大家好,我是小小明。
最近看到几个视频网站的地址依然是m3u8格式,不禁有了使用python进行下载的想法,虽然下载m3u8格式视频的工具很多,但如果我们自行编码就能应对更多的情况。
关于m3u8的基础知识可以参考:Python实时下载B站直播间视频(M3U8视频流)
下面我们将使用Python下载m3u8格式的加密离线视频流。
游览器抓包过滤能够获取该影片的m3u8播放地址:
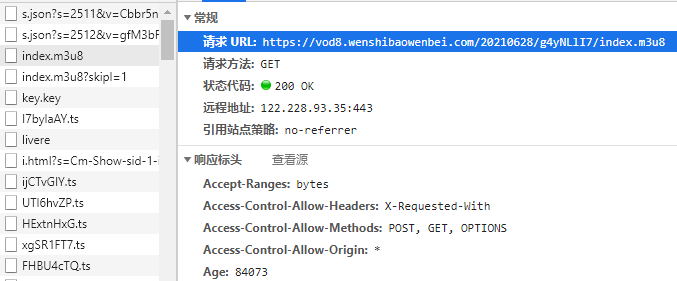
首先,测试一下该地址:
import m3u8
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
playlist = m3u8.load(
uri='https://vod8.wenshibaowenbei.com/20210628/g4yNLlI7/index.m3u8', headers=headers)
playlist.data
{'media_sequence': None,
'is_variant': True,
'is_endlist': False,
'is_i_frames_only': False,
'is_independent_segments': False,
'playlist_type': None,
'playlists': [{'uri': '/20210628/g4yNLlI7/1000kb/hls/index.m3u8',
'stream_info': {'program_id': 1,
'bandwidth': 1000000,
'resolution': '1280x720'}}],
'segments': [],
'iframe_playlists': [],
'media': [],
'keys': [],
'rendition_reports': [],
'skip': {},
'part_inf': {},
'session_data': [],
'session_keys': []}
从结果看到,这是一个嵌套的地址。
所以写个方法解析真实地址:
import m3u8
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
def get_real_url(url):
playlist = m3u8.load(uri=url, headers=headers)
return playlist.playlists[0].absolute_uri
real_url = get_real_url(
'https://vod8.wenshibaowenbei.com/20210628/g4yNLlI7/index.m3u8')
real_url
'https://vod8.wenshibaowenbei.com/20210628/g4yNLlI7/1000kb/hls/index.m3u8'
解析真实地址的加密key:
playlist = m3u8.load(uri=real_url, headers=headers)
key = playlist.keys[-1]
print(key.uri, key.method, key.iv)
https://ts8.hhmm0.com:9999/20210628/g4yNLlI7/1000kb/hls/key.key AES-128 None
可以看到密钥下载地址和加密类型。
使用request下载密钥:
import requests
r = requests.get(playlist.keys[0].uri, headers=headers)
key = r.content
key
b'7ec5143edebbc899'
可以单线程直接下载视频:
import time
n = len(playlist.segments)
size = 0
start = time.time()
for i, seg in enumerate(playlist.segments, 1):
r = requests.get(seg.absolute_uri, headers=headers)
data = r.content
data = AESDecrypt(data, key=key, iv=key)
size += len(data)
with open("reusult.mp4", "ab") as f:
f.write(data)
print(f"\r下载进度({i}/{n}),已下载:{size/1024/1024:.2f}MB,下载已耗时:{time.time()-start:.2f}s", end=" ")
下载进度(1435/1435),已下载:424.69MB,下载已耗时:850s
单线程下载,好处是不会产生多余的文件,缺点是速度太慢了,一个视频下载了10多分钟。
下面我们整理一下完整的代码:
import time
from Crypto.Util.Padding import pad
from Crypto.Cipher import AES
import requests
import m3u8
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
def get_real_url(url):
playlist = m3u8.load(uri=url, headers=headers)
return playlist.playlists[0].absolute_uri
def AESDecrypt(cipher_text, key, iv):
cipher_text = pad(data_to_pad=cipher_text, block_size=AES.block_size)
aes = AES.new(key=key, mode=AES.MODE_CBC, iv=key)
cipher_text = aes.decrypt(cipher_text)
return cipher_text
def download_m3u8_video(url, save_name):
real_url = get_real_url(url)
playlist = m3u8.load(uri=real_url, headers=headers)
key = requests.get(playlist.keys[-1].uri, headers=headers).content
n = len(playlist.segments)
size = 0
start = time.time()
for i, seg in enumerate(playlist.segments, 1):
r = requests.get(seg.absolute_uri, headers=headers)
data = r.content
data = AESDecrypt(data, key=key, iv=key)
size += len(data)
with open(save_name, "ab" if i != 1 else "wb") as f:
f.write(data)
print(
f"\r下载进度({i}/{n}),已下载:{size/1024/1024:.2f}MB,下载已耗时:{time.time()-start:.2f}s", end=" ")
download_m3u8_video('https://vod8.wenshibaowenbei.com/20210628/g4yNLlI7/index.m3u8', '走进家门.mp4')
对于多线程,由于下载的文件可能出现间断,所以我们不能直接追加到目标视频中,可以先下载下来,最后统一合并并删除。
先创建ts视频下载的方法:
import os
import requests
def download_ts(url, key, i):
r = requests.get(url, headers=headers)
data = r.content
data = AESDecrypt(data, key=key, iv=key)
with open(f"tmp/{i:0>5d}.ts", "ab") as f:
f.write(data)
print(f"\r{i:0>5d}.ts已下载", end=" ")
if not os.path.exists("tmp"):
os.mkdir('tmp')
任意下载一个片段测试一下:
import requests
import m3u8
def get_real_url(url):
playlist = m3u8.load(uri=url, headers=headers)
return playlist.playlists[0].absolute_uri
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
real_url = get_real_url(
'https://vod8.wenshibaowenbei.com/20210628/g4yNLlI7/index.m3u8')
playlist = m3u8.load(uri=real_url, headers=headers)
key = requests.get(playlist.keys[-1].uri, headers=headers).content
download_ts(playlist.segments[0].absolute_uri, key, 1)
00001.ts已下载
检查该片段可以正常播放。
然后执行以下方法即可10个线程同时一起下载:
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor(max_workers=10) as pool:
for i, seg in enumerate(playlist.segments):
pool.submit(download_ts, seg.absolute_uri, key, i)

经过一分20秒左右的时间,所有视频流已经全部下载完毕,比单线程的速度快了不止10倍。
最后我们实现文件的合并和ts临时文件清除:
import glob
with open('video.mp4', 'wb') as fw:
files = glob.glob('tmp/*.ts')
for file in files:
with open(file, 'rb') as fr:
fw.write(fr.read())
print(f'\r{file}已合并!总数:{len(files)}', end=" ")
os.remove(file)
执行后,已经在1秒左右时间合并并清除完临时文件。
import glob
from concurrent.futures import ThreadPoolExecutor
import m3u8
import os
import requests
from Crypto.Util.Padding import pad
from Crypto.Cipher import AES
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
def download_ts(url, key, i):
r = requests.get(url, headers=headers)
data = r.content
data = AESDecrypt(data, key=key, iv=key)
with open(f"tmp/{i:0>5d}.ts", "ab") as f:
f.write(data)
print(f"\r{i:0>5d}.ts已下载", end=" ")
def get_real_url(url):
playlist = m3u8.load(uri=url, headers=headers)
return playlist.playlists[0].absolute_uri
def AESDecrypt(cipher_text, key, iv):
cipher_text = pad(data_to_pad=cipher_text, block_size=AES.block_size)
aes = AES.new(key=key, mode=AES.MODE_CBC, iv=key)
cipher_text = aes.decrypt(cipher_text)
return cipher_text
def download_m3u8_video(url, save_name, max_workers=10):
if not os.path.exists("tmp"):
os.mkdir('tmp')
real_url = get_real_url(url)
playlist = m3u8.load(uri=real_url, headers=headers)
key = requests.get(playlist.keys[-1].uri, headers=headers).content
with ThreadPoolExecutor(max_workers=max_workers) as pool:
for i, seg in enumerate(playlist.segments):
pool.submit(download_ts, seg.absolute_uri, key, i)
with open(save_name, 'wb') as fw:
files = glob.glob('tmp/*.ts')
for file in files:
with open(file, 'rb') as fr:
fw.write(fr.read())
print(f'\r{file}已合并!总数:{len(files)}', end=" ")
os.remove(file)
download_m3u8_video('https://vod8.wenshibaowenbei.com/20210628/g4yNLlI7/index.m3u8', '走进家门.mp4')
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json