文章目录
场景:
mysql查询: select * from xx where mobile in(19000001111 , 19000003333 ,19000004444) and sex=男 and age >=20 and age <=30
mysql查询: select count(distinct (deptName)), count(distinct(provice)) from xx
先构造 index:testquery, 然后构造mapping结构, 插入测试数据
#构建 库index testquer
put /testquery
#构建mapping结构
put /testquery/_mapping
{
"properties" : {
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"copy_to" : [
"info"
]
},
"age" : {
"type" : "long"
},
"area" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"content" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"deptName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"fielddata" : true
},
"empId" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"info" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"mobile" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"copy_to" : [
"info"
]
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"copy_to" : [
"info"
]
},
"provice" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"fielddata" : true
},
"salary" : {
"type" : "long"
},
"sex" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"addtime" : {
"type":"date",
//时间格式 epoch_millis表示毫秒
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
插入测试数据
put /testquery/_bulk
{"index":{"_id": 1},"addtime":"1658041203000"}
{"empId" : "111","name" : "员工1","age" : 20,"sex" : "男","mobile" : "19000001111","salary":1333,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"光谷大道","address":"湖北省武汉市洪山区光谷大厦","content" : "i like to write best elasticsearch article", "addtime":"1658140003000"}
{"index":{"_id": 2}}
{"empId" : "222","name" : "员工2","age" : 25,"sex" : "男","mobile" : "19000002222","salary":15963,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i think java is the best programming language"}
{"index":{"_id": 3},"addtime":"1658040045600"}
{ "empId" : "333","name" : "员工3","age" : 30,"sex" : "男","mobile" : "19000003333","salary":20000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"经济技术开发区","address" : "湖北省武汉市经济开发区","content" : "i am only an elasticsearch beginner"}
{"index":{"_id": 4},"addtime":"1658040012000"}
{"empId" : "444","name" : "员工4","age" : 20,"sex" : "女","mobile" : "19000004444","salary":5600,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"沌口开发区","address" : "湖北省武汉市沌口开发区","content" : "elasticsearch and hadoop are all very good solution, i am a beginner"}
{"index":{"_id": 5},"addtime":"1658040593000"}
{ "empId" : "555","name" : "员工5","age" : 20,"sex" : "男","mobile" : "19000005555","salary":9665,"deptName" : "测试部","provice" : "湖北省","city":"高新开发区","area":"武汉","address" : "湖北省武汉市东湖隧道","content" : "spark is best big data solution based on scala ,an programming language similar to java"}
{"index":{"_id": 6},"addtime":"1658043403000"}
{"empId" : "666","name" : "员工6","age" : 30,"sex" : "女","mobile" : "19000006666","salary":30000,"deptName" : "技术部","provice" : "武汉市","city":"湖北省","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i like java developer","addtime":"1658041003000"}
{"index":{"_id": 7}}
{"empId" : "777","name" : "员工7","age" : 60,"sex" : "女","mobile" : "19000007777","salary":52130,"deptName" : "测试部","provice" : "湖北省","city":"黄冈市","area":"边城区","address" : "湖北省黄冈市边城区","content" : "i like elasticsearch developer","addtime":"1658040008000"}
{"index":{"_id": 8}}
{"empId" : "888","name" : "员工8","age" : 19,"sex" : "女","mobile" : "19000008888","salary":60000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"汉阳区","address" : "湖北省武汉市江汉大学","content" : "i like spark language","addtime":"1656040003000"}
{"index":{"_id": 9}}
{"empId" : "999","name" : "员工9","age" : 40,"sex" : "男","mobile" : "19000009999","salary":23000,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市郑州大学","content" : "i like java developer","addtime":"1608040003000"}
