分享嘉宾:管正雄 阿里云 高级算法工程师
出品平台:DataFunTalk
导读:面对海量的用户问题,有限的支持人员该如何高效服务好用户?智能QA生成模型给业务带来的提效以及如何高效地构建算法服务,为业务提供支持。本文将介绍:阿里云计算平台大数据产品答疑场景;基于达摩院AliceMind预训练模型实现的智能QA生成算法核心能力及背后实现原理;如何通过智能运维服务平台将算法能力输出,给业务提供一站式服务,优化答疑体验。主要分为以下几部分:
--
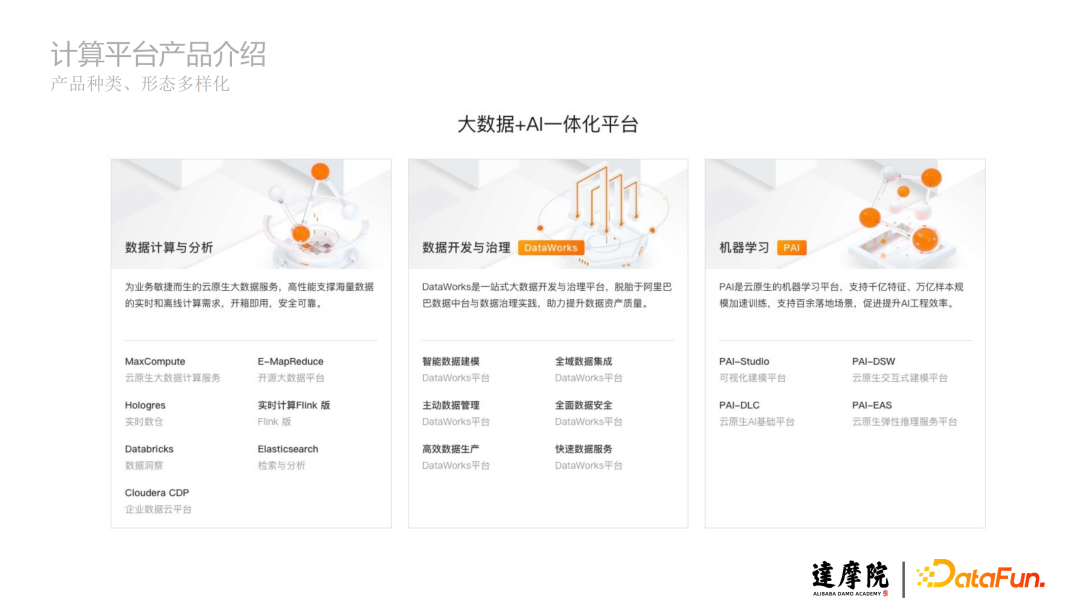
阿里云计算平台的产品种类多,形态多样化,主要包括数据计算与分析、数据开发与治理、机器学习三大模块,其中包括阿里云自研产品像MaxCompute、Hologres等,以及开源产品像Flink、Elasticsearch等阿里云提供资源和托管的服务。
在用户购买了阿里云的产品后,在使用过程中如果遇到问题,可以通过以下方式寻求解决方案,但同时又存在一些痛点:
a. 机器人问答:机器人语料覆盖有限。
b. 文档查询:内容过多,查找效率低。
c. 社区问答:集中于高频问题,中长尾问题较少。
d. 提工单:无法实时解答问题。
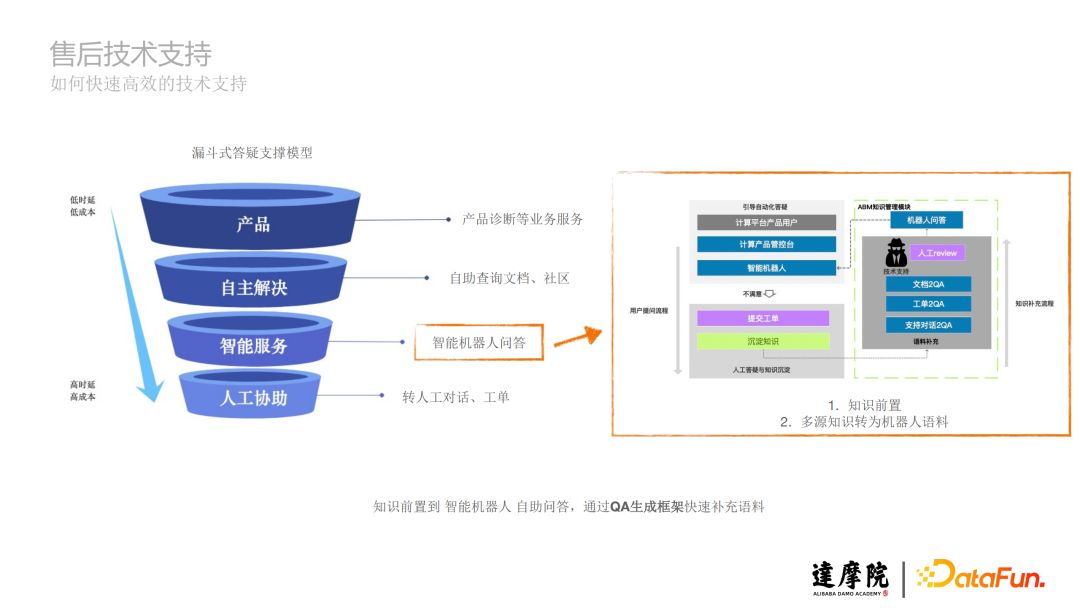
a. 产品:产品诊断等业务服务。
b. 自主解决:自助查询文档、社区。
c. 智能服务:智能机器人问答,分为用户提问流程和知识补充流程,实现知识前置,多源知识转为机器人语料。
d. 人工协助:转人工对话、工单。
接下来重点介绍在智能服务中,知识前置到智能机器人自助问答,通过QA生成框架快速补充语料。
--
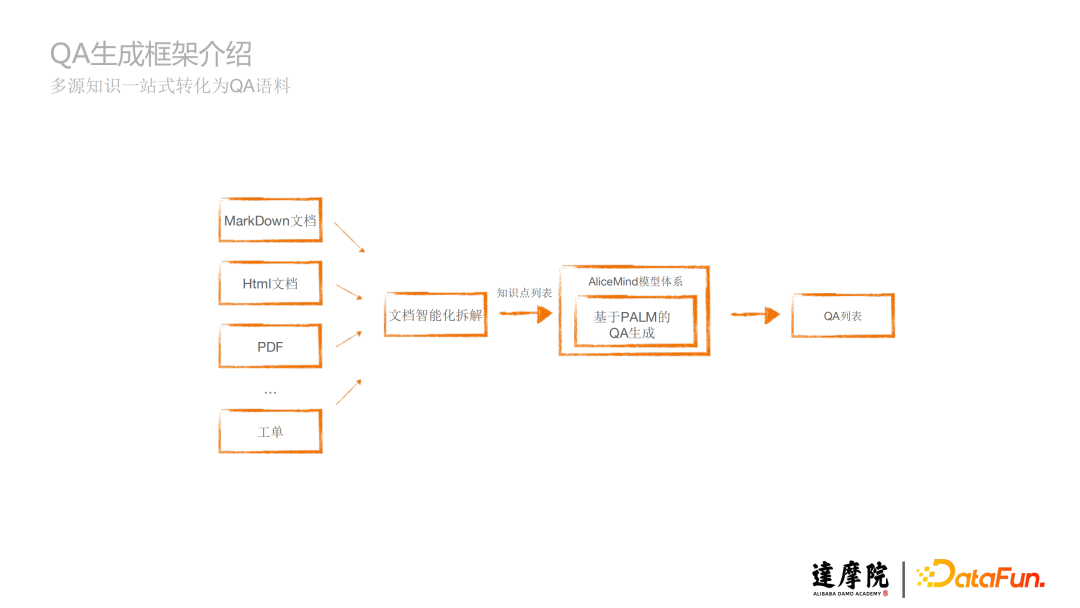
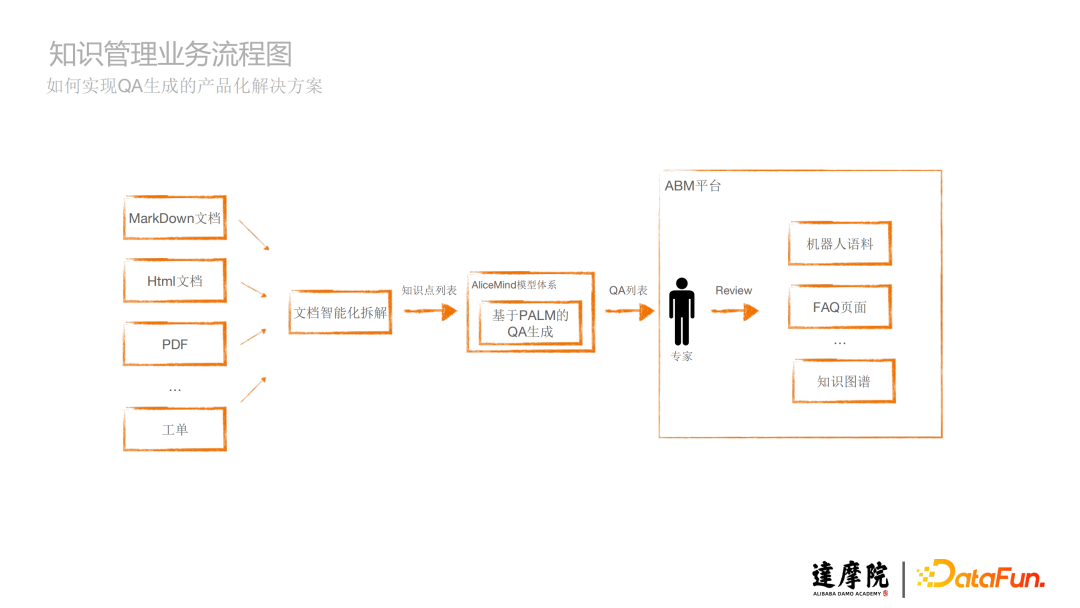
上图是QA生成框架概览。文档智能化拆解模块,将不同的文档如MarkDown文档、Html文档、PDF文档、工单等等拆解成知识点,生成知识点列表,知识点列表经过基于AliceMind模型体系里的PALM生成模型,将这些知识点生成QA,最终得到QA列表,从而实现多源知识一站式转化为QA语料。
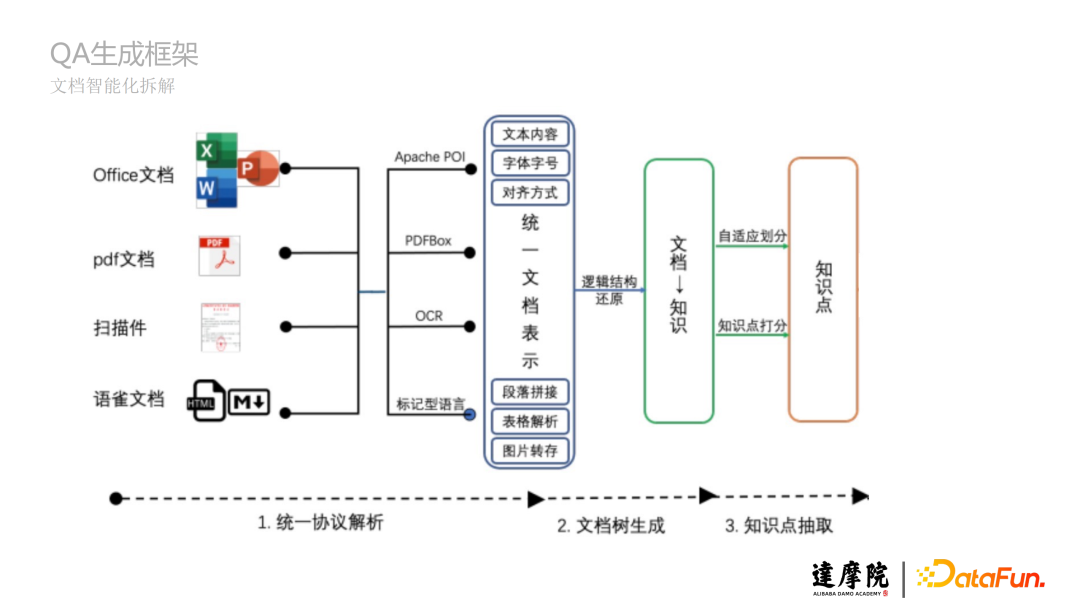
a. 统一协议解析:不同的文档有不同的协议,将诸如Office文档、PDF文档、扫描件、语雀文档等的协议进行统一文档表示。
b. 文档树生成:将文档的结构比如一、二、三标题等生成树状结构,将文档的内容梳理成知识点的树状汇总。
c. 知识点抽取:基于自适应划分或知识点打分,将知识树拆解成具体的知识点。
下图是HTML文档拆解和PDF文档拆解的举例:

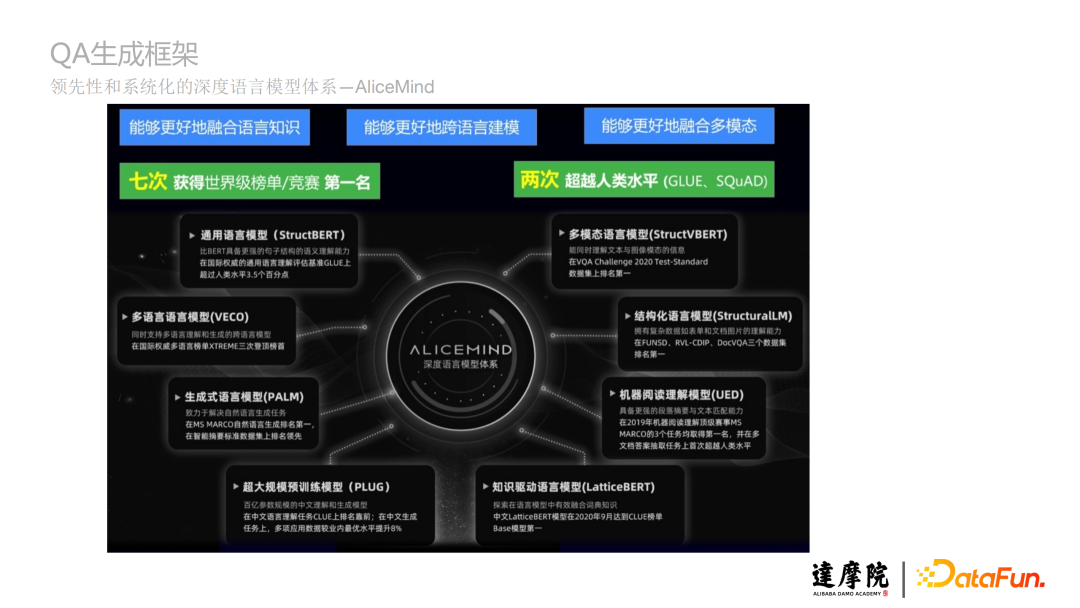
AliceMind是领先性和系统化的深度语言模型体系,本文将重点介绍AliceMind中的生成式语言模型(PALM)如何生成QA。
a. AliceMind的业务价值和应用领域举例
b. 基于PALM的QA生成模型
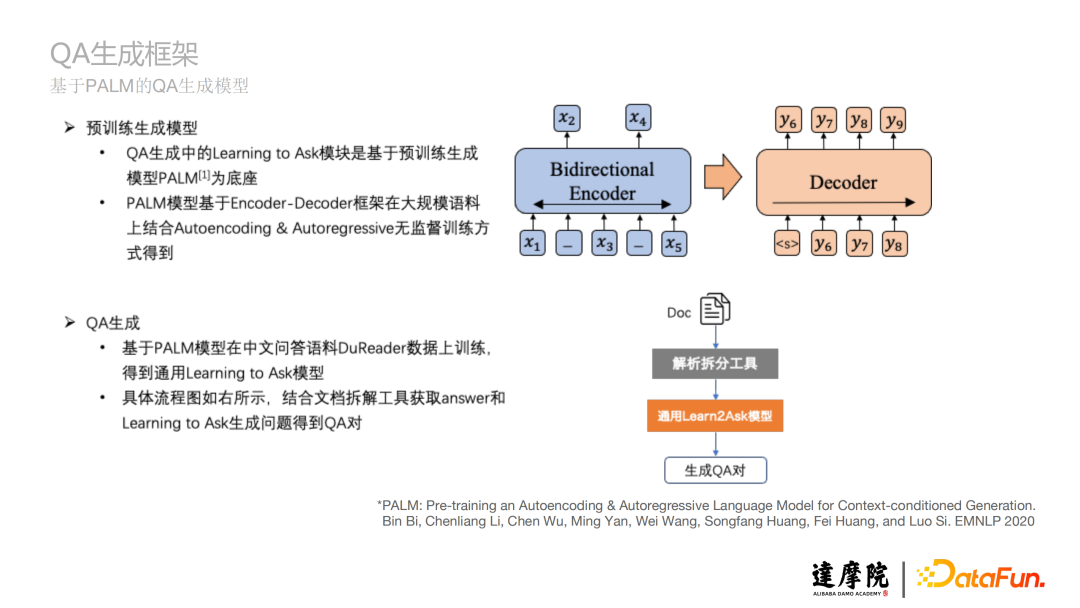
QA生成中的Learning to Ask模块是基于预训练生成模型PALM为底座;
PALM模型基于Encoder-Decoder框架在大规模语料上结合Autoencoding & Autoregressive无监督训练方式得到。
基于PALM模型在中文问答语料DuReader数据上训练,得到通用Learning to Ask模型;
具体流程图如上图下半部分所示,结合文档拆解工具获取answer和Learning to Ask生成问题得到QA对。
更多阅读:
PALM: Pre-training an Autoencoding & Autoregressive Language Model for Context-conditioned Generation.
