好家伙,继续优化,
好家伙,我把我的飞机大战发给我的小伙伴们玩
期待着略微的赞赏之词,然后他们用手机打开我的给他们的网址
然后点一下飞机就炸了。
游戏体验零分
(鼠标点击在移动端依旧可以生效)
好了所以我们来优化一下这个触屏移动事件
由于没有参考,就去翻文档了
触摸事件分三个:touchstart、touchmove和touchend
看名字大概是触摸点开始,触摸点移动,触摸点离开。
于是开始试探性的增加一个屏幕触碰事件
//为canvas绑定一个屏幕触碰事件 触碰点正好在飞机图片的正中心
canvas.addEventListener("touchstart",(e)=>{
let x = e.offsetX;
let y = e.offsetY;
hero.x = x - hero.width / 2;
hero.y = y - hero.height / 2;
})然后就寄了,参数有问题。
移动触点事件touchstart事件是不能直接拿到鼠标在canvas画布中的坐标。
参数e.offsetX直接就报undefind
去查百度了:
javaScript — touch事件详解(touchstart、touchmove和touchend) - 腾讯云开发者社区-腾讯云 (tencent.com)
(挺详细的)
每个Touch对象包含的属性如下。
clientX:触摸目标在视口中的x坐标。
clientY:触摸目标在视口中的y坐标。
identifier:标识触摸的唯一ID。
pageX:触摸目标在页面中的x坐标。
pageY:触摸目标在页面中的y坐标。
screenX:触摸目标在屏幕中的x坐标。
screenY:触摸目标在屏幕中的y坐标。
target:触目的DOM节点目标。
还是拿不到鼠标在canvas的坐标
那我们试着拿到页面中的坐标然后再去进行加减操作,然后还是不行
好家伙,拿不到鼠标移动时鼠标在canvas画布中的坐标,
所以,我们动点歪脑经
我们拿到屏幕坐标来计算就好了
canvas.addEventListener("touchmove", (e) => {
// let x = e.pageX;
// let y = e.pageY;
console.log(e);
// let x = e.touches[0].clientX;
// let y = e.touches[0].clinetY;
let x = e.touches[0].pageX;
let y = e.touches[0].pageY;
// let x = e.touches[0].screenX;
// let y = e.touches[0].screenY;
let write1 = (document.body.clientWidth - 480) / 2;
let write2 = (document.body.clientHeight - 650) / 2;
hero.x = x - write1 - hero.width / 2;
hero.y = y - write2 - hero.height / 2;
// hero.x = x - hero.width / 2;
// hero.y = y - hero.height / 2;
console.log(x, y);
console.log(document.body.clientWidth, document.body.clientHeight);
e.preventDefault(); // 阻止屏幕滚动的默认行为
})猜猜我干了什么

我们想办法用页面坐标减去空白部分长度就可以得到鼠标在canvas画布中的坐标了
纵坐标同理
(nice)
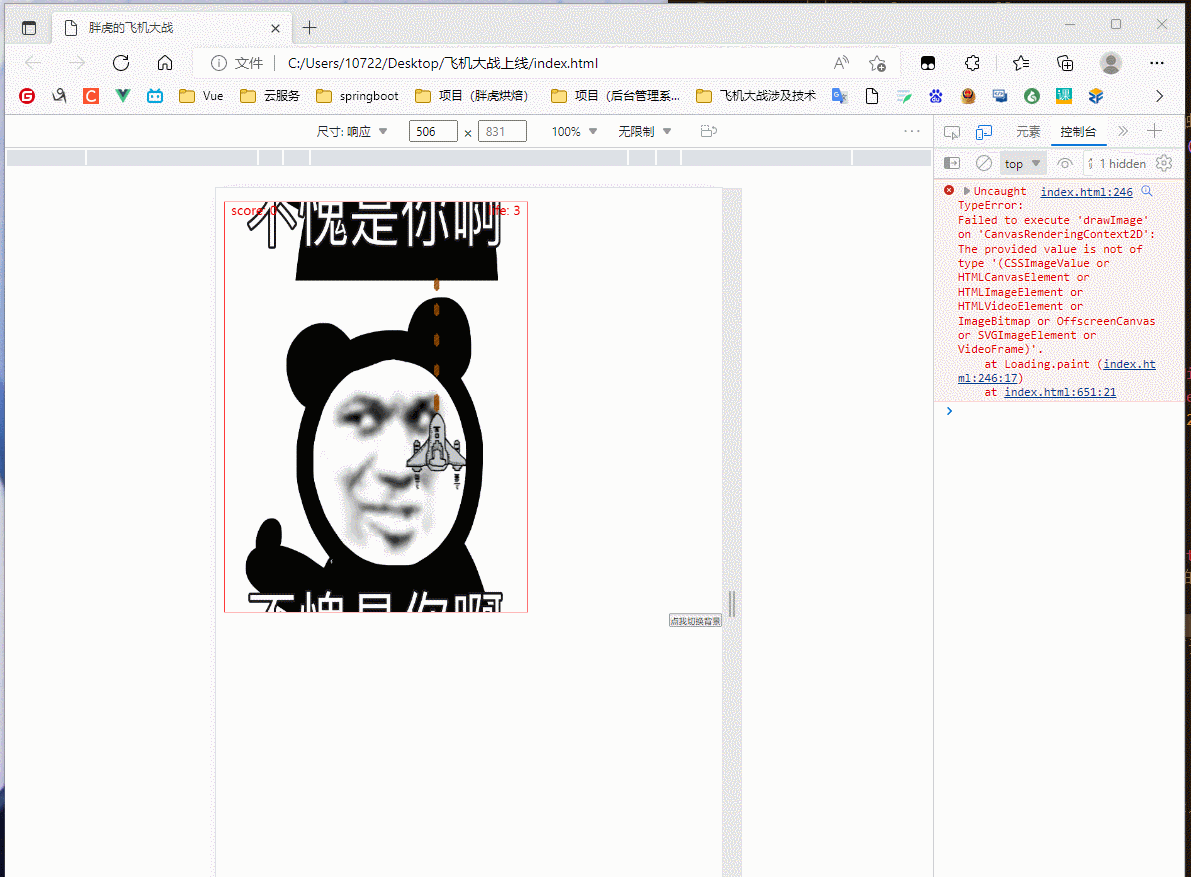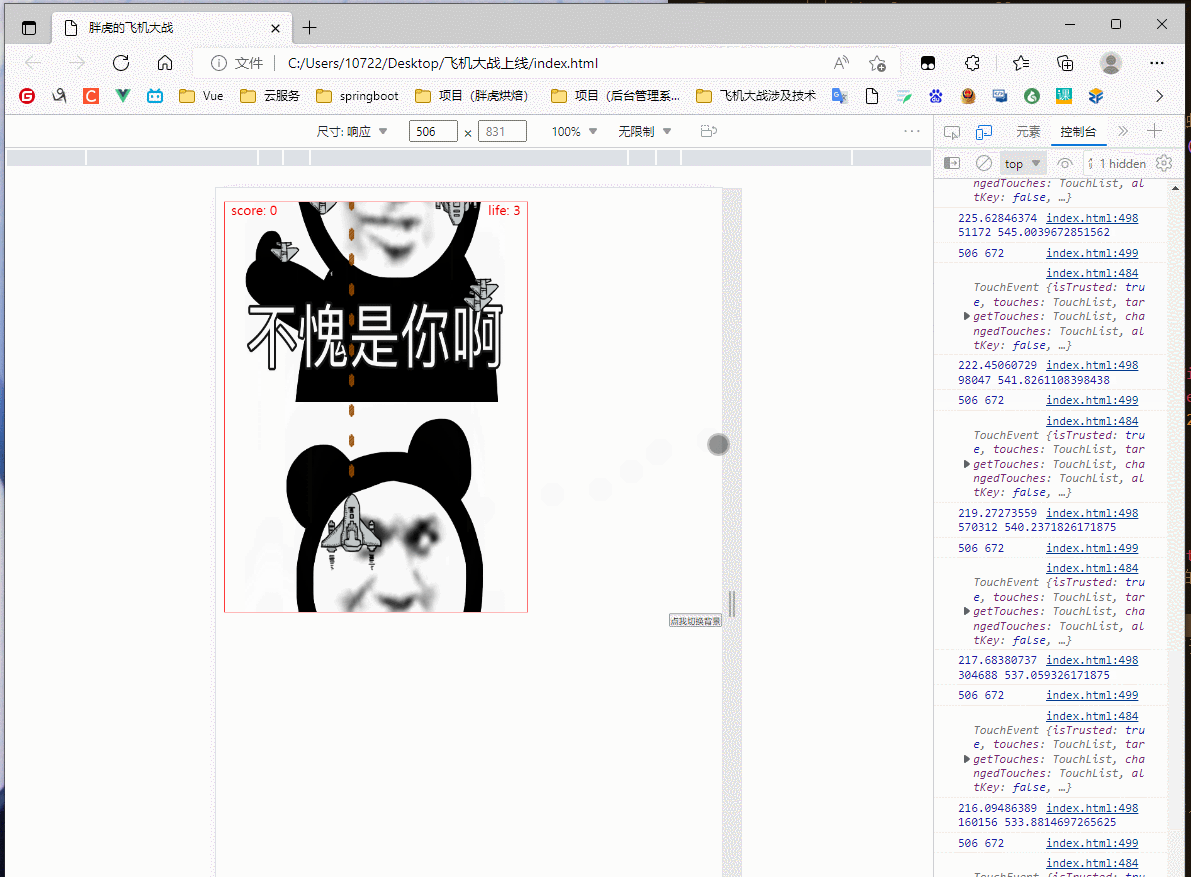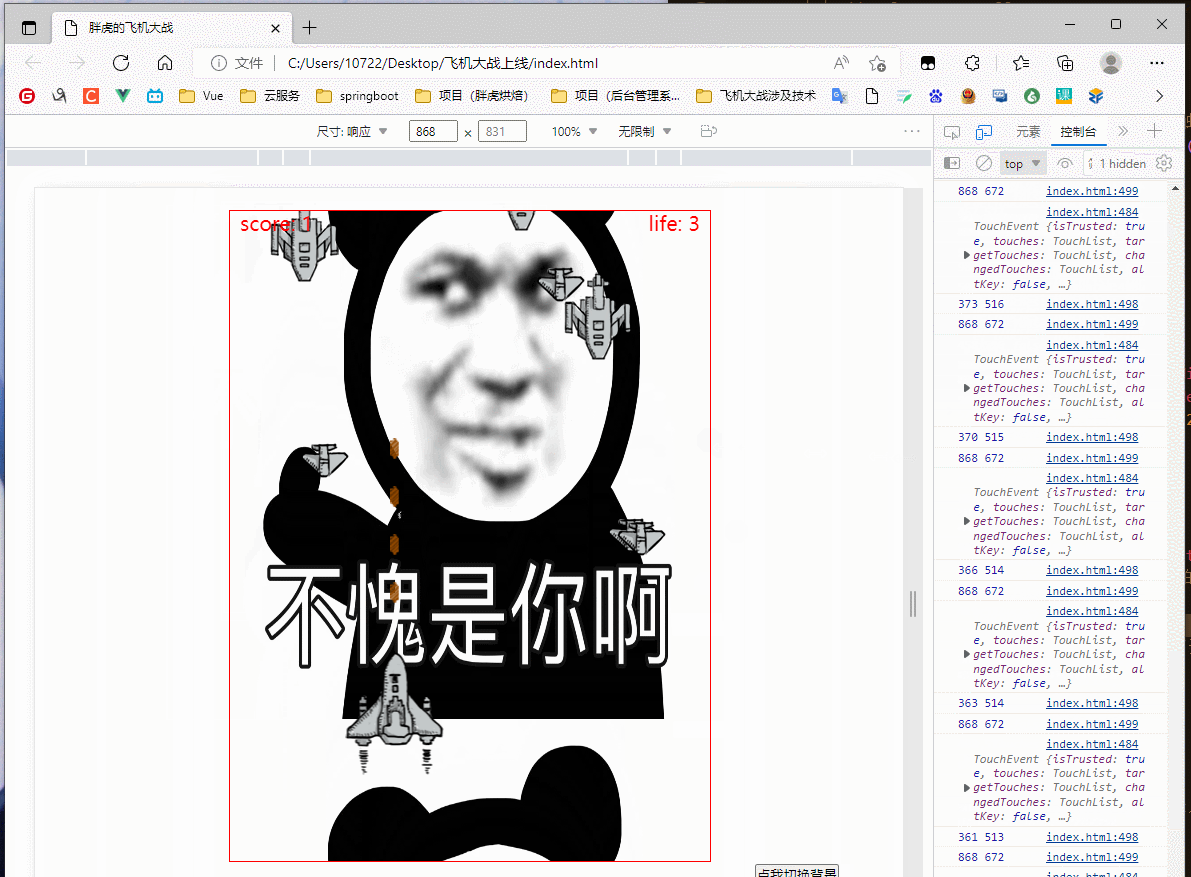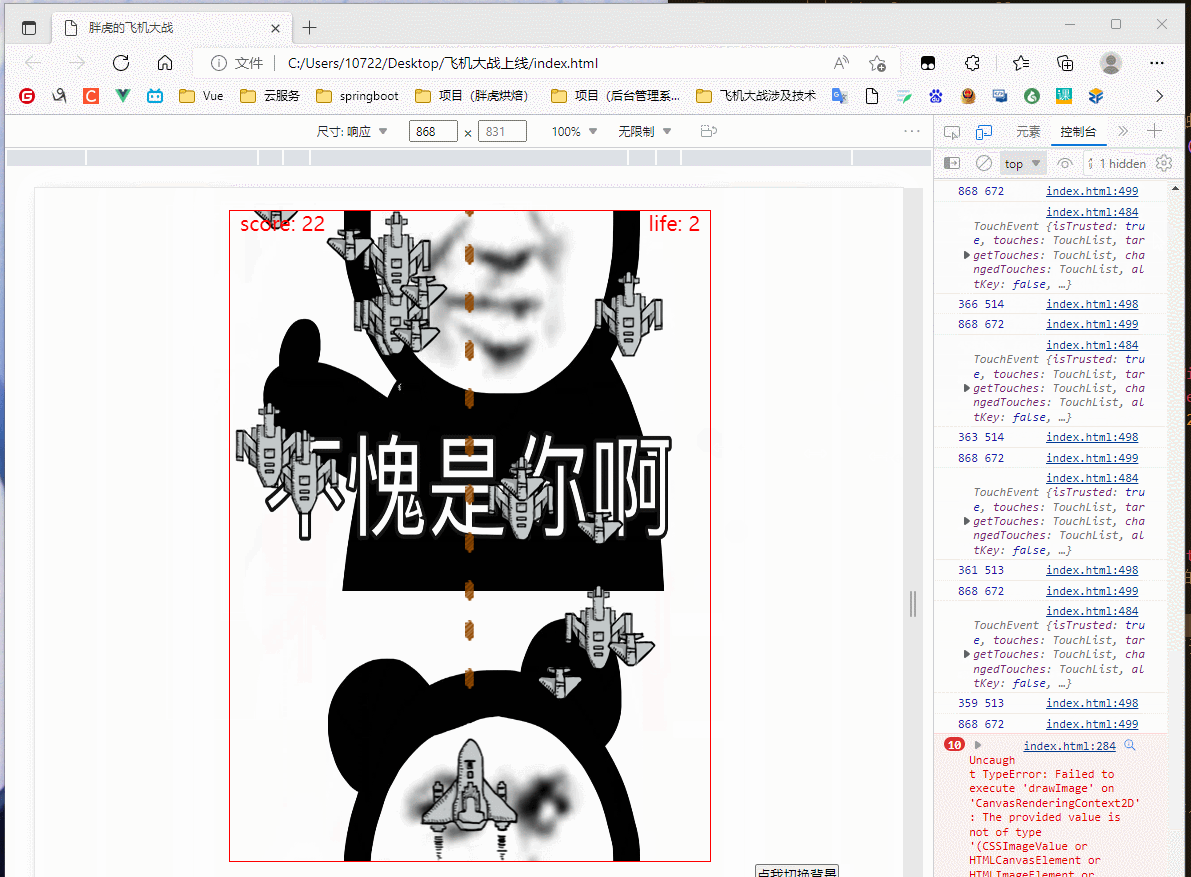
(此处为平板模式,完成了触屏连续移动)
效果还行
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我的代码目前看起来像这样numbers=[1,2,3,4,5]defpop_threepop=[]3.times{pop有没有办法在一行中完成pop_three方法中的内容?我基本上想做类似numbers.slice(0,3)的事情,但要删除切片中的数组项。嗯...嗯,我想我刚刚意识到我可以试试slice! 最佳答案 是numbers.pop(3)或者numbers.shift(3)如果你想要另一边。 关于ruby-多次弹出/移动ruby数组,我们在StackOverflow上找到一
在我的Controller中,我通过以下方式在我的index方法中支持HTML和JSON:respond_todo|format|format.htmlformat.json{renderjson:@user}end在浏览器中拉起它时,它会自然地以HTML呈现。但是,当我对/user资源进行内容类型为application/json的curl调用时(因为它是索引方法),我仍然将HTML作为响应。如何获取JSON作为响应?我还需要说明什么? 最佳答案 您应该将.json附加到请求的url,提供的格式在routes.rb的路径中定义。这
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
我正在使用Rails构建一个简单的聊天应用程序。当用户输入url时,我希望将其输出为html链接(即“url”)。我想知道在Ruby中是否有任何库或众所周知的方法可以做到这一点。如果没有,我有一些不错的正则表达式示例代码可以使用... 最佳答案 查看auto_linkRails提供的辅助方法。这会将所有URL和电子邮件地址变成可点击的链接(htmlanchor标记)。这是文档中的代码示例。auto_link("Gotohttp://www.rubyonrails.organdsayhellotodavid@loudthinking.
当我在我的Rails应用程序根目录中运行rakedoc:app时,API文档是使用/doc/README_FOR_APP作为主页生成的。我想向该文件添加.rdoc扩展名,以便它在GitHub上正确呈现。更好的是,我想将它移动到应用程序根目录(/README.rdoc)。有没有办法通过修改包含的rake/rdoctask任务在我的Rakefile中执行此操作?是否有某个地方可以查找可以修改的主页文件的名称?还是我必须编写一个新的Rake任务?额外的问题:Rails应用程序的两个单独文件/README和/doc/README_FOR_APP背后的逻辑是什么?为什么不只有一个?
我正在学习http://ruby.railstutorial.org/chapters/static-pages上的RubyonRails教程并遇到以下错误StaticPagesHomepageshouldhavethecontent'SampleApp'Failure/Error:page.shouldhave_content('SampleApp')Capybara::ElementNotFound:Unabletofindxpath"/html"#(eval):2:in`text'#./spec/requests/static_pages_spec.rb:7:in`(root)'
我从Ubuntu服务器上的RVM转移到rbenv。当我使用RVM时,使用bundle没有问题。转移到rbenv后,我在Jenkins的执行shell中收到“找不到命令”错误。我内爆并删除了RVM,并从~/.bashrc'中删除了所有与RVM相关的行。使用后我仍然收到此错误:rvmimploderm~/.rvm-rfrm~/.rvmrcgeminstallbundlerecho'exportPATH="$HOME/.rbenv/bin:$PATH"'>>~/.bashrcecho'eval"$(rbenvinit-)"'>>~/.bashrc.~/.bashrcrbenvversions
我正在尝试将一个简单的CSV文件读入HTML表格以在浏览器中显示,但我遇到了麻烦。这就是我正在尝试的:Controller:defshow@csv=CSV.open("file.csv",:headers=>true)end查看:输出:NameStartDateEndDateQuantityPostalCode基本上我只获取标题,而不会读取和呈现CSV正文。 最佳答案 这最终成为最终解决方案:Controller:defshow#OpenaCSVfile,andthenreaditintoaCSV::Tableobjectforda
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315