{"index":{"_id": 10}}
{"empId" : "101010","name" : "张湖北","age" : 35,"sex" : "男","mobile" : "19000001010","salary":18000,"deptName" : "测试部","provice" : "湖北省","city":"武汉","area":"高新开发区","address" : "湖北省武汉市东湖高新","content" : "i like java developer i also like elasticsearch","addtime":"1654040003000"}
{"index":{"_id": 11}}
{"empId" : "111111","name" : "王河南","age" : 61,"sex" : "男","mobile" : "19000001011","salary":10000,"deptName" : "销售部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am not like java ","addtime":"1658740003000"}
{"index":{"_id": 12}}
{"empId" : "121212","name" : "张大学","age" : 26,"sex" : "女","mobile" : "19000001012","salary":1321,"deptName" : "测试部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am java developer thing java is good","addtime":"165704003000"}
{"index":{"_id": 13}}
{"empId" : "131313","name" : "李江汉","age" : 36,"sex" : "男","mobile" : "19000001013","salary":1125,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市二七区","content" : "i like java and java is very best i like it do you like java ","addtime":"1658140003000"}
{"index":{"_id": 14}}
{"empId" : "141414","name" : "王技术","age" : 45,"sex" : "女","mobile" : "19000001014","salary":6222,"deptName" : "测试部",,"provice" : "河南省","city":"郑州市","area":"金水区","address" : "河南省郑州市金水区","content" : "i like c++","addtime":"1656040003000"}
{"index":{"_id": 15}}
{"empId" : "151515","name" : "张测试","age" : 18,"sex" : "男","mobile" : "19000001015","salary":20000,"deptName" : "技术部",,"provice" : "河南省","city":"郑州市","area":"高新开发区","address" : "河南省郑州高新开发区","content" : "i think spark is good","addtime":"1658040003000"}
ES搜索, 获取手机号是 19000001111 或者 19000003333 后者 19000004444 ,19000005555的人, 并且 性别是男, 且 年龄是[20-30]的人,这种查询用mysql 如何实现 ? 在mysql中会用in查询, 但是在ES中 我们实现就是 terms来实现 in功能的查询
| 手机号 | 性别 | 年龄 | 是否符合 |
|---|---|---|---|
| 19000001111 | 男 | 20 | 符合 |
| 19000003333 | 男 | 30 | 不符合 age |
| 19000004444 | 女 | 20 | 不符合 sex |
| 19000005555 | 男 | 20 | 符合 |
使用terms来实现 in的操作, 使用 bool must 进行匹配 sex, 然后使用给filter 来过滤范围
get /testquery/_search
{
"query":{
"bool": {
"must": [
{
"terms": {
"mobile.keyword": [
"19000001111",
"19000003333",
"19000004444",
"19000005555"
]
}
},
{
"match": {
"sex": "男"
}
}
],
//在 bool内部, must查询完的平级 进行filter过滤数据
"filter":{
"range": {
"age": {
"gte": 20,
"lte": 25
}
}
}
}
}
}
查询结果 2条数据, 分别是 19400001111-20岁, 19400005555-20岁,都是男生,结果正确
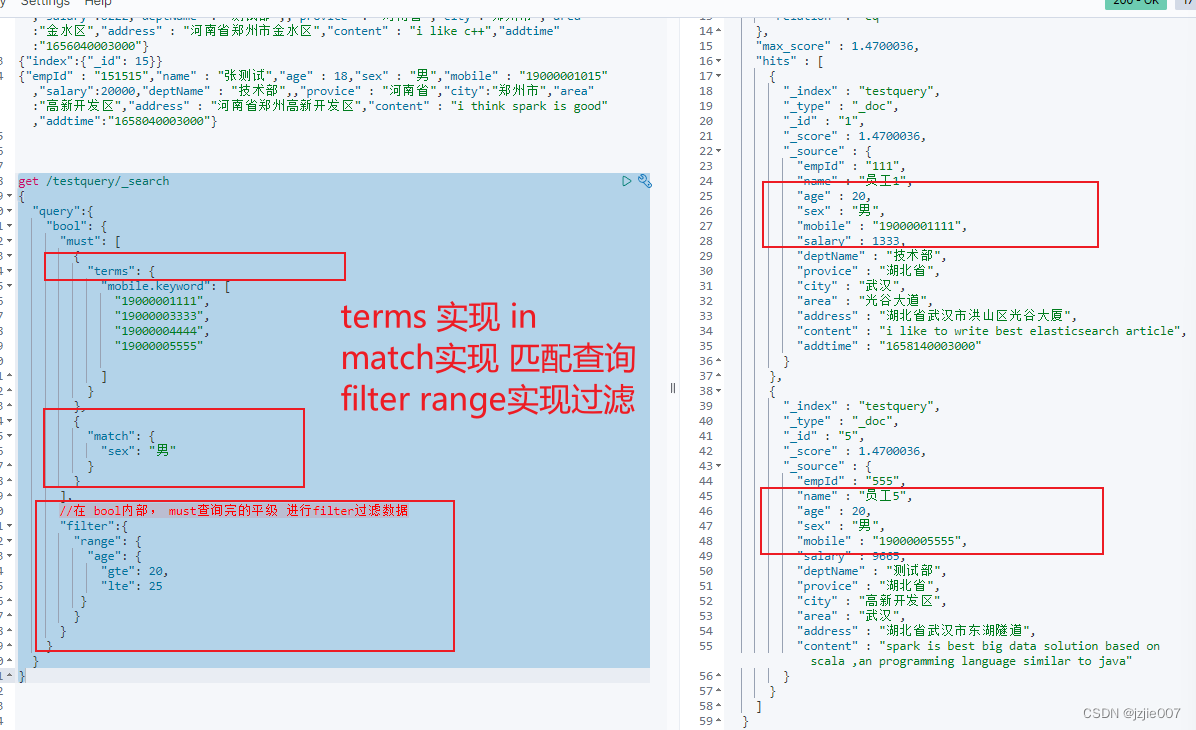
terms 其实就是对 should的简化方式,我们下面实现一种 should的方式来进行查询
使用 should 来实现 in的操作, must查询 sex 男生, 再次使用给filter 来过滤范围, 注意 should和 must结合使用的话, 一定要是先must再should,而且should 一定是再 must内部,为什么这样做, 之前的文章讲过 大家可以回顾一下
Elasticsearch实战(五)—高级搜索 Match/Match_phrase/Term/Must/should 组合使用 其中2.2章节就是 讲的 A&B&( C || D )的多种查询语法如何写
依旧是 上面的场景
ES搜索, 获取手机号是 19000001111 或者 19000003333 后者 19000004444 ,19000005555的人, 并且 性别是男, 且 年龄是[20-30]的人,通过 bool should 及单层 filter 实现
#先must 查询 ,然后 再 must内部 should查询, 然后 对结果进行 filter range 年龄20-25岁的
get /testquery/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"sex": "男"
}
},
//注意大括号, 再must 内部 再来一次should 来进行 或操作
{
"bool":{
"should": [
{
"match": {
"mobile.keyword": "19000001111"
}
},
{
"match": {
"mobile.keyword": "19000003333"
}
},
{
"match": {
"mobile.keyword": "19000004444"
}
},
{
"match": {
"mobile.keyword": "19000005555"
}
}
]
}
}
]
//must 同级 ,对查询的结果过滤, 保留年龄 20-25的
,"filter": [
{
"range": {
"age": {
"gte": 20,
"lte": 25
}
}
}
]
}
}
}
查询结果 2条数据, 分别是 19400001111-20岁, 19400005555-20岁,都是男生,结果正确
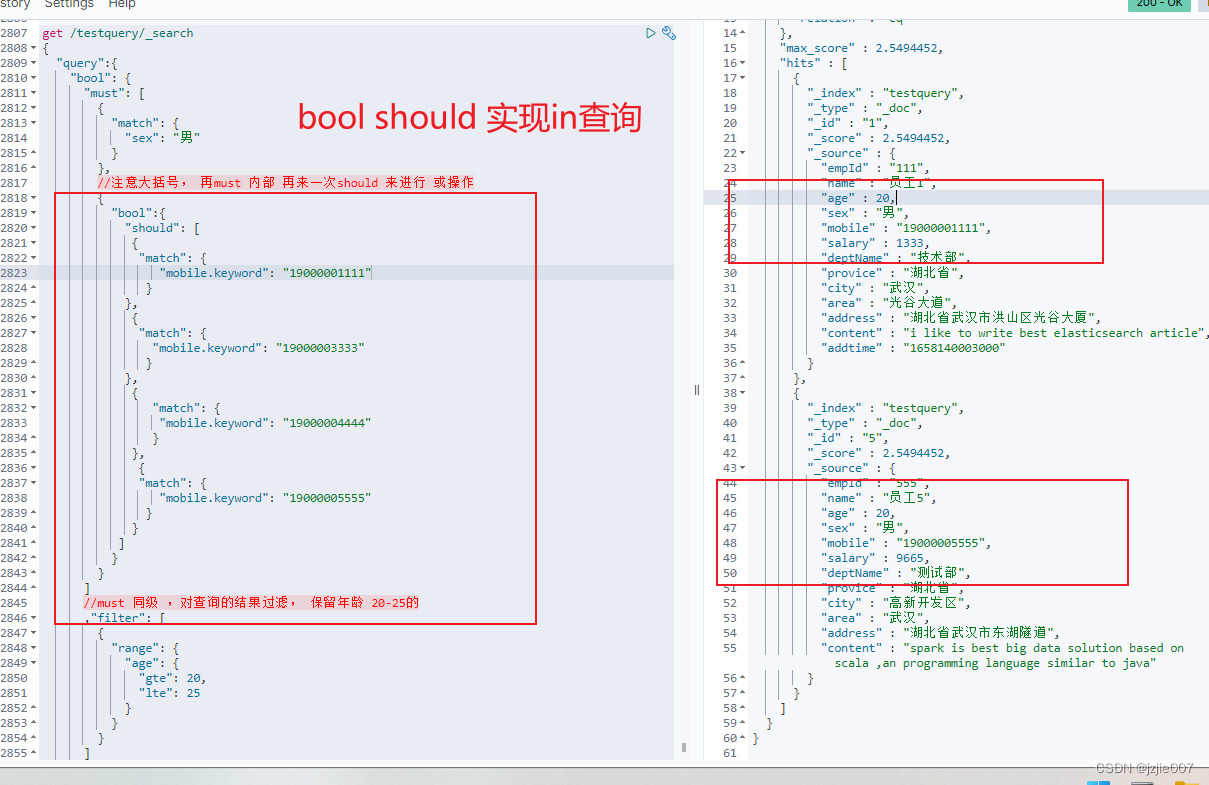
那如果再一个条件呢? 比如 现在是过滤 年龄是 20-25之间的, 我们现在 加一个 部门是技术部的 ,如何实现 ?
filter 过滤可以有多层过滤条件, 比如刚才的 我们使用给filter range 过滤了 age在20-25之间的, 我们如果再加一个 部门的过滤呢?
当然 部门的过滤我们可以 在 match sex:男 中加一个条件 deptName:技术部, 如果我们像过滤工资呢? 过滤工资 大于5000的人
这就涉及多个filter 的使用了
使用 must 多个嵌套, 单层filter实现
#先must 查询多个 以下 ,然后 再 must内部 should查询, 然后 对结果进行 filter range 年龄20-25岁的
get /testquery/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"sex": "男"
}
},
{
"match": {
"deptName.keyword": "技术部"
}
},
//must 内部 开始should 判断手机号
{
"bool": {
"should": [
{
"match": {
"mobile.keyword": "19000001111"
}
},
{
"match": {
"mobile.keyword": "19000003333"
}
},
{
"match": {
"mobile.keyword": "19000004444"
}
},
{
"match": {
"mobile.keyword": "19000005555"
}
}
]
}
}
]
//must 同级 开始 filter
, "filter": [
{
"range": {
"age": {
"gte": 20,
"lte": 25
}
}
}
]
}
}
}
先must 查询 sex:男, deptName:技术部, 然后 再 must内部 should查询 mobile in (19400001111,19400003333,19400004444,19400005555)
然后 对结果进行 filter range 年龄20-25岁的
查询结果 1条数据, 分别是 19400001111-20岁,男生,结果正确
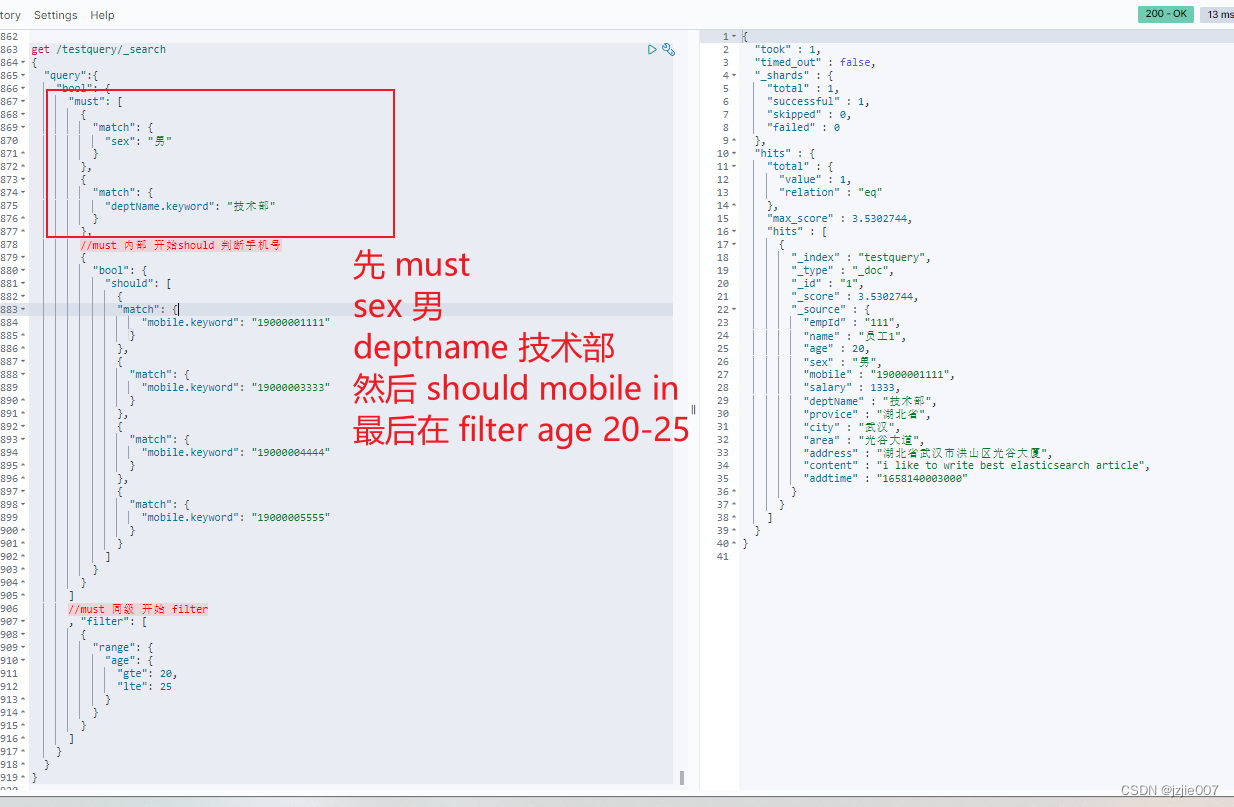
那如果使用多层filter 呢 ? 如何实现 ?
那如果使用多层filter 呢 ? 如何实现 ?
那如果使用多层filter 呢 ? 如何实现 ?
我们 已经是 must, terms in 结构, 然后 filter 这次 多加一些条件 比如 range age 20-30的,是技术部的 放在filter中操作
使用 must 单个条件, 多层filter 过滤实现
get /testquery/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"sex": "男"
}
},
{
"terms": {
"mobile": [
"19000001111",
"19000003333",
"19000004444",
"19000005555"
]
}
}
]
//must 同级 filter
,"filter": [
{
"range": {
"age": {
"gte": 20,
"lte": 25
}
}
},
{
"term": {
"deptName.keyword": "技术部"
}
}
]
}
}
}
多层filter 过滤条件 过滤age, 过滤 deptName, 查询结果 1条数据, 分别是 19400001111-20岁,男生,结果正确
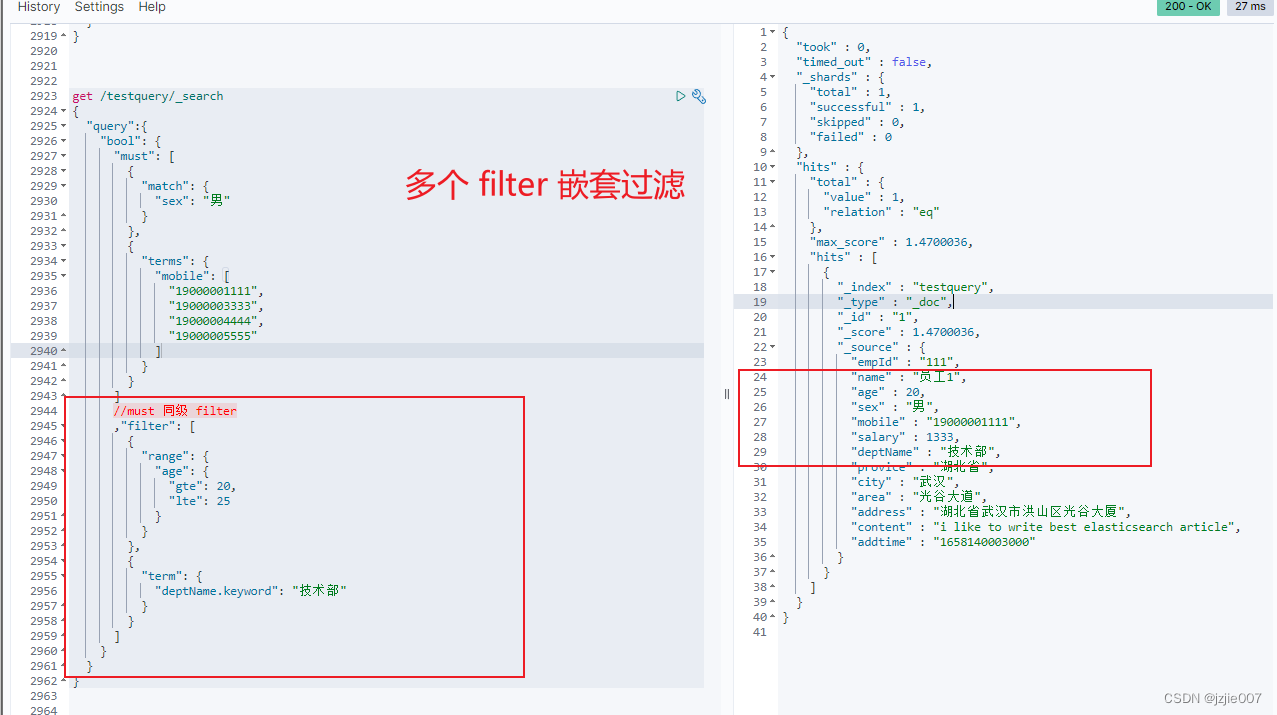
我们要想精确查 技术部有多少人,肯定要以某个字段去除重复数据的
