参考博客:https://www.cnblogs.com/fuzongle/p/12760193.html
(完成难度:低)
(完成难度:中等)
根据这篇博客,我们就可以搭建一个linux虚拟机。其中的内存、磁盘、cpu数、核心数可根据宿主机配置与需求修改,下面会详细分析一下。
安装位置不建议放默认的C盘,可以在其他盘创建一个专门存放虚拟机的文件夹。关于虚拟机磁盘大小,即使给虚拟机分配了100GB磁盘,只是创建、启动并不会占用多少宿主机磁盘(启动会占用内存),但是再后续使用的过程中虚拟机下载安装软件、存放数据,会增大宿主机磁盘占用。
a. 虚拟机磁盘占用与宿主机占用

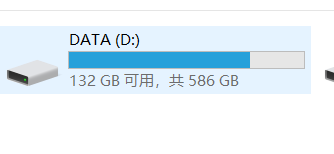
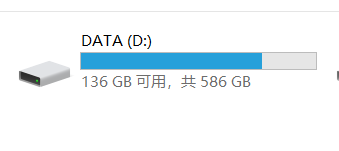
b. 虚拟机设定值过大会怎么样
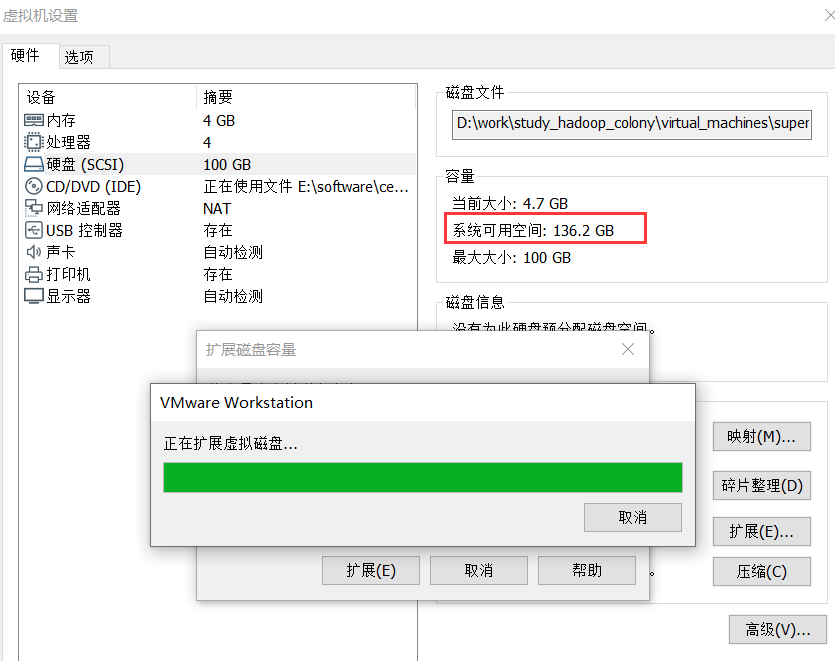
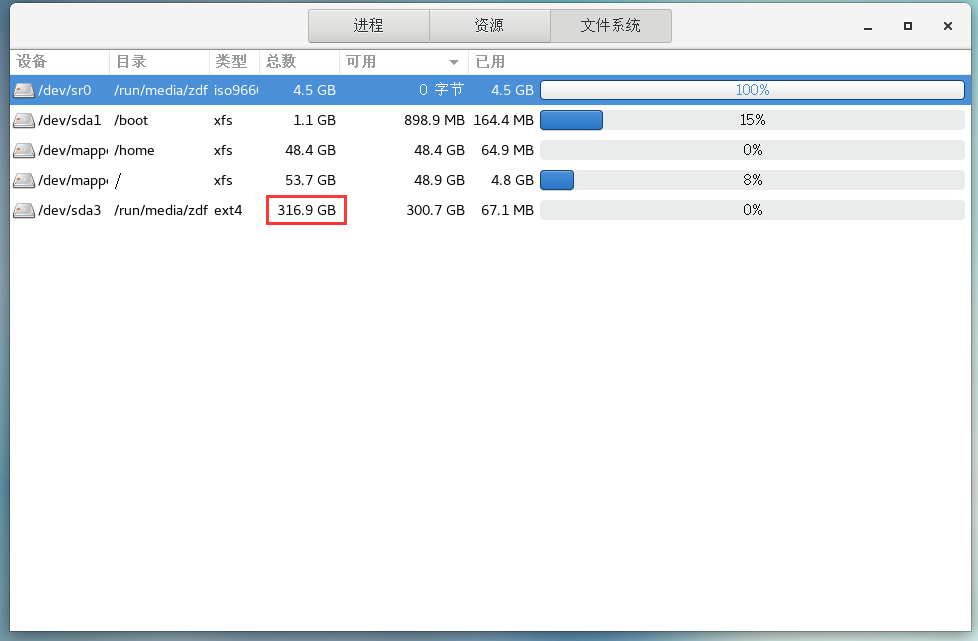
c. 小结
虚拟机磁盘大小只是设置一个可用磁盘上限,并不是实际占用,也不是实际可用(所以可以随便点,不要太小就可以)。这里根据我们的需求,需创建3个虚拟机,每个100GB就可以了。
cpu虚拟化
不考虑计算机虚拟化技术的话,虚拟机台数 * 虚拟机cpu个数 * cpu核心数 <= 宿主机cpu个数 * cpu核心数。我的电脑只有8核,要创建3个虚拟机,2 2 4是比较合理的分配。
但是既然cpu有虚拟化技术,我们试下多配置几个核心。
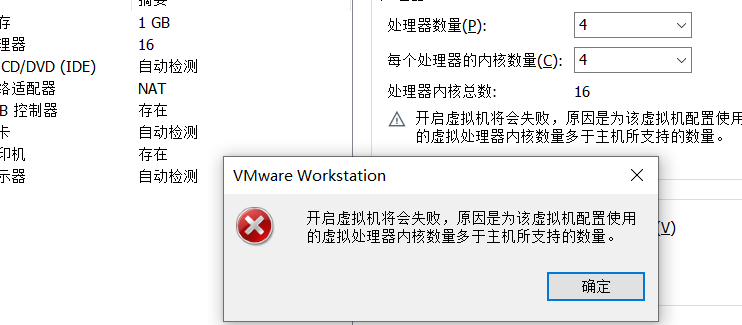
不让配!多次测试后发现最多只能配置8个。那我们多开个虚拟机试试。
创建、启动虚拟机后,查看虚拟机的基本信息(这次是最小安装,用命令行看一下)。
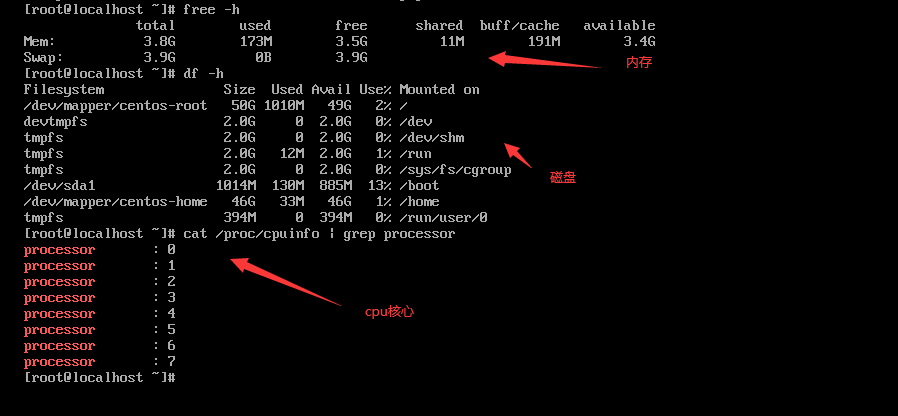
这里测试了2个4核虚拟机,1个8核虚拟机可以同时正常运行。
小结
单个虚拟机配置有要求,多个虚拟机cpu内核总数可超过宿主机cpu核心数。根据我们需求,三各虚拟机,4 4 4分配,或者2 2 4都是可以的。
这里有两个需要注意的地方:1.能连网 2.配置静态ip(linux默认ip自动分配,被坑过,关、开机一次ip变了)
安装时点了一下以太网模块的开启按钮,启动虚拟机直接就连上了。但这是我之前配置好了VMware的结果。
总体来讲需要配置3个地方:宿主机,VMware,虚拟机。
