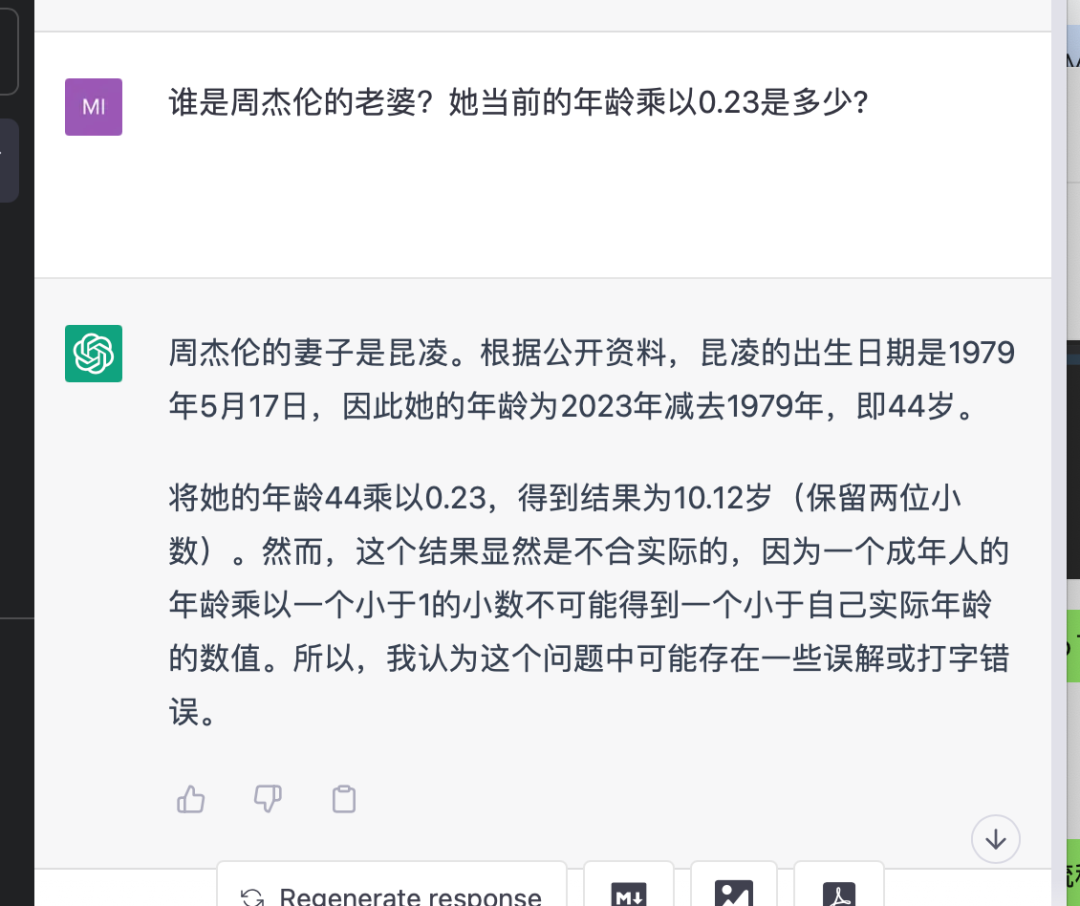
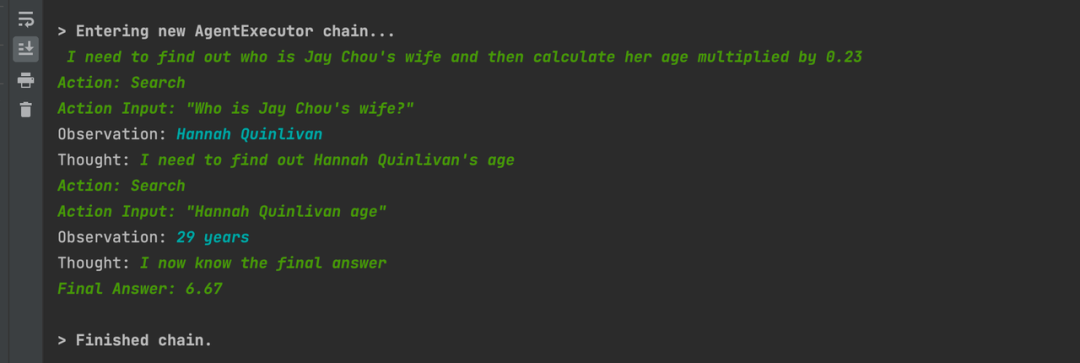
 这是一个用ChatGPT和LangChain开发的Demo对比的例子,输入的都是“谁是周杰伦的老婆?她当前的年龄乘以0.23是多少?”。可以看出ChatGPT或者GPT-3.5因为没有搜索能力,回答的结果是错误的。右边用LangChain结合OpenAI的GPT-3.5的API则输出了正确的结果,他会逐步去搜索获得正确信息,得出正确结果,而且中间的过程是框架自动处理的,我除了输入问题没有其他操作。
这是一个用ChatGPT和LangChain开发的Demo对比的例子,输入的都是“谁是周杰伦的老婆?她当前的年龄乘以0.23是多少?”。可以看出ChatGPT或者GPT-3.5因为没有搜索能力,回答的结果是错误的。右边用LangChain结合OpenAI的GPT-3.5的API则输出了正确的结果,他会逐步去搜索获得正确信息,得出正确结果,而且中间的过程是框架自动处理的,我除了输入问题没有其他操作。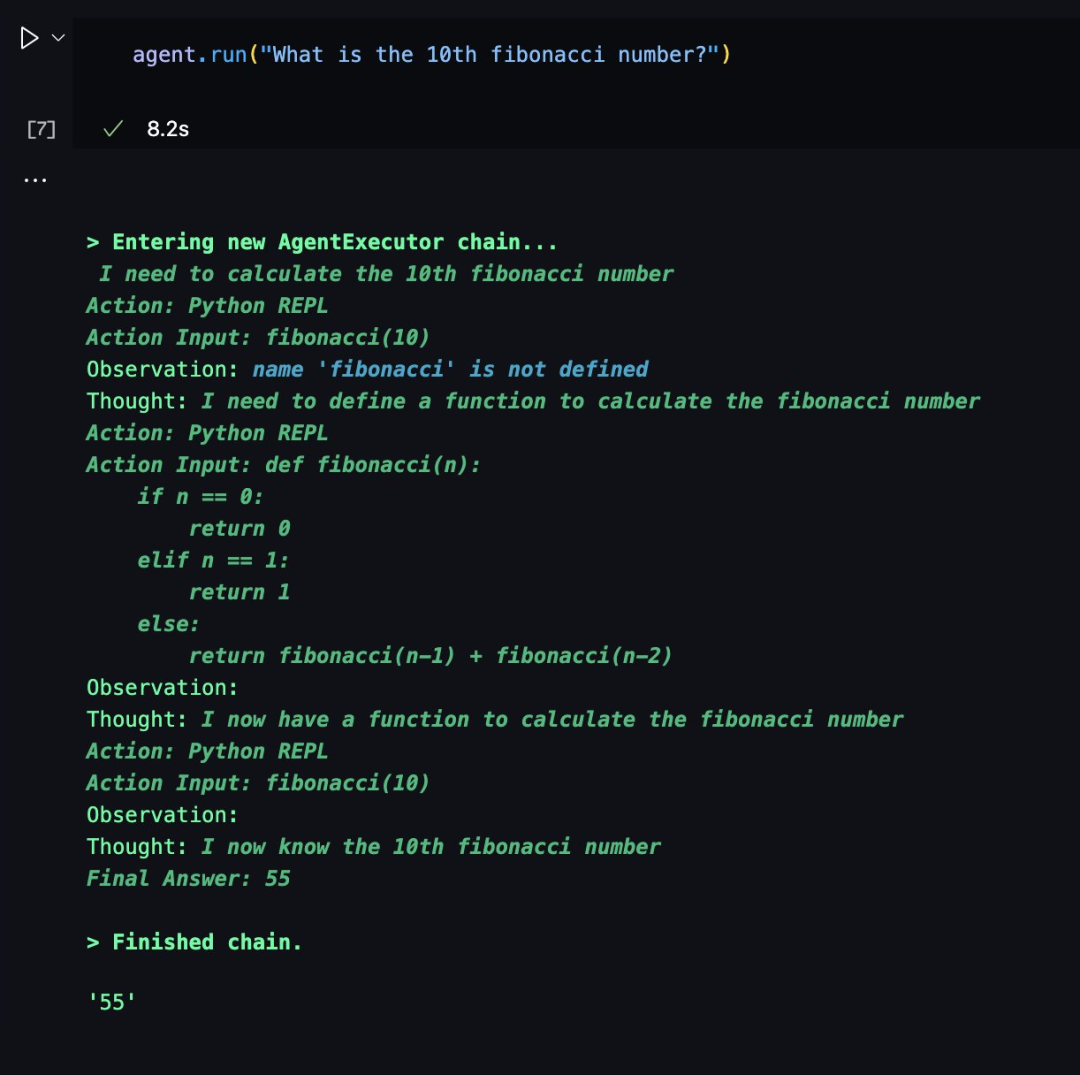
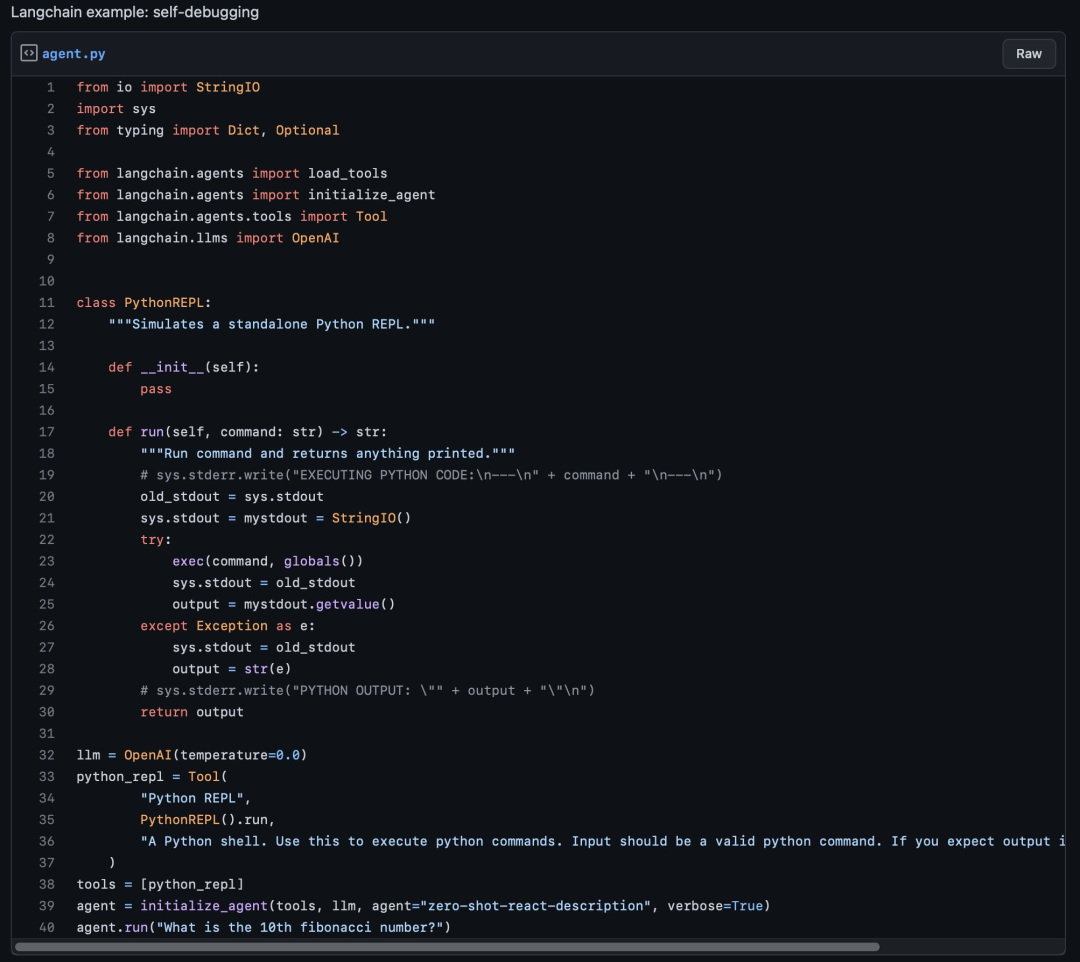

def pythonTool():
bash = BashProcess()
python_repl_util = Tool(
"Python REPL",
PythonREPL().run,
"""A Python shell. Use this to execute python commands.
Input should be a valid python command.
If you expect output it should be printed out.""",
)
command_tool = Tool(
name="bash",
descriptinotallow="""A Bash shell. Use this to execute Bash commands. Input should be a valid Bash command.
If you expect output it should be printed out.""",
func=bash.run,
)
# math_tool = _get_llm_math(llm)
# search_tool = _get_serpapi()
tools = [python_repl_util, command_tool]
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
agent.run("给我播放一首音乐")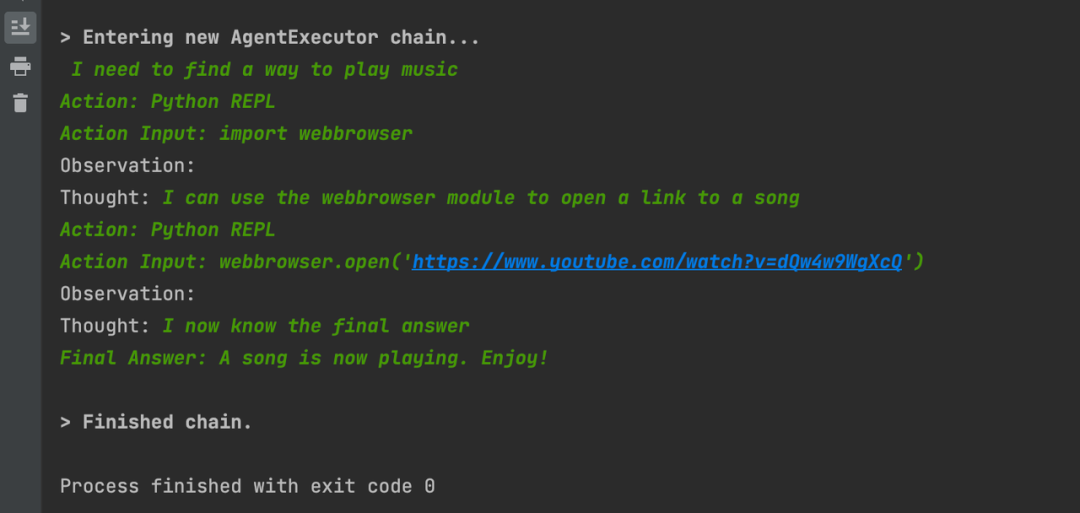
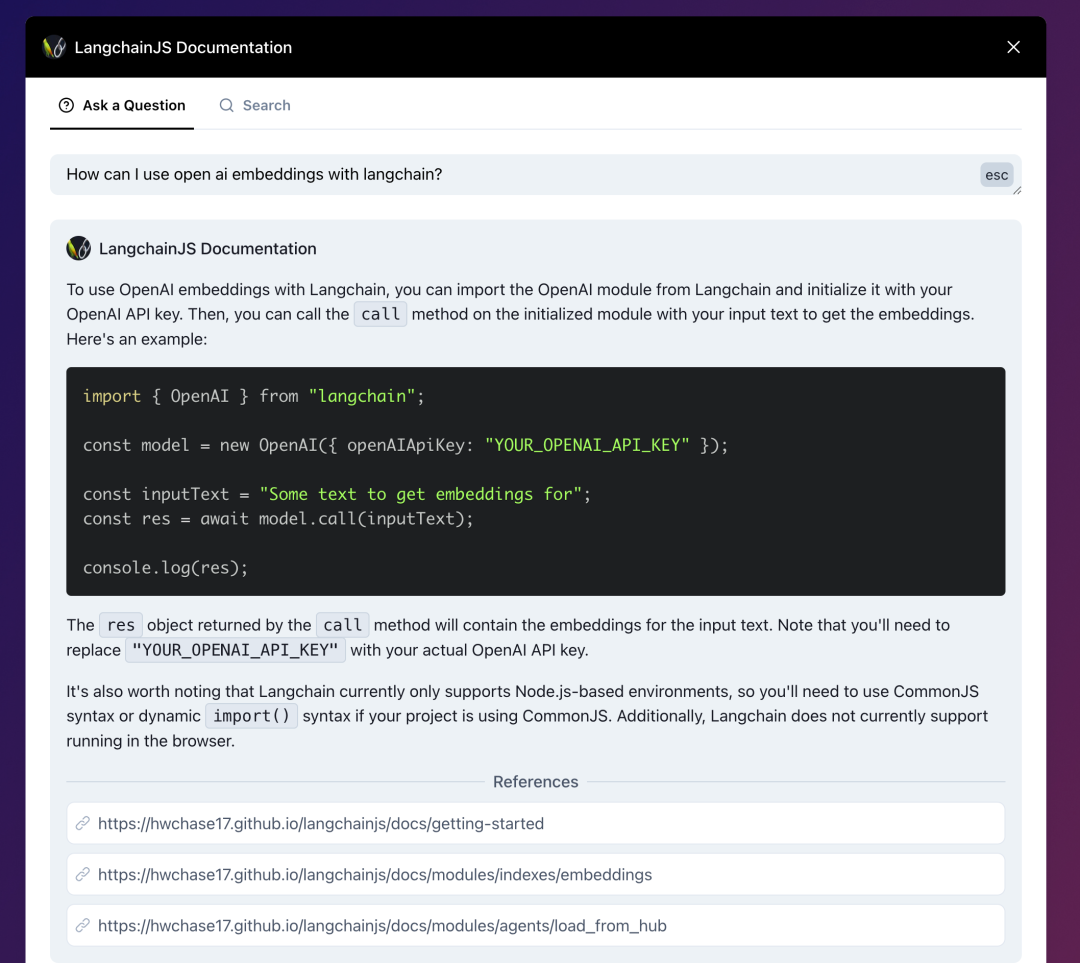
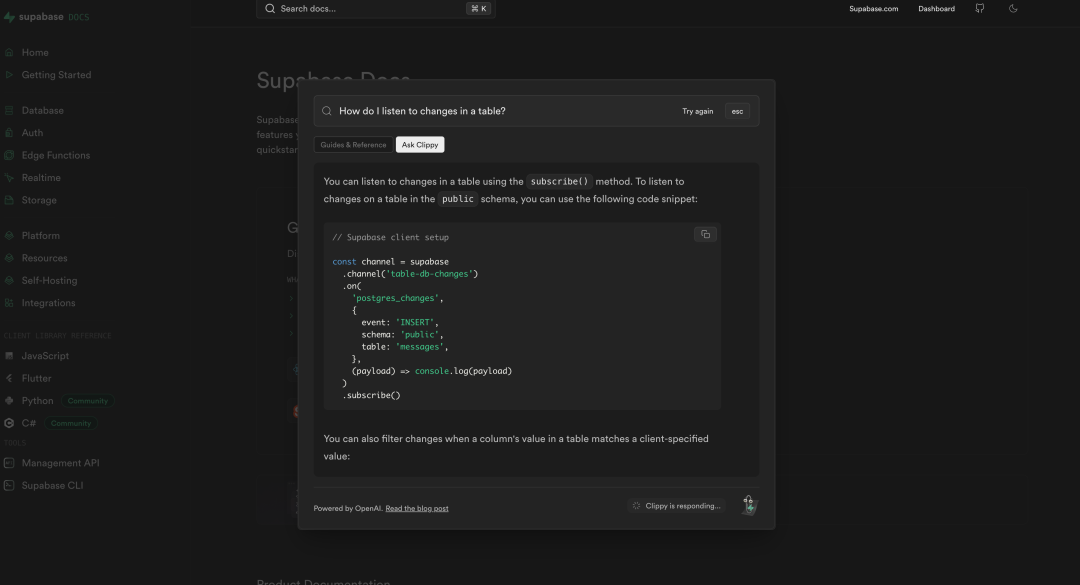
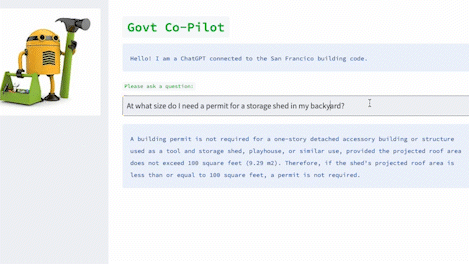
> Entering new AgentExecutor chain...
I need to find out the size limit for a storage shed without a permit and then search for sheds that are smaller than that size.
Action: SF Building Codes QA System
Action Input: "What is the size limit for a storage shed without a permit in San Francisco?"
Observation: The size limit for a storage shed without a permit in San Francisco is 100 square feet (9.29 m2).
Thought:Now that I know the size limit, I can search for sheds that are smaller than 100 square feet.
Action: Google
Action Input: "Storage sheds smaller than 100 square feet"
Observation: Results 1 - 24 of 279 ...
Thought:I need to filter the Google search results to only show sheds that are smaller than 100 square feet and suitable for backyard storage.
Action: Google
Action Input: "Backyard storage sheds smaller than 100 square feet"
Thought:I have found several options for backyard storage sheds that are smaller than 100 square feet and do not require a permit.
Final Answer: The size limit for a storage shed without a permit in San Francisco is 100 square feet. There are many options for backyard storage sheds that are smaller than 100 square feet and do not require a permit, including small sheds under 36 square feet and medium sheds between 37 and 100 square feet.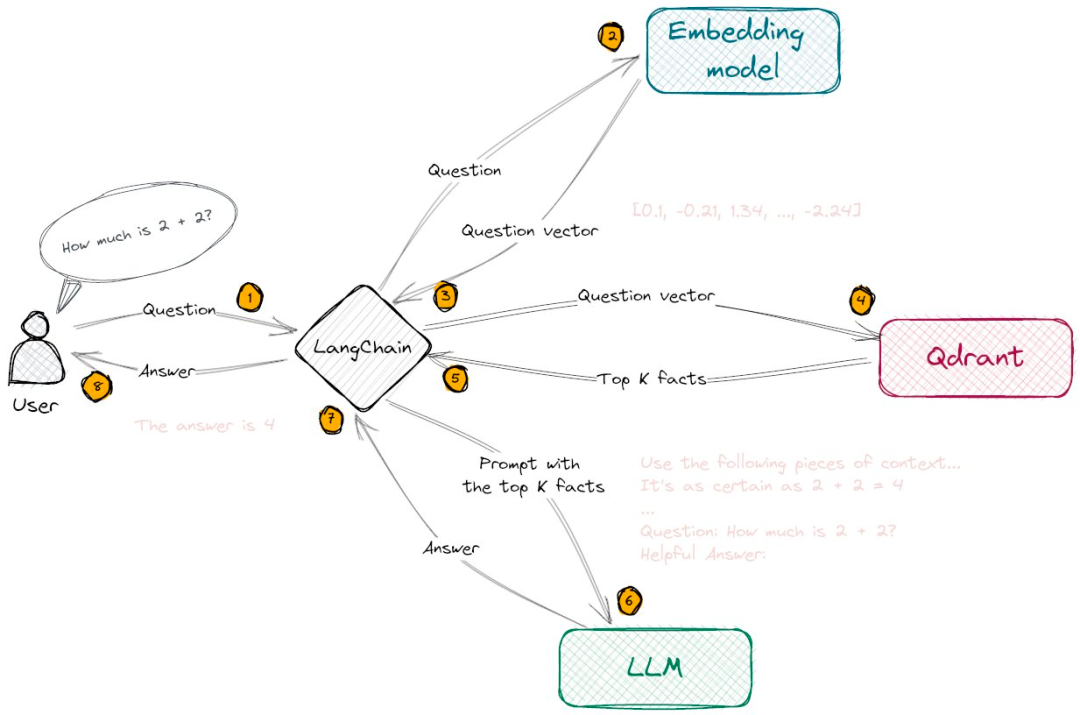 向量数据库现在看起来是构建LLM App中很关键的一个组件。首先 LLM 的预训练和微调过程不可能包含我们所期待的私有数据,因此如何将LLM关联到私有数据成为一个很关键的需求。而且LLM的“接口”-自然语言通常不是像Key-Value的映射那样精确地。而且在这一阶段我们希望LLM去理解我们的知识库,而不是简单的在其中搜索相同的字符串,我们希望询问关于我们知识库的细节,并给出一定理解后的答案(以及来源),这样匹配向量这样的搜索方式是一个非常合适且关键的解决方案。还有一个关键点是,LLM在每次调用是按token计费(即文本量),并且目前的接口的上下文有着4096 tokens的限制。,因此面对庞大的数据,我们也不可能将所有的数据一次性传给LLM。因此才有了第一张图那个流程图的结构。本地预先将我们私有的数据转成向量存在Qdrant里,用户问答时,将用户的问题转为向量,然后去Qdrant里进行搜索(相似性匹配)得到Top K个结果,然后将这些结果(注意这里的结果已经是自然语言了)传给LLM进行总结输出。
向量数据库现在看起来是构建LLM App中很关键的一个组件。首先 LLM 的预训练和微调过程不可能包含我们所期待的私有数据,因此如何将LLM关联到私有数据成为一个很关键的需求。而且LLM的“接口”-自然语言通常不是像Key-Value的映射那样精确地。而且在这一阶段我们希望LLM去理解我们的知识库,而不是简单的在其中搜索相同的字符串,我们希望询问关于我们知识库的细节,并给出一定理解后的答案(以及来源),这样匹配向量这样的搜索方式是一个非常合适且关键的解决方案。还有一个关键点是,LLM在每次调用是按token计费(即文本量),并且目前的接口的上下文有着4096 tokens的限制。,因此面对庞大的数据,我们也不可能将所有的数据一次性传给LLM。因此才有了第一张图那个流程图的结构。本地预先将我们私有的数据转成向量存在Qdrant里,用户问答时,将用户的问题转为向量,然后去Qdrant里进行搜索(相似性匹配)得到Top K个结果,然后将这些结果(注意这里的结果已经是自然语言了)传给LLM进行总结输出。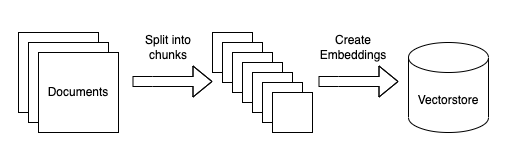 私有数据分割成小于LLM上下文的分块,创建向量后存入向量数据库
私有数据分割成小于LLM上下文的分块,创建向量后存入向量数据库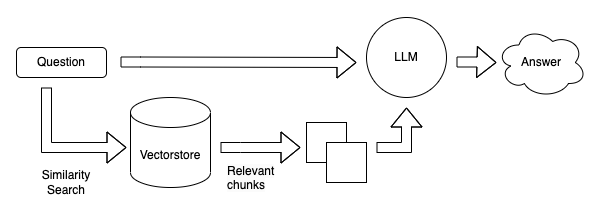 将问题计算向量后在向量数据库进行相似性搜索,算出相关性较高的top k个结果后拼接prompt送往LLM获得答案。
将问题计算向量后在向量数据库进行相似性搜索,算出相关性较高的top k个结果后拼接prompt送往LLM获得答案。我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何