#mysql 语法 统计技术部有多少人, 以 employeeid为唯一标识,去重重复数据
select count(dinstinct (employee_id)) from xx where deptName="技术部"
ES中 通过 caidinality 来实现去除重复数据,使用在 aggs中 聚合操作去除重复数据
# caidinality 去除重复数据, 使用在 aggs中 聚合操作去除重复数据
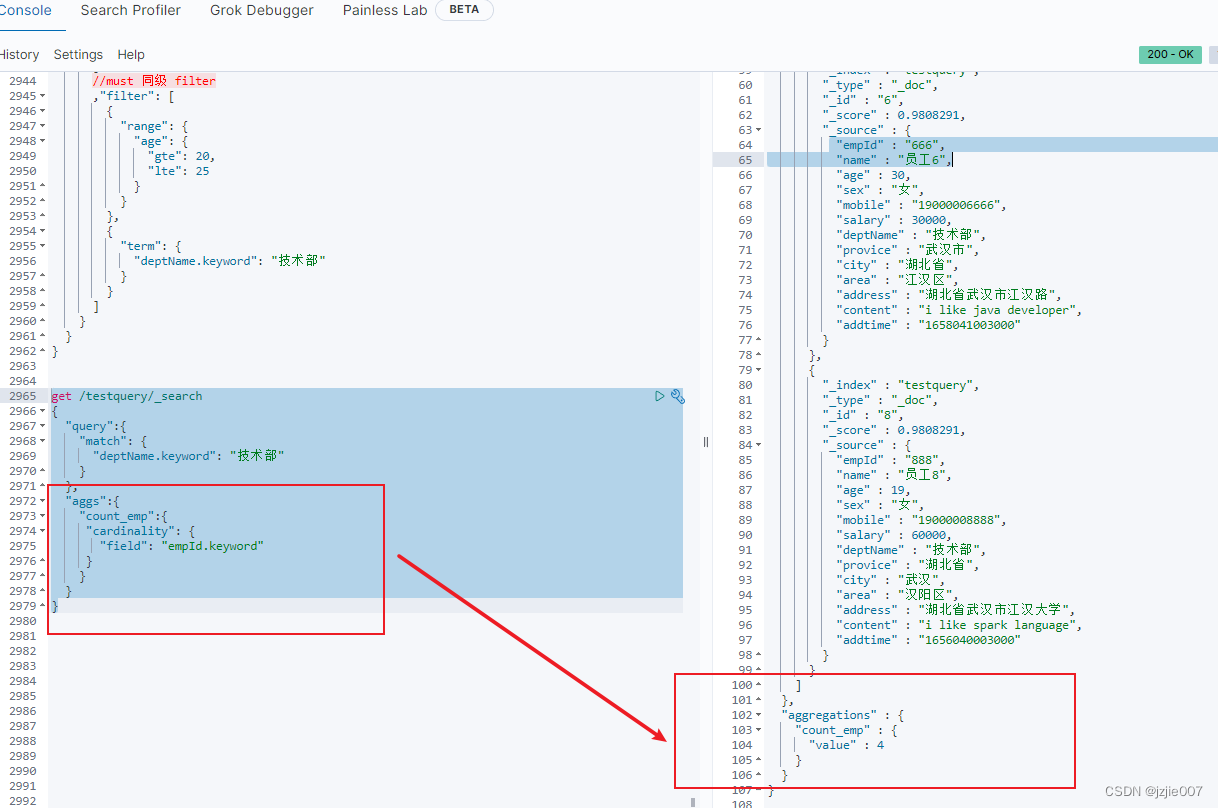
get /testquery/_search
{
"query":{
"match": {
"deptName.keyword": "技术部"
}
},
"aggs":{
"count_emp":{
"cardinality": {
"field": "empId.keyword"
}
}
}
}
查询过滤 结果 技术部的人 一共有四个, 去除重复数据 count_emp 就是 4人
场景 :
先把 empId设为 fileld_data=true 才能用做聚合 去重操作, 注意fielddata不建议在生产中用,后面篇章我们会介绍为什么不建议用,会导致OOM 内存溢出, 先暂时这样用,方便做测试数据
PUT testquery/_mapping
{
"properties": {
"empId": {
"type": "text",
"fielddata": true
}
}
}
统计每月 公司部门 去重后的入职人数>1的部门名称
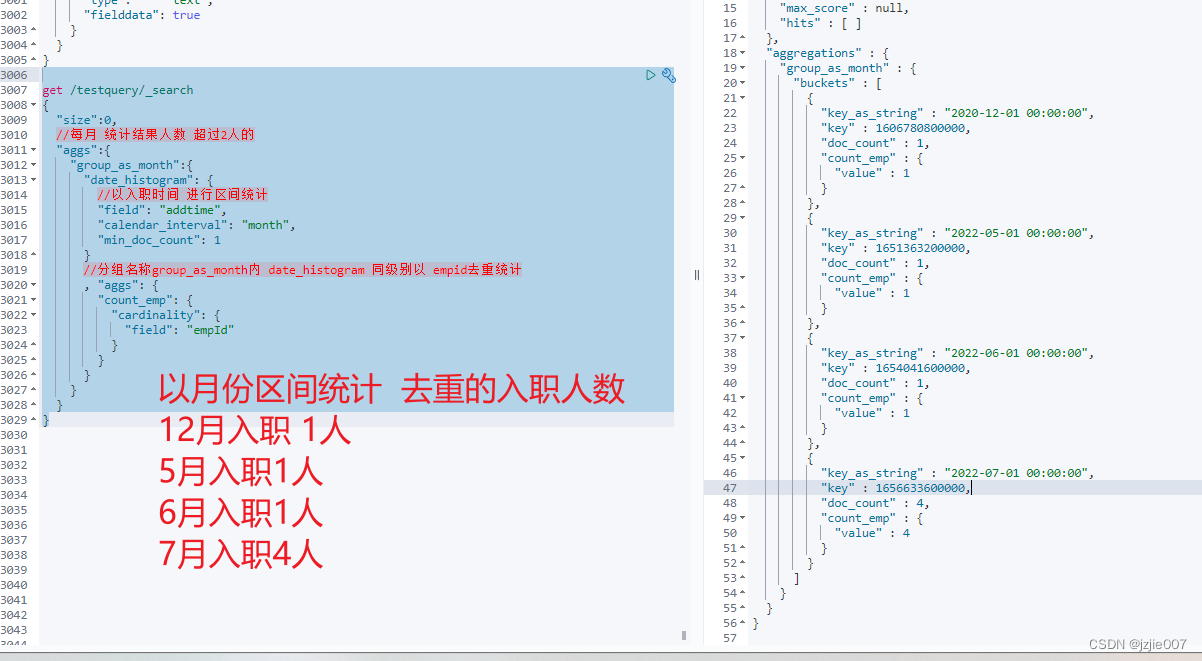
# 要统计每月 公司部门 入职人数>1 的部门名称
get /testquery/_search
{
"size":0,
//每月 统计结果人数 超过2人的
"aggs":{
"group_as_month":{
"date_histogram": {
//以入职时间 进行区间统计
"field": "addtime",
"calendar_interval": "month",
"min_doc_count": 1
}
//分组名称group_as_month内 date_histogram 同级别以 empid去重统计
, "aggs": {
"count_emp": {
"cardinality": {
"field": "empId"
}
}
}
}
}
}
查询过滤 结果 结果正确, 12月,5月,6月 入职1人, 7月 入职4人, 这里的统计人数的经过数据去重的 caidinality实现的 emp员工id去重
至此 我们已经学习了 ES 如何使用in查询数据,及 filter 单层,多层过滤如何查询,还有就是如果要实现distinct 去重统计,就要使用 caidinality来进行去重操作
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru