
文章目录

YOLO(You Only Look Once) 是由 Joseph Redmon 和 Ali Farhadi 在华盛顿大学开发的流行的目标检测和图像分割模型。第一个版本的 YOLO 于 2015 年发布,并因其高速度和准确性而迅速赢得了广泛的关注。
YOLOv2 于 2016 年发布,通过引入批归一化、锚框和尺寸聚类等方法改进了原始模型。
YOLOv3 于 2018 年发布,通过使用更高效的骨干网络、添加特征金字塔并利用焦点损失进一步提高了模型的性能。
2020 年,YOLOv4 发布,引入了许多创新,例如使用 Mosaic 数据增强、新的无锚检测头和新的损失函数。
2021年,Ultralytics 发布了 YOLOv5,进一步提高了模型的性能,并添加了新功能,例如支持全景分割和物体跟踪。
2022年,美团发布了 YOLOv6 ,这是一款面向工业部署的目标检测模型。
2022年,YOLOv7发布,这是 AlexeyAB(YOLOv4作者) 和 WongKinYiu(YOLOR作者) 发布的一款实时目标检测器。
2023年,Ultralytics 发布了 YOLOv8,进一步提高了模型的性能,可以同时实现分类、检测和分割等任务。
首先回顾一下 YOLOv5 的结构
New CSP-Darknet53,网络第一层 v5.0 版本前是 FOCUS 结构,v5.0 版本以后是 6×6 卷积。PAN 结构,v5.0 版本以前是SPP结构,v5.0版本以后是 SPPF 结构。YOLOv3一样。BCE loss;只计算正样本的分类损失。obj损失,采用的是BCE loss;这里的obj指的是网络预测的目标边界框与GT Box的CIoU,计算的是所有样本的obj损失。CIoU loss;只计算正样本的定位损失。

YOLOv8 项目地址:https://github.com/ultralytics/ultralytics
Ultralytics YOLOv8 是由 Ultralytics 开发的 YOLO 目标检测和图像分割模型的最新版本。YOLOv8 是一款先进的、最新的模型,基于之前 YOLO 版本的成功,并引入了新的特性和改进,进一步提高了性能和灵活性。
YOLOv8 的一个关键特性是其可扩展性。它被设计为一个框架,支持所有之前的 YOLO 版本,使得在不同版本之间切换并比较它们的性能变得非常容易。这使得 YOLOv8 成为那些想要利用最新的 YOLO 技术同时仍能够使用现有 YOLO 模型的用户的理想选择。
除了可扩展性之外,YOLOv8 还包括许多其他创新,使其成为一种适用于广泛目标检测和图像分割任务的吸引人选择。这些包括一个新的骨干网络、一个新的无锚点检测头和一个新的损失函数。此外,YOLOv8 高效并且可以在多种硬件平台上运行,从 CPU 到 GPU。
总的来说,YOLOv8 是一款强大、灵活的目标检测和图像分割工具,它提供了最新的 SOTA 技术以及使用和比较所有之前 YOLO 版本的能力,是一个兼具优点的选择。

ultralytics 并没有直接将开源库命名为 YOLOv8,而是直接使用 ultralytics 这个词,原因是 ultralytics 将这个库定位为算法框架,而非某一个特定算法,一个主要特点是可扩展性。其希望这个库不仅仅能够用于 YOLO 系列模型,而是能够支持非 YOLO 模型以及分类分割姿态估计等各类任务。
YOLOv8主要有如下的优点:
APIAnchor free
| 模型 | YOLOv5 (300epoch) | Params(M) | FLOPs@640(B) | YOLOv8 (500epoch) | Params(M) | FLOPs@640(B) |
|---|---|---|---|---|---|---|
| n | 28.0 | 1.9 | 4.5 | 37.3 | 3.2 | 8.7 |
| s | 37.4 | 7.2 | 16.5 | 44.9 | 11.2 | 28.6 |
| m | 45.4 | 21.2 | 49 | 50.2 | 25.9 | 78.9 |
| l | 49.0 | 46.5 | 109.1 | 52.9 | 43.7 | 165.2 |
| x | 50.7 | 86.7 | 205.7 | 53.9 | 68.2 | 257.8 |
表格中的数据来源于COCO数据集,但是在其它数据集上并不一定是v8优于v5。
6×6 卷积改为 3×3 卷积;参考 YOLOv7 ELAN 设计思想将 C3 模块换成了 C2f 模块,并配合调整了模块的深度。1×1 卷积的降采样层;同时也将原本的 C3 模块换成了 C2f 模块。Anchor-Based 换成了 Anchor-Free 。BCE Loss 作为分类损失;使用 VFL Loss + CIOU Loss 作为回归损失。Task-Aligned Assigner 样本分配策略。10 轮关闭 Mosaic 数据增强操作,该操作可以有效的提升精度。

因为YOLOv8采用Anchor free的范式,所以在 yaml 文件中移除了 anchor 的参数部分,并且YOLOv8将多个不同版本的模型写到了一起,除此之外在深度因子和宽度因子后又新增了一个最大通道数的参数,我觉得这可能和YOLOv7的模型理念有些相似,单凭宽度因子调整的通道数应该不是最优的,所以s\m\l没有遵循同一套的缩放系数。

主干部分改进主要有以下三点:
6×6 卷积改为 3×3 卷积 。C3 模块改为 C2f 模块 。C3 模块 3、6、9、3 改为C2f 的 3、6、6、3 。

依然采用 PAN 结构,但是删除了降维用的 1×1 卷积。

头部的改动是最大的,直接将原本的耦合头改成了解耦头,值得注意力的是,这个解耦头不再有之前的 objectness 分支,而是直接解耦成了两路,并且其回归分支使用了 Distribution Focal Loss 中提出的积分形式表示法。
在目标检测中,正负样本分配策略通常用于在训练期间为每个样本分配一个权重,以便模型更加关注困难的样本和重要的样本。动态分配策略和静态分配策略是两种常见的正负样本分配策略。
静态分配策略通常是在训练开始之前确定的,固定为一组预先定义的权重,这些权重不会在训练过程中改变。这种分配策略通常基于经验得出,可以根据数据集的特点进行调整,但是不够灵活,可能无法充分利用样本的信息,导致训练效果不佳。
相比之下,动态分配策略可以根据训练的进展和样本的特点动态地调整权重。在训练初期,模型可能会很难区分正负样本,因此应该更加关注那些容易被错分的样本。随着训练的进行,模型逐渐变得更加强大,可以更好地区分样本,因此应该逐渐减小困难样本的权重,同时增加易分样本的权重。动态分配策略可以根据训练损失或者其他指标来进行调整,可以更好地适应不同的数据集和模型。
总的来说,动态分配策略通常比静态分配策略更加灵活和高效,可以帮助模型更好地利用样本信息,提高训练效果。虽然动态分配策略可以在训练过程中根据模型的学习情况来适当调整正负样本的比例,但也存在一些缺点。
simOTA是YOLOX目标检测算法中的一种正负样本分配策略,全称为Similarity Overlap Threshold Assigner。它的主要思想是通过计算anchor和ground truth之间的相似度,来动态地分配正负样本。
在传统的目标检测算法中,通常使用IoU来度量anchor和ground truth之间的重叠程度,然后根据设定的阈值来判断是否将anchor分配为正样本或负样本。但这种方法存在一个问题,就是对于一些尺寸较小的目标,由于它们的IoU值通常比较低,因此很容易被分配为负样本,从而影响了检测性能。
simOTA的核心思想是:根据目标的相似度来确定正负样本的阈值,进而实现样本的自适应分配。在训练时,首先将所有的目标两两配对,并计算它们的相似度得分。然后,通过对相似度分数进行统计,得到一个阈值范围,用于确定正负样本的分配阈值。具体而言,相似度得分越高,对应的IoU阈值就越高,样本就越容易被视为正样本;相反,相似度得分越低,对应的IoU阈值就越低,样本就更容易被视为负样本。
通过引入相似度信息,simOTA可以更加灵活地处理目标间的差异性,从而提高模型的泛化能力和检测性能。实验结果表明,simOTA可以显著提高YOLOX模型在各种基准数据集上的表现,同时具有更好的鲁棒性和泛化性能。
相比传统的IoU分配方法,simOTA能够更好地处理尺寸较小的目标,从而提高了目标检测的性能。
Task-Aligned Assigner是一种TOOD中正负样本分配策略的方法,其基本原理是在训练过程中动态地调整正负样本的分配比例,以更好地适应不同的任务和数据分布,YOLOv8就是采用了这种策略。
具体而言,Task-Aligned Assigner基于一个关键的假设,即在不同的任务和数据集中,正负样本的分布情况可能会有所不同,因此需要针对具体的任务和数据分布,调整正负样本的分配比例,从而达到更好的检测效果。
为了实现这一目的,Task-Aligned Assigner提出了一个基于“任务自适应”的正负样本分配方法。具体而言,它使用一个任务感知的分配模块来估计不同任务下正负样本的分布情况,并基于这个分布情况动态调整正负样本的分配比例。
分配模块首先计算每个Anchor和每个Ground Truth Box之间的相似度,然后通过一个多任务学习框架,将相似度与正负样本标签的分布情况进行建模。最终,通过这个分布情况来动态地调整正负样本的分配比例,以更好地适应不同的任务和数据分布。
在具体实现中,Task-Aligned Assigner采用了一种基于动态阈值的分配方法。具体而言,它在计算Anchor与Ground Truth Box之间的IoU时,采用了一个基于任务自适应的动态阈值来判断正负样本的分配。通过这种方式,Task-Aligned Assigner能够根据具体的任务和数据分布,自适应地调整正负样本的分配比例,从而获得更好的检测性能。
Task-Aligned Assigner的公式如下:
t
=
s
α
×
u
β
t=s^α\times u^β
t=sα×uβ
使用上面公式来对每个实例计算 Anchor-level 的对齐程度:s 和 u 分别为分类得分和 IoU 值,α 和 β 为权重超参。t 可以同时控制分类得分和 IoU 的优化来实现 Task-Alignment,可以引导网络动态的关注于高质量的Anchor。采用一种简单的分配规则选择训练样本:对每个实例,选择 m 个具有最大 t 值的 Anchor 作为正样本,选择其余的 Anchor 作为负样本。然后,通过损失函数(针对分类与定位的对齐而设计的损失函数)进行训练。
YOLOv8源码中各个参数取值如下:

Loss 计算包括 2个分支:分类和回归分支,没有了之前的 objectness 分支。
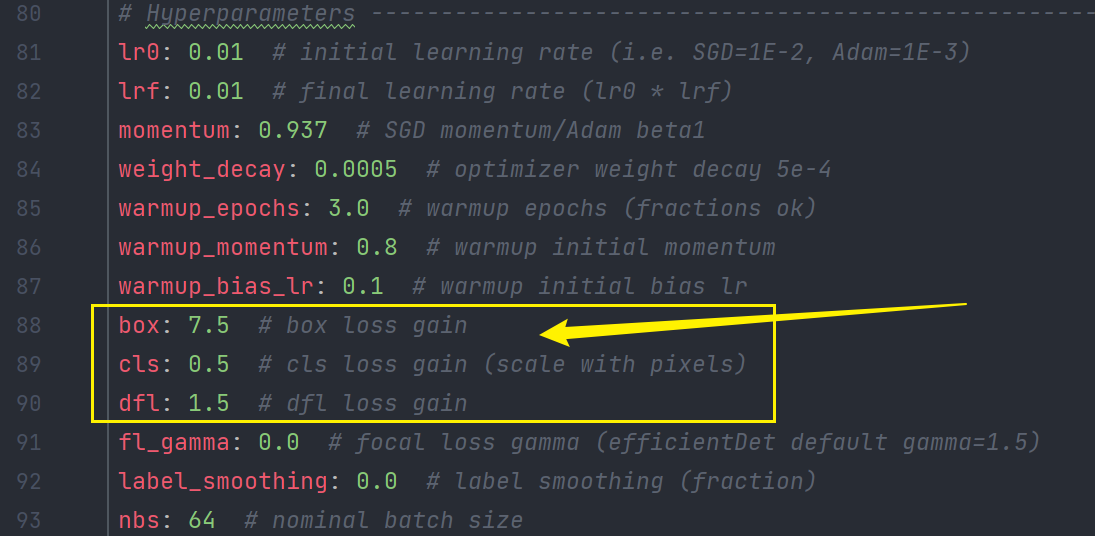
BCE Loss。Distribution Focal Loss 中提出的积分形式表示法绑定,因此使用了 Distribution Focal Loss, 同时还使用了 CIoU Loss。3 个 Loss 采用一定权重比例加权即可,默认的比例是7.5:0.5:1.5。
目标检测
| 模型 | 尺寸 (像素) | mAPval 50-95 | 推理速度 CPU ONNX (ms) | 推理速度 A100 TensorRT (ms) | 参数量 (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
分类
| 模型 | 尺寸 (像素) | acc top1 | acc top5 | 推理速度 CPU ONNX (ms) | 推理速度 A100 TensorRT (ms) | 参数量 (M) | FLOPs (B) at 640 |
|---|---|---|---|---|---|---|---|
| YOLOv8n-cls | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |
| YOLOv8s-cls | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |
| YOLOv8m-cls | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |
| YOLOv8l-cls | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |
| YOLOv8x-cls | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |
实例分割
| 模型 | 尺寸 (像素) | mAPbox 50-95 | mAPmask 50-95 | 推理速度 CPU ONNX (ms) | 推理速度 A100 TensorRT (ms) | 参数量 (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-seg | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
| YOLOv8s-seg | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
| YOLOv8m-seg | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
| YOLOv8l-seg | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
| YOLOv8x-seg | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
https://mp.weixin.qq.com/s/b8gpIb8UMivFm2iH7fRJ_A
目标检测算法——YOLOV8——算法详解
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我正在使用active_admin,我在Rails3应用程序的应用程序中有一个目录管理,其中包含模型和页面的声明。时不时地我也有一个类,当那个类有一个常量时,就像这样:classFooBAR="bar"end然后,我在每个必须在我的Rails应用程序中重新加载一些代码的请求中收到此警告:/Users/pupeno/helloworld/app/admin/billing.rb:12:warning:alreadyinitializedconstantBAR知道发生了什么以及如何避免这些警告吗? 最佳答案 在纯Ruby中:classA
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("