快速排序是一种常用的排序算法,比选择排序快的多。在之前的我随笔中也写过关于快速排序的算法,也可以看一下和现在的区别python实现快速排序 - Mr-Yang` - 博客园 (cnblogs.com)。
在看快速排序之前,要先了解一下递归,对于递归我之前的文章中也有提到python递归函数 - Mr-Yang` - 博客园 (cnblogs.com),在这里我补充一个关于递归的一个点:基线条件和递归条件
由于递归函数是自己调用自己,因此编写这样的函数时容易出错,从而导致无限循环。示例如下:
def countdown(i):
print(i)
countdown(i-1)
如果运行上述代码,就会发现一个问题:这个函数运行起来是不会停止,直到到达递归的最大深度。
正是因为这样,编写递归函数的时候,必须告诉它何时停止递归,所以每个递归函数都有两个部分:基线条件(base case)和递归条件(recursive case)。递归条件指定的是函数调用自己,而基线条件则指的是不再调用自己,从而避免循环。例如给 countdown 添加基线条件。
def countdown(i):
print(i)
if i <= 1: #<----------基线条件
return
else: #<--------------递归条件
countdown(i-1)
这样就按照预期那样执行,不会无限循环下去如图所示
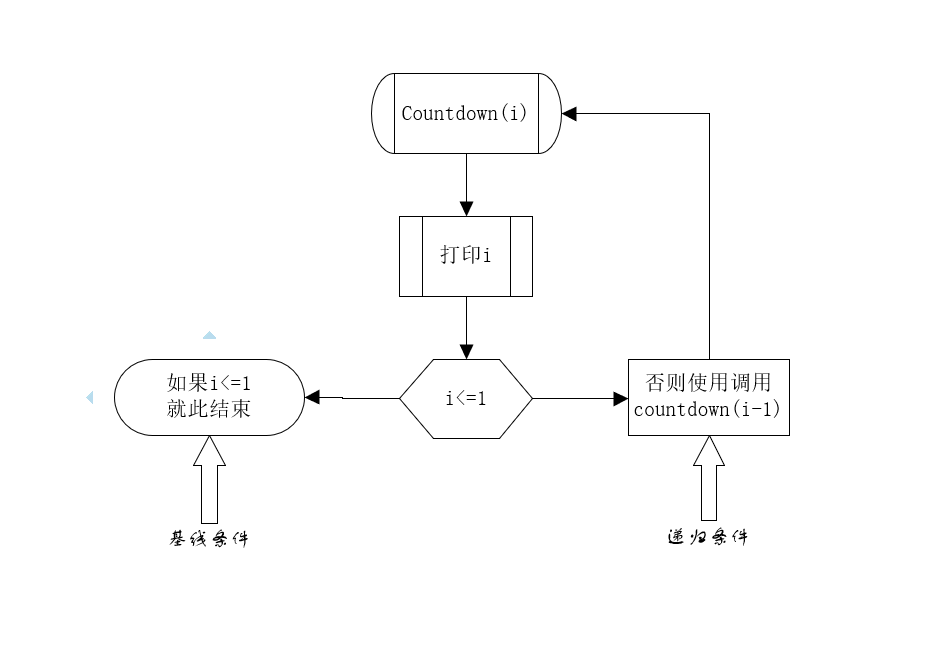
因为对于排序来说,最简单的就是一个空列表,或者只包含一个元素的列表,所以可以将基线条件设置为空或只包含一个元素,在这种情况下,只需要返回原列表。
def quicksort(alist):
if len(alist) < 2:
return alist
思路如下图所示:
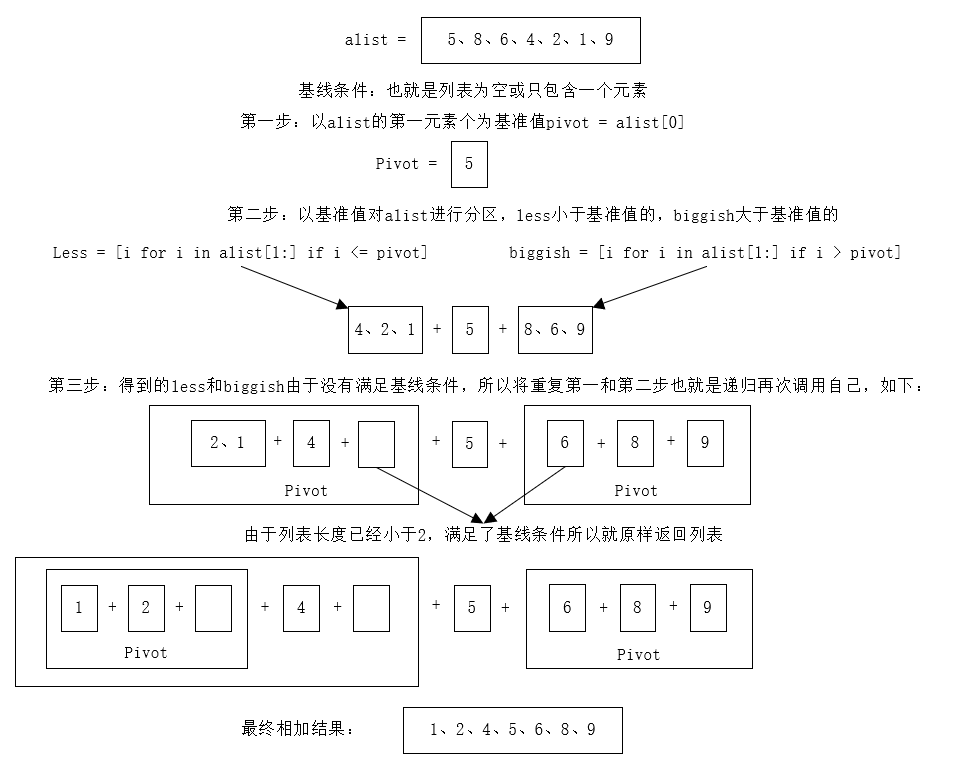
代码如下:
def quicksort(alist):
if len(alist) < 2:
return alist # 基线条件为空或只包含一个元素的列表是有序的。
else:
pivot = alist[0] # 选择基准值
less = [i for i in alist[1:] if i <= pivot] # 由小于基准值的元素组成
biggish = [i for i in alist[1:] if i > pivot] # 由大于基准值的元素组成
return quicksort(less) + [pivot] + quicksort(biggish)
作者:Mr-Yang
出处:https://www.cnblogs.com/XiaoYang-sir/p/16425804.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur