数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,将它们加以汇总和理解并消化,以求最大化地开发数据的功能,发挥数据的作用,使得数据的价值最大化
数据分析是为了提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。 数据分析的数学基础在20世纪早期就已确立,但直到计算机的出现才使得实际操作成为可能,并使得数据分析得以推广。
数据分析使用适当的方法对收集来的大量数据进行分析,帮助人们做出判断,以便采取适当的行动
官网:https://www.anaconda.com 下载安装对应安装包即可
注意: 安装目录不可以有中文和特殊符号
Anaconda集成好了数据分析和机器学习中所需要的全部环境
启动: 在终端中输入:jupyter notebook,按下回车即可
新建文件: New -->> python3
Cell(代码块)有两种模式
快捷键
添加cell:a或b
删除:x
修改cell的模式
my执行cell内代码:shift+enter
自动补全:tab
打开帮助文档:shift+tab
在Python中我们数据分析离不开以下三剑客
array()创建一个一维数组
array() 创建一个多维数组
zero() 创建一个多维数组
ones() 创建一个多维数组
linspace() 创建一维的等差数列数组
arange() 创建一维的等差数列数组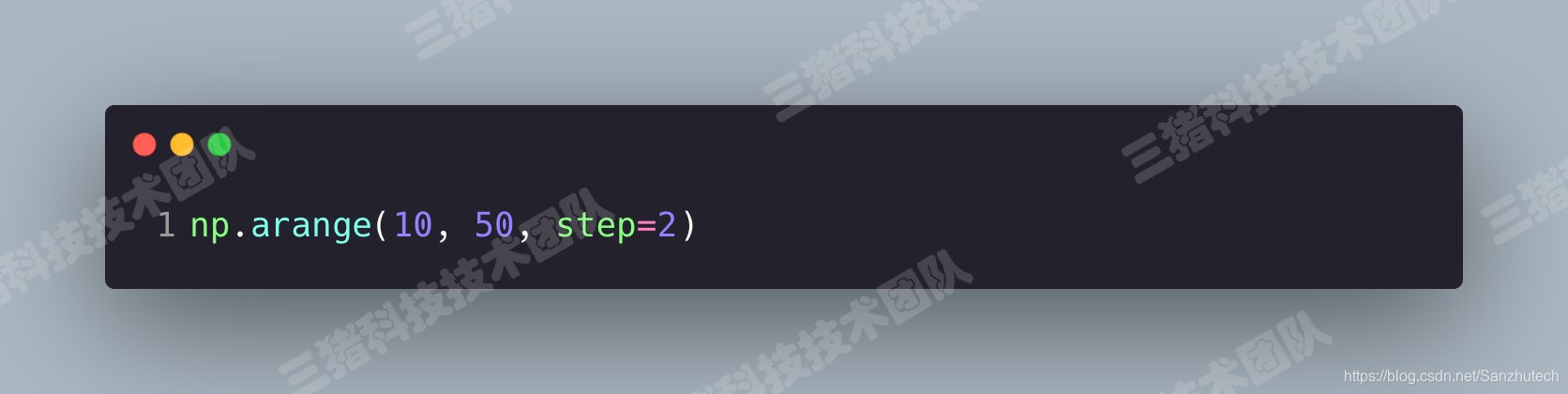
random.randint() 创建随机的多维数组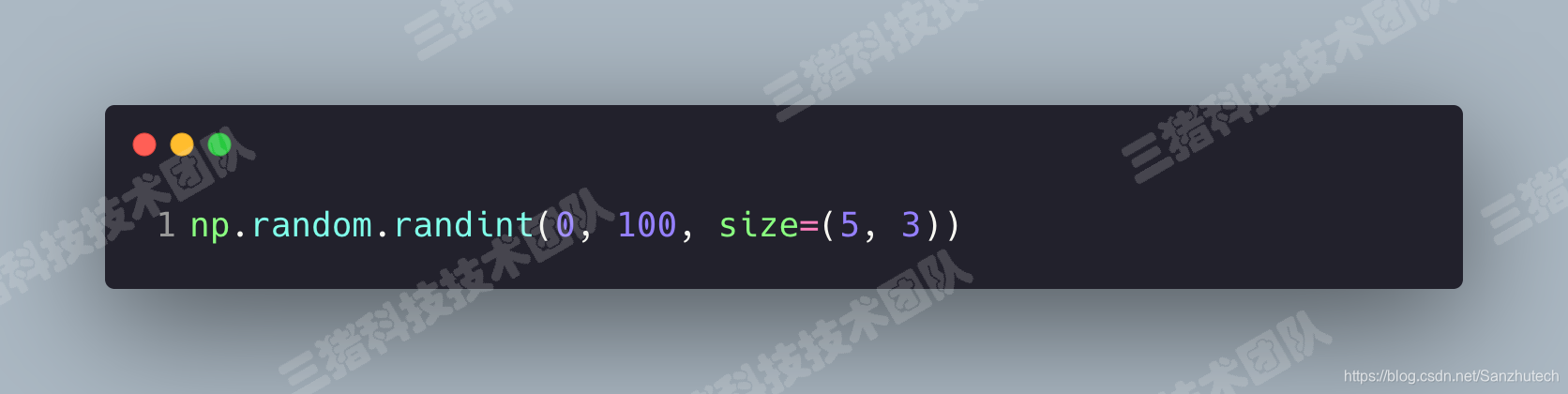




级联操作

常用的聚合操作
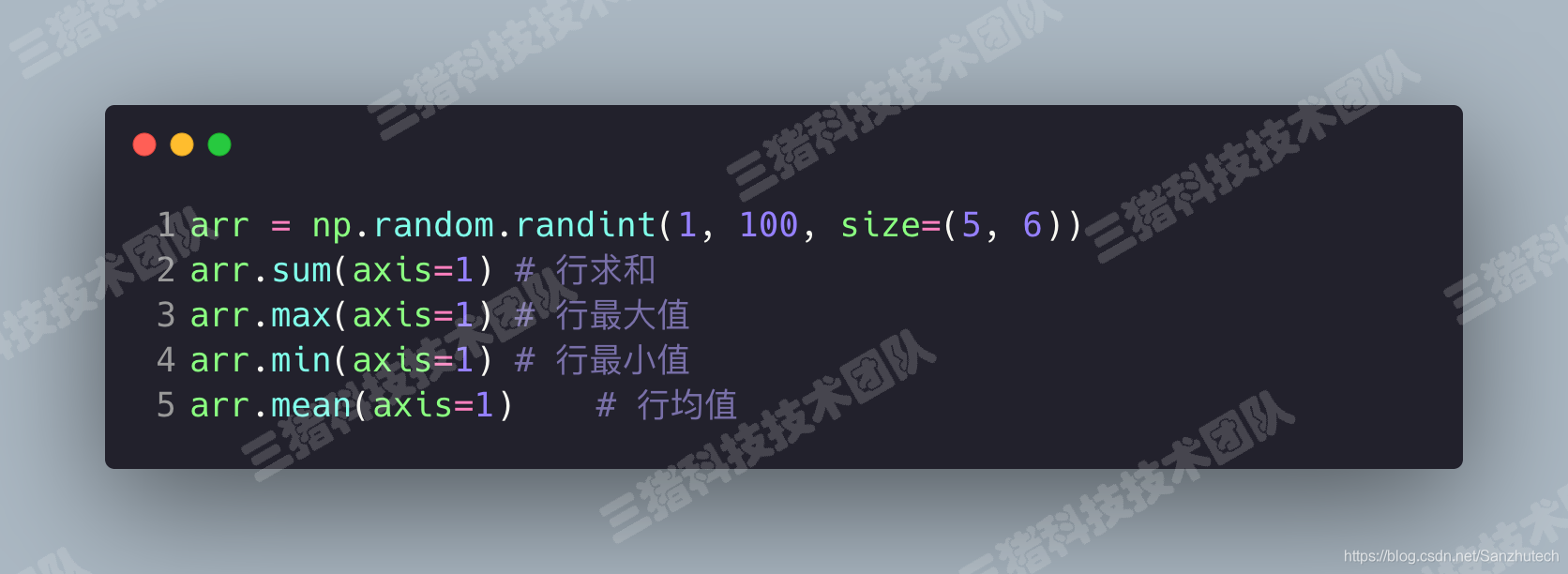
常用的统计函数
mean((x-x.mean())**2。换句话说,标准差就是方差的平方根。
Numpy能够帮助我们处理的是数值型的数据,而Pandas可以帮我们处理除数值型以外的其他类型数据,

index用来指定显式索引,可以增强Series的可读性。

也可以使用字典作为数据源。



head(), tail()unique()isnull(), notnull()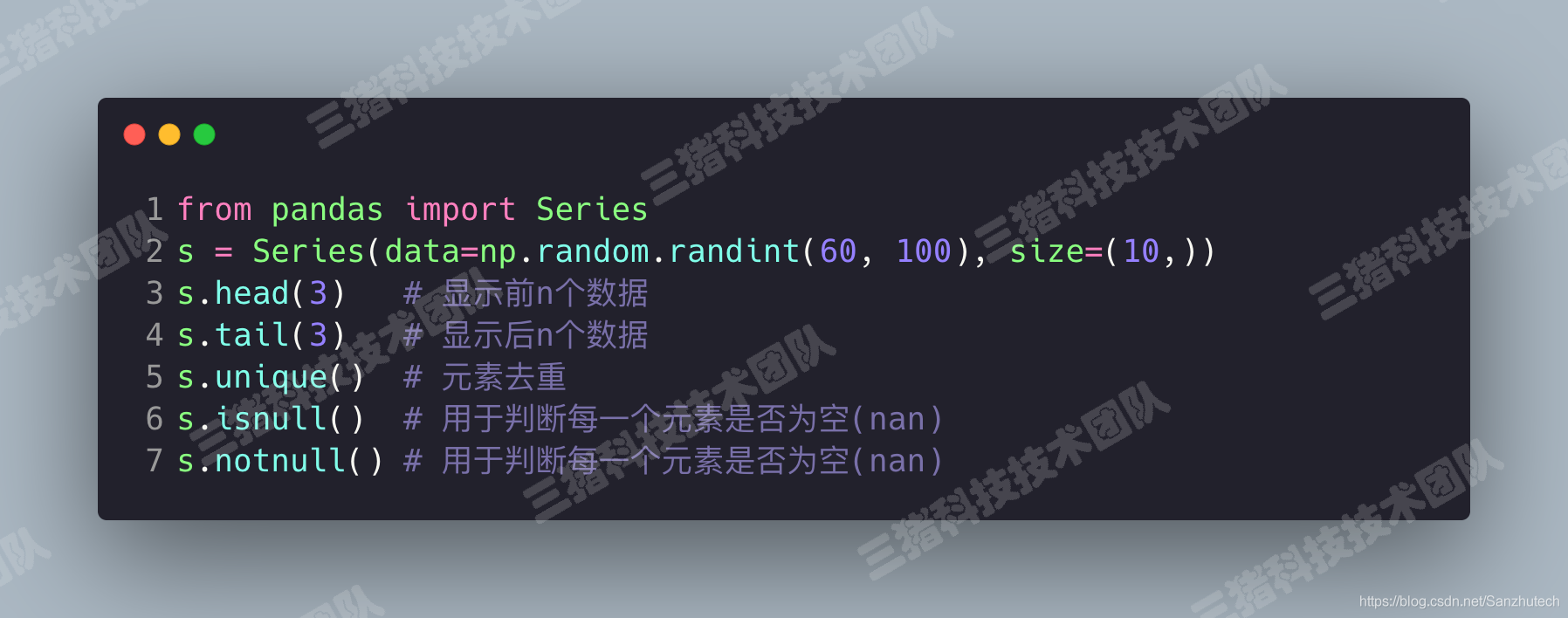
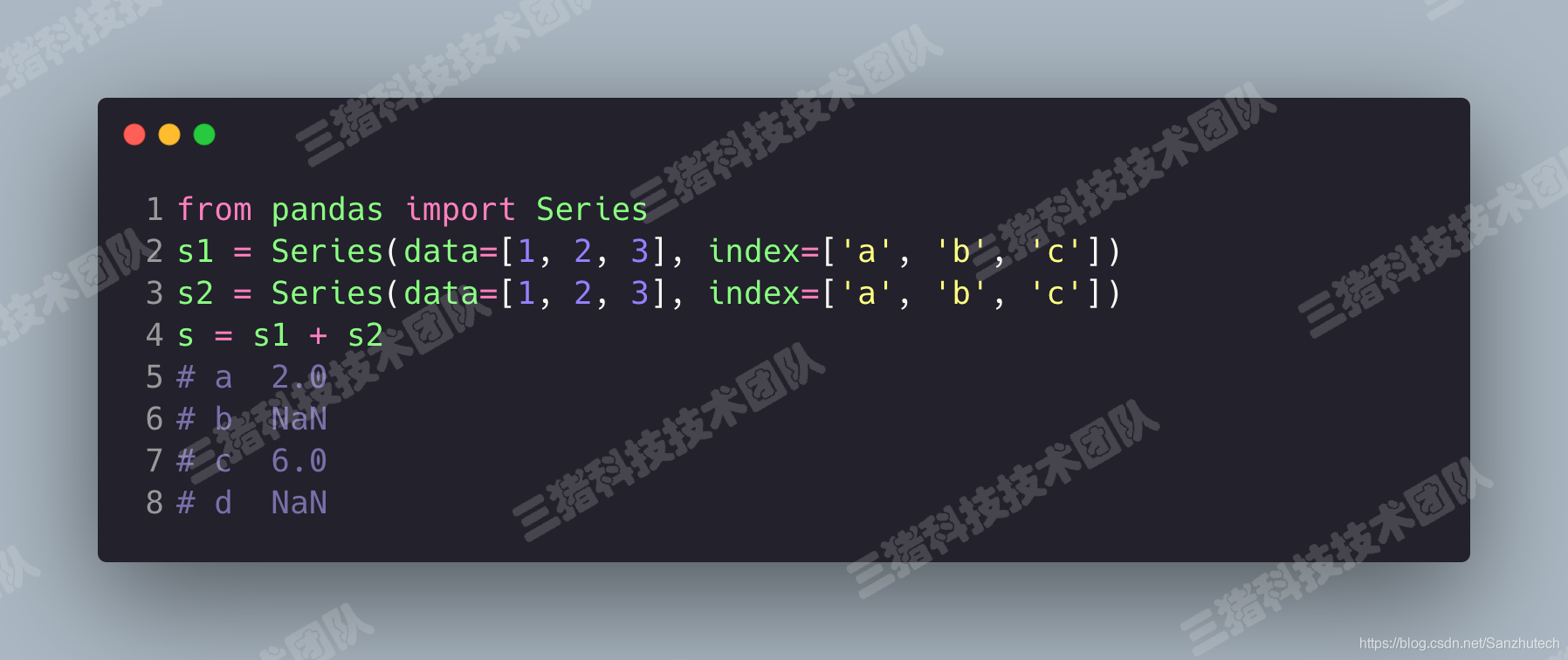
索引一致的元素进行算数运算否则补空

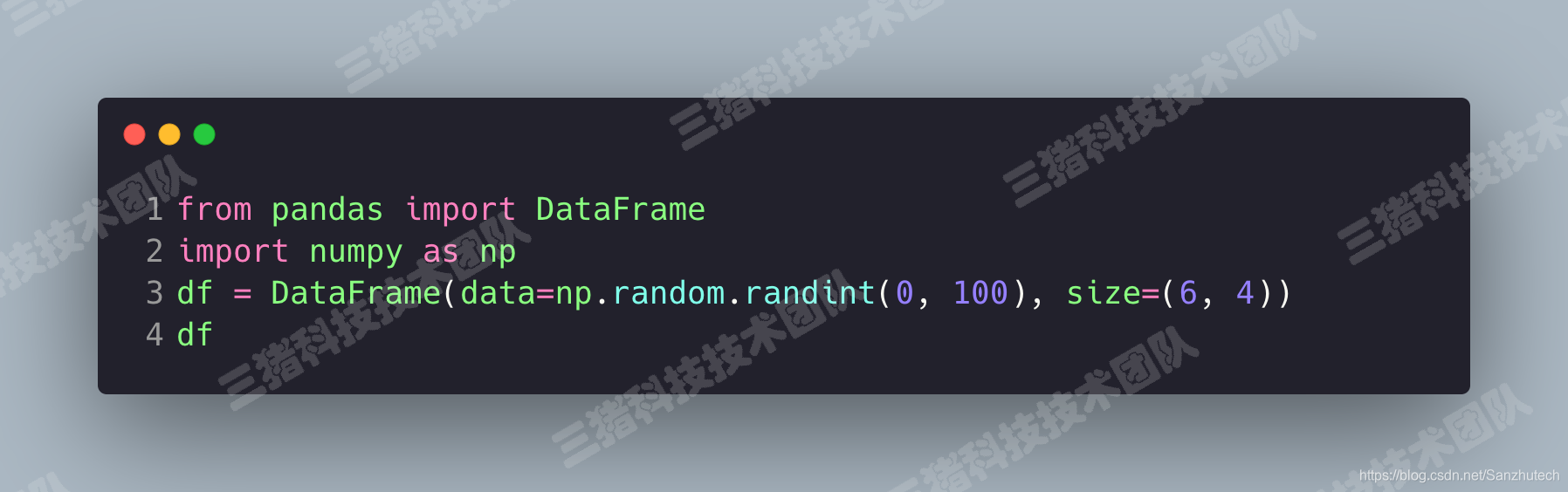
可使用 ndarray 创建。
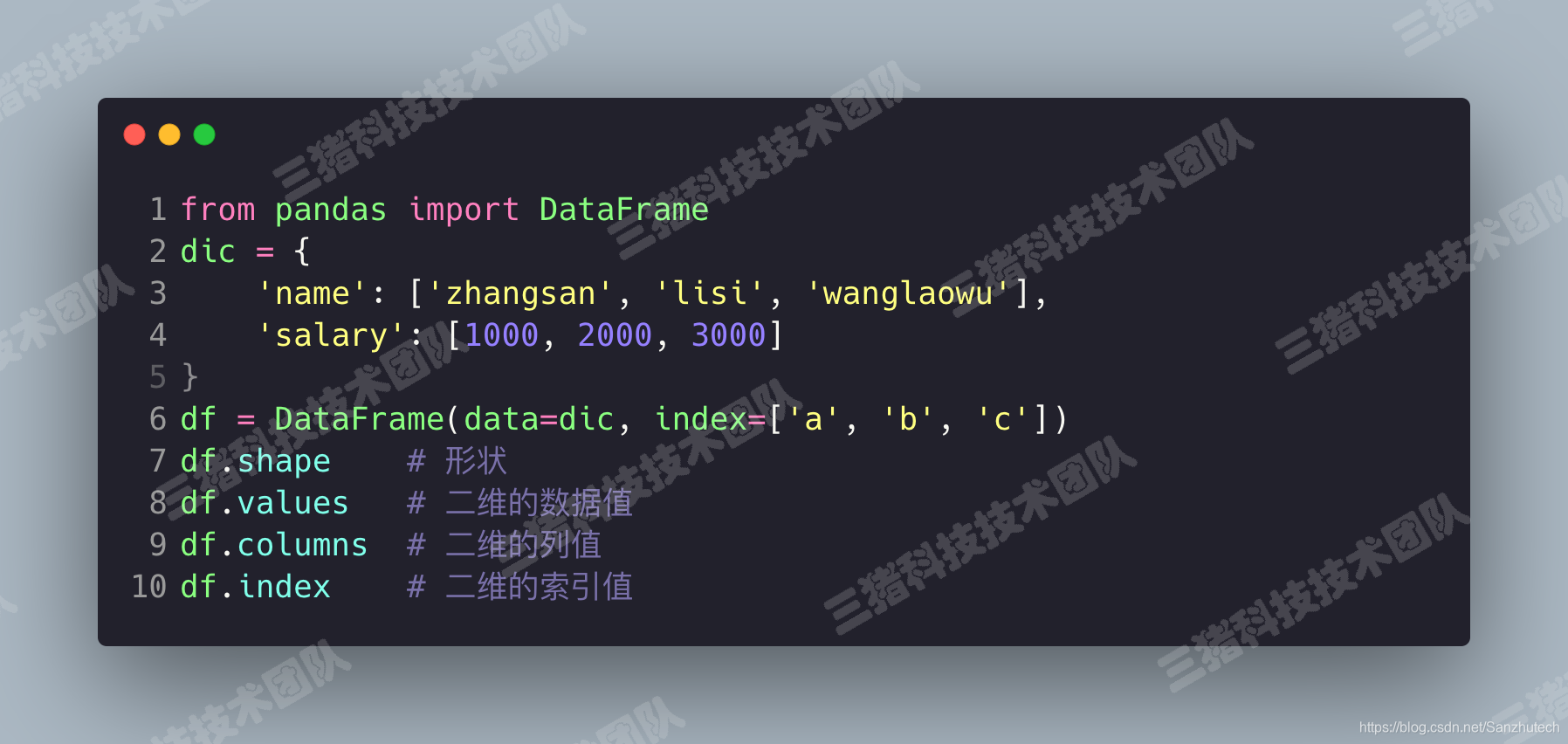
也可以使用字典作为数据源。

index 用来指定显式索引,可以增强 DataFrame 的可读性。

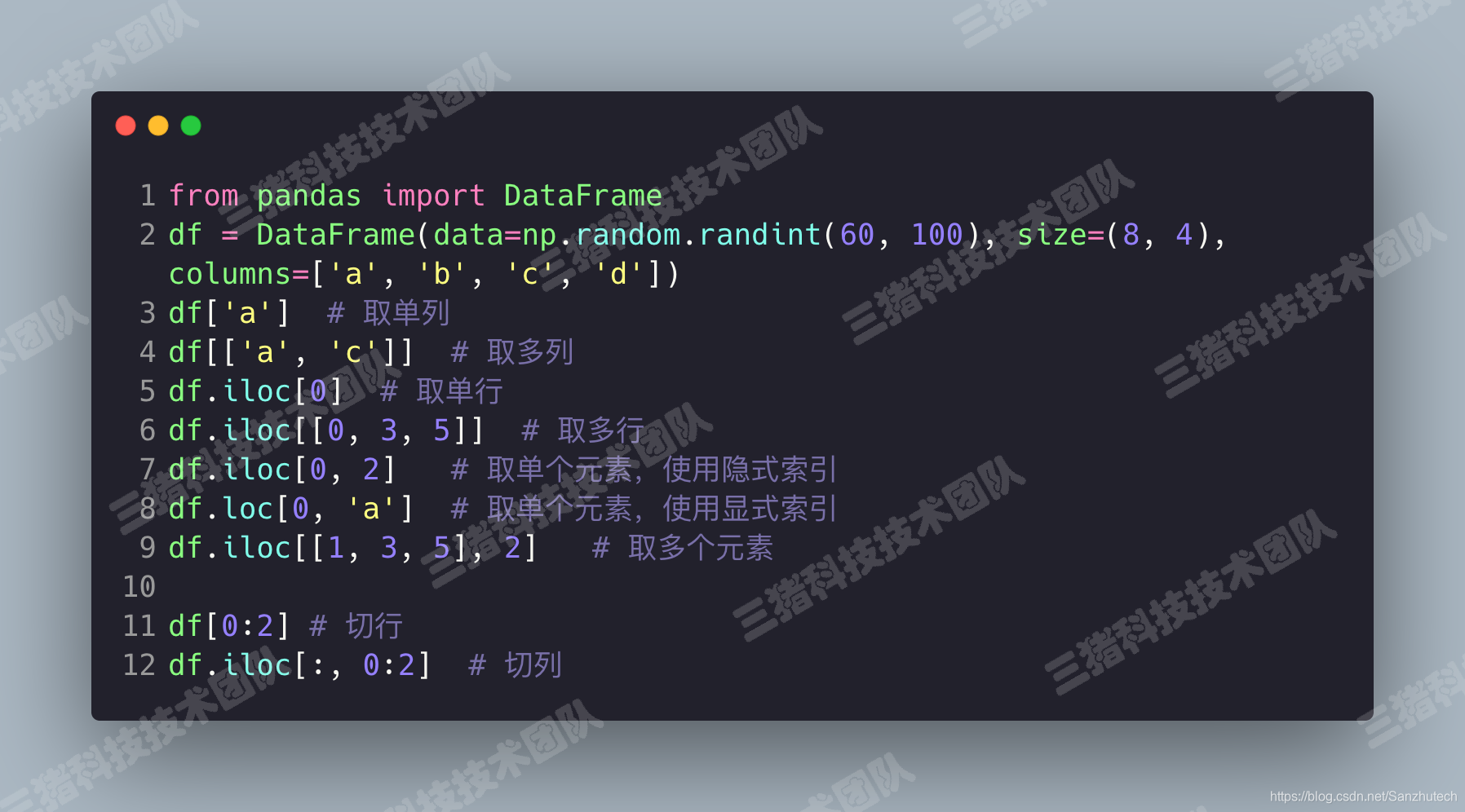
iloc: 通过隐式索引取行
loc: 通过显式索引取行
对行进行切片
对列进行切片
同Series
同Series
级联操作
接下来我们伪造两组DataFrame数据。
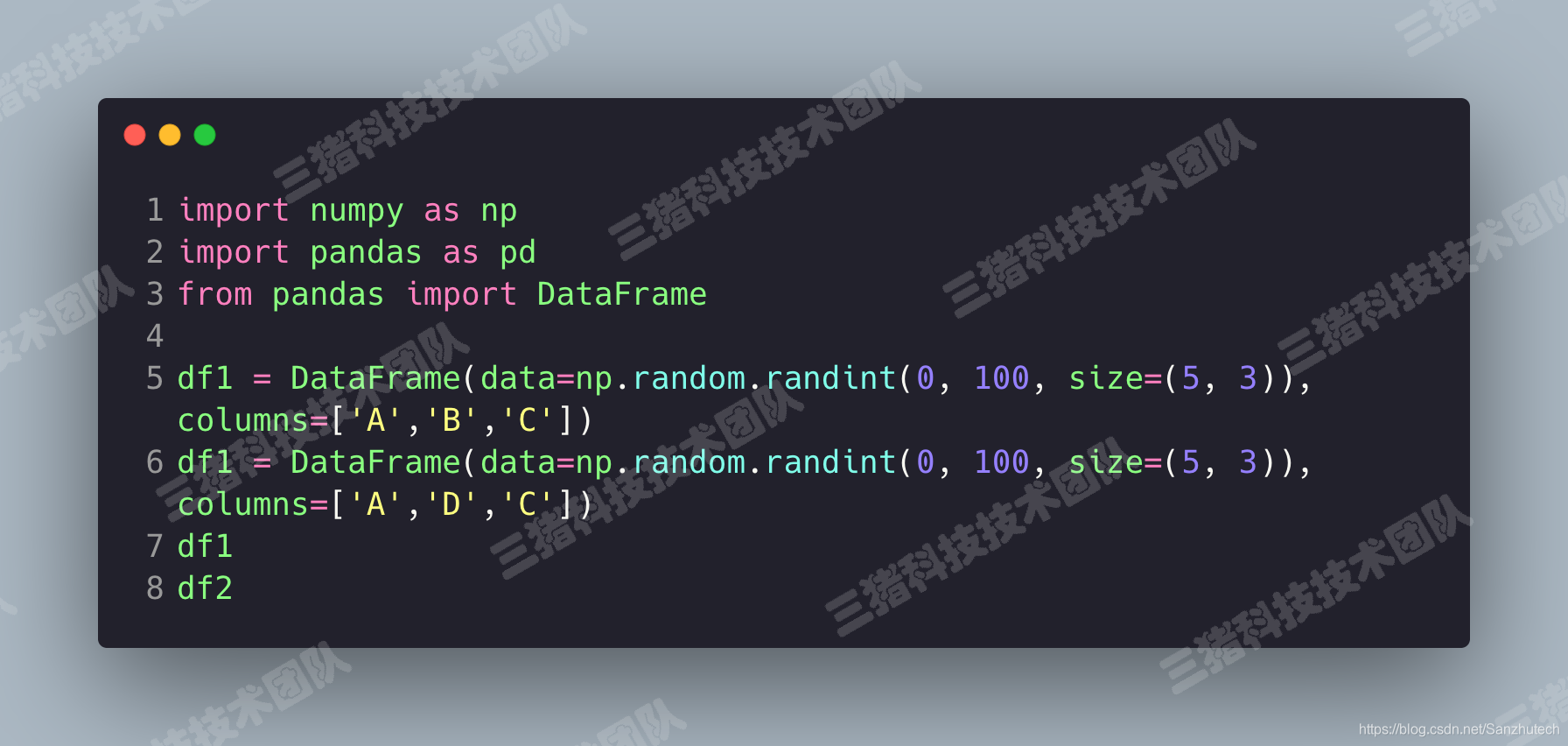
使用pd.concat()

PS:如果想要保留数据的完整性必须使用参数 join='outer'(外连接)
使用 pd.append()

合并操作
pd.merge()
merge 与 concat 的区别在于,merge 需要依据某一共同列来进行合并。pd.merge() 合并时,会自动根据两者相同 column 名称的那一列作为 key 来进行合并。一对一合并
首先我们来伪造两组 DataFrame。
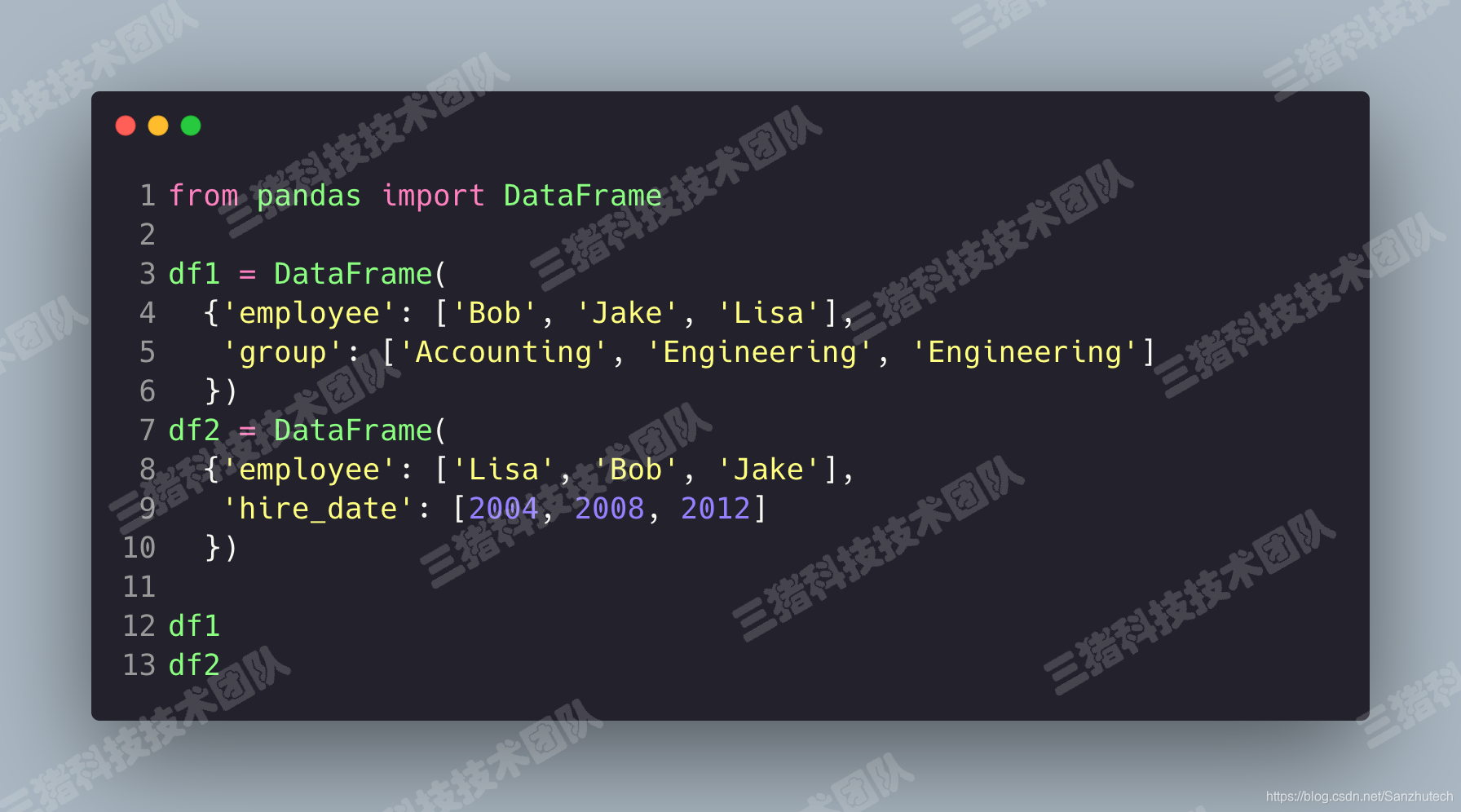
使用 pd.merge()

一对多合并
首先我们来伪造两组 DataFrame。
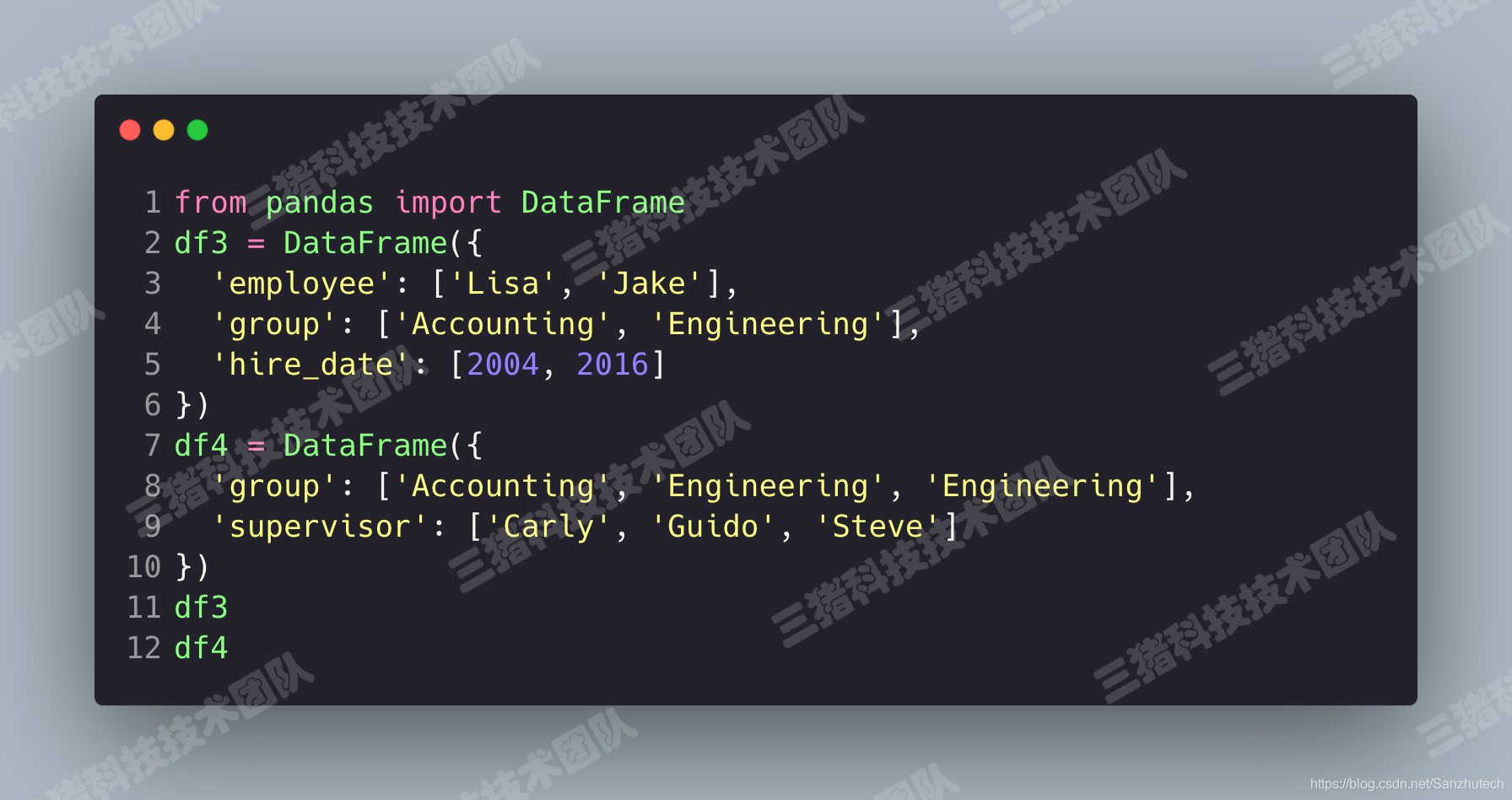
使用 pd.merge()

多对多合并
首先我们来伪造两组 DataFrame。
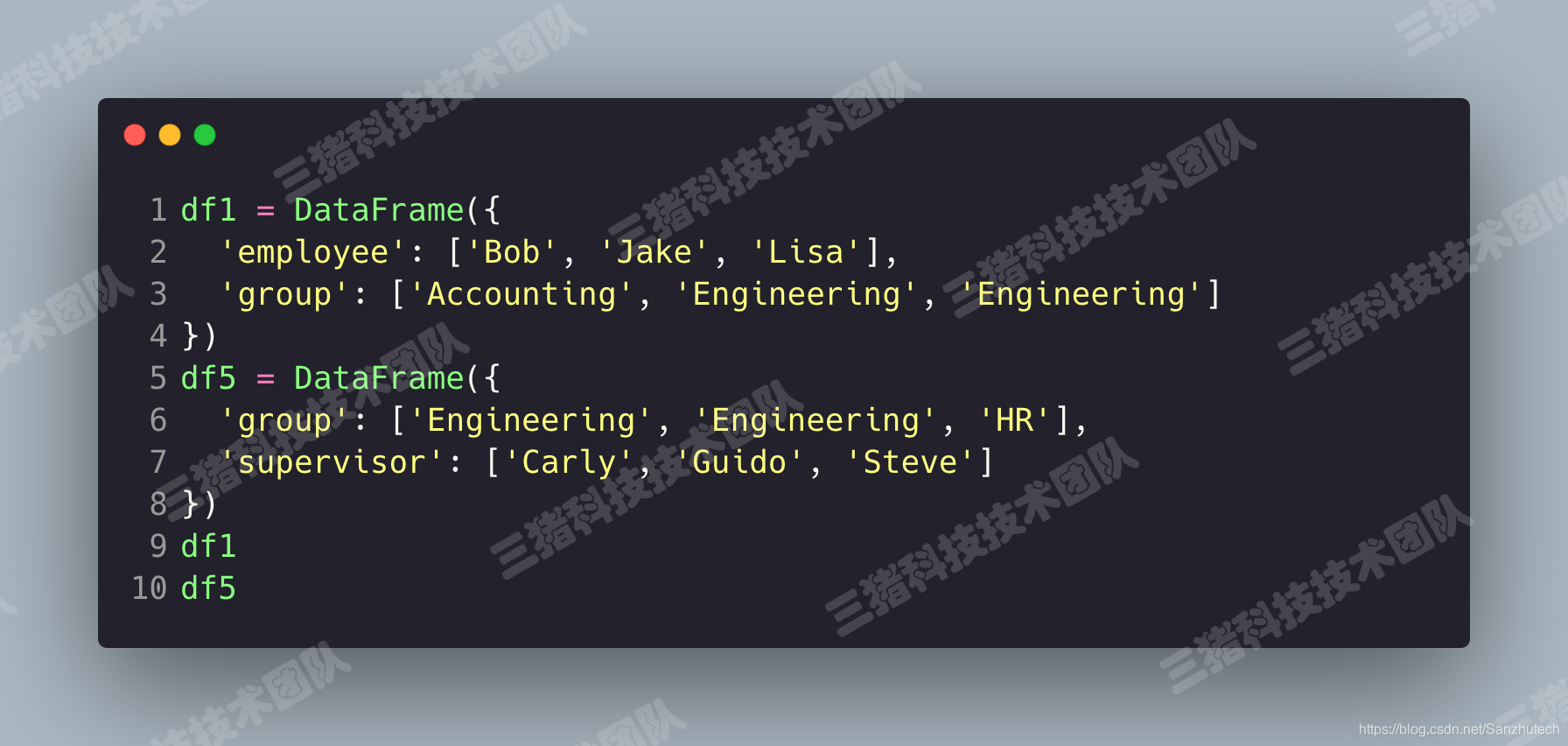
使用 pd.merge()
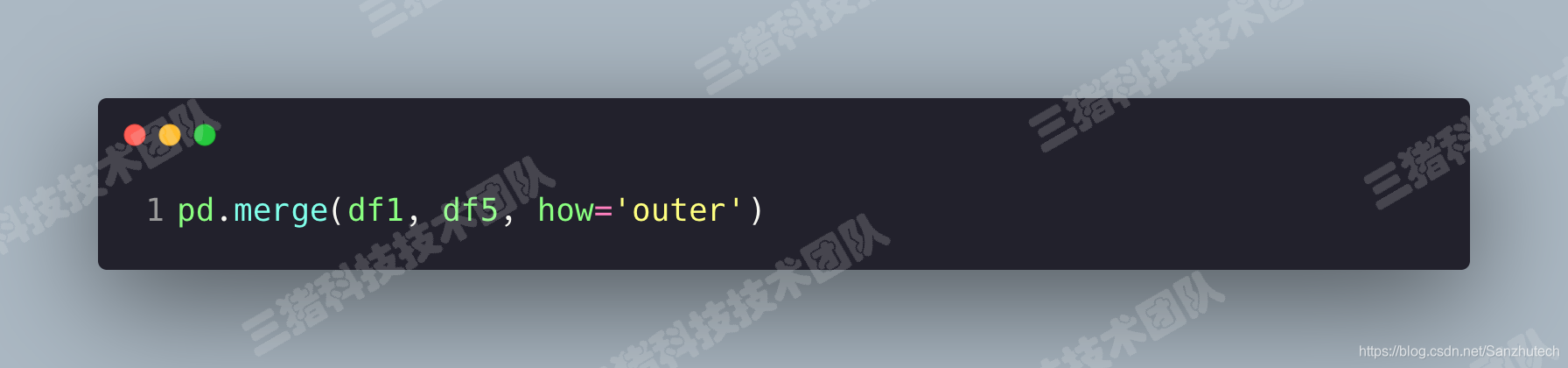
merge()方法还可以使用left_on参数和right_on参数哦,how这个参数也可以指定不同的连接方式。
为什么在数据分析中需要用到浮点类型的空而不是对象类型的?
None+1会报 TypeError,而 np.nan+1 结果是 nan。它不会干扰或者中断运算。在Pandas中如果数据中遇到了None形式的空值则Pandas会将其强转成NaN的类型。
缺失值处理操作
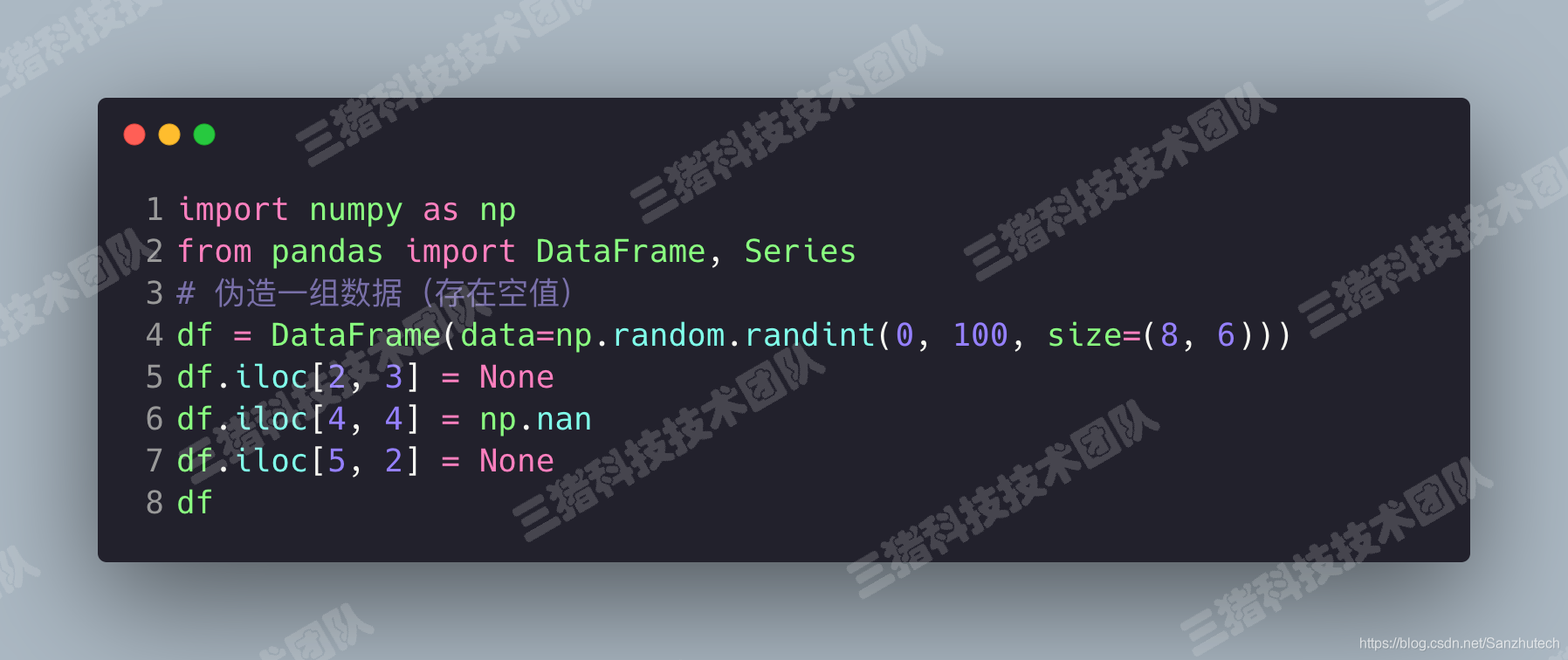
我们来伪造一组带有缺失值的数据。
方法1:对缺失值进行过滤(删除空所在的行数据)
isnull() 搭配 any()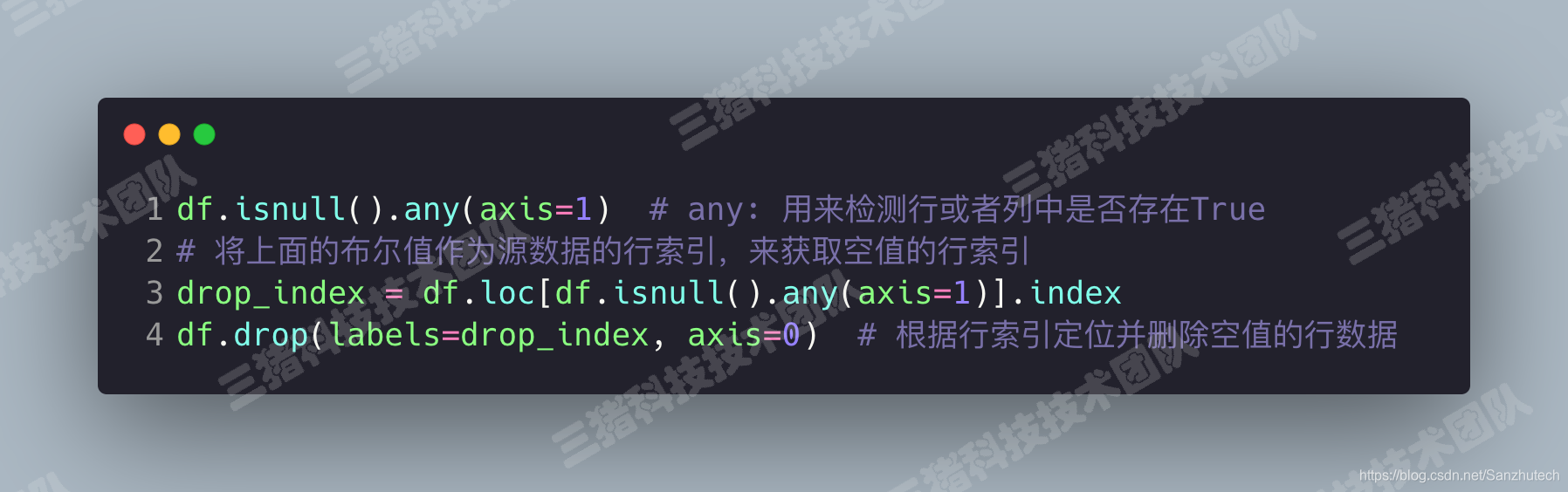
notnull() 搭配 all()
dropna()可以直接将缺失的行或者列数据进行删除
fillna() 对缺失值进行填充
我们来伪造一组带有重复值的数据。
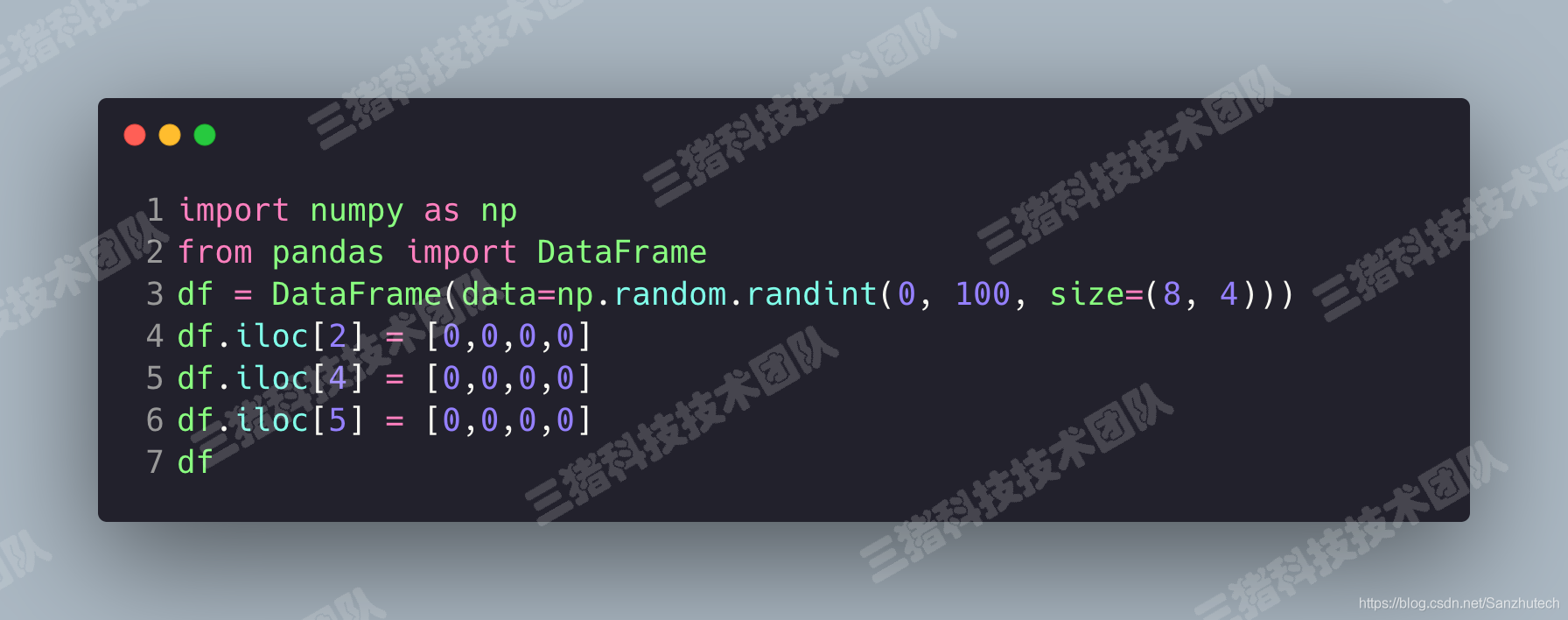
drop_duplicates()
异常值是什么?
接下来我们伪造一组带有异常值的数据。

然后我们来实现异常值的清洗。

to_replace=15, value='value'to_replace={列标签: 替换值}, value='value'to_replace=[], value=[]to_replace={to_replace: value, to_replace: value}首先我们来伪造一组DataFrame。

使用 replace()

首先我们来伪造一组DataFrame。

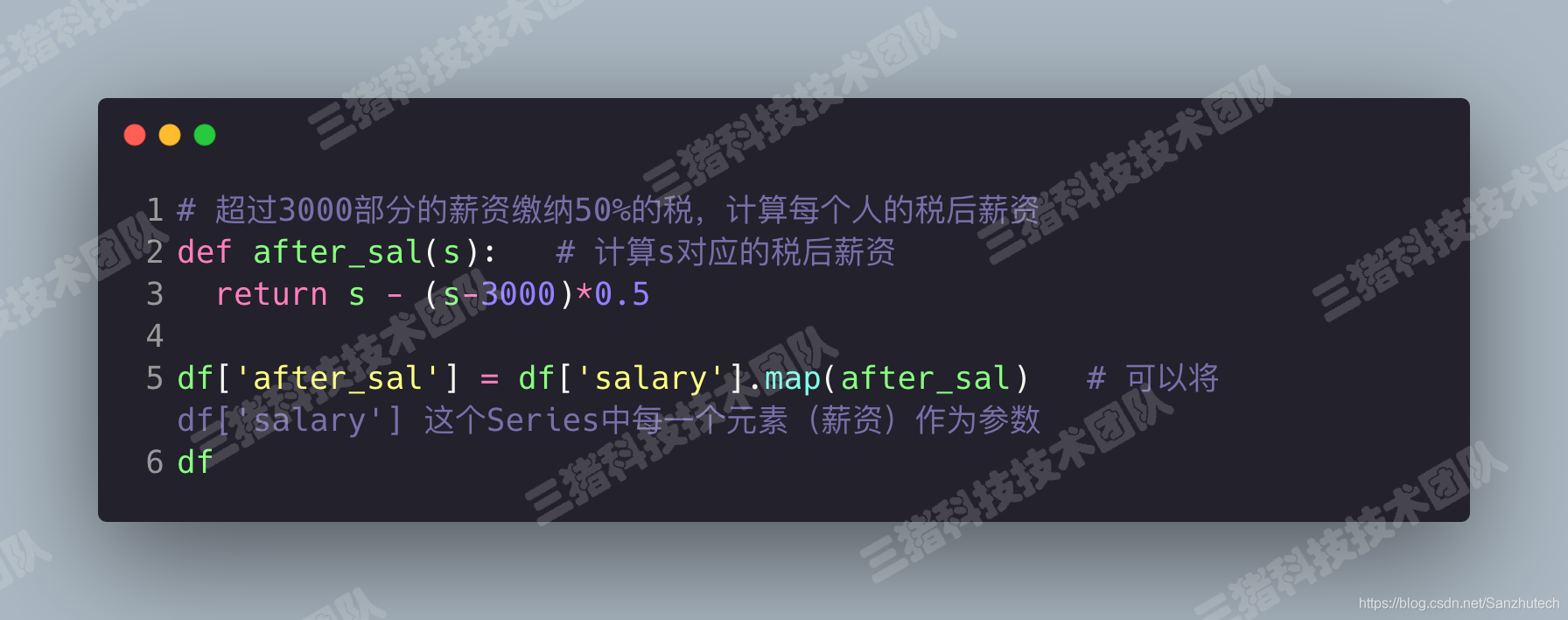
使用 map()

例:超过3000部分的薪资缴纳50%的税,计算每个人的税后薪资
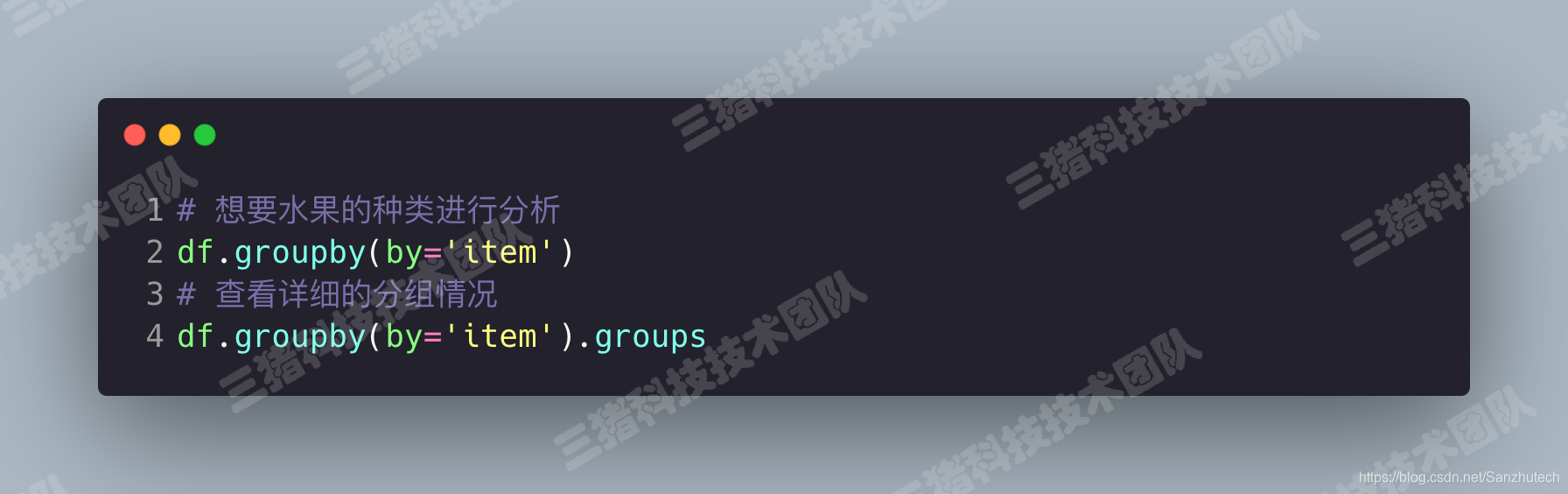
groupby() 函数groups 属性查看分组情况分组
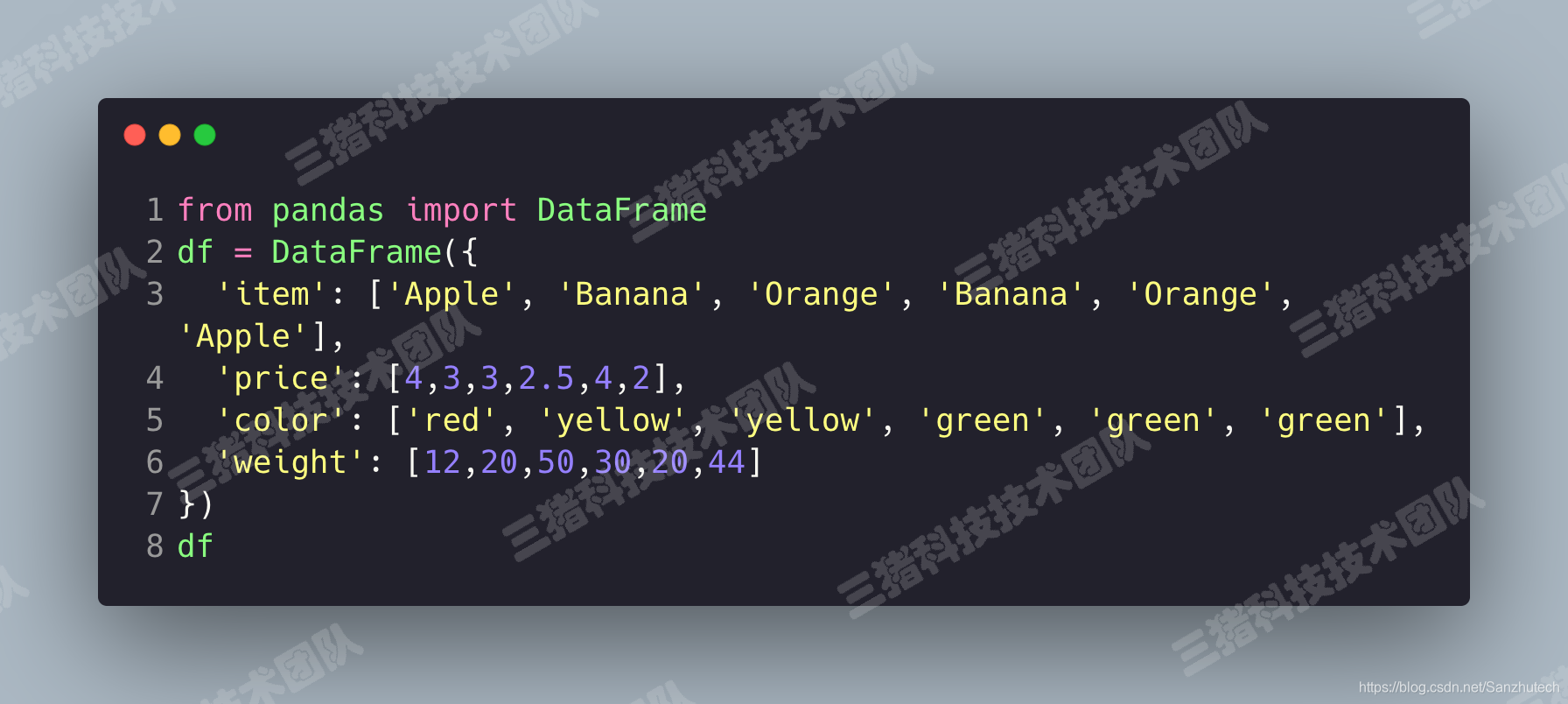
接下里我们伪造一组DataFrame。
使用 groupby() 和 groups
聚合
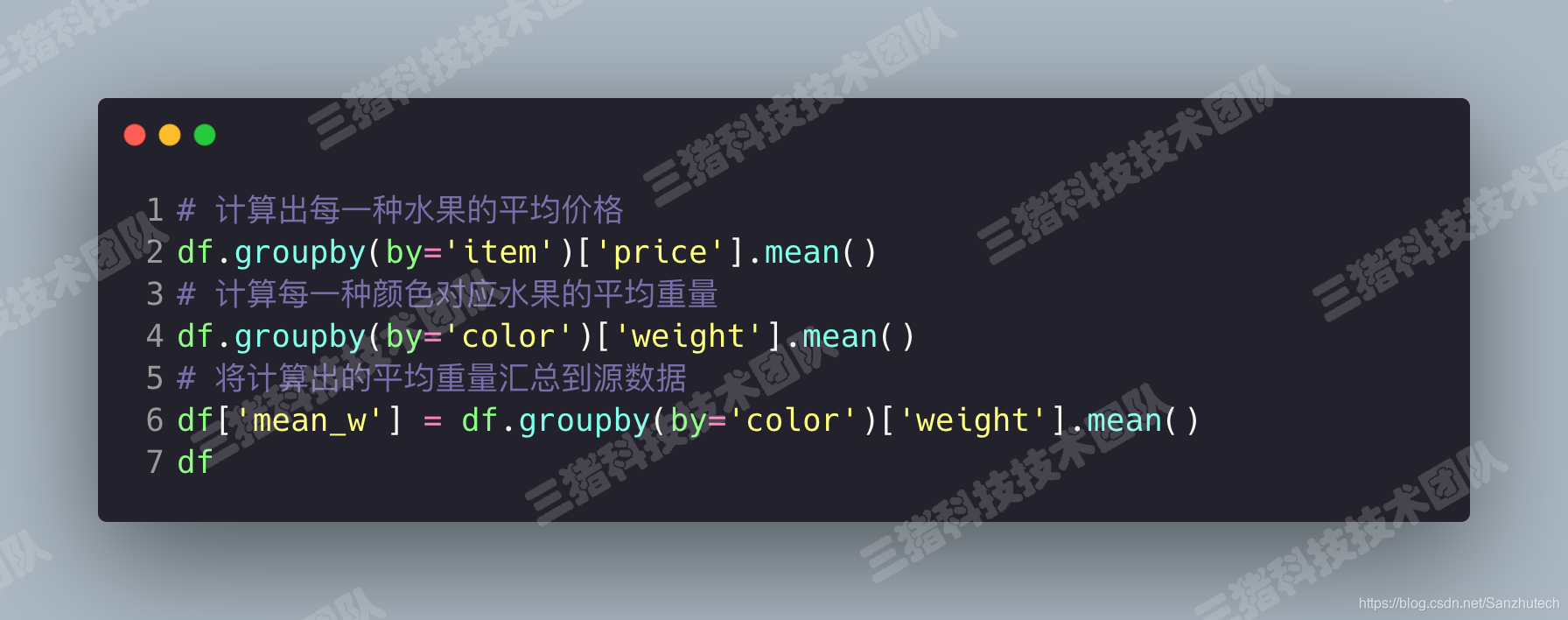
高级数据聚合
groupby() 分组后,也可以使用 transform() 和 apply() 提供自定义函数实现更多的运算df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum)transform() 和 apply() 都会进行运算,在 transform() 或者 apply() 中传入函数即可transform() 和 apply() 也可以传入一个 lambda 表达式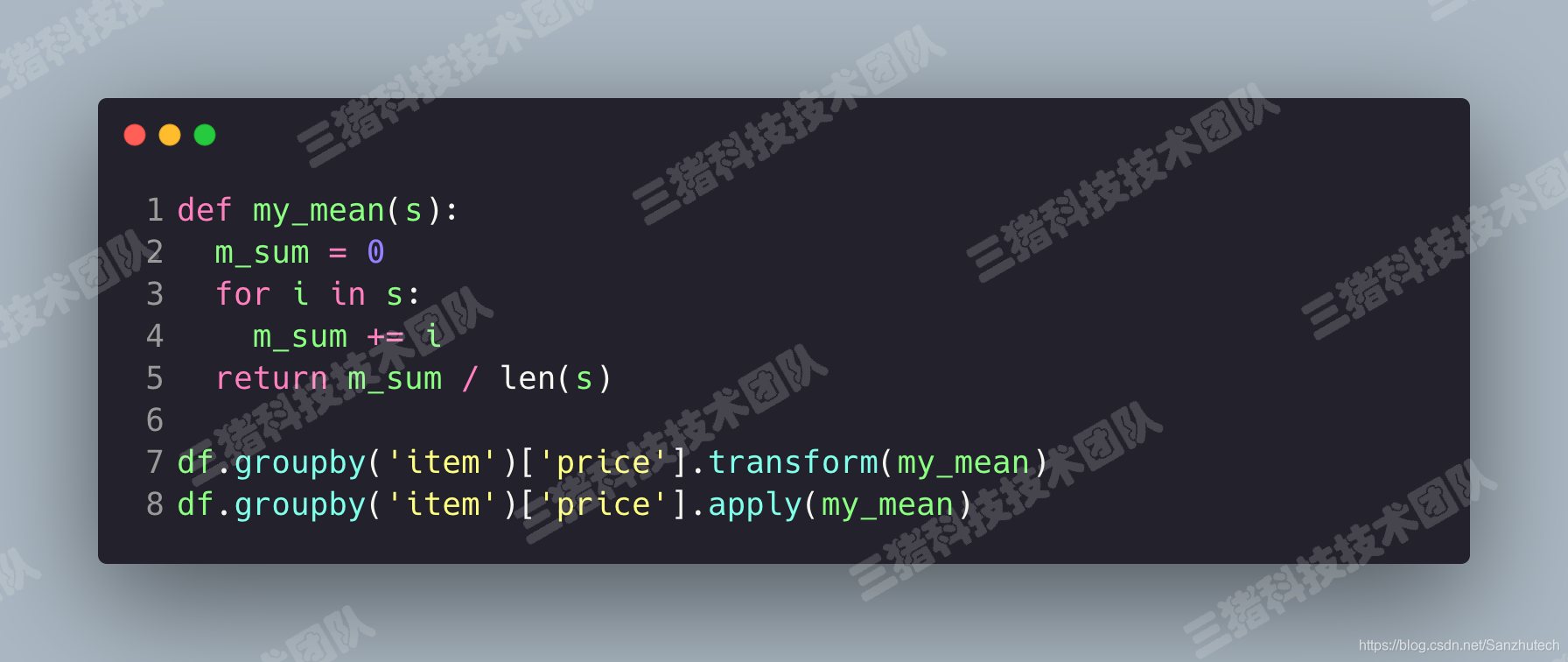

首先我们倒入全局的模块






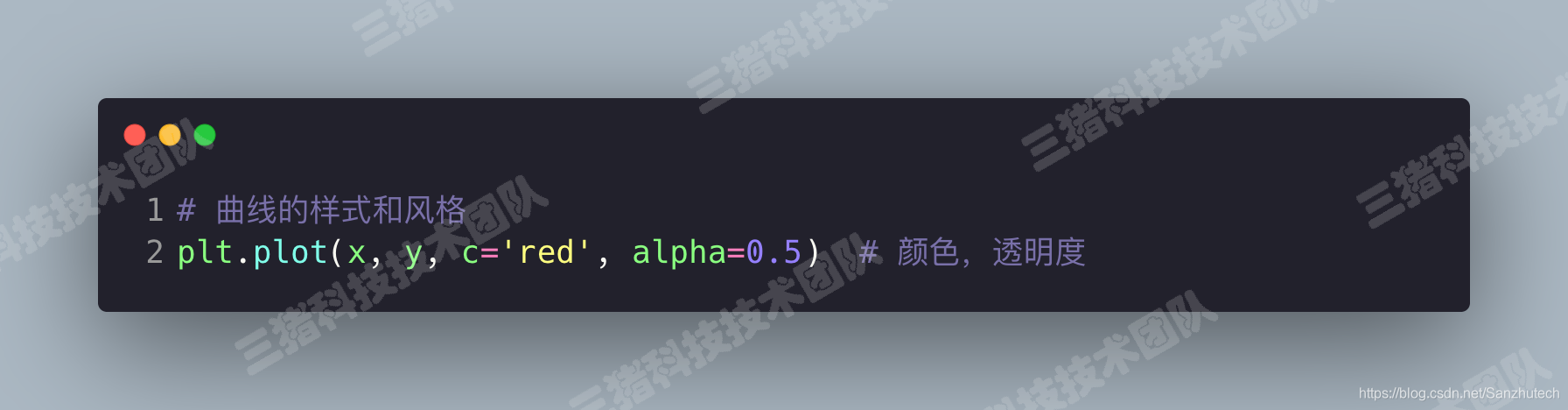
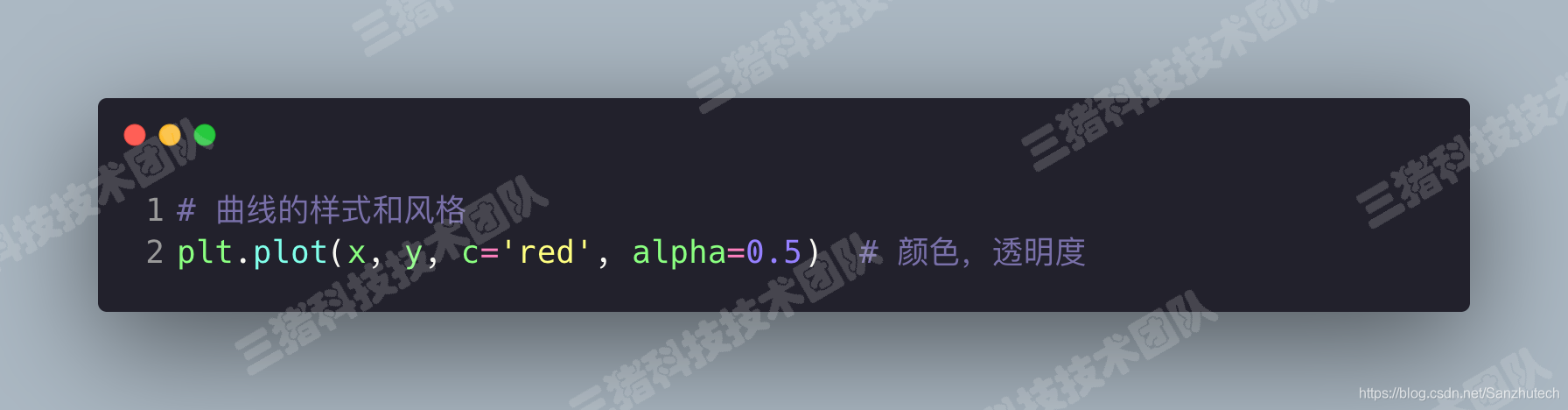
还有其他多种参数的样式哦,详情请见库的源代码。
其余用法和线形图类似。
plt.hist()的参数
bins:可以是一个bin数量的整数值,也可以是表示bin的一个序列。默认值为10normed:如果值为True,直方图的值将进行归一化处理,形成概率密度,默认值为Falsecolor:指定直方图的颜色。可以是单一颜色值或颜色的序列。如果指定了多个数据集合,例如DataFrame对象,颜色序列将会设置为相同顺序。如果未指定,将会使用一个默认的线条颜色orientation:通过设置 orientation 为 horizontal 创建水平直方图。默认值为 vertical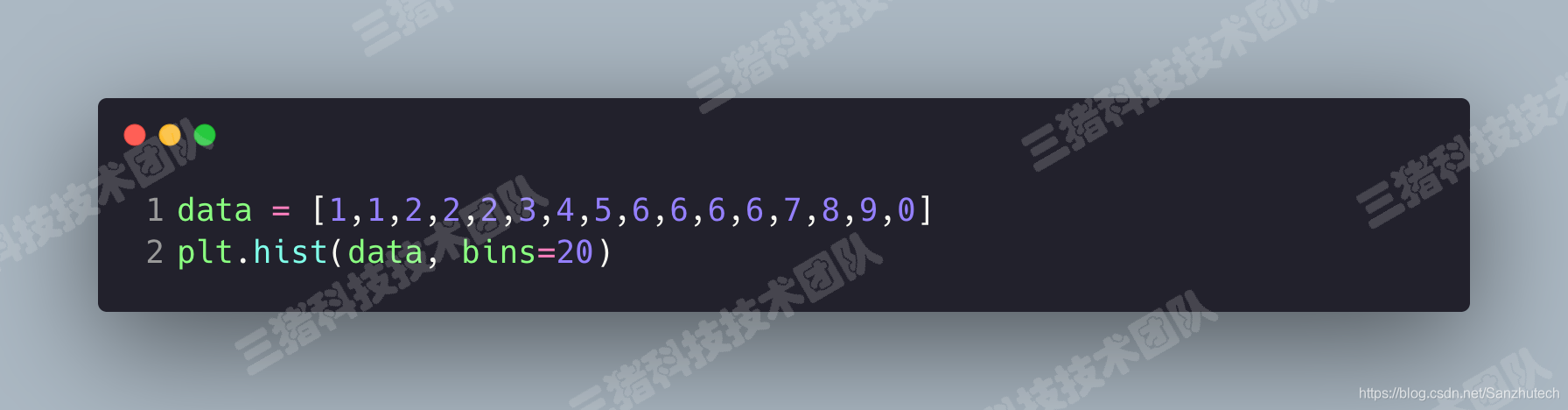
其余用法和线形图类似。
pie(),饼图也只有一个参数 x
其余用法和线形图类似。
scatter(), 因变量随自变量而变化的大致趋势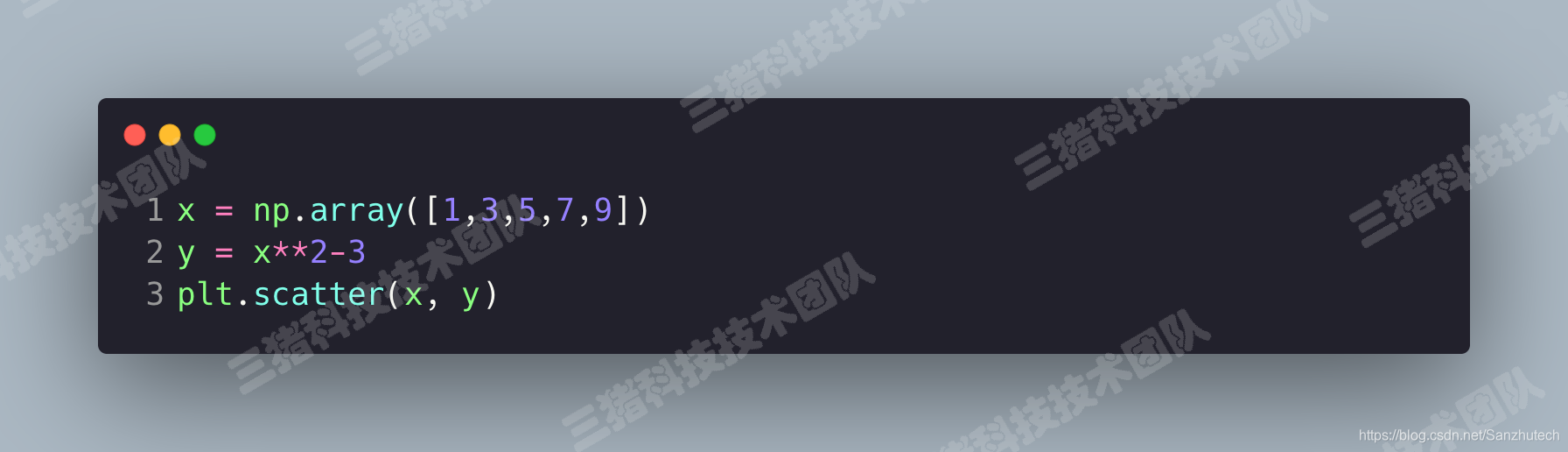
其余用法和线形图类似。
PS:欢迎提出宝贵意见,如想询问技术问题可以留言区留言或加开发人员的微信(微信号:x118422)进行咨询~
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po