BinBi, Chenliang Li, Chen Wu, Ming Yan, Wei Wang, Songfang Huang, Fei Huang, and Luo Si. EMNLP 2020
a. 文档:

Q:Dataworks的工作空间是什么
A:工作空间是Dataworks管理任务、成员……
Q:DataWorks的解决方案的优势是什么
A:一个解决方案可以包括多个业务流程,解决方案……
--
ABM运维管控平台即飞天大数据管控平台(ABM,Apsara Big Data Manager),是支撑平台服务与集群的全生命周期管理,智能化运维、运营和交付,面向大数据的业务方、运营方及研发方提供企业级运维平台。

ABM智能算法平台提供算法从开发-构建-部署的全生命周期的支撑。

如图所示,算法开发可以添加算法配置和注册算法检测器,SRE用户或运维可以创建场景生成检测实例,这个检测实例就是QA生成算法的应用实例,然后算法调度框架去调度,最后再给到用户。这一系列过程可以通过智能场景运营大盘进行整个生命周期的管理。
基于前面的QA生成框架概览图,最终生成的QA列表可能不是100%准确的,那么还要通过一些指标对其进行评估是否符合预期,同时经过我们专家的review,符合预期的QA将灌入到机器人语料、FAQ页面、知识图谱等里面。这就是整体的业务流程。
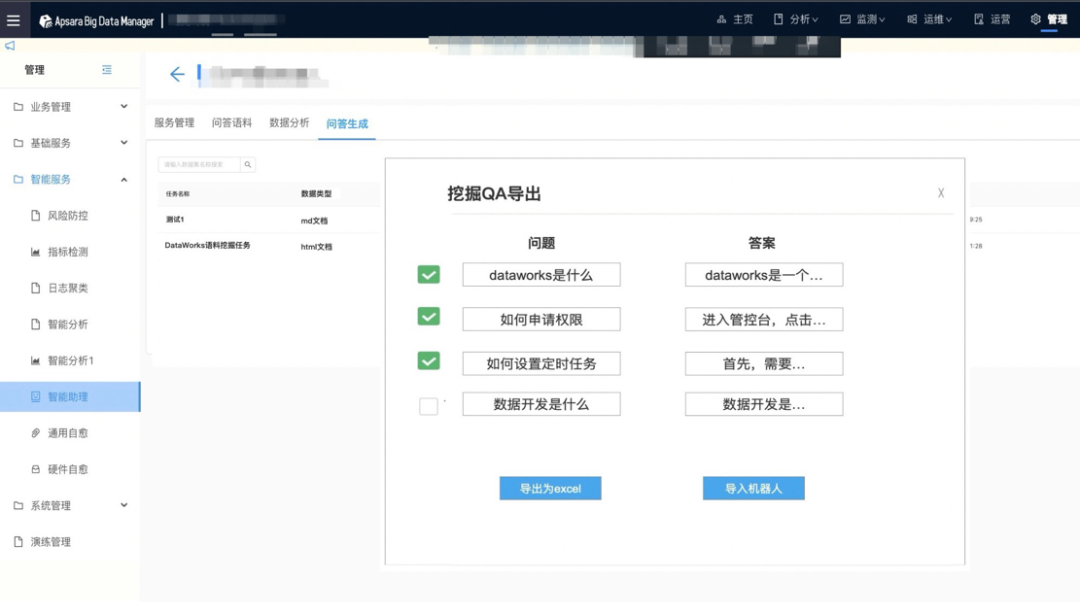
a. 新建挖掘任务
b. 导出生成QA语料
--
提取对话、论坛、工单等中的不同形式,有效知识通过某种方式沉淀到统一的知识库中。
关键词:多源数据、格式化。
规划:增加更多的数据源,格式化方法能力进一步提升。
通过人机交互接口,精准推送知识,解用户内心之惑。
关键词:搜索与推荐、个性化、评估与反馈。
规划:通过深度模型提升搜索、推荐的能力。
流程化,将知识的沉淀、消费在各角色间串联,让知识流动,实现迭代优化。
关键词:机制、人机协同。
规划:进一步优化流程,流程符合习惯的同时,进一步减少人工成本。
--
Q:如果这套QA生成方案在其它领域使用,迁移成本高吗?有哪些注意事项?
A:不高。我们在构建下游任务的时候需要一些数据,这个量不需要很大,目前我们应用的场景主要是电力、合同领域,大概几百条左右就可能会在该领域有一个比较好的表现。需要注意的是,训练集的质量相对来说要高一点,更能反映这个领域的属性。
Q:这样构造的问答对会不会样式比较单一?
A:这个是跟产品有关,一个问题就是一个知识点,以及对应这个知识点的答案,QA在这样的一个场景里还是比较好用的。
Q:请问怎么衡量问题生成的质量?
A:这个主要有两部分。第一部分,从模型层面会有一个得分,然后会有一些评价指标来衡量,这一部分在论文里有明确说明;第二部分是通过人工来评估,需要该领域的专家来完成,比如看这个QA是不是符合用户提问的习惯等。
Q:支持抽取多轮问答吗?
A:支持的。这个取决于你的训练集,如果训练集是多轮的,是可以抽取多轮对话的问答的。但是多轮对话问答的训练集,相对于文档生成问题的训练集,要难构建一点。
Q:能详细说一下评估反馈机制吗?
A:好的。从后台界面可以看到,生成QA以后,展现在界面上的是经过第一层筛选的,也就是说经过模型筛选的,然后让技术支持的同学去评估,评估完了以后可以选定和导出,或者导入机器人,我们会记录,作为一些正样本和副样本,作为后面学习过程的一个增量。除了技术支持的反馈,还有用户的反馈,然后再去调优。
Q:问答最后是人工质量质检,如果量大怎么控制?
A:第一层模型筛选会过滤掉较大的部分,分配下来以后,人工评估的工作量并不是特别的大。
Q:为啥智能客服很智障?
A:人工智能的前提,都是靠人的智力去慢慢堆积出来的。我们希望做的这些工作,能够慢慢地把智能客服从人工智障变成人工智能,这个也是我们的目标。
Q:拆解只适合格式化文件吗?
A:不是的。这个主要是你构建的下游任务,比如你的训练集是通过多人对话去抽取QA,还是从工单里面抽取QA,那下游任务训练出来的模型,就可以执行对应的任务,这取决于你的训练集。
Q:评价通过的准确率大概有多少?会超过90%吗?
A:根据我们之前的内部测试,大概在70%-80%左右,不同的产品可能会有一些差异性。
Q:对没有明显结构的网页数据如何进行拆解?
A:没有明显结构的网页数据可能会有一些HTML的Tag,可以基于Tag来拆解;如果一点都没有的话,那只能根据语意来拆解了,效果肯定没有有Tag的效果好。
Q:什么是多轮对话的知识形式?
A:多轮对话不像一问一答这么简单,它可能会有一些状态。我们的场景是计算平台的产品,目前基本上用不到多轮对话,一轮对话基本上可以解决了。
Q:Query如何和用户库中的QA对进行检索匹配?
A:比较简单的,Elasticsearch就可以做了;如果有更高的个性化需求比如做Query改写等,可以上一些深度模型。
Q:考虑过通过阅读理解去解决这个问题吗?
A:PALM就是基于语言理解和生成模型,它是通过阅读理解的这个深度模型作为底座,然后再加上下游任务来完成的。
Q:有用到知识图谱吗?
A:目前没有用到。目前我们的场景基本上是可以通过QA来覆盖的,后续其实我们是有这样一个方向的,我们做的这些可能就是知识图谱前面的一些铺垫。
Q:生成的问题模式会比较单一?
A:不一定。这基于两点,第一是预训练语料的语法是不是很灵活多变;第二是你的训练集,训练集里面的问法,如果说都是同一类的话,它生成的模型也会有比较大的倾向。
Q:自动文档抽取使用的预训练模型,在迁移训练时有模型改动或者输入格式匹配吗?
A:会有一些。这里肯定会做格式统一,但没有一个强制的规定,只要有一定格式上的相似性。
Q:Query同意改写在你们团队有实践吗?
A:有的。这个同意改写其实是基于一些模型,比如说是通过一些相似性、近义词等。在我们的大数据产品领域,对于产品的问法,我们可以为维护一个词库,我去收集一套可能的这个产品的所有的问法,就可以把它放到Query改写里面,作为一个同义词库。对于领域化的东西相对来说比较好找,像Query改写在开发领域则相对难一些。
Q:有源码吗?
A:可以去看那篇PALM论文。因为讲得比较清晰,大家也可以自己实现。
今天的分享就到这里,谢谢大家。
分享嘉宾:

本文首发于微信公众号“DataFunTalk”。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs