云计算将计算资源、数据资源统一在一个能力很强的地方(云中心),让普通用户成为瘦客户。也就是说,用户将数据存储在云端后,对本地存储能力和计算能力的要求降低,节约升级设备的成本
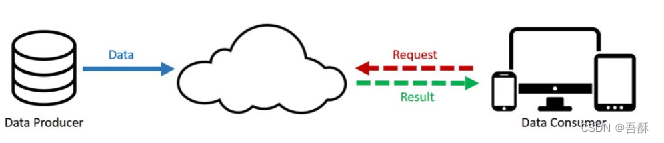
但云计算也有问题,通信成为了瓶颈,例如:
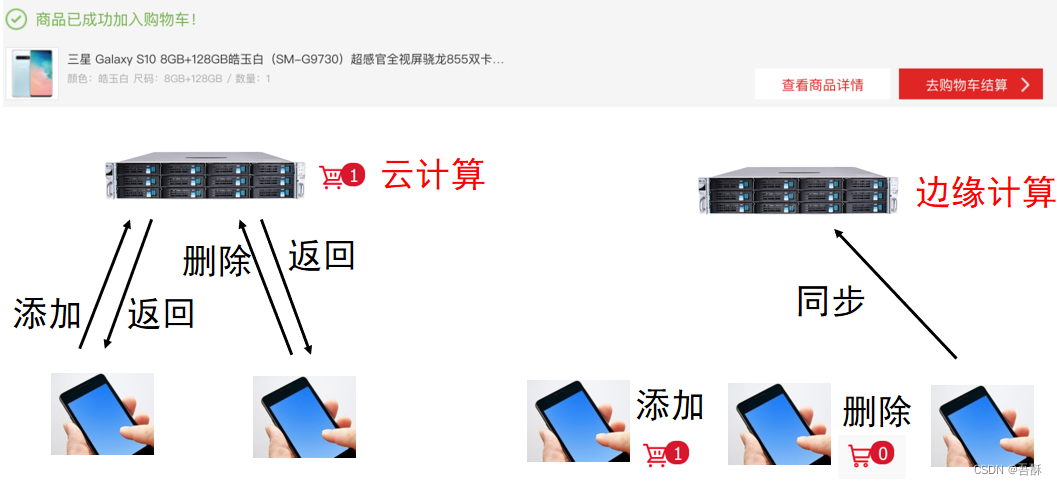
边缘计算:边缘计算是指用网络边缘结点来处理、分析数据。其中,边缘结点指的就是在数据产生源头和云中心之间任一具有计算资源和网络资源的结点。**直白的说:就是将计算放置在数据源的附近。**下图中左下灰色波浪部分即是用于计算的边缘节点,相较于云计算,它们离本地较近,云计算的通运问题被部分解决。

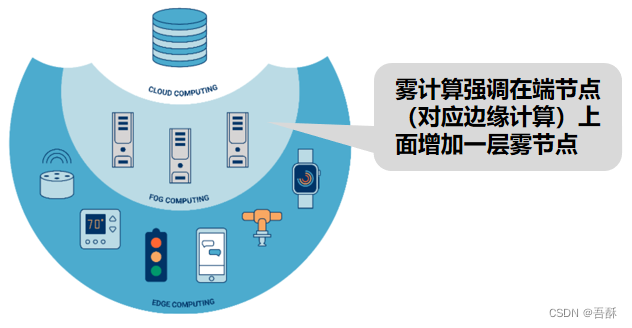
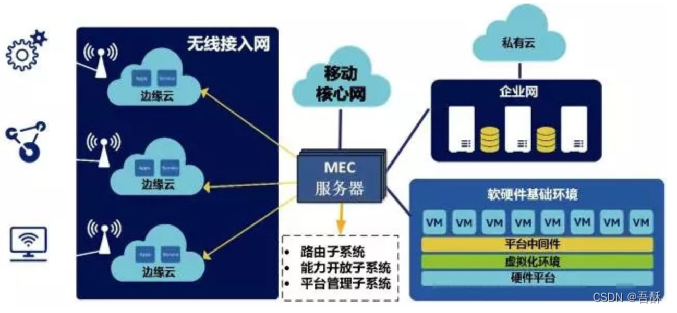
到目前为止,边缘计算还没有一个好的框架,框架仅供参考
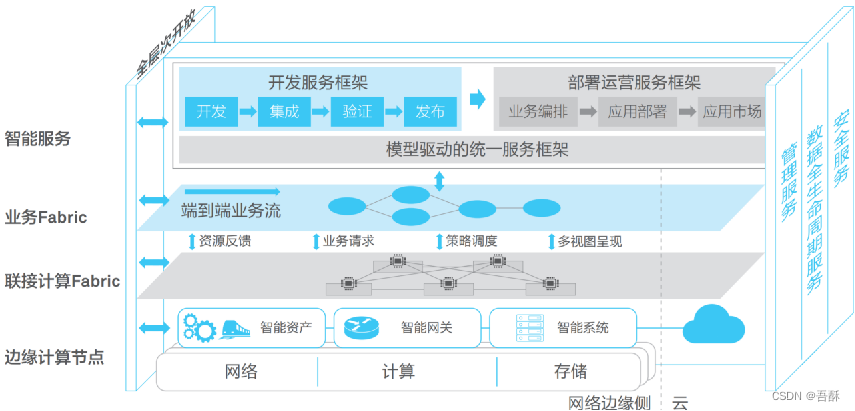
边缘计算参考框架 – 制造
Windows环境下的exe不能在Linux上运行,不同操作系统的运行环境不一样,x86和ARM在CPU指令集上都不一样,对于边缘计算来说,异构非常常见,如树莓派基于ARM CPU、NVIDIA Jetson Nano基于GPU、iPhone基于iOS、Huawei Mate 20基于Android等等…
同样的功能,在不同的环境下运行的要求不同,若是对每一个异构都重写一遍,代价太高。
核心挑战:如何编写一个应用程序可以将其分布式部署在边缘计算框架中
命名(Naming),即定位资源。例如,监控系统需要用到某个摄像头,若是单机操作,可以根据文件路径命名摄像头,例如,open(/dev/camera0)。但边缘计算框架可能会用到非本地摄像头,怎么处理?一个简单的想法是通过IP地址来找到具体节点,IPV4够用吗?IPV6有具体的较为明确的含义吗?如果有很多很多不同地点的摄像头,我们要记下来一堆没有任何规律的IP地址吗?
核心挑战:资源如何命名来使其适合于大规模动态异构环境?
计算资源隔离:即应用程序间不能相互干扰。
数据的隔离:即不同应用程序应具有不同的访问权限。
边缘计算更复杂,更容易出现错误,却要求更可靠
Docker: 普遍应用的Docker技术可以实现应用在基于0S级虚拟化的隔离环境中运行
docker介绍:https://www.cnblogs.com/idktp/articles/10538872.html
和网络一样,边缘计算也会形成一种网络,具有动态性,下一刻可能会有新节点的加入,也会有旧节点的退出。动态环境有三个步骤:服务发现、快速配置以及负载均衡。
服务发现:计算服务请求者如何知道周边的服务。
快速配置:节点移动、设备开关会造成服务的动态注册和撤销,服务通常也需要跟着进行迁移……
负载均衡:数据、需求、服务、网络、计算、能耗等很多因素决定负载均衡
ROS有可能成为边缘计算场景的典型操作系统
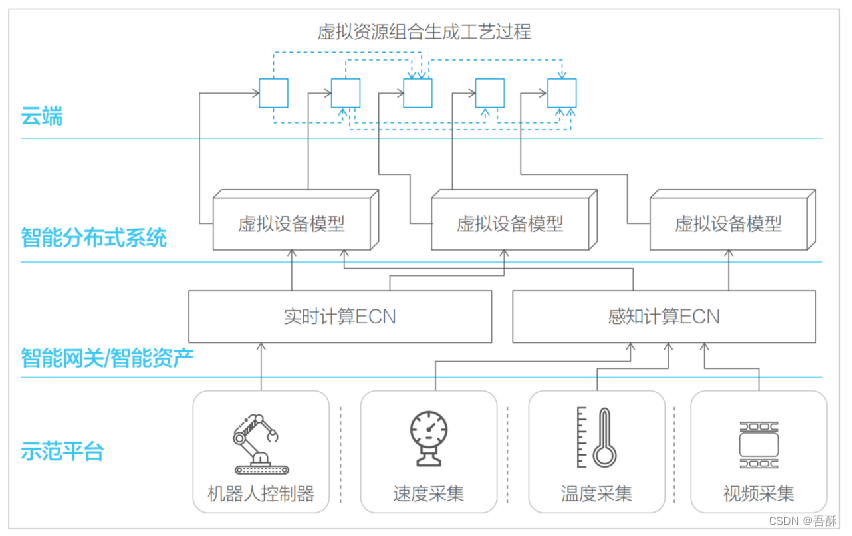
OpenVDAP(2018,韦恩州立大学)
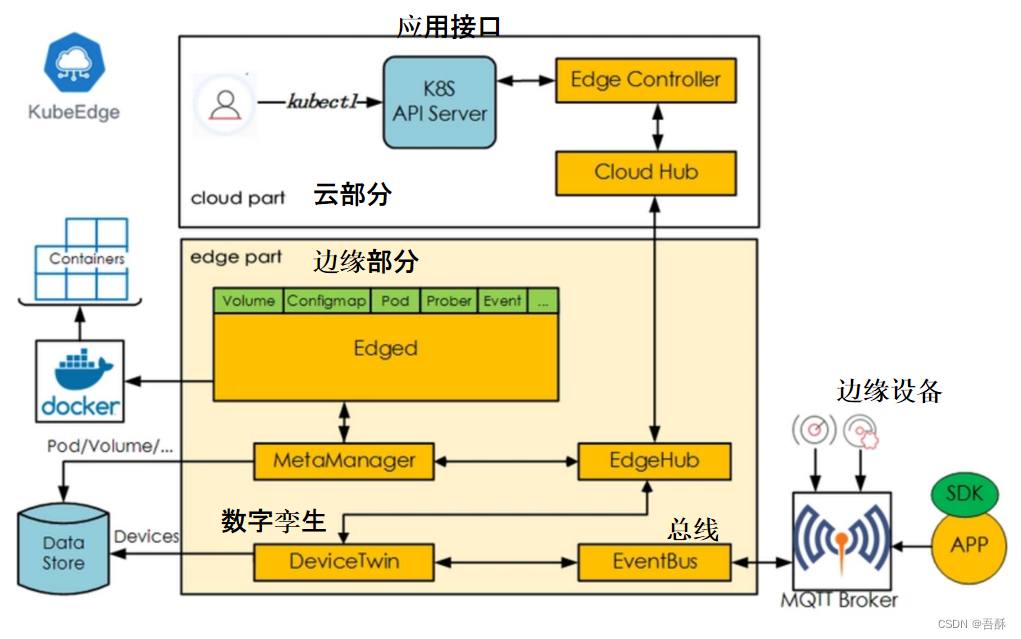
KubeEdge(华为)
Azure IoT Edge(2017,微软)
OpenEdge(2018.12,百度)
哈工大《边缘计算与嵌入式智能》笔记
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
Ruby中如何“一般地”计算以下格式(有根、无根)的JSON对象的数量?一般来说,我的意思是元素可能不同(例如“标题”被称为其他东西)。没有根:{[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]}根包裹:{"posts":[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]} 最佳答案 首先,withoutroot代码不是有效的json格式。它将没有包
目标我正在尝试计算自给定日期以来周的距离,而无需跳过任何步骤。我更喜欢用普通的Ruby来做,但ActiveSupport无疑是一个可以接受的选择。我的代码我写了以下内容,这似乎可行,但对我来说似乎还有很长的路要走。require'date'DAYS_IN_WEEK=7.0defweeks_sincedate_stringdate=Date.parsedate_stringdays=Date.today-dateweeks=days/DAYS_IN_WEEKweeks.round2endweeks_since'2015-06-15'#=>32.57ActiveSupport的#weeks
技术选型1,前端小程序原生MINA框架cssJavaScriptWxml2,管理后台云开发Cms内容管理系统web网页3,数据后台小程序云开发云函数云开发数据库(基于MongoDB)云存储4,人脸识别算法基于百度智能云实现人脸识别一,用户端效果图预览老规矩我们先来看效果图,如果效果图符合你的需求,就继续往下看,如果不符合你的需求,可以跳过。1-1,登录注册页可以看到登录页有注册入口,注册页如下我们的注册,需要管理员审核,审核通过后才可以正常登录使用小程序1-2,个人中心页登录成功以后,我们会进入个人中心页我们在个人中心页可以注册人脸,因为我们做人脸识别签到,需要先注册人脸才可以进行人脸比对,进
如何计算两个字符串之间的字符交集?例如(假设我们有一个名为String.intersection的方法):"abc".intersection("ab")=2"hello".intersection("hallo")=4好的,男孩女孩们,感谢你们的大量反馈。更多示例:"aaa".intersection("a")=1"foo".intersection("bar")=0"abc".intersection("bc")=2"abc".intersection("ac")=2"abba".intersection("aa")=2一些补充说明:维基百科定义intersection如下:Int