文章目录
项目根目录中经常会出现一个.vscode文件夹,它是干什么的?
众所周知,vscode 的配置分两类,一是全局的用户配置,二是当前工作区配置。vscode 打开的文件夹的根目录是一个工作区,.vscode目录就是存放当前工作区相关配置文件的目录。
这样分享项目时,也把该项目的 vscode 配置分享出去了,保证了协同工作开发环境的统一性。
.vscode目录下一般有 4 种配置文件和项目中的代码片段:
extensions.json:推荐当前项目使用的插件setting.json:vscode编辑器和插件的相关配置launch.json:调试配置文件task.json:任务配置xxxxxxx.code-snippets:项目中共享的代码片段将插件添加到该项目的推荐列表中:
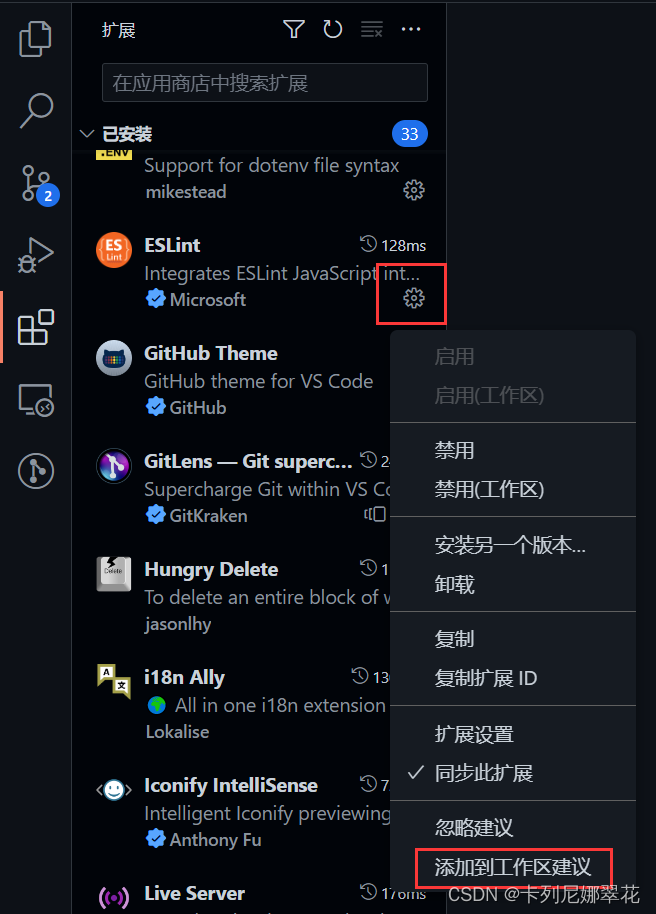
生成的 extensions.json 文件:
{
"recommendations": [
"dbaeumer.vscode-eslint"
]
}
拿到别人的项目,安装项目中推荐的扩展插件:
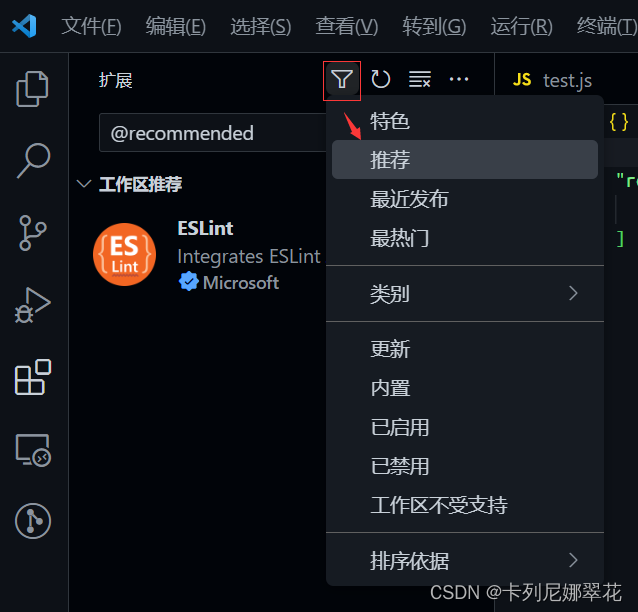
创建工作区设置配置文件:
进入工作区设置界面,点击任一【在setting.json中编辑】链接都会自动创建setting.json文件。
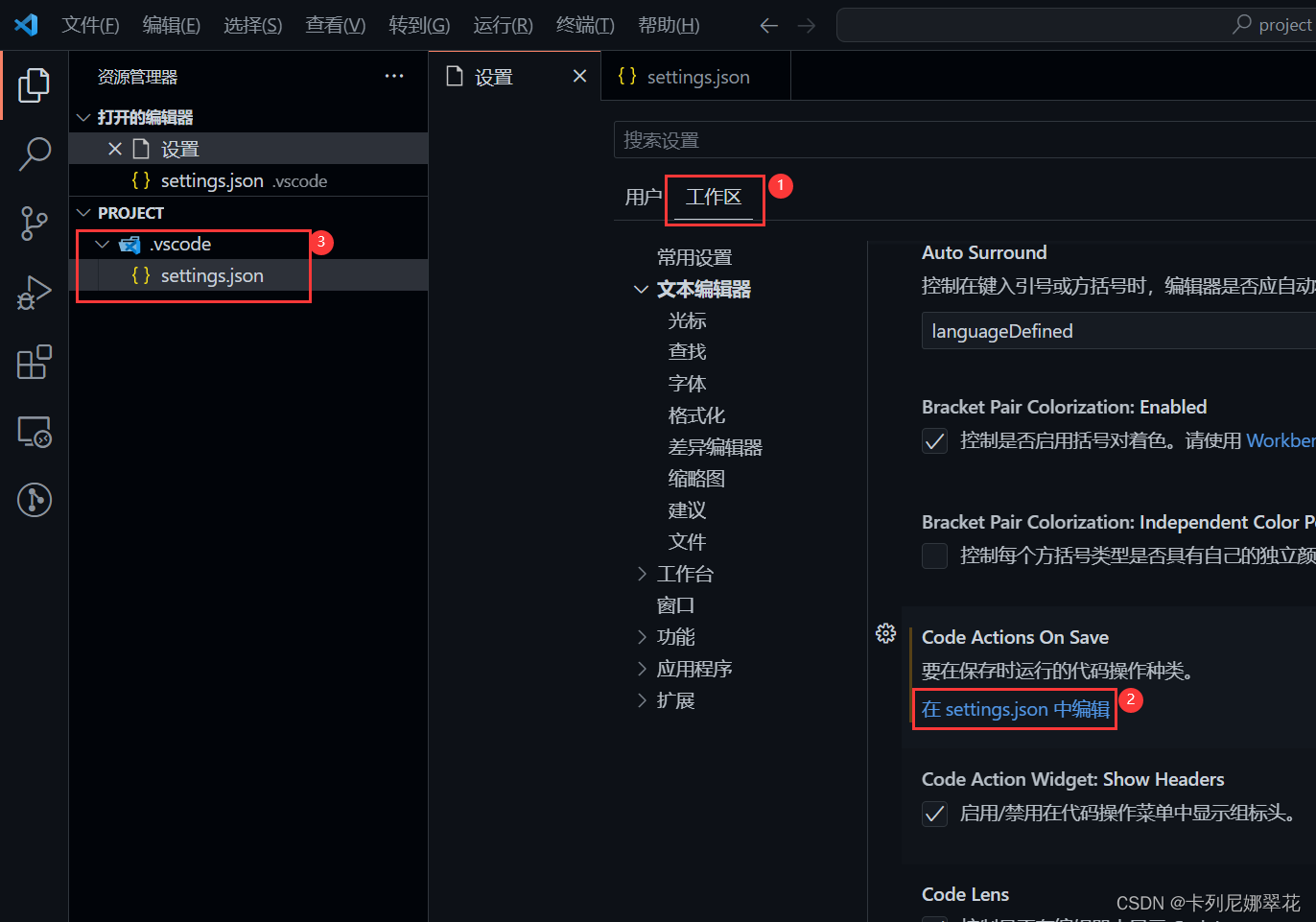
生成的 setting.json 文件:
{
"editor.codeActionsOnSave": {
}
}
如果想直接修改JSON文件,可以使用ctrl + space智能提示来查看该选项都有哪些设置。
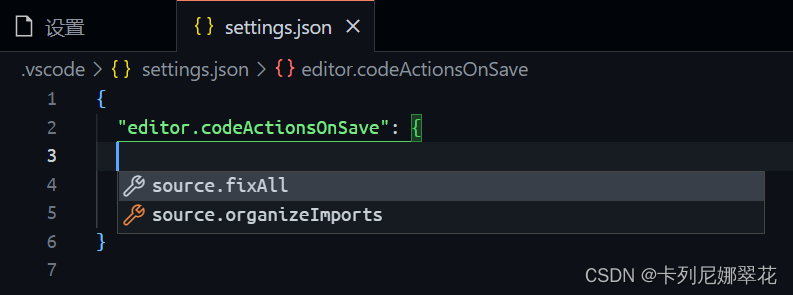
生成 setting.json 文件后,在可视化的工作区设置界面,修改的设置都会自动添加到 setting.json 文件中。包括对插件的设置。
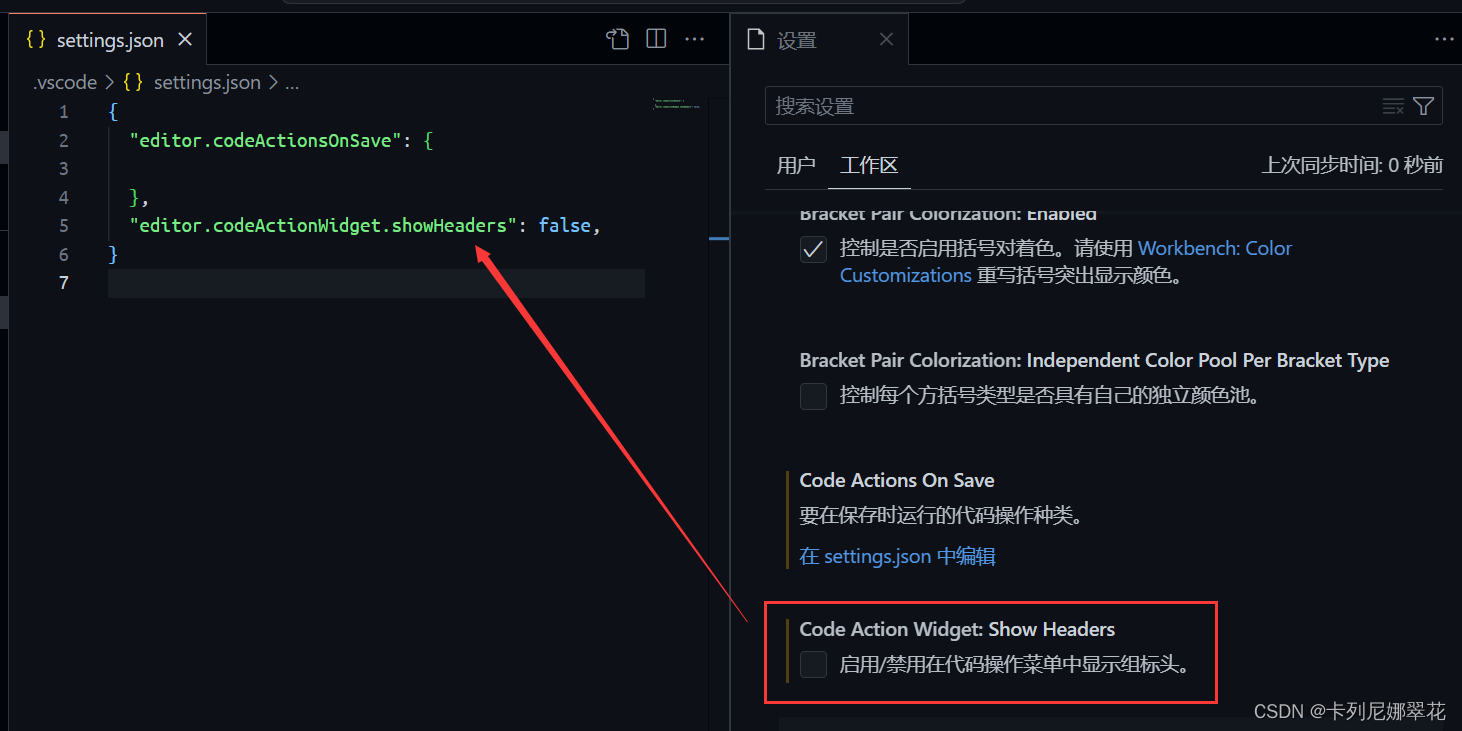
创建调试配置文件:
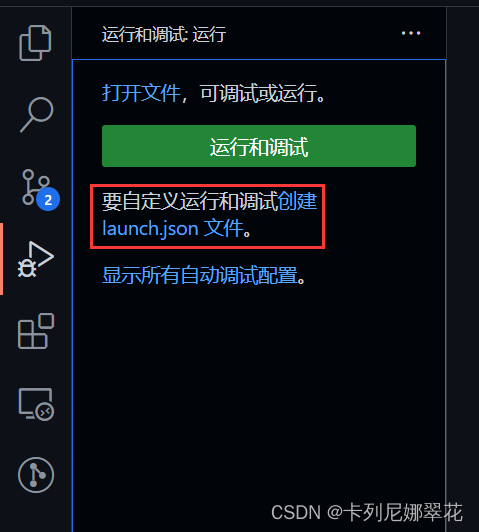
选择调试引擎后,就会自动生成调试配置文件,以 node.js 为调试引擎为例:
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "启动程序",
"skipFiles": [
"<node_internals>/**"
],
"program": "${file}"
}
]
}
之前很多工作都是通过命令行为完成,比如执行一个文件 node test.js。这种工作就可以配置成任务,让vscode一键执行。
创建任务配置文件:
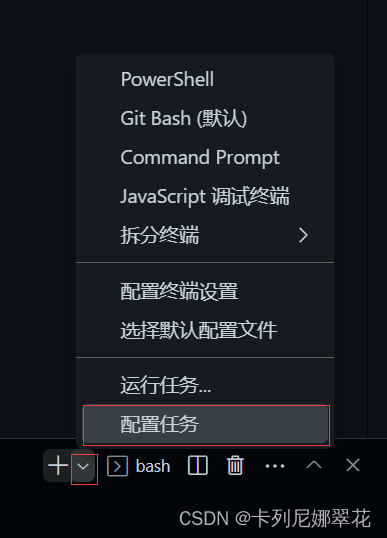
如果项目中存在 package.json 文件,vscode 就会读取其中的脚本命令,可以方便的将脚本命令配置为任务。
比如自动配置好 node 执行 test.js 文件的任务。
package.json :
"scripts": {
"node": "node test.js",
},
vscode 自动读取脚本,选择要配置的任务:
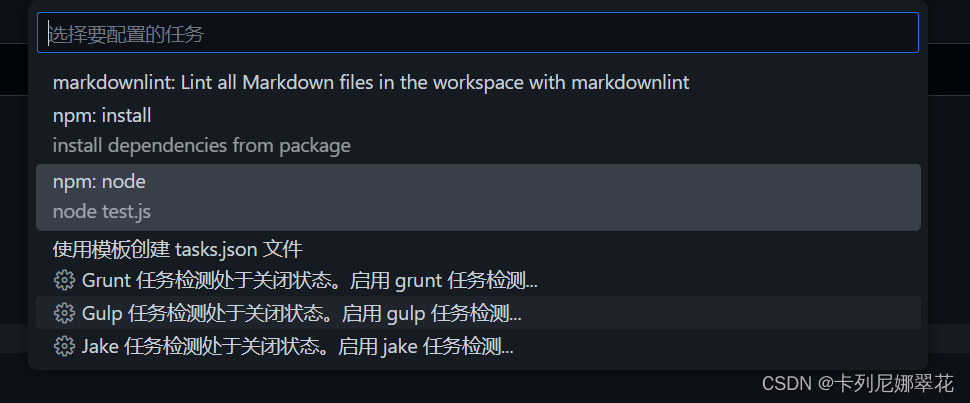
task.json:
{
"version": "2.0.0",
"tasks": [
{
"type": "npm",
"script": "node",
"problemMatcher": [],
"label": "npm: node",
"detail": "node test.js"
}
]
}
对于一些重复代码,我们可以在 vscode 中配置用户代码片段,方便一键生成。
代码片段有用户级别的,也有项目级别的。用户级,比如你换了台电脑,就可以将自己之前保存的代码片段共享过来,项目级别的就是便于团队成员之间使用了。
创建代码片段:

VSCode中的代码片段有固定的 json 格式,所以我们一般会借助于一个在线工具来完成
具体的步骤如下:
● 第一步,复制自己需要生成代码片段的代码;
{
"片段名字": {
"prefix": "快捷指令",
"body": [
代码片段
],
"description": ""
}
}
● 第二步,https://snippet-generator.app/在该网站中生成代码片段;
● 第三步,在VSCode中配置代码片段;
比如生成一个打印 123 的片段:
"print 123": {
"prefix": "p123",
"body": [
"console.log(123)"
],
"description": "print 123"
}
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i