时序逻辑 UDP 与组合逻辑 UDP 在定义形式和行为功能上均有不同,主要区别如下:
... : <current_state> : <next_state> ;
表示时序逻辑的 UDP 主要分为 2 种:电平触发 UDP 与 边沿触发 UDP。
电平触发 UDP 的输出是根据输入电平状态的改变而改变。
带有清零端的 D 锁存器的功能描述为:
其真值表为(q 表示当前状态,q+ 表示下一个状态):
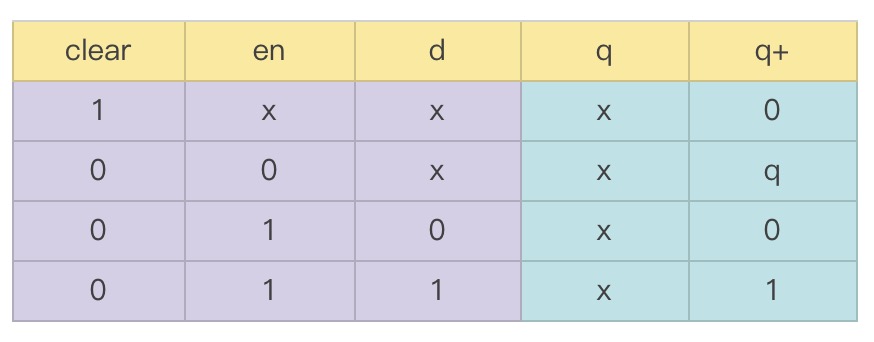
其实编写 UDP 的过程,可以理解为换一种格式编写真值表的过程。
带有清零端的 D 锁存器的 UDP 可以描述如下:
primitive d_latch(q, clear, en, d);
output q ;
reg q ;
input d, en, clear ;
initial
q = 0 ;
table
//clear en d :q :q+ ;
1 ? ? :? :0 ; //clear
0 0 ? :? :- ; //"-" means stable
0 1 0 :? :0 ; //q = d
0 1 1 :? :1 ;
endtable
endprimitive
当然,也可以在罗列端口信号时就声明其类型,并且赋初值。
primitive d_latch2(
output reg q = 0,
input clear, en, d);
......
endprimitive
边沿触发 UDP 的输出是根据输入跳边沿和(或)输入电平状态的改变而改变。
直接给出带有异步复位端(RST)且在时钟下降沿采集信号的 D 触发器的"真值表":
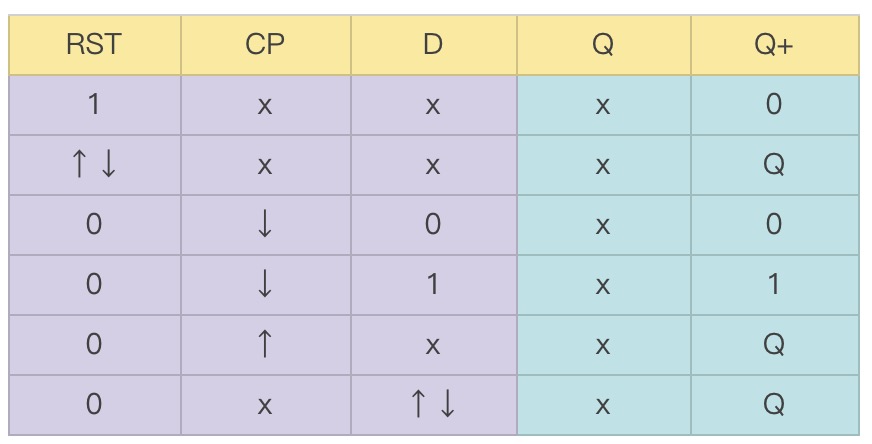
可见此"真值表"中还加入了上下沿的概念,是为了方便编写 UDP 代码。
此 D 触发器的时序逻辑 UDP 描述如下:
primitive D_TRI(
output reg Q = 0,
input RST, CP, D);
table
//RST CP D :Q :Q+ ;
//(1) 清零
1 ? ? :? :0 ; //RST=1 时清零
(??) ? ? :? :- ; //忽略 RST 边沿变化
//(2) 时钟下降沿采集
0 (10) 0 :? :0 ; //时钟下降沿采集信号
0 (10) 1 :? :1 ;
//possible negedge
0 (1x) ? :? :- ; //可能是时钟下降沿时保持
0 (x0) ? :? :- ;
//(3) 时钟上升沿保持
0 (0?) ? :? :- ; //时钟上升沿时保持
//possible posedge
0 (x1) ? :? :- ; //可能是时钟上升沿时保持
//(4) 非时钟沿变化时,即便数据有跳变,输出仍然保持
0 ? (??) :? :- ;
endtable
endprimitive // D_TRI
对此触发器进行简单的仿真,testbench 描述如下。
`timescale 1ns/1ps
module test ;
reg D, CP = 0 ;
reg RST ;
wire Q ;
always #5 CP = ~CP ;
//data driver
initial begin
D = 0 ;
#12 D = 1 ;
#10 D = 0 ;
#14 D = 1 ;
#3 D = 0 ;
#18 D = 0 ;
end
//reset driver
initial begin
RST = 0 ;
#3 RST = 1 ;
#2 RST = 0 ;
#22 RST = 1 ;
#1 RST = 0 ;
end
D_TRI u_d_trigger(Q, RST, CP, D);
initial begin
forever begin
#100;
//$display("---gyc---%d", $time);
if ($time >= 1000) begin
$finish ;
end
end
end
endmodule // test
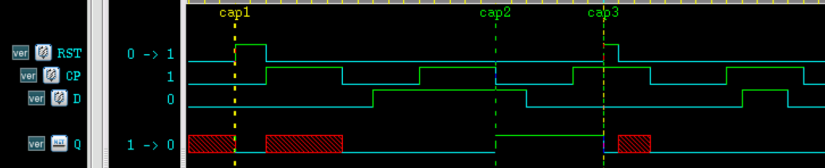
仿真结果如下。
