在大数据的学习过程中,我们经常会听到“分布式”这三个字,那个所谓的“分布式”到底是什么意思?我们看到一些古装电视剧电影,在古代,生产力比较低下,没有现在的各种便捷的交通工具。人们需要运输一些货物的时候,最常见的方式就是套马车,用马来拉动车。如果需要拉的货物比较多,一匹马拉不动呢?人们的做法并不是训练一匹更加强壮的马,而是会使用多匹马同时来拉动这辆马车。这就是分布式的思想!
那么在程序世界中,单台服务器的能力是有限的,虽然我们可以堆配置来构建一台性能非常强悍的服务器,但是上限还是容易达到的,且成本会非常的高。为了解决这样的问题,我们就可以使用多台服务器协同工作,共同来完成指定的任务,组成一个服务器集群,而这样的集群我们通常也就称为--分布式集群。
分布式集群可以提供数据的存储、计算等操作。今天我们就来聊一聊分布式存储,也就是一个分布式文件系统。其实在HDFS之前,也有一些其他的分布式文件系统,笼统的来说,只要是实现了将数据分散的存储在多个节点上进行存储,并且可以实现数据的读取就可以称为是“分布式文件系统”。
现在想象一下这种情况:有四个文件 0.5TB的file1,1.2TB的file2,50GB的file3,100GB的file4;有7个服务器,每个服务器上有10个1TB的硬盘。
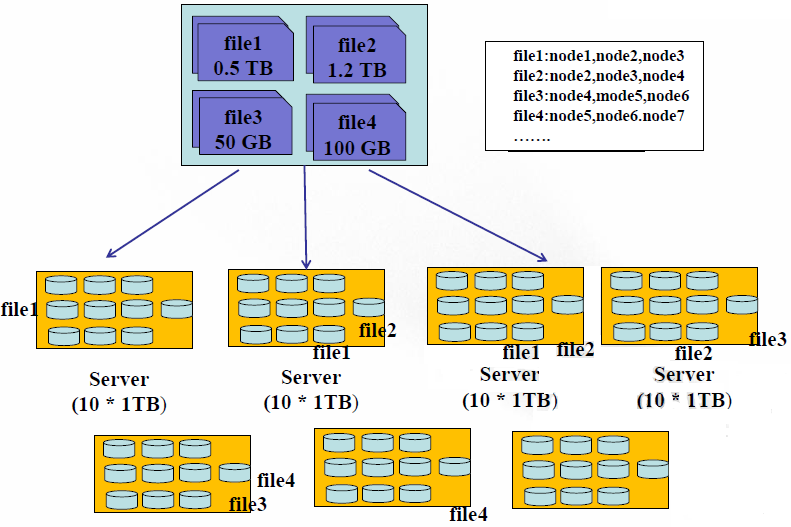
在存储方式上,我们可以将这四个文件存储在同一个服务器上(当然大于1TB的文件需要切分),我们需要使用一个文件来记录这种存储的映射关系吧。用户是可以通过这种映射关系来找到节点硬盘相应的文件的。那么缺点也就暴露了出来:
第一、负载不均衡。
因为文件大小不一致,势必会导致有的节点磁盘的利用率高,有的节点磁盘利用率低。
第二、网络瓶颈问题。
一个过大的文件存储在一个节点磁盘上,当有并行处理时,每个线程都需要从这个节点磁盘上读取这个文件的内容,那么就会出现网络瓶颈,不利于分布式的数据处理。
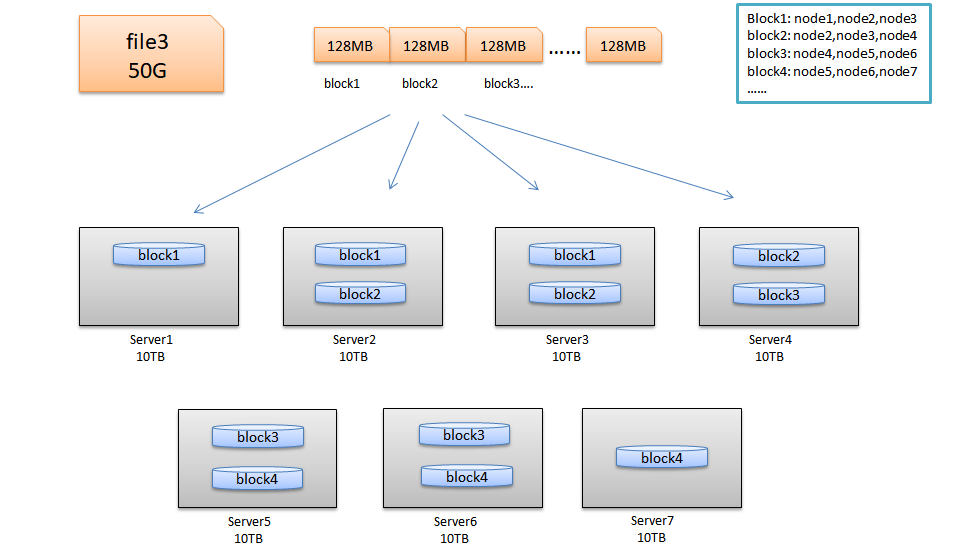
HDFS与其他普通文件系统一样,同样引入了块(Block)的概念,并且块的大小是固定的。但是不像普通文件系统那样小,而是根据实际需求可以自定义的。块是HDFS系统当中的最小存储单位,在hadoop2.0中默认大小为128MB(hadoop1.x中的块大小为64M)。在HDFS上的文件会被拆分成多个块,每个块作为独立的单元进行存储。多个块存放在不同的DataNode上,整个过程中 HDFS系统会保证一个块存储在一个数据节点上 。但值得注意的是,如果某文件大小或者文件的最后一个块没有到达128M,则不会占据整个块空间 。
在hdfs-site.xml中我们配置过下面这个属性,这个属性的值就是块在linux系统上的存储位置
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>

1. 高容错性(硬件故障是常态):数据自动保存多个副本,副本丢失后,会自动恢复
2. 适合大数据集:GB、TB、甚至PB级数据、千万规模以上的文件数量,1000以上节点规模。
3. 数据访问: 一次性写入,多次读取;保证数据一致性,安全性
4. 构建成本低:可以构建在廉价机器上。
5. 多种软硬件平台中的可移植性
6. 高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
7. 高可靠性:Hadoop的存储和处理数据的能力值得人们信赖.
1. 不适合做低延迟数据访问:
HDFS的设计目标有一点是:处理大型数据集,高吞吐率。这一点势必要以高延迟为代价的。因此HDFS不适合处理用户要求的毫秒级的低延迟应用请求
2. 不适合小文件存取:
1. 从存储能力出发(固定内存)
因为HDFS的文件是以块为单位存储的,且如果文件大小不到128M的时候,是不会占用整个块的空间的。但是,这个块依然会在内存中占用150个字节的元数据。因此,同样的内存占用的情况下,大量的小文件会导致集群的存储能力不足。
例如: 同样是128G的内存,最多可存储9.2亿个块。如果都是小文件,例如1M,则集群存储的数据大小为9.2亿*1M = 877TB的数据。但是如果存储的都是128M的文件,则集群存储的数据大小为109.6PB的数据。存储能力大不相同。
2. 从内存占用出发(固定存储能力)
同样假设存储1M和128M的文件对比,同样存储1PB的数据,如果是1M的小文件存储,占用的内存空间为1PB/1Mb*150Byte = 150G的内存。如果存储的是128M的文件存储,占用的内存空间为1PB/128M*150Byte = 1.17G的内存占用。可以看到,同样存储1PB的数据,小文件的存储比起大文件占用更多的内存。
3. 不适合并发写入,文件随机修改:
HDFS上的文件只能拥有一个写者,仅仅支持append操作。不支持多用户对同一个文件的写操作,以及在文件任意位置进行修改。
帮助到你的话就点个关注吧~
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我正在编写一个简单的静态Rack应用程序。查看下面的config.ru代码:useRack::Static,:urls=>["/elements","/img","/pages","/users","/css","/js"],:root=>"archive"map'/'dorunProc.new{|env|[200,{'Content-Type'=>'text/html','Cache-Control'=>'public,max-age=6400'},File.open('archive/splash.html',File::RDONLY)]}endmap'/pages/search.
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我去了这个website查看Rails5.0.0和Rails5.1.1之间的区别为什么5.1.1不再包含:config/initializers/session_store.rb?谢谢 最佳答案 这是删除它的提交:Setupdefaultsessionstoreinternally,nolongerthroughanapplicationinitializer总而言之,新应用没有该初始化器,session存储默认设置为cookie存储。即与在该初始值设定项的生成版本中指定的值相同。 关于
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315