设置->查找设置->网络连接->启用VMnet8->鼠标右键点击VMnet8->属性->ipv4设置
IP地址:使用下面的IP地址
| 设置 | value |
|---|---|
| IP地址 | 192.168.10.15 |
| 子网掩码 | 255.255.255.0 |
| 默认网关 | 192.168.10.2 |
dns设置:使用下面的DNS地址
| 设置 | value |
|---|---|
| 首选DNS | 192.168.10.2 |
| 备用DNS | 8.8.8.8 |
编辑->虚拟网络编辑器->右下的'更改设置'
VMnet信息
编辑->虚拟网络编辑器->右下的'更改设置'->NAT设置
vi /etc/sysconfig/network-scripts/ifcfg-ens33
#替换为以下内容
#注意这里第四行配置了静态ip
DEVICE=ens33
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="ens33"
IPADDR=192.168.10.102
PREFIX=24
GATEWAY=192.168.10.2
DNS1=192.168.10.2
#重启网卡
/etc/init.d/network restart
GOME图形化安装:
最小化安装:
小结:这里取舍有点难,内存紧张,用最小化吧。
内存4GB 4核心(2 * 2)磁盘100GB 最小化安装 名称:superPC01 ip:192.168.10.135
内存3GB 2核心(1 * 2)磁盘100GB 最小化安装 名称:superPC02 ip:192.168.10.136
内存3GB 2核心(1 * 2)磁盘100GB 最小化安装 名称:superPC03 ip:192.168.10.137
弄好一个,克隆,修改。
安装个 network-tools.x86_64,可以使用ifconfig命令看ip地址。
配一下静态ip,并确认网络畅通。
#使用命令行测试网络
ping www.baidu.com
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我有两个Rails模型,即Invoice和Invoice_details。一个Invoice_details属于Invoice,一个Invoice有多个Invoice_details。我无法使用accepts_nested_attributes_forinInvoice通过Invoice模型保存Invoice_details。我收到以下错误:(0.2ms)BEGIN(0.2ms)ROLLBACKCompleted422UnprocessableEntityin25ms(ActiveRecord:4.0ms)ActiveRecord::RecordInvalid(Validationfa
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我正在尝试将以下SQL查询转换为ActiveRecord,它正在融化我的大脑。deletefromtablewhereid有什么想法吗?我想做的是限制表中的行数。所以,我想删除少于最近10个条目的所有内容。编辑:通过结合以下几个答案找到了解决方案。Temperature.where('id这给我留下了最新的10个条目。 最佳答案 从您的SQL来看,您似乎想要从表中删除前10条记录。我相信到目前为止的大多数答案都会如此。这里有两个额外的选择:基于MurifoX的版本:Table.where(:id=>Table.order(:id).
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
我有一个应用需要发送用户事件邀请。当用户邀请friend(用户)参加事件时,如果尚不存在将用户连接到该事件的新记录,则会创建该记录。我的模型由用户、事件和events_user组成。classEventdefinvite(user_id,*args)user_id.eachdo|u|e=EventsUser.find_or_create_by_event_id_and_user_id(self.id,u)e.save!endendend用法Event.first.invite([1,2,3])我不认为以上是完成我的任务的最有效方法。我设想了一种方法,例如Model.find_or_cr
在许多ruby类之间共享记录器实例的最佳(正确)方法是什么?现在我只是将记录器创建为全局$logger=Logger.new变量,但我觉得有更好的方法可以在不使用全局变量的情况下执行此操作。如果我有以下内容:moduleFooclassAclassBclassC...classZend在所有类之间共享记录器实例的最佳方式是什么?我是以某种方式在Foo模块中声明/创建记录器还是只是使用全局$logger没问题? 最佳答案 在模块中添加常量:moduleFooLogger=Logger.newclassAclassBclassC..