由图可知,在 cap1 时刻,Q 端被复位清零;在 cap2 时刻,即时钟下降沿时,输出端采集到 D 端输入 1;在 cap3 时刻,Q 端又被清零。符合设计。

需要注意的是:
状态表每行多个输入部分,最多只能有一个跳边沿,例如下面状态表的表述是错误的。
table
......
(10) (10) 1 :? :1 ;
endtable
电平触发的状态表输入项,其优先级高于边沿触发的状态表输入项。若两者在同一时刻出现,则输出端的状态由电平触发的状态表决定。
例如上述 D 触发器中,RST 可以看做是电平触发,CP 可以看做是边沿触发。当 RST 上升沿与 CP 端下降沿同时刻来临时,输出端会变为 0 ,如下图 cap 时刻。当然,实际的时序应该避免时钟和复位边沿同时到来。
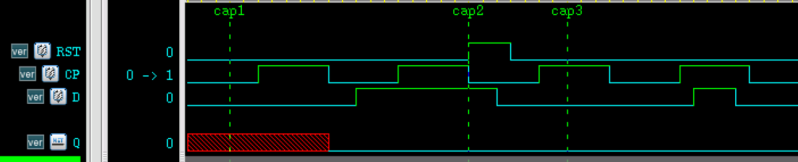
边沿触发 UDP 中,必须为每一个输入信号都指定边沿变化时输出信号的变化情况,否则在该信号的跳变沿处可能会造成输出端为 X 。
例如缺少 RST 边沿变化的说明:
//(??) ? ? :? :- ; //忽略 RST 边沿变化
则在 RST 下降沿输出会变为 x。
再例如缺少时钟稳定、D 端数据变化时的说明:
//(4) 非时钟沿变化时,即便数据有跳变,输出仍然保持
//0 ? (??) :? :- ;
则 D 端数据变化的边沿处也会使输出为 x。

UDP 状态表的电平和跳变沿缩写符号及说明如下表所示。
| 缩写符 | 含义 | 说明 |
|---|---|---|
| ? | 0, 1, x | 只能用于输入 |
| b | 1, 1 | 只能用于输入 |
| - | 保持原值不变 | 只能用于输出 |
| (ab) | 信号由 a 变 b | 用作输入端边沿的指示 |
| r | (01) | 信号的上升沿 |
| f | (10) | 信号的下降沿 |
| p | (01), (0x) 或 (x1) | 可能是信号的上升沿 |
| n | (10), (1x) 或 (x0) | 可能是信号的下降沿 |
| * | (??) | 信号任意边沿的变化 |
针对数字设计时是选择使用 module 还是 primitive,要从设计需求、复杂度等方面进行综合考虑。下面给出一些指导性的建议。
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
我们有一个目前在Rails2.3.12版和Ruby1.8.7版上运行的应用程序。我们想将我们的应用程序更新到Rails4.0和Ruby2.1.0。我们有大约200个模型和150个Controller。我想知道升级过程需要多大的努力。您还可以提供升级可以遵循的步骤。我们应该先升级Ruby然后再升级Rails还是相反? 最佳答案 您想要实现的目标将是史诗般的努力。我无法为您提供分步说明,因为不可能在一个答案中涵盖所有情况。我建议不要同时升级Ruby和Rails,而是分步升级。升级本身的复杂性是巨大的,但只要您的应用程序具有合理的测试覆盖
我正在尝试让Rails在Windows10上运行。我正在使用Ruby2.3.0和Rails4.2.6,并且暂时使用Nokogiri1.6.3。当我尝试运行railsnewdemo时,它返回错误:Anerroroccurredwhileinstallingnokogiri(1.6.7.2),andBundlercannotcontinue.Makesurethat`geminstallnokogiri-v'1.6.7.2'`succeedsbeforebundling.当我运行geminstallnokogiri-v'1.6.7.2时,我得到:ERROR:Errorinstallingn
目录一、inout在设计文件中的使用方法1.1、inout的第一种使用方法1.2、inout实现的第二种使用方法1.3、inout使用总结 二、inout在仿真测试中的使用方法一、inout在设计文件中的使用方法在FPGA的设计过程中,有时候会遇到双向信号(既能作为输出,也能作为输入的信号叫双向信号)。比如,IIC总线中的SDA信号就是一个双向信号,QSPIFlash的四线操作的时候四根信号线均为双向信号。在Verilog中用关键字inout定义双向信号,这里总结一下双向信号的处理方法。1.1、inout的第一种使用方法 实际上,双向信号的本质是由一个三态门组成的,三态门可以输出高电平,低电
文章目录一基础定义二创建逻辑卷2-1准备物理设备2-2创建物理卷2-3创建卷组2-4创建逻辑卷2-5创建文件系统并挂载文件三扩展卷组和缩减卷组3-1准备物理设备3-2创建物理卷3-3扩展卷组3-4查看卷组的详细信息以验证3-5缩减卷组四扩展逻辑卷4-1检查卷组是否有可用的空间4-2扩展逻辑卷4-3扩展文件系统五删除逻辑卷5-1备份数据5-2卸载文件系统5-3删除逻辑卷5-4删除卷组5-5删除物理卷六LVM逻辑卷缩容6-1缩容注意事项6-2标准缩容步骤一基础定义LVM,LogicalVolumeManger,逻辑卷管理,Linux磁盘分区管理的一种机制,建立在硬盘和分区上的一个逻辑层,提高磁盘分
我在新的Rails应用程序(3.2.3)中运行迁移时遇到了问题。我们正在使用postrgres9.1.3和-pg(0.13.2)-当我运行rakedb:create,然后运行rakedb:migrate,我得到->1.9.3-p194(master)rakedb:migrate--trace**Invokedb:migrate(first_time)**Invokeenvironment(first_time)**Executeenvironmentrakeaborted!PG::Error:ERROR:relation"roles"doesnotexistLINE4:WHEREa
我有一个PORO(普通旧Ruby对象)来处理一些业务逻辑。它接收一个ActiveRecord对象并对其进行分类。为了简单起见,以下面为例:classClassificatorSTATES={1=>"Positive",2=>"Neutral",3=>"Negative"}definitializer(item)@item=itemenddefnameSTATES.fetch(state_id)endprivatedefstate_idreturn1if@item.value>0return2if@item.value==0return3if@item.value但是,我还想根据这些st
在Rails中,什么是集成更新模型某些元素的UDP监听过程的最佳方式(特别是它将向其中一个表添加行)。简单的答案似乎是在同一个进程中使用UDP套接字对象启动一个线程,但我什至不清楚我应该在哪里做适合Rails方式的事情。有没有一种巧妙的方法来开始收听UDP?具体来说,我希望能够编写一个UDPController并在每个数据报消息上调用一个特定的方法。理想情况下,我希望避免在UDP上使用HTTP(因为它会浪费一些在这种情况下非常宝贵的空间),但我完全控制消息格式,因此我可以为Rails提供它需要的任何信息。 最佳答案 Rails是一个
在以下示例中,我无法理解Ruby运算符的优先级:x=1&&y=2由于&&的优先级高于=,我的理解是类似于+和*运算符:1+2*3+4解析为1+(2*3)+4它应该等于:x=(1&&y)=2但是,所有Ruby源代码(包括内部语法解析器Ripper)都将其解析为x=(1&&(y=2))为什么?编辑[08.01.2016]让我们关注一个子表达式:1&&y=2根据优先规则,我们应该尝试将其解析为:(1&&y)=2这没有意义,因为=需要特定的LHS(变量、常量、[]数组项等)。但是既然(1&&y)是一个正确的表达式,那么解析器应该如何处理呢?我试过咨询Ruby的parse.y,但它太像意大利面条
我正在尝试解决来自SevenLanguagesinSevenWeeks的一个简单的Ruby问题Printthecontentsofanarrayofsixteennumbers,fournumbersatatime,usingjusteach这是我想到的,可以用简单的方式完成还是改进它?a=(1..16).to_ai=0j=[]a.eachdo|item|i+=1j可以在一行中使用each_slicea.each_slice(4){|x|px} 最佳答案 Teja,你的解决方案没问题。由于您需要使用每一个,因此算法的复杂性将受限于数