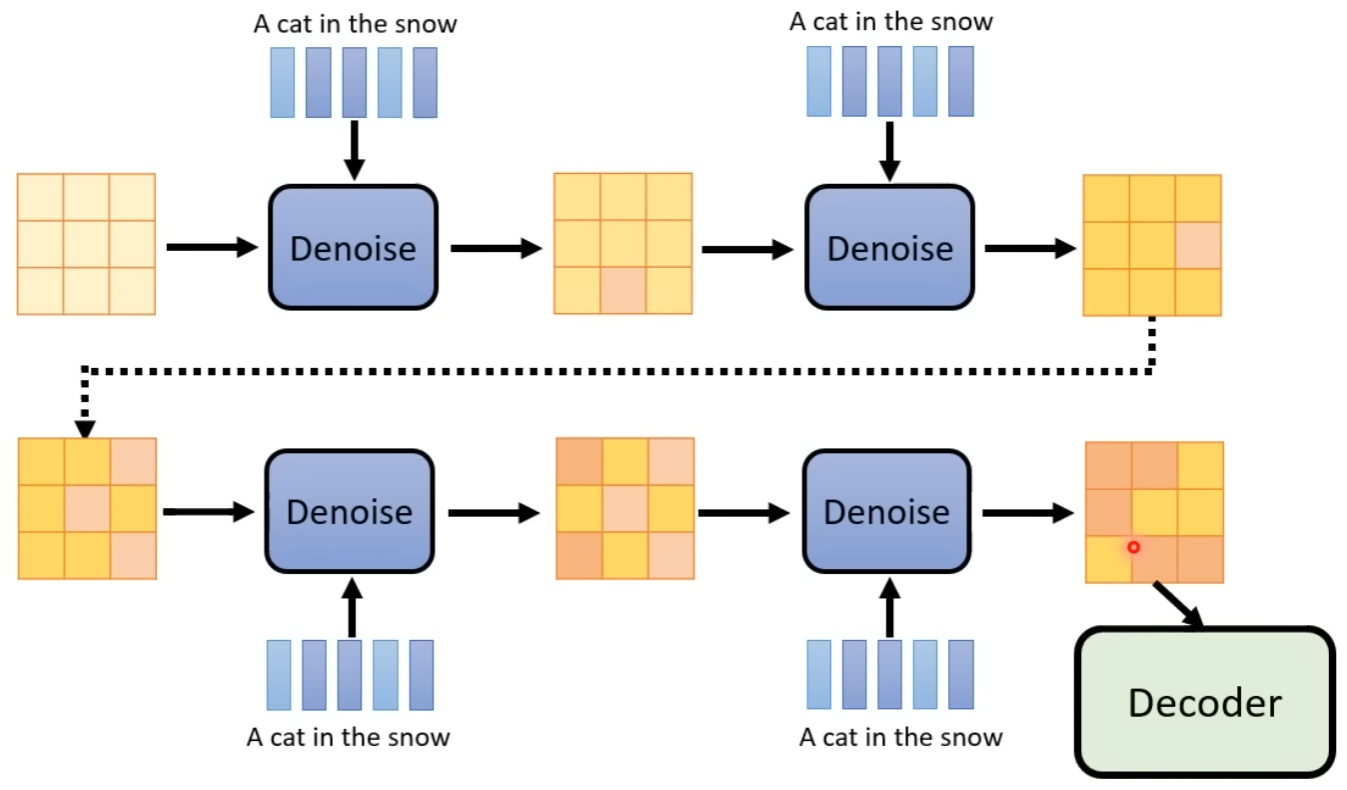
此处需要注意,去噪的过程是「随机高斯噪音」逐步变成「最终 Latent Representation」的过程,该过程中的每一步的 Embedding,丢进 Decoder 均可得到图片,对应于图片生成时,图片逐步变清晰的过程。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我是Rails的新手,所以请原谅简单的问题。我正在为一家公司创建一个网站。那家公司想在网站上展示它的客户。我想让客户自己管理这个。我正在为“客户”生成一个表格,我想要的三列是:公司名称、公司描述和Logo。对于名称,我使用的是name:string但不确定如何在脚本/生成脚手架终端命令中最好地创建描述列(因为我打算将其设置为文本区域)和图片。我怀疑描述(我想成为一个文本区域)应该仍然是描述:字符串,然后以实际形式进行调整。不确定如何处理图片字段。那么……说来话长:我在脚手架命令中输入什么来生成描述和图片列? 最佳答案 对于“文本”数
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
有这些railscast。http://railscasts.com/episodes/218-making-generators-in-rails-3有了这个,你就会知道如何创建样式表和脚手架生成器。http://railscasts.com/episodes/216-generators-in-rails-3通过这个,您可以了解如何添加一些文件来修改脚手架View。我想把两者结合起来。我想创建一个生成器,它也可以创建脚手架View。有点像RyanBates漂亮的生成器或web_app_themegem(https://github.com/pilu/web-app-theme)。我
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
我使用的第一个解析器生成器是Parse::RecDescent,它的指南/教程很棒,但它最有用的功能是它的调试工具,特别是tracing功能(通过将$RD_TRACE设置为1来激活)。我正在寻找可以帮助您调试其规则的解析器生成器。问题是,它必须用python或ruby编写,并且具有详细模式/跟踪模式或非常有用的调试技术。有人知道这样的解析器生成器吗?编辑:当我说调试时,我并不是指调试python或ruby。我指的是调试解析器生成器,查看它在每一步都在做什么,查看它正在读取的每个字符,它试图匹配的规则。希望你明白这一点。赏金编辑:要赢得赏金,请展示一个解析器生成器框架,并说明它的
我一直在玩一个脚本,它在Chrome中获取选定的文本并在Google中查找它,提供四个最佳选择,然后粘贴相关链接。它以不同的格式粘贴,具体取决于当前在Chrome中打开的页面-DokuWiki打开的DokuWiki格式,普通网站的HTML,我想要我的WordPress所见即所得编辑器的富文本。我尝试使用pbpaste-Preferrtf来查看没有其他样式的富文本链接在粘贴板上的样子,但它仍然输出纯文本。在文本编辑中保存文件并进行试验后,我想出了以下内容text=%q|{\rtf1{\field{\*\fldinst{HYPERLINK"URL"}}{\fldrsltTEXT}}}|te
Ruby有一些不错的文档生成器,例如Yard、rDoc,甚至Glyph。问题是Sphinx可以做网站、PDF、epub、LaTex等。它在重组文本中完成所有这些事情。在Ruby世界中有替代方案吗?也许是程序的组合?如果我也能使用Markdown就更好了。 最佳答案 自1.0版以来,Sphinx有了“域”的概念,它是从Python和/或C以外的语言标记代码实体(如方法调用、对象、函数等)的方法。有一个rubydomain,所以你可以只使用Sphinx本身。您唯一会缺少的(我认为)是Sphinx使用autodoc从源代码自动创建文档